可直接拿来用的kafka+prometheus+grafana监控告警配置
kafka配置jmx_exporter
点击:https://github.com/prometheus/jmx_exporter,选择下面的jar包下载:
将下载好的这个agent jar包上传到kafka的broker节点所在服务器上,每个broker都需要,比如上传到如下路径:
/opt/agent/jmx_prometheus_javaagent-0.16.1.jar
修改kafka启动脚本: bin/kafka-server-start.sh,增加java agent配置如下:
-
JMX_EXPORTER_OPTS=
"-javaagent:/opt/agent/jmx_prometheus_javaagent-0.16.1.jar=9095:/opt/agent/kafka_broker.yml"
-
export KAFKA_JMX_OPTS=
"$KAFKA_JMX_OPTS $JMX_EXPORTER_OPTS"
这两行代码可以添加在脚本首部。
这里指定了9095作为端口,jmx_exporter用到的kafka_broker.yml 配置如下:https://github.com/xxd763795151/kafka-exporter/blob/main/kafka_broker.yml
将kafka每个broker都这样配置,重启kafka。
Prometheus配置
修改prometheus的配置prometheus.yml,增加如下配置:
p.s. 注意job_name不要修改,值就是"kafka",要不我下面的grafana不能直接用,还需要每个面板依次修改。
Grafana配置
下面的Grafana面板我已经配置好,可以直接拿来用,之后可以根据需要增加或删除相关面板:https://github.com/xxd763795151/kafka-exporter/blob/main/grafana.json
贴几个截图:
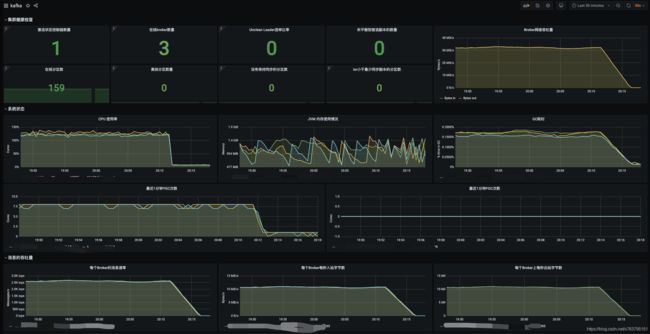
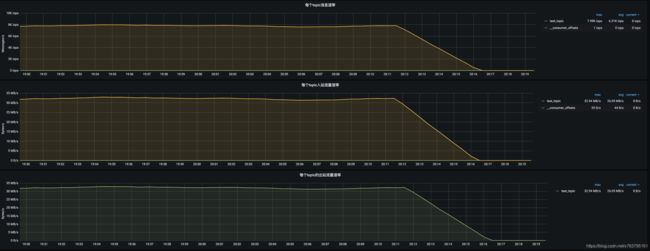
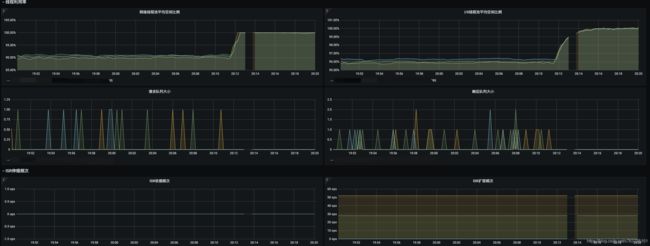

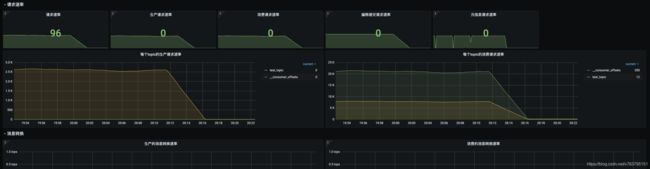
消息积压
在kafka的broker端无法直接获取消息积压等指标信息,这些数据在消费端上,我们也不太可能去连接所有的消费端获取监控信息。
所以,我单独写了一个kafka-exporter可以获取消息积压的监控指标:https://github.com/xxd763795151/kafka-exporter
点击这个链接进入github仓库后,根据说明进行部署并配置启动后,然后在prometheus.yml增加如下配置:
上面的grafana配置里已经包含了消息积压的面板:
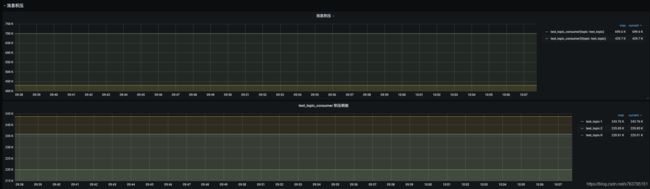 如果后续有其它指标在jmx里不提供,也可以继续补充kafka-exporter,刮取更多需要的metrics。
如果后续有其它指标在jmx里不提供,也可以继续补充kafka-exporter,刮取更多需要的metrics。
告警
最新的配置代码会提交在这里: https://github.com/xxd763795151/kafka-exporter/blob/main/kafka_alert.yml
示例如下:
末语
我从grafana 官方上搜索了几个dashboard,但指标实在太少。感谢从这篇博文里找到的grafana配置可以参考,提供了很多指标的面板,可以让我对着kafka官方监控jmx说明进行整理,让我在grafana面板的配置上,省了一半的功夫:
https://www.confluent.io/blog/monitor-kafka-clusters-with-prometheus-grafana-and-confluent/