机器学习笔记之条件随机场(五)条件随机场需要解决的任务介绍
机器学习笔记之条件随机场——条件随机场需要解决的任务介绍
- 引言
-
- 回顾:条件随机场
- 条件随机场要解决的任务
引言
上一节介绍了条件随机场的建模对象——条件概率 P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O)参数形式和向量形式的表示。本节将针对条件随机场面对的任务进行介绍。
回顾:条件随机场
条件随机场(Condition Random Field,CRF)是一种结合了最大熵模型(Maximum Entropy Model)和隐马尔可夫模型(Hidden Markov Model,HMM)特点的无向图模型。其概率图结构表示如下:
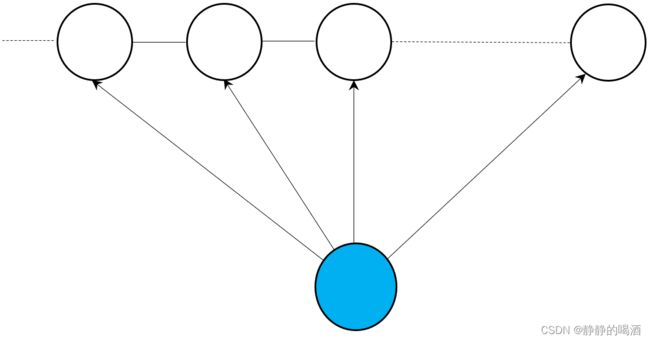
并且,它是一个概率判别模型,它的建模对象是关于隐变量的条件概率 P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O):
P ( I ∣ O ) = 1 Z exp [ ∑ t = 1 T − 1 ∑ m = 1 M λ m ⋅ s m ( i t + 1 , i t , O ) + ∑ t = 1 T ∑ l = 1 L η l ⋅ g l ( i t , O ) ] = 1 Z ( O , θ ) exp ⟨ θ , H ( i t + 1 , i t , O ) ⟩ { θ = ( λ 1 , ⋯ , λ M , η 1 , ⋯ , η L ) T H ( i t + 1 , i t , O ) = ( ∑ t = 1 T − 1 s ( i t + 1 , i t , O ) ∑ t − 1 T g ( i t , O ) ) \begin{aligned} \mathcal P(\mathcal I \mid \mathcal O) & = \frac{1}{\mathcal Z} \exp \left[\sum_{t=1}^{T-1} \sum_{m=1}^{\mathcal M} \lambda_m \cdot s_m(i_{t+1},i_t,\mathcal O) + \sum_{t=1}^{T} \sum_{l=1}^{\mathcal L} \eta_l \cdot g_l(i_t,\mathcal O)\right] \\ & = \frac{1}{\mathcal Z(\mathcal O,\theta)} \exp \left\langle \theta,\mathcal H(i_{t+1},i_t,\mathcal O)\right\rangle \quad \begin{cases} \theta = (\lambda_1,\cdots,\lambda_{\mathcal M},\eta_1,\cdots,\eta_{\mathcal L})^{T} \\ \mathcal H(i_{t+1},i_t,\mathcal O) = \begin{pmatrix} \sum_{t=1}^{T-1}s(i_{t+1},i_t,\mathcal O) \\ \quad \\ \sum_{t-1}^{T}g(i_t,\mathcal O) \end{pmatrix} \end{cases} \end{aligned} P(I∣O)=Z1exp[t=1∑T−1m=1∑Mλm⋅sm(it+1,it,O)+t=1∑Tl=1∑Lηl⋅gl(it,O)]=Z(O,θ)1exp⟨θ,H(it+1,it,O)⟩⎩⎪⎪⎪⎨⎪⎪⎪⎧θ=(λ1,⋯,λM,η1,⋯,ηL)TH(it+1,it,O)=⎝⎛∑t=1T−1s(it+1,it,O)∑t−1Tg(it,O)⎠⎞
并且,条件随机场打破了齐次马尔可夫假设和观测独立性假设,虽然没有脱离动态模型的范畴,但针对的目标是时间/序列状态转移过程有限的情况。例如:一条文本句子,一条蛋白质序列。
其中 s m ( i t + 1 , i t , O ) s_m(i_{t+1},i_t,\mathcal O) sm(it+1,it,O)被称作转移特征函数(Transition Feature Function), g l ( i t , O ) g_l(i_t,\mathcal O) gl(it,O)被称作状态特征函数(State Feature Function)。以词性标注的角度为例,描述这两个特征函数。
-
一个句子由词语组成,这些词语的词性在句子中存在关联关系。例如: The boy knocked at the watermelon \text{The boy knocked at the watermelon} The boy knocked at the watermelon(男孩敲了敲西瓜)。
-
我们需要定义合适的特征函数,来刻画数据的一些可能成立或者期望成立的经验特性。
当 t = 3 t=3 t=3时,此时的观测变量 o 3 o_3 o3为 knocked \text{knocked} knocked,而下一时刻的词语是介词 at \text{at} at。在条件随机场——背景介绍中提到特征函数通常是实值函数,因此当前时刻的状态特征函数 g l ( i 3 , O ) g_l(i_3,\mathcal O) gl(i3,O)表示如下:
这里忽略‘时态’的影响,并且[ V \mathcal V V]表示动词;[ P \mathcal P P]表示介词。
g l ( i 3 , O ) = { 1 if i 3 = [ V ] and o 3 = ′ knock ′ 0 otherwise g_l(i_3,\mathcal O) = \begin{cases} 1 \quad \text{if } i_3 = [\mathcal V] \text{ and } o_3 = '\text{knock}' \\ 0 \quad \text{otherwise} \end{cases} gl(i3,O)={1if i3=[V] and o3=′knock′0otherwise
很明显, i 3 = [ V ] and o 3 = ′ knock ′ i_3 = [\mathcal V] \text{ and } o_3 = '\text{knock}' i3=[V] and o3=′knock′描述了一种既定事实,只要满足该事实条件, g l ( i 3 , O ) g_l(i_3,\mathcal O) gl(i3,O)才有它的存在价值。同理,关于两个隐变量共同作用的转移特征函数 s m ( i 4 , i 3 , O ) s_m(i_4,i_3,\mathcal O) sm(i4,i3,O)表示如下:
和状态特征函数类似,当“当前词语的词性是动词”且“下一个词语的词性是介词”,并且当前单词是knock \text{knock} knock时,该特征函数被启用。对应产生价值的大小由对应特征函数的参数λ m , η l \lambda_m,\eta_l λm,ηl决定。
s m ( i 4 , i 3 , O ) = { 1 if i 4 = [ P ] , i 3 = [ V ] and o 3 = ′ knock ′ 0 otherwise s_m(i_4,i_3,\mathcal O)= \begin{cases} 1 \quad \text{if } i_4 = [\mathcal P],i_3 = [\mathcal V] \text{ and } o_3 = '\text{knock}'\\ 0 \quad \text{otherwise}\end{cases} sm(i4,i3,O)={1if i4=[P],i3=[V] and o3=′knock′0otherwise
条件随机场要解决的任务
条件随机场作为一个概率图模型,其主要任务主要分为两个部分:
-
学习任务(Learning),主要针对模型参数进行求解。(Parameter Estimation)
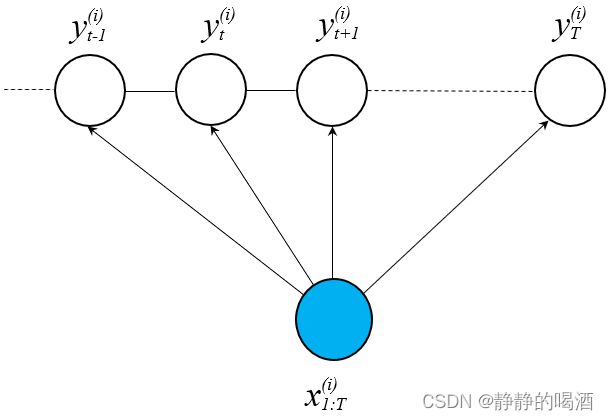
对于条件随机场的学习任务,可以将其理解为:给定训练数据集 D \mathcal D D:样本/标签维度均是T T T,即样本维度和条件随机场建模的‘序列/时间长度相同’。不要和‘转置符号’弄混;从真实样本的角度观察,样本x ( i ) x^{(i)} x(i)可能是某一个句子,一个序列,而不是一个单词,一个氨基酸;对应的标签y ( i ) y^{(i)} y(i)可能是‘每个单词的词性标注组成的序列’。各样本之间属于‘独立同分布’,各样本之间不存在关联关系。
D = { ( x ( i ) , y ( i ) ) } i = 1 N x ( i ) , y ( i ) ∈ R T x ( i ) = ( x 1 ( i ) , x 2 ( i ) , ⋯ , x T ( i ) ) T → x 1 : T ( i ) y ( i ) = ( y 1 ( i ) , y 2 ( i ) , ⋯ , y T ( i ) ) T \begin{aligned} \mathcal D & = \{(x^{(i)},y^{(i)})\}_{i=1}^{N} \quad x^{(i)},y^{(i)} \in \mathbb R^T \\ x^{(i)} & = \left(x_1^{(i)},x_2^{(i)},\cdots,x_T^{(i)}\right)^T \to x_{1:T}^{(i)}\\ y^{(i)} & = \left(y_1^{(i)},y_2^{(i)},\cdots,y_T^{(i)}\right)^T \end{aligned} Dx(i)y(i)={(x(i),y(i))}i=1Nx(i),y(i)∈RT=(x1(i),x2(i),⋯,xT(i))T→x1:T(i)=(y1(i),y2(i),⋯,yT(i))T
对应图像示例如下:
对于最优参数 θ ^ \hat {\theta} θ^的估计表示如下:
其朴素思想在于:希望预测的标签序列y y y能够与对应的样本x x x最大程度的匹配,即P ( y ∣ x ) \mathcal P(y \mid x) P(y∣x)越大越好。并且各样本之间独立同分布,因此在学习过程中,模型参数的评价标准就是对‘数据集合内’的所有样本的P ( y ∣ x ) \mathcal P(y \mid x) P(y∣x)都达到最大。
θ ^ = arg max θ ∏ i = 1 N P ( y ( i ) ∣ x ( i ) ) \begin{aligned} \hat {\theta} = \mathop{\arg\max}\limits_{\theta} \prod_{i=1}^N \mathcal P \left(y^{(i)} \mid x^{(i)}\right) \end{aligned} θ^=θargmaxi=1∏NP(y(i)∣x(i)) -
对于未知变量的推断任务(Inference):
在概率图模型——推断基本介绍中提到过关于推断的描述。- 通过联合概率分布,对边缘概率分布进行求解 (Marginal Probability):
P ( i t ∣ O ) = ∑ i 1 , ⋯ , i t − 1 , i t + 1 , ⋯ , i T P ( I ∣ O ) \mathcal P(i_t \mid \mathcal O) = \sum_{i_1,\cdots,i_{t-1},i_{t+1},\cdots,i_T}\mathcal P(\mathcal I \mid \mathcal O) P(it∣O)=i1,⋯,it−1,it+1,⋯,iT∑P(I∣O)
从样本角度观察,可以看作:给定一条完整句子序列的条件下,对句中某一单词词性的条件概率进行求解:
P ( y t ( i ) ∣ x 1 : T ( i ) ) \mathcal P(y_t^{(i)} \mid x_{1:T}^{(i)}) P(yt(i)∣x1:T(i)) - 求解条件概率分布(Conditional Probability):
I = I A ∪ I B → P ( I A ∣ I B ) \mathcal I = \mathcal I_{\mathcal A} \cup \mathcal I_{\mathcal B} \to \mathcal P(\mathcal I_{\mathcal A} \mid \mathcal I_{\mathcal B}) I=IA∪IB→P(IA∣IB)
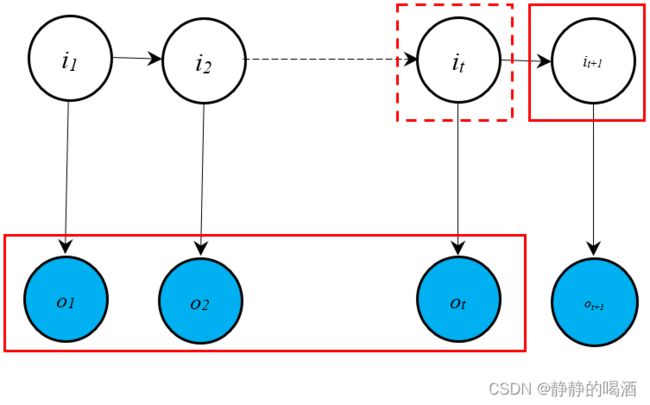
由于条件随机场是概率判别模型,求解条件概率主要针对概率生成模型,对于概率判别模型基本没有意义。例如隐马尔可夫模型中的预测任务(Prediction):
齐次马尔可夫假设~
P ( i t + 1 ∣ o 1 , ⋯ , o t ) = ∑ i t P ( i t + 1 , i t ∣ o 1 , ⋯ , o t ) = ∑ i t P ( i t + 1 ∣ i t , o 1 , ⋯ , o t ) ⋅ P ( i t ∣ o 1 , ⋯ , o t ) = ∑ i t P ( i t + 1 ∣ i t ) ⋅ P ( i t ∣ o 1 , ⋯ , o t ) \begin{aligned} \mathcal P(i_{t+1} \mid o_1,\cdots,o_t) & = \sum_{i_t} \mathcal P(i_{t+1},i_t \mid o_1,\cdots,o_t) \\ & = \sum_{i_t} \mathcal P(i_{t+1} \mid i_t,o_1,\cdots,o_t) \cdot \mathcal P(i_{t} \mid o_1,\cdots,o_t) \\ & = \sum_{i_t} \mathcal P(i_{t+1} \mid i_t) \cdot \mathcal P(i_t \mid o_1,\cdots,o_t) \end{aligned} P(it+1∣o1,⋯,ot)=it∑P(it+1,it∣o1,⋯,ot)=it∑P(it+1∣it,o1,⋯,ot)⋅P(it∣o1,⋯,ot)=it∑P(it+1∣it)⋅P(it∣o1,⋯,ot)
此时,将预测任务转化为滤波任务(Filtering)。对应概率图描述表示如下:
- 最大后验概率推断(MAP Inference):主要针对解码任务(Decoding),依然以隐马尔可夫模型的解码任务为例,在求解 P ( I ∣ O ) = P ( i 1 , ⋯ , i T ∣ o 1 , ⋯ , o T ) \mathcal P(\mathcal I\mid \mathcal O) = \mathcal P(i_1,\cdots,i_T \mid o_1,\cdots,o_T) P(I∣O)=P(i1,⋯,iT∣o1,⋯,oT)过程中,需要求解一组适合的状态序列 I ^ \hat {\mathcal I} I^,使得后验概率 P ( I ^ ∣ O , λ ) \mathcal P(\hat {\mathcal I} \mid \mathcal O,\lambda) P(I^∣O,λ)最大:
I ^ = arg max I P ( I ^ ∣ O , λ ) \hat {\mathcal I} = \mathop{\arg\max}\limits_{\mathcal I} \mathcal P(\hat{\mathcal I} \mid \mathcal O,\lambda) I^=IargmaxP(I^∣O,λ)
但实际求解过程并没有直接对 P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O)进行求解,而是通过 维特比算法 求解 相邻时刻下,状态变量取值的联合概率分布之间的关系:
δ t ( k ) = max I t − 1 P ( O , I t − 1 , i t = q k ∣ λ ) δ t + 1 ( j ) = max I t P ( O , I t , i t + 1 = q j ∣ λ ) δ t ( k ) ⇔ ? δ t + 1 ( j ) \begin{aligned} \delta_t(k) & = \mathop{\max}\limits_{\mathcal I_{t-1}} \mathcal P(\mathcal O,\mathcal I_{t-1},i_t = q_k \mid \lambda) \\ \delta_{t+1}(j) & = \mathop{\max}\limits_{\mathcal I_t}\mathcal P(\mathcal O,\mathcal I_t,i_{t+1} = q_j \mid \lambda) \\ \delta_t(k) & \overset{\text{?}}{\Leftrightarrow}\delta_{t+1}(j) \end{aligned} δt(k)δt+1(j)δt(k)=It−1maxP(O,It−1,it=qk∣λ)=ItmaxP(O,It,it+1=qj∣λ)⇔?δt+1(j)
这种将 P ( I ∣ O , λ ) \mathcal P(\mathcal I \mid \mathcal O,\lambda) P(I∣O,λ)的问题转化为 P ( I , O ∣ λ ) \mathcal P(\mathcal I,\mathcal O \mid \lambda) P(I,O∣λ)的问题,用到了最大后验概率(Maximum a posteriori Probability,MAP)的思想:
I ^ = arg max I P ( I ∣ O , λ ) = arg max I P ( I , O ∣ λ ) P ( O , λ ) ∝ arg max I P ( I , O ∣ λ ) \begin{aligned} \hat {\mathcal I} & = \mathop{\arg\max}\limits_{\mathcal I} \mathcal P(\mathcal I \mid \mathcal O,\lambda) \\ & = \mathop{\arg\max}\limits_{\mathcal I} \frac{\mathcal P(\mathcal I,\mathcal O \mid \lambda)}{\mathcal P(\mathcal O,\lambda)} \\ & \propto \mathop{\arg\max}\limits_{\mathcal I} \mathcal P(\mathcal I,\mathcal O\mid \lambda) \end{aligned} I^=IargmaxP(I∣O,λ)=IargmaxP(O,λ)P(I,O∣λ)∝IargmaxP(I,O∣λ)
对于条件随机场,它的解码任务即:找到一条合适的词性标注序列 Y ^ \hat {\mathcal Y} Y^,使得 P ( Y ^ ∣ X ) \mathcal P(\hat {\mathcal Y} \mid \mathcal X) P(Y^∣X)达到最大。其中 X \mathcal X X表示一个句子样本。数学符号表达如下:
Y ^ = arg max Y = ( y 1 , ⋯ , y T ) T P ( Y ∣ X ) \hat {\mathcal Y} = \mathop{\arg\max}\limits_{\mathcal Y = (y_1,\cdots,y_T)^T} \mathcal P(\mathcal Y \mid \mathcal X) Y^=Y=(y1,⋯,yT)TargmaxP(Y∣X)
- 通过联合概率分布,对边缘概率分布进行求解 (Marginal Probability):
下一节将详细介绍条件随机场的推断任务。
相关参考:
机器学习-周志华著
机器学习-条件随机场(6)-CRF模型-要解决的问题