[2022-10-09]神经网络与深度学习 hw5 - 卷积
contents
- hw5 卷积
-
- task1
-
-
- 题目内容
- 题目分析
-
- 区分:卷积核和滤波器
- 卷积核里面的数字是怎么得到的
- 卷积的过程
- 边上怎么办?对于边界的处理
- 解答
-
- task2
-
- 题目内容
- 题目分析
- 题目解答
-
- 语言描述
- 探究不同卷积核的作用
- 编程实现各种操作
-
- 灰度图操作
- 调整卷积核参数
- 使用不同尺寸照片测试并总结
- 更多卷积核
- 彩色图片边缘检测
- 总结
hw5 卷积
task1
题目内容
编程实现下图:
![[2022-10-09]神经网络与深度学习 hw5 - 卷积_第1张图片](http://img.e-com-net.com/image/info8/32d9404346b54d45a9ffbfa005da72d6.png)
题目分析
这题是简单的使用卷积核对图像进行卷积运算的过程,本人理解该过程是卷积核在原图像上进行滑动并且加权相加的过程,由此只要写一个卷积过程的代码即可得到卷积完成后的结果。
卷积的过程抽象一点理解是如下公式:
g ( x , y ) = w ∗ f ( x , y ) = ∑ d x = − a a ∑ d y = − b b w ( d x , d y ) f ( x − d x , y − d y ) g(x,y)=w * f(x,y)=\sum_{dx=-a}^{a}\sum_{dy=-b}^{b}w(dx,dy)f(x-dx,y-dy) g(x,y)=w∗f(x,y)=dx=−a∑ady=−b∑bw(dx,dy)f(x−dx,y−dy)
其中 w w w为滤波器的卷积核, f f f为原图像, g g g为卷积后图像。
区分:卷积核和滤波器
卷积核是图像卷积过程中一个简单的、用于进行图像卷积运算的二维矩阵,而滤波器是由多个卷积核组成的三维的矩阵,多出的一维是通道(比如彩色图像有RGB三个通道)
卷积核里面的数字是怎么得到的
一开始我以为这个卷积核里面的数字是试出来的,但是经过数字信号处理的学习后,我们能够发现这些卷积核都是由数字信号处理中的各种变换推理得到,下面列举几种卷积核:
![[2022-10-09]神经网络与深度学习 hw5 - 卷积_第2张图片](http://img.e-com-net.com/image/info8/f2441a8aee5946758ed3f7e784027594.jpg)
卷积的过程
前面在思路里面讲的卷积过程并不直观,公式又过于繁琐,因此这边给出一张非常直观的卷积动图:
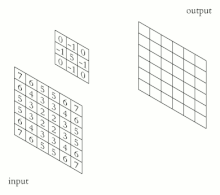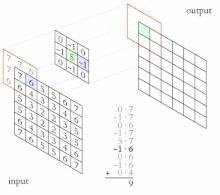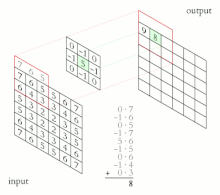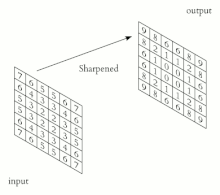
边上怎么办?对于边界的处理
在卷积过程中免不了对于边界部分的处理,大体上有三种方式:
- 边缘填充:填充一些特定数字,让卷积能够正常运行,这个一般用于保持输入输出大小;
- 忽略:直接从非边缘开始,这个方法一般会改变输出图像的大小;
- 重复像素填充:边缘增加和开头相同值的像素点。
传送门:介绍卷积的pdf
解答
由题意我们很容易得到代码,这边我们使用热度图进行图像可视化:
fig,*ax = plt.subplots(1,2,figsize=(10,5))
img_ori = torch.tensor([[[[0,0,0,255,255,255]] * 7]])
img_kernel = torch.tensor([[[[-1,1]]]])
cmap = (mpl.colors.ListedColormap(['black', 'white'])
.with_extremes(over='red', under='blue'))
ax[0][0].imshow(img_ori[0,0],cmap=cmap)
ax[0][0].set_xticks([])
ax[0][0].set_yticks([])
ax[0][0].set_title('original image')
img_new = torch.conv2d(img_ori,img_kernel,None)
ax[0][1].imshow(img_new[0,0],cmap=cmap)
ax[0][1].set_xticks([])
ax[0][1].set_yticks([])
ax[0][1].set_title('transformed image')
plt.show()
得到结果:
![[2022-10-09]神经网络与深度学习 hw5 - 卷积_第3张图片](http://img.e-com-net.com/image/info8/220a5473a146486e9103b1f7cb61ef57.png)
然后我们对如下三个图进行卷积操作并输出特征图:
![[2022-10-09]神经网络与深度学习 hw5 - 卷积_第4张图片](http://img.e-com-net.com/image/info8/7f1fd128a64f496a8e91421f84292d8f.jpg)
按照特定要求卷积完成后的图像结果:
![[2022-10-09]神经网络与深度学习 hw5 - 卷积_第5张图片](http://img.e-com-net.com/image/info8/46613d113d1b4eb4acb78187d40edfc9.jpg)
task2
题目内容
- 用自己的语言描述“卷积、卷积核、特征图、特征选择、步长、填充、感受野”。
- 探究不同卷积核的作用
- 编程实现:
- 实现灰度图的边缘检测、锐化、模糊
- 调整卷积核参数,测试并总结
- 使用不同尺寸图片,测试并总结
- 探索更多类型卷积核
- 尝试彩色图片边缘检测
题目分析
题目主要考察的是卷积的各种概念、各种卷积核以及卷积的实际应用。
题目解答
语言描述
-
卷积:将两个函数通过翻转平移(类似滑动窗口)进行相乘并求和得到一个新的函数。其规则理解是前文提到的公式:
g ( x , y ) = w ∗ f ( x , y ) = ∑ d x = − a a ∑ d y = − b b w ( d x , d y ) f ( x − d x , y − d y ) g(x,y)=w * f(x,y)=\sum_{dx=-a}^{a}\sum_{dy=-b}^{b}w(dx,dy)f(x-dx,y-dy) g(x,y)=w∗f(x,y)=dx=−a∑ady=−b∑bw(dx,dy)f(x−dx,y−dy)
还找到一张直观的图片:
![[2022-10-09]神经网络与深度学习 hw5 - 卷积_第6张图片](http://img.e-com-net.com/image/info8/364065df10f04c9dadb9b741e3ccfbcb.jpg)
-
卷积核:一个小的二维矩阵,用来在原图像上面通过滑动进行卷积的相乘相加得到新的像素值。卷积核的参数通过数字信号处理的各种处理方法得到。
-
特征图:图像经过卷积过程后,其由卷积核卷积得到的有其特征的新的图像,比如边缘卷积核卷积后得到的边缘的图像就是特征图。
-
特征选择:选择不同的卷积核用来对原图像进行不同特征提取的过程,选择合适的特征能够更好地表现图像的特殊之处。
-
步长:卷积核在原图上滑动一次的跨度。如步长为1就是卷积核计算一次后向右移动一个像素,步长为2则是移动两个像素。
-
填充:为了方便保持图像大小不变,或者保留边缘特征而在边缘处增加像素点的操作。
-
感受野:可以理解成卷积核的大小。就像人眼看东西是聚焦一部分一部分的,每次卷积就相当于“看”一部分,卷积的大小会影响一次“看”的范围,这个范围(和卷积核大小相同)就是感受野。
探究不同卷积核的作用
因为卷积核太多了,我们使用在线的网站来体验这些卷积核:
![[2022-10-09]神经网络与深度学习 hw5 - 卷积_第7张图片](http://img.e-com-net.com/image/info8/7cd57386fb234252972759e8f51b937c.jpg)
这篇文章详细地介绍了各种卷积核矩阵和作用,本作也中不展开叙述。
编程实现各种操作
灰度图操作
边缘检测我们使用如下卷积核来进行:

锐化我们采用如下卷积核:
![[2022-10-09]神经网络与深度学习 hw5 - 卷积_第8张图片](http://img.e-com-net.com/image/info8/41e337c119c548e88cfc262df2688df9.png)
模糊我们采用如下卷积核:
![[2022-10-09]神经网络与深度学习 hw5 - 卷积_第9张图片](http://img.e-com-net.com/image/info8/ab02dc295ef0408c97bafb539620b5c2.jpg)
这三种卷积的结果总体代码和效果如下:
import cv2
img = plt.imread(r'C:\Users\Lupnis\Downloads\test.jpg')
img = cv2.cvtColor(img,cv2.COLOR_RGB2GRAY)
fig,*ax = plt.subplots(1,4,figsize=(20,20))
ax[0][0].imshow(img,cmap='gray')
ax[0][0].set_xticks([])
ax[0][0].set_yticks([])
ax[0][0].set_title('original image')
img_kernel = torch.tensor([[[
[ -1., -1., -1.],
[ -1., 8., -1.],
[ -1., -1., -1.]
]]],dtype=torch.float)
img_new = torch.conv2d(torch.tensor([[img]],dtype=torch.float),img_kernel,None)
img_new = torch.clamp(img_new,0.,255.)
ax[0][1].imshow(img_new[0,0],cmap='gray')
ax[0][1].set_xticks([])
ax[0][1].set_yticks([])
ax[0][1].set_title('outline')
img_kernel = torch.tensor([[[
[ 0., -1., 0.],
[ -1., 5., -1.],
[ 0., -1., 0.]
]]],dtype=torch.float)
img_new = torch.conv2d(torch.tensor([[img]],dtype=torch.float),img_kernel,None)
img_new = torch.clamp(img_new,0.,255.)
ax[0][2].imshow(img_new[0,0],cmap='gray')
ax[0][2].set_xticks([])
ax[0][2].set_yticks([])
ax[0][2].set_title('sharpen')
img_kernel = torch.tensor([[[
[ 0.0625, 0.125, 0.0625],
[ 0.125, 0.25, 0.125],
[ 0.0625, 0.125, 0.0625]
]]],dtype=torch.float)
img_new = torch.conv2d(torch.tensor([[img]],dtype=torch.float),img_kernel,None)
img_new = torch.clamp(img_new,0.,255.)
ax[0][3].imshow(img_new[0,0],cmap='gray')
ax[0][3].set_xticks([])
ax[0][3].set_yticks([])
ax[0][3].set_title('blur')
plt.show()
![[2022-10-09]神经网络与深度学习 hw5 - 卷积_第10张图片](http://img.e-com-net.com/image/info8/20ffd76b190a45ae8544c2ad48c4dcd4.jpg)
调整卷积核参数
我们将描边的卷积核进行修改来进行测试,我们将中间的数字改为0和10,结果如下:
![[2022-10-09]神经网络与深度学习 hw5 - 卷积_第11张图片](http://img.e-com-net.com/image/info8/d1f79b1dfb3444278631b306fb3b4d2b.jpg)
我们将四周的数字改成-2和-1.5,结果如下:
![[2022-10-09]神经网络与深度学习 hw5 - 卷积_第12张图片](http://img.e-com-net.com/image/info8/e28a0d061f1b4873a1bda87281e1dc74.jpg)
**总结:**对于卷积核参数进行修改,在相加值在0~255之间时,图片显示正常,能够正确得出特征图,然而,当卷积核计算得到恒为小于等于0或者大于等于255时,特征图将会没有任何意义,因为图片将会是纯黑或者纯白。同时,在代码中,由于像素经过卷积后将有超过255和小于0的数,因此需要使用截断:img_new = torch.clamp(img_new,0.,255.)
使用不同尺寸照片测试并总结
不同尺寸的图片卷积效果如下:
![[2022-10-09]神经网络与深度学习 hw5 - 卷积_第13张图片](http://img.e-com-net.com/image/info8/ca9626a244c34b999daf50ad82a4e23b.jpg)
**总结:**我们发现图像尺寸并不会影响卷积的内容,只是会让卷积过程的耗时发生变化,卷积的效果只和卷积的图像特征相关。
更多卷积核
卷积核千变万化,我找到这些卷积核:传送门
彩色图片边缘检测
彩色图片相对灰度图片,仅仅是增加了两个颜色通道,在每个通道计算完后重新汇总起来即可。代码如下:
img = plt.imread(r'C:\Users\Lupnis\Downloads\小豆泥.jpg') / 255.
fig,*ax = plt.subplots(1,2,figsize=(20,10))
ax[0][0].imshow(img,cmap='gray')
ax[0][0].set_xticks([])
ax[0][0].set_yticks([])
ax[0][0].set_title('original image')
img_kernel = torch.tensor([[[
[ -1., -1., -1.],
[ -1., 8., -1.],
[ -1., -1., -1.]
]]],dtype=torch.float).expand(3,1,3,3)
img_new = torch.conv2d(torch.tensor(img,dtype=torch.float).permute(2,0,1).unsqueeze(0),img_kernel,groups=3)
img_new = torch.clamp(img_new,0.,1.).detach().squeeze(0).permute(1,2,0)
ax[0][1].imshow(img_new)
ax[0][1].set_xticks([])
ax[0][1].set_yticks([])
ax[0][1].set_title('outline')
结果如下:

总结
通过本次作业,我了解到了卷积的原理、过程;不同的卷积核及其作用,以及为什么卷积核能够提取特征:
- 1.卷积核就像人类眼睛,通过感受野去观察图片;
- 2.卷积核是由数字信号处理的各种变换和滤波器得到,能够对图像进行基于数学的滤波等操作提取特征;
- 3.卷积核本质上是对图片在感受野内的总结和抽象,通过这个过程能够提取图像本身的特征。