浅谈CVPR2022 Traffic Line

" Paper Sharing - Traffic Line"
CVPR 2022 刚刚结束,而我最近一段时间一直在进行Traffic Line 相关的工作,所以趁着热度跟大家聊一聊CVPR 2022 中关于Traffic Line 相关的论文。这次主要挑选我认为比较有意思的一些Paper来跟大家分享一下。
by 元戎感知组 Kivi·Wong
01
《Rethinking Efficient Lane Detection via Curve Modeling》
摘要
目前车道线处理方案包含以下三大类:
| Keypoint-base Method:类似于物体检测的方式,将车道线看成由若干关键点组成的线,然后进行关键点检测。例如:Line-CNN[1]、LaneATT[2]
|Segmentation-base Method:这种方式将车道线标注为图像分割,通过图像分割的方式进行车道线检测。例如:HDMapNet[3]
|Curve-base Method: 首先预定义曲线模型,通过对曲线模型的学习来获取图像中的车道线表示。例如:PolyLaneNet[4]
目前主流的方法是Keypoint-base Method和Segmentation-base Method,基于Curve-base Method的方法在性能上落后于其他的两类方法。在此基础上,作者认为主要的原因在于基于多项式的曲线参数形式很难被学习。
面对上述的情况,作者提出了一个问题,Curve-base相关方法是否有可能达到SOTA的水平?
作者观察到,贝塞尔曲线模型有足够的参数自由度,能够表征驾驶场景中的车道线线型。该曲线模型具有计算复杂性低、高稳定等优势,并且曲线参数模型拟合的方式也可以避免其他冗余的后处理(例如NMS)以及手动设计Anchor。这些优势都使得整体模型能够更加简洁高效。
本篇文章作者主要有两点创新点:
1. 提出了基于贝塞尔曲线拟合的车道检测方法
2. 提出了基于可变形卷积的特征反转融合模块
论文方法
贝塞尔曲线方程可由下式定义,曲线中的每个点均由多个控制点递归组合而确定。作者在实验过程发现,取n=3基本满足车道线的拟合需求。
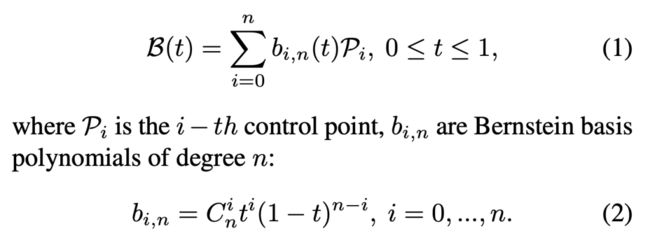
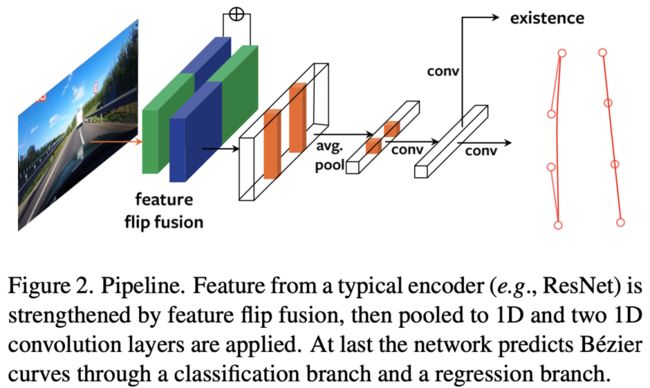
作者整个网络结构的设计由下图所示,首先利用一个特征网络(例如ResNet)对输入图像进行特征提取,然后经过特征翻转融合,并进行pooling操作,最后送入到分类分支和回归分支。
特征反转融合
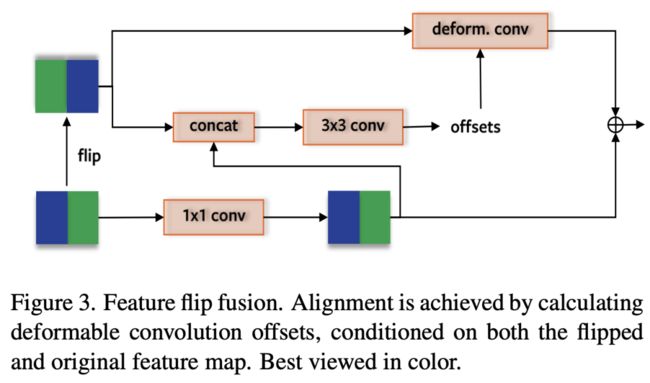
作者发现,对于前装摄像头而言,所看到路面的车道线,往往具备一定的对称性。例如:如果左边看到了一条车道线,往往对称的右边也会有一条。所以作者认为可以利用这个特征,进行对称的特征加强。当然,为了兼容可能出现的不对称现象(例如:转弯、变道、线段不成对),作者使用了可变形卷积来进行一个偏置情况的学习。
Loss 的设定
在loss这块,作者使用在Ground Truth Curve 与Predict Curve 内做等间距插点,并利用这些点做L1 Error的方式作为模型训练的回归Loss。整体表达式如下

作者提出,类似于ABCNet[4] 中利用控制点之间的L1 Error 会出现控制点之间差距大,而生成的曲线差距小的情况。如下图(a) 所示,所以作者选用了下图(b)的方式进行Loss计算。并且,对比与经典的多项式回归算法中采用的等y值采样,这种方式能够避免由于线段错位而引起的额外loss计算,如下图(c)所示。

实验结果

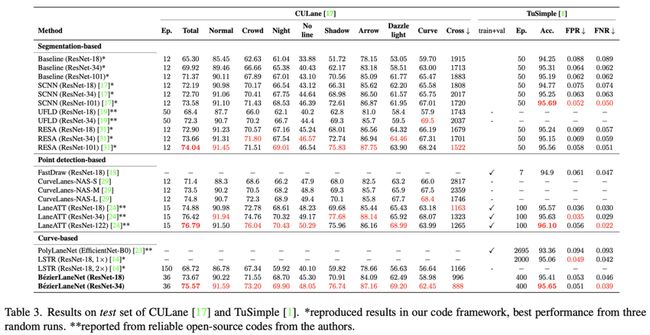
作者在TuSimple(见上表)、CULane(见上表)、LLAMAS(见下表)等数据集上均做了对比实验
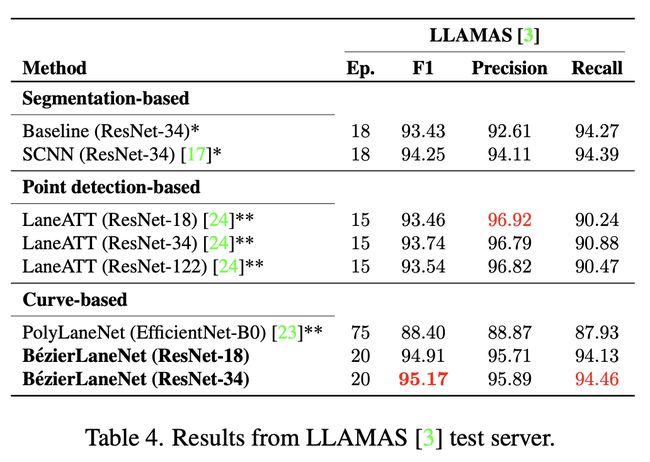
从整体的实验结果来看,作者提出的方法在精度表现上并不惊艳。单看最优的模型结果设计,与一年前的LaneATT 在不同指标上平分秋色。不过当我们连同模型速度一起比较时,不难发现,得益于模型后处理的简洁,其FPS相较于同等结构的其他模型要高出一大截。当我们将FPS大致相同的BezierLaneNet(ResNet-34)与LaneATT(ResNet-18)进行精度比较时,可以发现BezierLaneNet 还是具备了一定的优势。

结论
本篇论文探索了一种新的基于贝塞尔曲线拟合的车道线检测方式,并且证明其性能表现能够达到与其他类型的方式相近的程度。论文中实验结论给Curve-base 相关方法的研究指出了一条新的方向,在Curve-base 方法中,一个易于拟合的曲线模型对整个算法精度的影响更为关键。
02
《VectorMapNet: End-to-end Vectorized HD Map Learning》
摘要
对于环境的感知理解是自动驾驶领域关键的一环。现行大多数方法采用密集栅格化分割预测(Dense Rasterized Segmentation Predictions)的方式进行环境感知。这种方式常常由于没有包含实例信息而要求进行复杂的后处理。由于上述的原因,作者提出了一种E2E的Semantic Map Leaning方法,称之为VectorMapNet。
本篇论文中,作者核心的贡献点在于:提出了VectorMapNet方法,并设计了Map Element Detector模块和Polyline Generator模块,能够兼容交通环境中多种不同类型的地图元素感知。
论文方法
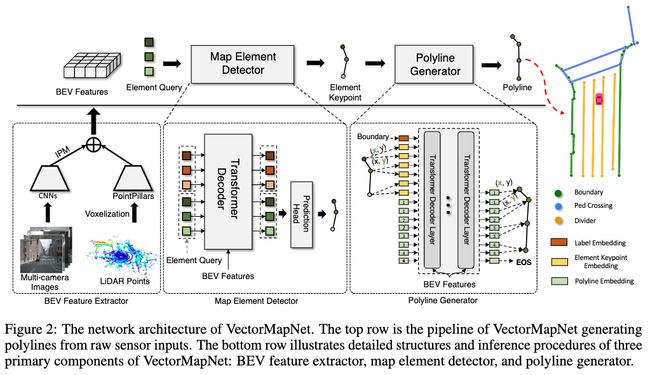
在特征提取的部分,作者延续了HDMapNet[3]的方式,利用Image Feature 与Lidar Feature 融合而成的BEV Feature 作为整个网络的特征部分。与前者不同的是,这里Image Feature 采用了IPM的方式,利用多个不同高度的地平面投影得到多个不同Channel的Feature 再与Lidar Feature 进行融合。
在Map Element Detector部分,作者实际上采用了DETR相同的结构。作者利用这个结构来预测Map Element 的Keypoint 序列和Type类别。在训练的过程中,作者使用了二分图匹配的方式来作为Ground Truth和Prediction的匹配方式。
这里可以着重提一点的是关于作者使用的Map Element Keypoint的表示方式。作者提出了如下三种描述Map Element的形式,1) Bounding Box,最小的包围盒,由左下角点和右上焦点构成;2)SME(Start-Middle-End), 包含起始点、中间点和结束点。3)Extreme Points,由最上点、最下点、最左点和最右点构成。

Map Element Detector 输出的Keypoints会做转换为两个Embedding形式。第一个是Position Embedding,用于指示keypoint在keypoints序列中的位置,第二个是Embedding用于指示关键点属于哪个Map Element。
Map Element Detector输出的Keypoints及Type 将联合BEV Feature 一并被送入PolyLine Generator中,用于生成最终的Polyline表示,对于最后的Polyline生成方式,也遵循PolyGen[5]的方式,由三个Embedding来表示每个Token,1)Coordinate embedding,表示值代表的是x轴还是y轴;2)Position embedding, 表示其所属的顶点;3)Value Embedding,表示其具体的值。
实验结果
作者在nuScenes上进行了对比实验。从指标精度上来看VectorMapNet的性能相较于上一版HDMapNet有比较大的性能提升,尤其在Ped Crossing和Divider这两个分类上面。
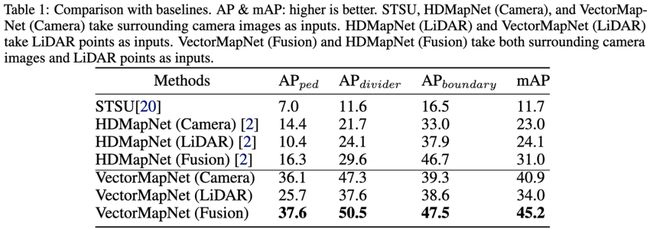
 VectorMapNet主要能够实现性能提升的原因在于Polyline的表示形式降低了对于Map Element编码的难度,其可以学习到整个Map Element之间的几何特性,而基于Segmentation形式的Pixel-Wise Feature很难做到这一点,并且在实际环境中,相同类型的Map Element的形状是多变的(如下图红色圈所示);其次是Polyline 的表示形式避免了具有歧义的结果,其生成的Line本身具有方向性,从而也能够避免产生环的可能(如下图蓝色圈所示)。
VectorMapNet主要能够实现性能提升的原因在于Polyline的表示形式降低了对于Map Element编码的难度,其可以学习到整个Map Element之间的几何特性,而基于Segmentation形式的Pixel-Wise Feature很难做到这一点,并且在实际环境中,相同类型的Map Element的形状是多变的(如下图红色圈所示);其次是Polyline 的表示形式避免了具有歧义的结果,其生成的Line本身具有方向性,从而也能够避免产生环的可能(如下图蓝色圈所示)。

结论
本篇论文提出了一种E2E的Map Element检测方式,这种方式能够减少额外的后处理开销,并且通过Transformer能够建立不同Map Element之间的联系,对最终结果形成相互促进作用。除此之外,由于所有的Map Element均通过Polyline的形式进行表示,能够同时兼容交通环境中Line Type和Area Type两种不同类型的元素,让整个处理过程变得简单有效。
最后聊两句
行业发展与学术研究之间密不可分,行业发展过程不断的挖掘出具有价值意义的技术难题,学术研究的不断深入能够为产业发展所遇到的难题提供技术解决方案。本次CVPR 2022 还有很多优秀的文章值得大家阅读学习,也欢迎大家一起学习、一起探讨。
引用文章
[1] Xiang Li, Jun Li, Xiaolin Hu, and Jian Yang. Line-cnn: End-to-end traffic line detection with line proposal unit. ITS, 2019.
[2] Lucas Tabelini, Rodrigo Berriel, Thiago M Paixao, Claudine Badue, Alberto F De Souza, and Thiago Oliveira-Santos. Keep your eyes on the lane: Real-time attention-guided lane detection. In CVPR, 2021
[3] Li, Q., Wang, Y., Wang, Y. and Zhao, H., 2021. Hdmapnet: A local semantic map learning and evaluation framework. arXiv preprint arXiv:2107.06307.
[4]Yuliang Liu, Hao Chen, Chunhua Shen, Tong He, Lianwen Jin, and Liangwei Wang. Abcnet: Real-time scene text spot- ting with adaptive bezier-curve network. In CVPR, 2020.
[5]C. Nash, Y. Ganin, S. A. Eslami, and P. Battaglia. Polygen: An autoregressive generative model of 3d meshes. In International Conference on Machine Learning, pages 7220–7229. PMLR, 2020.