利用PaddleOCR训练车牌识别模型
目录
1--前言
2--生成车牌数据集
3--构建车牌数据集标签
4--自定义字典
5--训练模型
6--模型转换和推理
7--模型转换为onnx模型
8--参考
1--前言
①系统:Ubuntu18.04
②Cuda:11.0
③CudaNN:8.04
④配置Paddle环境
2--生成车牌数据集
①具体可见GitHub项目:Github生成车牌数据集
#coding=utf-8
import random
import numpy as np
from PlateCommon import *
if __name__ == "__main__":
import all_kinds_plate
else:
from . import all_kinds_plate
def aug_generate(com):
# cv2.imwrite('03.jpg', com)
com = rot(com, r(20)-10, com.shape, 10) # 矩形-->平行四边形
# cv2.imwrite('04.jpg', com)
com = rotRandrom(com, 5, (com.shape[1], com.shape[0])) # 旋转
# cv2.imwrite('05.jpg', com)
com = tfactor(com) # 调灰度
# cv2.imwrite('06.jpg', com)
com, loc = random_scene(com, "./background") # 放入背景中
# com,loc = random_scene_dangerous(com,"./dangerous_background") #针对黄牌大货车带危险品字样识别不好的情况进行特点生成
if com is None or loc is None:
return None, None
# cv2.imwrite('07.jpg', com)
com = AddGauss(com, 5) # 加高斯平滑
# cv2.imwrite('08.jpg', com)
com = addNoise(com) # 加噪声
# cv2.imwrite('09.jpg', com)
return com, loc
class Draw:
_draw = [
all_kinds_plate.BlackPlate(),
all_kinds_plate.BluePlate(),
all_kinds_plate.GreenPlate(),
all_kinds_plate.YellowPlate(),
all_kinds_plate.WhitePlate(),
all_kinds_plate.SpecialPlate(),
all_kinds_plate.RedPlate(),
all_kinds_plate.RedPlate1(),
]
_provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新"]
_alphabets = ["A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L", "M", "N", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z"]
_ads = ["A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L", "M", "N", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z", "0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
def __call__(self):
draw = random.choice(self._draw)
candidates = [self._provinces, self._alphabets]
if type(draw) == all_kinds_plate.GreenPlate:
candidates += [self._ads] * 6
label = "".join([random.choice(c) for c in candidates])
return draw(label, random.randint(0, 1)), label
elif type(draw) == all_kinds_plate.BlackPlate:
if random.random() < 0.5:
candidates += [self._ads] * 4
candidates += [["港", "澳"]]
else:
candidates += [self._ads] * 5
label = "".join([random.choice(c) for c in candidates])
return draw(label), label
elif type(draw) == all_kinds_plate.YellowPlate:
if random.random() < 0.1:
candidates += [self._ads] * 4
candidates += [["学"]]
else:
candidates += [self._ads] * 5
label = "".join([random.choice(c) for c in candidates])
return draw(label), label
elif type(draw) == all_kinds_plate.WhitePlate:
candidates += [self._ads] * 4
candidates += [["警"]]
label = "".join([random.choice(c) for c in candidates])
return draw(label), label
elif type(draw) == all_kinds_plate.SpecialPlate:
candidates = [self._alphabets, self._alphabets]
candidates += [self._ads] * 5
label = "".join([random.choice(c) for c in candidates])
return draw(label), label
else:
candidates += [self._ads] * 5
label = "".join([random.choice(c) for c in candidates])
return draw(label), label
if __name__ == "__main__":
import math
import argparse
import matplotlib.pyplot as plt
import cv2
parser = argparse.ArgumentParser(description="Random generate all kinds of chinese plate.")
parser.add_argument("--num", help="set the number of plates (default: 9)", type=int, default=10000)
parser.add_argument("--savepath", help="savepath", type=str, default="./Save_Result/train_dataset")
args = parser.parse_args()
draw = Draw()
for i in range(args.num):
plate, label = draw()
print(label)
img = cv2.cvtColor(plate,cv2.COLOR_RGB2BGR)
img,loc = aug_generate(img)
path = os.path.join(args.savepath,label+".jpg")
cv2.imwrite(path,img)②终端调用:
# --num 表示生成的车牌数目
# --savepath 生成车牌数据集存放的位置
python main.py --num 10000 --savepath ./Save_Result/train_dataset这里博主生成10000个车牌作为训练集,1000个车牌作为测试集:
python main.py --num 10000 --savepath ./Save_Result/train_dataset
python main.py --num 1000 --savepath ./Save_Result/test_dataset3--构建车牌数据集标签
①参考官方文档对于自制数据集的规定:

②标签构建代码:
import os
paths = os.listdir('./Save_Result')
for path in paths:
count = 0
total = []
for item in os.listdir(os.path.join('./Save_Result', path)):
if item[-3:] == 'jpg':
#new_path = os.path.join('./CPDD_Dataset', path, item) # train_data_path
new_path = os.path.join(item)
line = new_path+'\t' + item[:-4]
line = line[:] + '\n'
total.append(line)
count = count + 1
print(count)
with open('./Save_Result/'+path+'.txt', 'w', encoding='UTF-8') as f:
for line in total:
f.write(line)
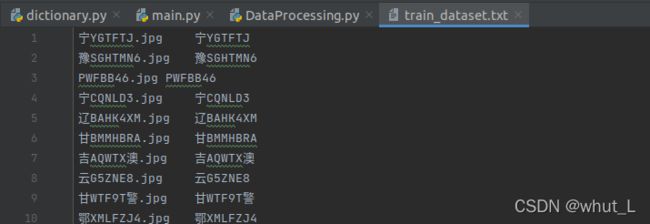
③结果展示:
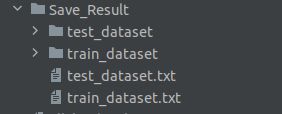
其中train_dataset存在车牌图片,txt文件存放标签,txt文件内容如下图所示,第一项是路径,第二项是标签,符合官方文档要求。
4--自定义字典
注:若使用默认提供的字典,可能会导致预测新数据时,出现不属于车牌的字符,因为默认字典拥有6000+字符。
①官方文档对于自制字典的要求:

②自制车牌字典的代码:
dic_list = [
"A","B","C","D","E",
"F","G","H","J","K",
"L","M","N","P","Q",
"R","S","T","U","V",
"W","X","Y","Z","0",
"1","2","3","4","5",
"6","7","8","9",
"皖", "沪", "津", "渝", "冀",
"晋", "蒙", "辽", "吉", "黑",
"苏", "浙", "京", "闽", "赣",
"鲁", "豫", "鄂", "湘", "粤",
"桂", "琼", "川", "贵", "云",
"西", "陕", "甘", "青", "宁",
"新", "港", "澳", "学", "警"
]
with open('./dictionary_dir/' + 'dic_license_plate' + '.txt', 'w', encoding='UTF-8') as f:
for line in dic_list:
if line == "警":
f.write(line)
else:
f.write(line + '\n')5--训练模型
①下载PaddleOCR源码:PaddleOCR项目源码
②下载CRNN识别模型,放在新建的pretrain_models文件夹中。
# 进入下载的OCR源码项目
# cd PaddleOCR/
# 下载MobileNetV3的预训练模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_mv3_none_bilstm_ctc_v2.0_train.tar
# 解压模型参数
cd pretrain_models # 进入新建的pretrain_models文件夹
tar -xf rec_mv3_none_bilstm_ctc_v2.0_train.tar && rm -rf rec_mv3_none_bilstm_ctc_v2.0_train.tar③配置yml文件:
参考官方文档提供的yml文件:rec_chinese_lite_train_v2.0.yml
这里提供博主的设置:
Global:
use_gpu: true
epoch_num: 200 # epoch数目
log_smooth_window: 20
print_batch_step: 10
save_model_dir: /civi/license_plate_model/train10000_test1000
save_epoch_step: 5 # 保存模型的间隔
# evaluation is run every 5000 iterations after the 4000th iteration
eval_batch_step: [0, 2000]
cal_metric_during_train: True
pretrained_model: /civi/PaddleOCR-release-2.4/pretrain_models/rec_mv3_none_bilstm_ctc_v2.0_train # 预训练模型的地址
checkpoints:
save_inference_dir:
use_visualdl: False
infer_img: /civi/generate_chinese_license_plate-master/Prediction_file/LMWWEZ9.jpg # 预测图片
# for data or label process
character_dict_path: /civi/generate_chinese_license_plate-master/dictionary_dir/dic_license_plate.txt
max_text_length: 25
infer_mode: False
use_space_char: True
save_res_path: /civi/license_plate_model/train10000_test1000/rec/rec.txt
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.001
warmup_epoch: 5
regularizer:
name: 'L2'
factor: 0.00004
Architecture:
model_type: rec
algorithm: CRNN
Transform:
Backbone:
name: ResNet
layers: 34
Neck:
name: SequenceEncoder
encoder_type: rnn
hidden_size: 256
Head:
name: CTCHead
fc_decay: 0.00004
Loss:
name: CTCLoss
PostProcess:
name: CTCLabelDecode
Metric:
name: RecMetric
main_indicator: acc
Train:
dataset:
name: SimpleDataSet
data_dir: /civi/generate_chinese_license_plate-master/Save_Result/train_dataset
label_file_list: ["/civi/generate_chinese_license_plate-master/Save_Result/train_dataset.txt"]
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- RecAug:
- CTCLabelEncode: # Class handling label
- RecResizeImg:
image_shape: [3, 32, 320]
- KeepKeys:
keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
loader:
shuffle: True
batch_size_per_card: 200 # 256 训练_batch_size
drop_last: True
num_workers: 8
Eval:
dataset:
name: SimpleDataSet
data_dir: /civi/generate_chinese_license_plate-master/Save_Result/test_dataset
label_file_list: ["/civi/generate_chinese_license_plate-master/Save_Result/test_dataset.txt"]
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- CTCLabelEncode: # Class handling label
- RecResizeImg:
image_shape: [3, 32, 320]
- KeepKeys:
keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
loader:
shuffle: False
drop_last: False
batch_size_per_card: 200 # 256 测试_batch_size
num_workers: 8
注:着重关注以下几个参数:
use_gpu: true:使用GPU加速
epoch_num:epoch数目
save_model_dir:保存模型的地址
save_epoch_step:保存模型的间隔
data_dir:训练集和测试集图片的路径
label_file_list:训练集和测试集标签的路径
batch_size_per_card:训练集和测试集批大小
num_workers:线程数
④官方文档训练代码
# GPU训练 支持单卡,多卡训练
# 训练icdar15英文数据 训练日志会自动保存为 "{save_model_dir}" 下的train.log
#单卡训练(训练周期长,不建议)
python3 tools/train.py -c configs/rec/rec_icdar15_train.yml
#多卡训练,通过--gpus参数指定卡号
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_icdar15_train.yml博主使用的是单卡训练:
# -c 表示yml文件的路径
python3 ./tools/train.py -c /civi/generate_chinese_license_plate-master/dic_plate.yml6--模型转换和推理
①官方文档代码:
# -c 后面设置训练算法的yml配置文件
# -o 配置可选参数
# Global.pretrained_model 参数设置待转换的训练模型地址,不用添加文件后缀 .pdmodel,.pdopt或.pdparams。
# Global.save_inference_dir参数设置转换的模型将保存的地址。
python3 tools/export_model.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml -o Global.pretrained_model=./ch_lite/ch_ppocr_mobile_v2.0_rec_train/best_accuracy Global.save_inference_dir=./inference/rec_crnn/-c:yml文件地址
Global.pretrained_model:best_accuracy文件的路径
Global.save_inference_dir:模型转换后存在的路径
②转换结果:


③使用转换后的模型预测新车牌图片

python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words_en/word_336.png" --rec_model_dir="./your inference model" --rec_image_shape="3, 32, 100" --rec_char_type="ch" --rec_char_dict_path="your text dict path"7--模型转换为onnx模型
①安装paddle2onnx
pip install paddle2onnx
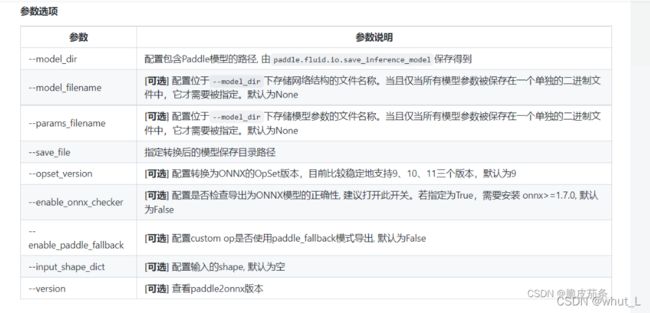
②终端执行代码
paddle2onnx --model_dir xx --model_filename model.pdmodel --params_filename model.pdiparams --opset_version 11 --save_file xx.onnx
--model_dir:存放pdmodel和pdiparams文件的路径
--save_file:存放onnx文件的路径
8--参考
paddle转换oonx
官方训练参考文档