PaddleOCR实现车牌识别系统
效果展示
如何实现
1.OpenCV环境:个人采用的是OpeCV-440-release版本,网上有很多相关教程
2.PaddleOCR: 这里需要3个文件

models:识别模型下载
paddle_inference_install_dir:预测库下载
PaddleOCR-release-2.0:PaddleOCR 2.0源码下载
models下载
预测库下载:2.0.0版本迅雷下载链接
***PaddleOCR-release-2.0:***
接下来在下图文件夹中建立一个build文件夹

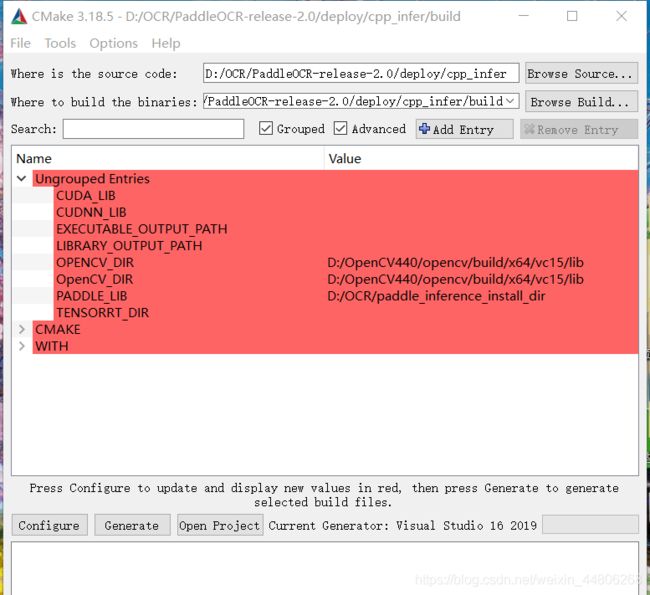
利用CMake编译PaddleOCR源码:添加好路径后,依次点击Configure,Genrate即可
点击ocr_system.sln进入项目中,将ocr_system设为启动项
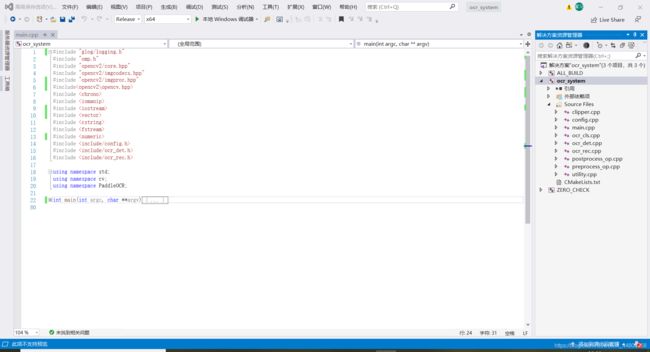
我简单修改了一下main函数,如果采用我的main函数记得同时将在ocr_rec.h和ocr_rec.cpp中的run函数参数列表末尾添加上vector
#include "glog/logging.h"
#include "omp.h"
#include "opencv2/core.hpp"
#include "opencv2/imgcodecs.hpp"
#include "opencv2/imgproc.hpp"
#include最后想要让我们的代码运行起来还需要一些条件
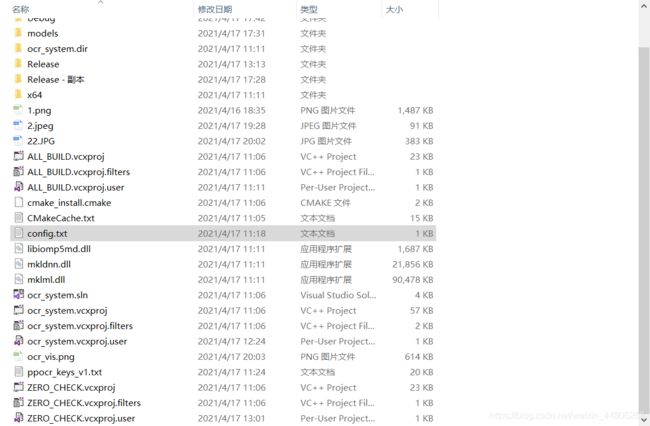
config.txt中需要修改三处位置,分别指向我们下载好的识别模型
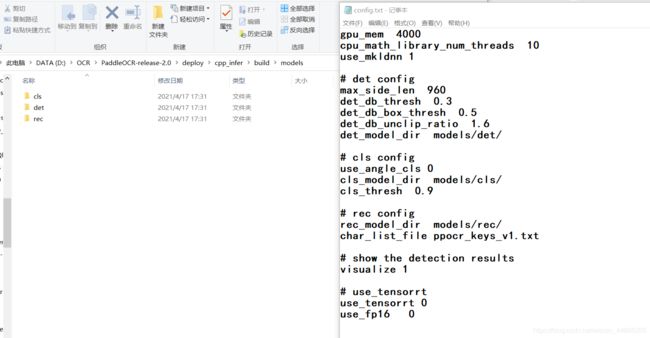
这里为了方便,我将三个模型名字改了一下,因为我将models和ppocr_keys_v1.txt都直接放入放入当前目录了,所以写的是相对路径。ppocr_keys_v1.txt在PaddleOCR-release-2.0\ppocr\utils下,最后我们添加需要识别的图片和在main函数里修改图片路径,点击运行就可以出现文章开头的识别效果啦
更多的功能可以在这基础上进行扩展,如UI,交互等
参考博客:https://blog.csdn.net/stq054188/article/details/114002913