机器学习之聚类(实战)
1.无监督学习
按照特征进行划分,没有对与错,寻找数据的共同点。
机器学习的一种方法,没有给定事先标记过的训练示例,自动对输入的数据进行分类或分群。
优点:
- 算法不受监督信息的约束,可能考虑到新的信息。
- 不需要标签数据,极大程度扩大数据样本。
主要应用:聚类分析clustering,关联规则,维度缩减
与监督学习的区别:没有数据标签y
- 监督学习:训练数据{
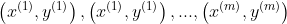 }
} - 无监督学习:训练数据{
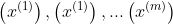 }
}
无监督学习常用算法:聚类分析
- 聚类分析又称群分析,根据对象某些属性的相似度,将其自动划分类别。
- 聚类分析常用算法:KMeans聚类,Meansift均值漂移聚类,DBSCAN基于密度的空间聚类算法
1).KMeans聚类:根据数据与中心点距离划分类别;基于类别数据更新中心的;重复至收敛。
特点:实现简单,收敛快;需要指定类别数量
2).Meanshift均值漂移聚类:在中心点一定区域检索数据;更新中心;重复至中心点稳定。
特点:自动发现类别数量,不需要人工选择;需要选择区域半径。
3).DBSCAN基于密度的空间聚类算法:基于区域点密度筛选有效数据;居于有效数据向周边扩张,直到没有新点加入。
特点:可以过滤噪声;不用人为选择类别数量;数据密度不同时影响结果。
2.Kmeans,KNN(监督学习),Mean-shift
(1)KMeans Analysis K均值聚类
- 定义:以空间中k个点为中心进行聚类,对最靠近他们的对象归类
- 公式:
数据点与各簇中心点的距离:![]()
根据距离归类: ∈
∈![]()
中心更新: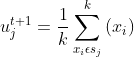

其中: 为t时刻第j个区域簇;k为包含在范围内点的个数;为包含在范围内的点;
为t时刻第j个区域簇;k为包含在范围内点的个数;为包含在范围内的点;![]() 为t状态下第j区域中心。
为t状态下第j区域中心。
- 算法流程:
1)选择聚类的个数k
2)确定聚类中心
3)根据点找到聚类中心确定各点所属类别
4)根据各个类别的数据更新聚类中心
5)重复直到收敛
(2)KNN近邻分类模型
- 定义:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某类别,就把该输入实例分类到这个类中。
(3)均值漂移聚类
- 一种基于密度梯度上升的聚类算法(沿着密度梯度上升的方向寻找聚类中心点)
- 公式:
均值偏移: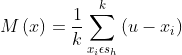
中心更新:![]()
其中:![]() 以u为中心点,半径为h的高维半球区域;k为包含在
以u为中心点,半径为h的高维半球区域;k为包含在![]() 范围内点的个数;为包含在
范围内点的个数;为包含在![]() 范围内的点均值;
范围内的点均值;![]() 为t状态下求得的偏移;
为t状态下求得的偏移;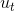 为t状态下的中心。
为t状态下的中心。
- 算法流程:
1)随机选择未分类点作为中心点
2)找出离中心点距离在带宽之内的点,记作集合s
3)计算从中心点到集合s中每个匀速的便宜向量M
4)中心点以向量M移动
5)重复2-4,直到收敛
6)重复1-5直到所有点都被归类
7)分类:根据每个类,对每个点的访问频率,取访问频率最大的那个类,作为当前点集的所属类。
3.实战准备
(1)KMeans Analysis K均值聚类
- 模型训练
from sklearn.cluster import KMeans
#n_clusters就是k,要分成几类;random_state是初始状态
KM = KMeans(n_clusters = 3,random_state = 0
KM.fit(x)- 获取模型确定的中心点
centers = KM.cluster_centers_- 准确率计算
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)- 预测结果矫正
#y_cal:矫正的结果,i是预测的结果,120是实际的结果 y_cal = [] for i in y_predict: if i == 0: y_cal.append(2) elif i == 0: y_cal.append(1) else: y_cal.append(0) print(y_predict,y_cal)(2)Meanshift均值漂移聚类
- 自动计算带宽(区域半径)
from sklearn.cluster import MeanShift,estimate_bandwidth
#detect bandwidth;X是样本数量;n_samples是采用多少样本
bandwidth = estimate_bandwidth(X,n_samples = 500)- 模型建立与训练
ms = MeanShift(bandwidth = bandwidth)
ms.fit(X)(3)KNN近邻分类模型
from sklearn.neighbors import KNeighborsClassifier
KNN = KNeighborsClassifier(n_neighbors = 3)
KNN.fit(X,y)
4.实战一:2D数据类别划分
- 目的:
(1)采用Kmeans算法实现2D数据自动聚类,预测V1=80,V2=60数据类别;
(2)计算预测准确率,完成结果矫正
(3)采用KNN,MeanShift算法,重复1-2