实习踩过的那些坑1:数据抽取
python表格数据预处理
- 检验
- 常用表操作
-
- 信息读取
- 表备份
- 创建操作
-
- 遍历每一行
- 增加一行
- 创建空列
- 赋值
-
- 给某列满足条件的行赋值
- 一列拆成两列
- list一般是浅拷贝,需要深复制
- 删除操作
-
- 删除行
- 删除指定列
- 删除指定列为缺失值的那一行
- groupby后 仅保留指定列最小值所在行
-
- 保留最大最小列
- groupby字符串拼接
- 多表连接
-
- 单列连接
- 多列连接
- 两表拼接
-
- 列重命名
- 通过concat合并两个表
- 先投影再连接
- 正则表达式
-
- 转义字符
- ?< 表示以其开头
- 写抽取的例子
- split()函数:多个分隔符
- list查找包含所有某个字符串的项,并保存到一个新的列表
- 将时间标准化为时间字段
-
- 多种时间表达式的匹配
- 报错
-
- 1
- 2
检验
jupyter notebook可以通过TAB+SHIFT键,放句首是减少缩进的作用,放中间能看数据类型
无意间试探出来的嘿嘿嘿
常用表操作
信息读取
import pandas as pd
import codecs # 中文乱码
# 字段数据类型不一样,需要完善规范化
test = pd.read_csv(r"检验-精简.csv",encoding='gbk', dtype={"patient_SN": str})
表备份
参考:https://blog.csdn.net/cxj540947672/article/details/107539572
深复制
birthtime11 = birthtime1.copy(deep=True)
创建操作
遍历每一行
参考:https://blog.csdn.net/Jarry_cm/article/details/99683788
for row in birthtime1.itertuples():
增加一行
参考:https://blog.csdn.net/weixin_43938251/article/details/108256073
series = pd.Series({"x":1,"y":2},name="a")
data = data.append(series)
创建空列
在 Pandas DataFrame 中创建一个空列
参考:https://www.zhihu.com/question/505115458
第四种参考:
https://freexyz.cn/dev/23539.html
df["Empty_1"] = ""
df["Empty_2"] = np.nan
df['Empty_3'] = pd.Series()
df['Empty_4'] = None
它在 df 中创建三个空列。为 Empty_1 列分配空字符串,为 Empty_2 分配 NaN 值,为 Empty_3 分配一个空 Pandas Series,这也将导致整个 Empty_3 的值为 NaN。
Date Income Expenses Empty_1 Empty_2 Empty_3
0 April-20 10 3 NaN NaN
1 April-21 20 8 NaN NaN
2 April-22 10 4 NaN NaN
3 April-23 15 5 NaN NaN
4 April-24 10 6 NaN NaN
5 April-25 12 10 NaN NaN
中间遇到报错
ValueError: setting an array element with a sequence.
原因:
1,数组拼接的时候行或者列个数不对齐;
2,数据类型不对,如object,有的int,float,有的int32,int64
打印np.nan的类型,会发现np.nan是float类型的。
参考:https://freexyz.cn/dev/23539.html
改为
df['Empty_4'] = None
问题得以解决
赋值
给某列满足条件的行赋值
参考:https://blog.csdn.net/snail82/article/details/104584145
对DataFrame某列部分行成功赋值
df.loc[df['a']==2,'b'] = 10
print(df)
一列拆成两列
DataFrame一列拆成多列以及一行拆成多行
参考:https://blog.csdn.net/Asher117/article/details/84346073
将City列转成多列(以‘|’为分隔符)
这里使用匿名函数lambda,来将City列拆成两列。

df1["PATIENT_ID"] = df1["就诊标识(医渡云计算)"].map(lambda x:x.split('|')[2])
df1["VISIT"] = df1["就诊标识(医渡云计算)"].map(lambda x:x.split('|')[3])
list一般是浅拷贝,需要深复制
删除操作
删除行
参考:https://blog.csdn.net/m0_52829559/article/details/119063896
# 删除多个索引,1和2的行
dftest = df.drop([1,2],axis = 0)
删除指定列
df.drop('columns',axis=1,inplace=True) #改变原始数据
删除指定列为缺失值的那一行
(1)如果字段是float
time1.drop(time1[np.isnan(time1['检验标本采样时间'])].index, inplace=True)
(2)如果字段是str
time1 = time1[time1['检验标本采样时间'].notna()]
# print(time1)
(3)删除缺失值“失败”
(后来发现是删除后又赋值了,无语)
参考:https://zhuanlan.zhihu.com/p/136281253
因为这里的nan实际是一个空字符串,.dropna在使用时并不会将空字符串当作缺失值处理。
方法1(推荐)
#用replace将字符串nan替代为真正的缺失值np.nan,再进行.dropna
salesDf.replace("nan",np.nan,inplace=True)
salesDf=salesDf.dropna(subset=["销售时间","社保卡号"],how="any")
方法2
#用.isin筛选出任意一列为nan值的记录,再用~筛选出不在前面这些记录中的记录
salesDf=salesDf[~salesDf.isin (nan).any(axis=1)]
groupby后 仅保留指定列最小值所在行
参考:https://www.codenong.com/23394476/
# 按diff升序排序,然后获取每个item组中的第一个元素
time4 = time3.sort_values("diff",ascending = True).groupby(["patient_SN","检验子项名称"], as_index=False).head(1)
保留最大最小列
参考:https://blog.csdn.net/KIKI_ZSH/article/details/124548025
data1 = data.groupby('course').apply(lambda t: t[(t['grade']==t['grade'].min()) ^ (t['grade']==t['grade'].max())])
groupby字符串拼接
利用groupby分组后,对字符串字段进行合并拼接
参考:https://blog.csdn.net/d1240673769/article/details/106038811
https://blog.csdn.net/BUNNYGG/article/details/121485791
如,将下面表格中的内容,对skill字段按照id进行分组合并

data=df.groupby('id')['skill'].apply(lambda x:x.str.cat(sep=':')).reset_index()

参考:https://blog.csdn.net/weixin_40161254/article/details/104796953

df.groupby('user_id')['practice_name'].apply(list).reset_index()

这个链接很有意思
https://blog.csdn.net/qq_41706810/article/details/106060905
多表连接
参考:https://blog.csdn.net/lost0910/article/details/104814860
连接在一起,主要分为两类:
1)第一类:将两个pandas表根据一个或者多个键(列)值进行连接。这种操作类似关系数据库中sql语句的连接操作。这一类操作在使用pandas的merge、join操作来实现。
birthtime2 = pd.merge(birthtime1,birthtime0, on='patient_SN',how='inner')
这里还有其他一些可选项,比如left, right, outer
2)第二类:将两个pandas表在轴向上(水平、或者垂直方向上)进行粘合或者堆叠。这一类操作在使用pandas的concat、append操作来实现。
单列连接
time2 = pd.merge(testdata,birthtime, on='patient_SN')
多列连接
参考:https://blog.csdn.net/fightingoyo/article/details/106573221
birthtime0 = pd.merge(df1,birthtime, on=['PATIENT_ID',"VISIT"])
两表拼接
表1:列就诊标识(医渡云计算)、分娩时间
表2:列就诊标识(医渡云计算)、手术开始时间
想要效果:如果第一个表中没有记录,则增加第二个表的时间
# 合并检验的手术时间和分娩时间
jiuzhen_identity = list(set(birthtime0['就诊标识(医渡云计算)'])) # 分娩时间的保存就诊标识
birthtime11 = birthtime1[~birthtime1['就诊标识(医渡云计算)'].isin(jiuzhen_identity)] # 仅保留手术中不包含分娩SN
列重命名
#inplace=True是在原df上直接修改
birthtime1.rename(columns={'手术开始时间':'分娩时间'}, inplace = True)
通过concat合并两个表
birthtime12 = pd.concat([birthtime11,birthtime0])# 通过concat合并两个表
先投影再连接
1、MemoryError: Unable to allocate 16.9 GiB for an array with shape (2266018830,) and data type int64
表全连接时内存不够了,可以先表投影,然后连接时分列、行进行表连接
正则表达式
转义字符
python-pandas dataframe正则筛选包含某字符串的列数据str.contains()
str.contains()不直接支持对象里边的括号,因为括号是正则表达式之一。
如果想匹配元字符本身或者正则中的一些特殊字符,使用\转义。例如匹配*这个字符则使用*,匹配\这个字符,使用\。
需要转义的字符:$, (, ), *, +, ., [, ], ?, , ^, {, }, |
?< 表示以其开头
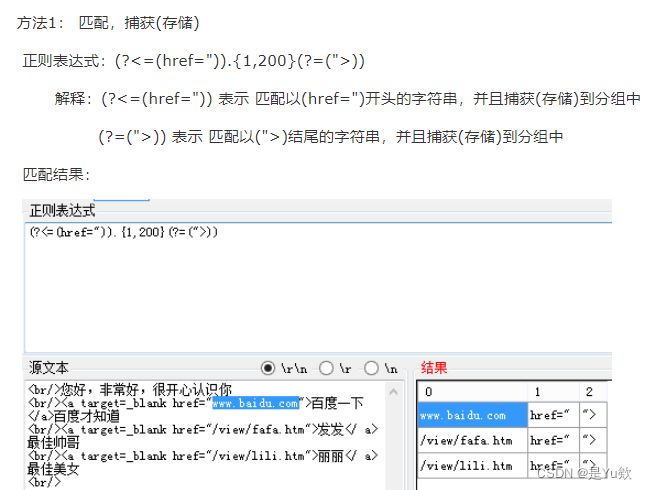
写抽取的例子
一个表达式对应一个例子
split()函数:多个分隔符
参考:https://blog.csdn.net/zhuzuwei/article/details/78886662
re模块的split()函数可以使用多个分隔符对句子进行分割,其中不同的分隔符要用 “|” 隔开。
import re
re.split('。|!|?',text)
Out[67]: ['你好', '吃早饭了吗', '再见', '']
list查找包含所有某个字符串的项,并保存到一个新的列表
参考:https://blog.csdn.net/weixin_41955821/article/details/110457849
data=['aaaaaFFa','ccccccc','bbbbFF']
l = [s for s in data if 'FF' in s]
l
输出:
['aaaaaFFa', 'bbbbFF']
将时间标准化为时间字段
time1['检验标本采样时间'] = time1['检验标本采样时间'].apply(lambda x: datetime.strptime(str(x),'%Y-%m-%d %H:%M:%S'))
time2['检验标本采样时间'] = time2['检验标本采样时间'].apply(lambda x: datetime.strptime(str(x),'%Y/%m/%d %H:%M'))
time1['分娩时间'] = time1['分娩时间'].apply(lambda x: datetime.strptime(x,'%Y年%m月%d日 %H时%M分'))
报错:
ValueError: time data ‘2021/2/18’ does not match format ‘%Y/%m/%d %H:%M’
解决:

time2['检验标本采样时间'] = pd.to_datetime(time2['检验标本采样时间'], infer_datetime_format=True)
多种时间表达式的匹配
① 先做个正则表达式匹配,把年月日换成-
chuyuan['分娩时间'] = chuyuan['分娩时间'].apply(lambda x:re.sub("年|月|日",'-',x))
②然后强制转换为时间格式
chuyuan['分娩时间'] = pd.to_datetime(chuyuan['分娩时间'], infer_datetime_format=True)
报错
1
shunchan = shunchan_flag1["就诊标识(医渡云计算)"]+shunchan_flag2["就诊标识(医渡云计算)"])
发现数据比预期少很多
list1+list2后,数据更少,存在问题
而后改为extend
shunchan = shunchan_flag1["就诊标识(医渡云计算)"].extend(shunchan_flag2["就诊标识(医渡云计算)"])
报错
‘Series’ object has no attribute ‘extend’
因此’Series’ 拼接
参考:https://blog.csdn.net/weixin_43387909/article/details/116596095
df_data = pd.concat([df.a,df.b,df.c], axis=1)
备注:
1、concat中括号里得内容必须是series格式的,如果想要拼接的是list可以将list转为series(pd.Series(list1)),如果是纵向拼接,list可以直接用+。
2、axis=1表示横向拼接,即不增加长度,只增加维度;
axis=0表示纵向拼接,即不增加维度,只增加长度;
2
报错:invalid syntax

lambda函数必须具有返回值,如果你的if语句不为true,则没有返回值。因此,你将必须添加else语句
添加else语句返回空值