SqueezeNet 一维,二维网络复现 pytorch 小白易懂版
SqueezeNet
时隔一年我又开始复现神经网络的经典模型,这次主要复的是轻量级网络全家桶,轻量级神经网络旨在使用更小的参数量,无限的接近大模型的准确率,降低处理时间和运算量,这次要复现的是轻量级网络的非常经典的一个模型SqueezeNet,它由美国加州大学伯克利分校的研究团队开发,并于2016年发布。
文章链接: https://arxiv.org/pdf/1602.07360.pdf?source=post_page---------------------------
看懂这篇文章需要的基础知识
- 了解python语法基础
- 了解深度学习基本原理
- 知道什么是卷积层池化层激活函数层softmanx层
- 熟悉卷积层池化层需要的参数
- 需要了解pytorch模型的基本构成
我记得去年的这个时候,好像GPT还没被特别广泛的使用,还没到一键就能直接输出写好的模型的这一个步骤,那为什么还要看博客这类的文章呢,应该是因为毕竟GPT他还是靠着已有的资料进行读取,他不能图文并茂的给你写一个一定好用的大型模型,不然直接把论文甩给他让他复现就好了,所以还是打算写一下,然后简单画点图然后给之后的学弟学妹们留一点遗产。
SqueezeNet 的模型结构
下面是原论文给出的模型结构

原文中给出了三种模型,分别是第一个基础模型,以及第二个和第三个带有残差分支的模型,其中卷积池化分支我们都有了解,这里新的东西就是这个Fire层,那就先从这个Fire层开始介绍
Fire层
作者说他的SqueezeNet网络为什么可以有更小的参数量,主要由于用了下面这个叫Fire层的东西,Fire层分两部分
- 一部分是Squeeze层其实就是卷积核大小为1×1的一个卷积层
- 另一部分呢是expend层他实际上是卷积核大小为1×1和卷积核大小为卷积层和3×3输出的一个拼接
下面是原论文中对Fire模型的详细描述


那如果要实现一维的那就把3×3的卷积核改成1×3的
加上激活函数,其实现代码应该是这样的,接下来详细介绍里面的参数。
- in_channels 指Fire模块的输入通道数,也是就每个Fire模块的squeeze卷积层的输入通道数
- squeeze_channels 指的是squeeze层的输出通道数
- expand1x1_channels 指的是expand层中卷积核大小为1×1的卷积层的输出通道数
- expand1x3_channels 指的是expand层中卷积核大小为1×2的卷积层的输出通道数
class FireModule(torch.nn.Module):
def __init__(self, in_channels, squeeze_channels, expand1x1_channels, expand1x3_channels):
super(FireModule, self).__init__()
self.squeeze = torch.nn.Conv1d(in_channels, squeeze_channels, kernel_size=1)
self.relu = torch.nn.ReLU(inplace=True)
self.expand1x1 = torch.nn.Conv1d(squeeze_channels, expand1x1_channels, kernel_size=1)
self.expand1x3 = torch.nn.Conv1d(squeeze_channels, expand1x3_channels, kernel_size=3, padding=1)
def forward(self, x):
x = self.squeeze(x)
x = self.relu(x)
out1x1 = self.expand1x1(x)
out1x3 = self.expand1x3(x)
out = torch.cat([out1x1, out1x3], dim=1)
return self.relu(out)
基础知识补充: torch.cat 将向量在某一个维度上拼接
import torch
# Create two tensors
out1x1 = torch.tensor([[1, 2, 3], [1, 2, 3]])
out1x3 = torch.tensor([[4, 5, 6], [7, 8, 9]])
# Concatenate the tensors along the second dimension (dim=1)
out = torch.cat([out1x1, out1x3], dim=1)
print(out)
# tensor([[1, 2, 3, 4, 5, 6],
# [1, 2, 3, 7, 8, 9]])
out = torch.cat([out1x1, out1x3], dim=0)
print(out)
# tensor([[1, 2, 3],
# [1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]])
那有了Fire层模块之后就可以开始搭建我们的模型,那在搭建的过程中,各个层的参数如何设置呢,原文中给了如下表
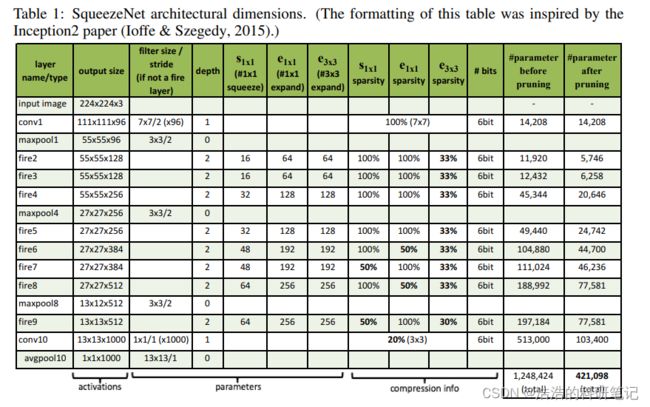
- 第一列Layer name/type 指的是层的名称和类型
- 第二列Output size 指的是输出尺寸
- 第三列是filter size/stride (if not a fire layer)滤波器(卷积核/池化核)的大小(不包含Fire层)
- 第四列depth 卷积层的深度,可以无视掉,没什么用
- 第五-第七 给的就是Fire 层的参数了
再后面的是稀疏性字节大小还有修剪前后的参数大小,这部分不用过于关注,可能要多提一下的就是这个稀疏性sparsity,他指的是卷积层里选择多少参数一直为0,但是并没有详细说具体是怎么实现的,然后我也去搜了一下,需要用一些正则化的东西才可以,这个问题我打算再详细理解一下,暂时我们都默认稀疏性是100,不再为了稀疏性降低参数量实现额外复杂的工作.
根据参数和结构实现代码
一维
import torch
from torchsummary import summary
class FireModule(torch.nn.Module):
def __init__(self, in_channels, squeeze_channels, expand1x1_channels, expand1x3_channels):
super(FireModule, self).__init__()
self.squeeze = torch.nn.Conv1d(in_channels, squeeze_channels, kernel_size=1)
self.relu = torch.nn.ReLU(inplace=True)
self.expand1x1 = torch.nn.Conv1d(squeeze_channels, expand1x1_channels, kernel_size=1)
self.expand1x3 = torch.nn.Conv1d(squeeze_channels, expand1x3_channels, kernel_size=3, padding=1)
def forward(self, x):
x = self.squeeze(x)
x = self.relu(x)
out1x1 = self.expand1x1(x)
out1x3 = self.expand1x3(x)
out = torch.cat([out1x1, out1x3], dim=1)
return self.relu(out)
class SqueezeNet(torch.nn.Module):
def __init__(self,in_channels,classes):
super(SqueezeNet, self).__init__()
self.features = torch.nn.Sequential(
# conv1
torch.nn.Conv1d(in_channels, 96, kernel_size=7, stride=2),
torch.nn.ReLU(inplace=True),
# maxpool1
torch.nn.MaxPool1d(kernel_size=3, stride=2),
# Fire2
FireModule(96, 16, 64, 64),
# Fire3
FireModule(128, 16, 64, 64),
# Fire4
FireModule(128, 32, 128, 128),
# maxpool4
torch.nn.MaxPool1d(kernel_size=3, stride=2),
# Fire5
FireModule(256, 32, 128, 128),
# Fire6
FireModule(256, 48, 192, 192),
# Fire7
FireModule(384, 48, 192, 192),
# Fire8
FireModule(384, 64, 256, 256),
# maxpool8
torch.nn.MaxPool1d(kernel_size=3, stride=2),
# Fire9
FireModule(512, 64, 256, 256)
)
self.classifier = torch.nn.Sequential(
# conv10
torch.nn.Conv1d(512, classes, kernel_size=1),
torch.nn.ReLU(inplace=True),
# avgpool10
torch.nn.AdaptiveAvgPool1d((1))
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
x = torch.flatten(x, 1)
return x
if __name__ == "__main__":
# 创建一个SqueezeNet实例
model = SqueezeNet(in_channels=3,classes=10)
# model = FireModule(96,16,64,64)
# 打印模型结构
summary(model=model, input_size=(3, 224), device='cpu')
二维
import torch
from torchsummary import summary
class FireModule(torch.nn.Module):
def __init__(self, in_channels, squeeze_channels, expand1x1_channels, expand3x3_channels):
super(FireModule, self).__init__()
self.squeeze = torch.nn.Conv2d(in_channels, squeeze_channels, kernel_size=1)
self.relu = torch.nn.ReLU(inplace=True)
self.expand1x1 = torch.nn.Conv2d(squeeze_channels, expand1x1_channels, kernel_size=1)
self.expand3x3 = torch.nn.Conv2d(squeeze_channels, expand3x3_channels, kernel_size=3, padding=1)
def forward(self, x):
x = self.squeeze(x)
x = self.relu(x)
out1x1 = self.expand1x1(x)
out3x3 = self.expand3x3(x)
out = torch.cat([out1x1, out3x3], dim=1)
return self.relu(out)
class SqueezeNet(torch.nn.Module):
def __init__(self,in_channels,classes):
super(SqueezeNet, self).__init__()
self.features = torch.nn.Sequential(
# conv1
torch.nn.Conv2d(in_channels, 96, kernel_size=7, stride=2),
torch.nn.ReLU(inplace=True),
# maxpool1
torch.nn.MaxPool2d(kernel_size=3, stride=2),
# Fire2
FireModule(96, 16, 64, 64),
# Fire3
FireModule(128, 16, 64, 64),
# Fire4
FireModule(128, 32, 128, 128),
# maxpool4
torch.nn.MaxPool2d(kernel_size=3, stride=2),
# Fire5
FireModule(256, 32, 128, 128),
# Fire6
FireModule(256, 48, 192, 192),
# Fire7
FireModule(384, 48, 192, 192),
# Fire8
FireModule(384, 64, 256, 256),
# maxpool8
torch.nn.MaxPool2d(kernel_size=3, stride=2),
# Fire9
FireModule(512, 64, 256, 256)
)
self.classifier = torch.nn.Sequential(
# conv10
torch.nn.Conv2d(512, classes, kernel_size=1),
torch.nn.ReLU(inplace=True),
# avgpool10
torch.nn.AdaptiveAvgPool2d((1,1))
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
x = torch.flatten(x, 1)
return x
if __name__ == "__main__":
# 创建一个SqueezeNet实例
model = SqueezeNet(in_channels=3,classes=10)
# model = FireModule(96,16,64,64)
# 打印模型结构
summary(model=model, input_size=(3, 224, 224), device='cpu')
结束
对于SqueezeNet的第二个和第三个模型,我先把其他的轻量级网络都复现完之后我再回来写一下,对于入门来说先实现个基础版本就够用了