elasticsearc在后端上传word,PDF,Txt文本后将里面正文内容导入到elasticsearch字段
最先再es里面安装插件很重要
在es数据库的目录下有个bin文件夹在这个文件夹下执行
./elasticsearch-plugin install ingest-attachment
插件目录下可以看到

如果搭es集群每一个节点都要有
启动es可以看到

说明安装好了
创建自己的文本抽取管道pipeline
其中url里的attachment可以自定义
curl -X PUT “localhost:9200/_ingest/pipeline/attachment” -d ‘{
“description” : “Extract attachment information”,
“processors”:[
{
“attachment”:{
“field”:“data”,
“indexed_chars” : -1,
“ignore_missing”:true
}
},
{
“remove”:{“field”:“data”}
}]}’
建立索引和映射:

在kibana里面操作是这样的
PUT _ingest/pipeline/attachment
{
“description” : “Extract attachment information”,
“processors” : [
{
“attachment” : {
“field” : “file-contents”,
“indexed_chars” : -1,
“ignore_missing”:true
}
},
{
“remove”: {
“field”: “file-contents”
}
}
]
}

然后建立映射是这样的
PUT /wodewendang
{
“settings”: {
“number_of_shards”: 3,
“number_of_replicas”: 0
},
“mappings”: {
“document”:{
“properties”:{
“documentid”:{
“type”:“long”
},
“documentname”:{
“type”:“text”,
“analyzer”:“ik_max_word”
},
“documentsize”:{
“type”:“long”
},
“uploader”:{
“type”:“text”,
“analyzer”:“ik_max_word”
},
“uploadtime”:{
“type”:“date”
},
“attachment”: {
“properties”: {
“content”: {
“type”: “text”,
“analyzer”: “ik_max_word”
}
}
}
}
}
}
}

正文上传时候word,pdf,txt先转成base64
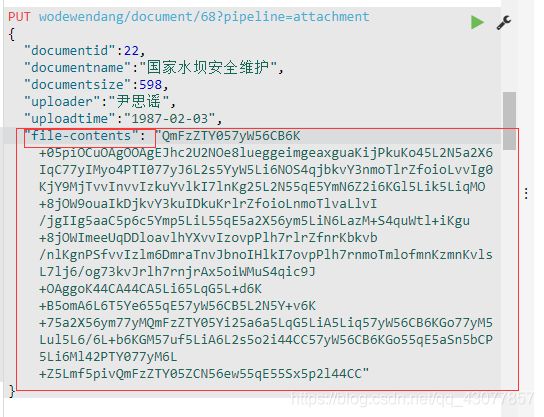
直接转成了这种中文

搜索正文
GET /wodewendang/document/_search
{
“query”:{
"match":{
"attachment.content":"编码"
}}}

这里用kibana
输入一段正文做尝试
这里是添加的Java api:
做一个test
@Test
public void esAddTest8() throws Exception {
Settings settings=Settings.builder().put(“cluster.name”, “cluster-elasticsearch-prod”).build();
TransportClient client=new PreBuiltTransportClient(settings)
.addTransportAddress(new TransportAddress(InetAddress.getByName(“192.168.1.109”), 9300));
String importText = importText();
String randomUUID = UUID.randomUUID().toString();
XContentBuilder doc=XContentFactory.jsonBuilder()
.startObject()
.field(“File_ID”, randomUUID)
.field(“FileName”,“云之遥水库信息”)
.field(“FileSize”, 65555)
.field(“User_ID”, “李凡”)
.field(“LastChangerTime”, “2019-11-28”)
.field(“file-contents”,importText)
.endObject();
IndexResponse response=client.prepareIndex(“tgdsm”, “fileinfo”, “563”).setSource(doc).setPipeline(“attachment”).get();
System.out.println("============="+response.status());
}
截图标注

如果不加setPipeline(“attachment”)
![]()
加入后会直接加入结果如下:

加上之后:

文本内容被转译
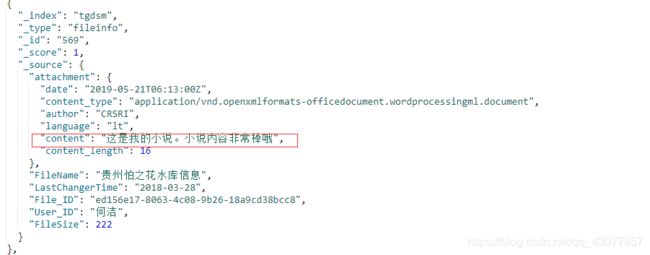
搜索
