ViT解读
ViT
-
- 0 前言
- 1 Transformer
-
- encoder
- decoder
- 2 ViT
- 3 总结
0 前言
Transformer被广泛使用在nlp领域,在处理序列化数据方面具有优势,最初提出的论文是attention is all you need 。之后不断有一些将其用在cv领域的工作,ViT便是最新的工作之一,结构中只使用了transformer,并且在分类方面取得不错的效果。这里对其做简单的记录总结。
1 Transformer
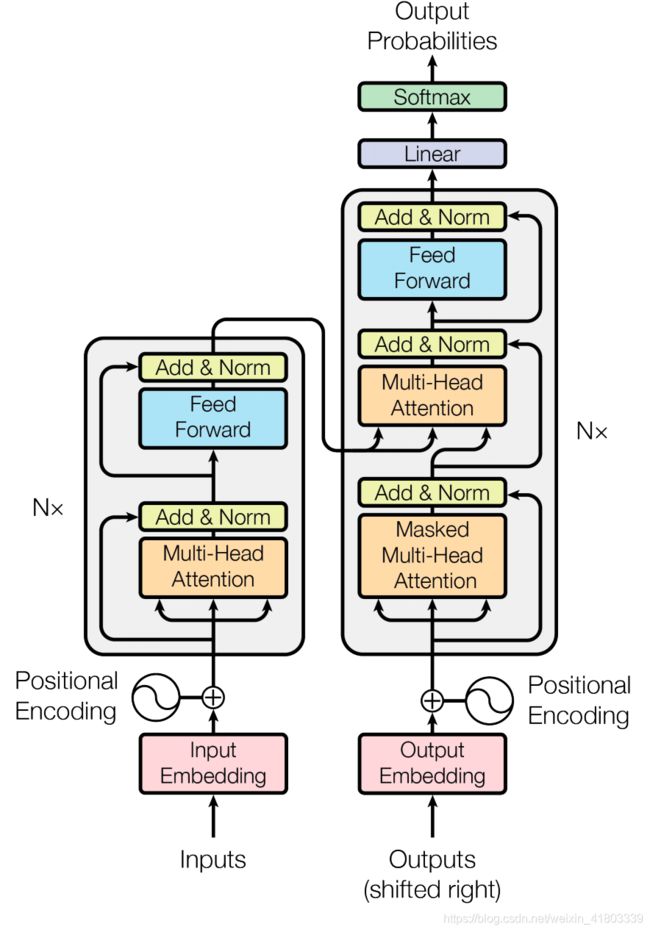
论文的核心就是在这张图,结构包括了encoder和decoder两个部分。
encoder
其中encoder的基础结构包括多头注意力模块和前馈网络两个部分,inputs是词向量+位置编码。然后将其分为Q、K、V三个矩阵,其中Q和K生成attention的权重矩阵,随后和V矩阵相乘。Q和K生成attention的权重矩阵的方式是Q乘K的转制在除以根号下head的设定纬度d,称为scale操作,除这个玩意的原因是QK点乘的值可能很大,如果直接经过后续的softmax可能会导致梯度消失。后面就是标准化norm和残差操作了。在nlp中使用的norm方式是LN,因为BN和batch的纬度有关系,而nlp中的batch是动态变化的,所以用BN无法很好的统计均值方差,标准化效果较差。前馈网络就是简单的mlp,也就是全连接神经网络。
decoder
decoder部分相对encoder加了mask muti-head attention,mask的原因是预测阶段是一个词一个词预测的,所以encoder是一次执行,而decoder是循环的,类似于RNN。比如encoder直接输入“我爱你”,decoder先生成I再生成love最后生成you。要注意的是decoder的muti-head attention中的Q和K用的是encoder生成的,这就是encoder和decoder的交互操作。其他就是norm和残差,以及前馈网络。decoder可能理解的比较表面,因为本身对nlp的训练理解不深入,但大致的理解是正确的。
2 ViT
ViT论文中开篇直接表明:transform经常被用在nlp任务中,但是用在cv中还有一些限制。在cv中,attention经常和CNN结合起来一起使用。我们提出这种是没有必要的,可以直接序列化图像数据,然后全部使用transform来搭建网络结构,并且能够在图像分类任务中取得很好的结果。

如上图所示,只用了transform的encoder结构,将图片网格化,每个网格进行序列化,也就是flatten操作,然后加上可学习的位置嵌入参数,然后进入transform encoder,过程中在训练中多加一纬向量class token用作后续的分类,其他没有啥好说的,直接放代码,代码中我也加了注释。
import torch
from torch import nn, einsum
import torch.nn.functional as F
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
# helpers
def pair(t):
return t if isinstance(t, tuple) else (t, t)
# classes
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class FeedForward(nn.Module):
'simple fully connected layer structure'
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class Attention(nn.Module):
"muti-head self attention"
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
b, n, _, h = *x.shape, self.heads
qkv = self.to_qkv(x).chunk(3, dim = -1)
#扩充维度后在最后一个维度划分为3份。
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = h), qkv)
dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale # softmax(Q乘以K的转置除以根号下dim_head)
attn = self.attend(dots) # softmax
out = einsum('b h i j, b h j d -> b h i d', attn, v)#这里的einsum就是矩阵乘法
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out) # 由回到输入之前的维度
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim,
pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
# dim是图像网格化后每一个网格序列化后需要统一到一个相同的序列化长度
# depth是transform里面encoder的堆叠数量
# heads是multi-head attention里面的head数量, dim_head是每个head里面的qkv长度
# mlp_dim是前向网络里面的隐藏层的tersor长度
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_height // patch_height) * (image_width // patch_width)
# num_patches是将图片网格化后网格的数量
patch_dim = channels * patch_height * patch_width
# patch_dim是将图片网格化后每一个网格序列化的长度
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.Linear(patch_dim, dim),
) # 输出的维度是(b, h*w, dim)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity() # nn.Identity是用来占位的
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
# n是每一个网格的h*w
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
# cls_tokens在batch维度进行扩充
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
x = self.transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)
if __name__ == "__main__":
test_input = torch.randn((2,3,544,960)).cuda()
model = ViT(image_size=(544, 960), patch_size=(32, 32), num_classes=4, dim=128, depth=6, heads=8, mlp_dim=64)
model.cuda()
model(test_input)
3 总结
ViT虽然取得了不错的结果,但是需要大数据集才能收敛,一般会进行大数据集训练后finetune,因此CNN和tranformer混合使用还是各位炼丹师的选择,其他没了。