【论文阅读】UDASOD-UPL
一篇关于无监督自适应显著对象检测(SOD)的论文,实习期间阅读复现
论文地址:https://www.aaai.org/AAAI22Papers/AAAI-604.YanP.pdf
目录
- 1、摘要
- 2、介绍
- 3、相关工作
-
- 3.1、Salient Object Detection(显著目标检测)
- 3.2、Unsupervised Domain Adaption(无监督域适应)
- 3.3、Pseudo-Label Learning(伪标签学习)
- 4、Proposed Dataset(SYNSOD 数据集)
-
- 4.1、图片集
- 4.2、数据生成
- 4.3、数据集统计
- 5、方法
-
- 5.1、问题表述
- 5.2、不确定性感知伪标签学习
- 6、实验
-
- 6.1、实验细节
- 6.2、数据集和评估指标
- 6.3、定量比较
- 6.4、定性比较
- 6.5、消融实验
- 6.6、对数据增强的敏感性。
- 6.7、对训练回合的敏感性。
- 7、结论
Unsupervised Domain Adaptive Salient Object Detection Through Uncertainty-Aware Pseudo-Label Learning
通过不确定性感知伪标签学习的无监督域自适应显着目标检测
1、摘要
深度学习的最新进展显着提高了显著对象检测 (SOD) 的性能,但代价是标记更大规模的每像素注释。 为了减轻劳动密集型标签的负担,已经提出了深度无监督 SOD 方法来利用手工制作的显著性方法生成的噪声标签。 然而,仍然很难从粗糙的嘈杂标签中学习准确的显着性细节。 在本文中,我们建议从合成但干净的标签中学习显着性,这自然具有更高的像素标签质量,而无需手动注释。 具体来说,我们首先通过简单的复制粘贴策略构建了一个新的合成 SOD 数据集。 考虑到合成场景和真实场景之间的巨大外观差异,直接使用合成数据进行训练会导致真实场景的性能下降。 为了缓解这个问题,我们提出了一种新的无监督域自适应 SOD 方法,通过不确定性感知自我训练在这两个域之间进行调整。 实验结果表明,我们提出的方法在几个基准数据集上优于现有的最先进的深度无监督 SOD 方法,甚至可以与完全监督的方法相媲美。
2、介绍
SOD旨在准确定位和分割场景中视觉上最独特的对象区域。 近年来,深度卷积神经网络 (DCNN) 的发展显着提升了显着目标检测的性能,并且已经取代了传统的手工制作的基于特征的算法成为显着目标检测的主要方法。 然而,这种有希望的性能是以大量像素级注释图像来训练基于 DCNN 的模型为代价的。 此外,为了确保标注的质量和一致性,通常需要多个人工标注者为同一图像标注精细的像素级掩码。耗时费力的标注工作限制了训练数据的数量,从而阻碍了基于 DCNN 的 SOD 方法的进一步发展。
为了减轻逐像素标注的负担,同时充分利用 DCNN 的端到端训练优势,弱监督和 深度无监督已经提出了 SOD 算法。 弱监督 SOD 算法主要侧重于从简单但干净的手动注释中学习显着性推断,例如图像类、图像说明和涂鸦。 而深度无监督 SOD 方法旨在学习显着性检测,而不诉诸任何手动注释。 现有的深度无监督 SOD 方法主要侧重于从单个或多个生成的密集噪声标签中学习。传统的无监督 SOD 方法(如图 1 (a) 所示),可以通过噪声建模或伪标签自我训练来实现。 然而,依赖手动特征和特定显着性先验的传统无监督方法难以处理低前景/背景对比度的复杂情况。 生成的伪标签含有丰富的噪声,在基于伪标签的迭代训练中几乎不可能修复,尤其是显着对象的边界。
在本文中,我们建议从合成但干净的标签中学习显着性(图 1(b)),而不是与生成的真实图像的噪声标签作斗争,这将是另一种可行的解决方案。 从互联网上的设计资源或摄影网站可以很容易地收集到具有透明背景的海量物体图像以及没有显着物体的纯背景图像。 由于场景的显着对象通常是前景对象,我们通过简单地复制前景对象并将它们粘贴到背景图像上来构建具有干净标签的新的大规模合成显着对象检测(SYNSOD) 数据集 。 SYNSOD 数据集可以应用于现有的全监督 SOD 方法,以减轻手动注释的负担。 然而,如图 1 所示,由于真实图像(目标域)和合成图像(源域)之间存在被称为“域间隙”的较大外观差异,模型直接在 SYNSOD 上训练(图 1(e )) 在 DUTS 等真实数据集上表现不佳。

图 1:通过两种训练设置实现的深度无监督显着目标检测 (USOD)。 现有的深度 USOD 算法主要在 (a) 具有由传统 USOD 方法生成的噪声标签的真实世界图像(目标域)上进行训练。 虽然我们建议利用(b)合成显着性数据(源域)进行训练。然而,由于两个域之间的差异,仅在没有域自适应 (DA) 的合成数据((e) 仅源数据)上训练的显着性检测器通常无法在 © 真实图像上表现良好。 为了解决这个问题,我们提出了 (f) 一种无监督域自适应 SOD (UDASOD) 方法,它可以生成比 (d) 表现最好的深度 USOD 方法 EDNL更准确的显着性预测
为了解决上述问题,我们提出了一种新的无监督域自适应显着对象检测(UDA SOD)算法,以使在合成数据集上训练的基于 DCNN 的显着性检测器适应现实世界的 SOD 数据集。 所提出的 UDASOD 算法是一种迭代方法,它利用**不确定性感知伪学习 (UPL) **策略来实现两个域之间的自适应。
具体来说,在每一轮迭代中,UDASOD 利用带有合成标签的源图像和带有加权伪标签的目标图像来联合训练显着性检测器。 每轮训练结束后,UPL通过像素级不确定性估计、图像级样本选择和像素级伪标签重加权三个主要步骤动态更新目标域的训练集和伪标签 . 本文的主要贡献可归纳如下:
• 据我们所知,我们是第一次尝试通过利用合成数据的无监督域适应来实现 SOD,这与现有的针对噪声标签的深度无监督 SOD 算法不同。
• 我们构建了一个合成SOD 数据集,并进一步提出了利用不确定性感知伪标签学习的UDASOD,以使在合成数据集上训练的显着性检测器适应现实世界的场景。
• 实验结果表明,我们提出的域自适应 SOD 方法优于所有现有的最先进的深度无监督 SOD 方法,并且与完全监督的方法相当。
3、相关工作
3.1、Salient Object Detection(显著目标检测)
传统的 SOD 主要通过不同的显著性先验或手工特征来实现。 DCNN 的最新进展显着提高了 SOD 的性能,但代价是大量的像素级注释。 为了降低标记成本,提出了弱监督 SOD 来学习弱监督下的显着性,例如图像类、字幕和涂鸦 。 进一步提出了深度无监督 SOD 来学习显著性,而无需求助于任何手动注释。 现有的深度无监督方法主要依赖于从传统 SOD 方法生成的噪声标签中学习,这可以通过噪声建模或伪标签自训练。 在本文中,我们建议从一个新的角度解决 SOD,即从合成但干净的标签中学习。
3.2、Unsupervised Domain Adaption(无监督域适应)
无监督域适应(UDA)旨在将从标签丰富的源域学到的知识转移到未标记的目标域。 它在图像分类等各种视觉任务上得到了广泛的研究、对象检测、语义分割 等。在这些任务中,语义分割与 SOD 具有最多的特征。UDA 用于语义分割的主要方法是通过对抗性学习最小化两个域分布之间的差异。 有一些基于自训练的 UDA 方法将伪标签分配给置信的目标样本,并直接使用伪标签作为目标域监督来减少域不匹配。 据我们所知,我们是第一次尝试通过利用 UDA 进行显着目标检测来减轻大规模手动注释的负担。
3.3、Pseudo-Label Learning(伪标签学习)
伪标签学习最初是在半监督学习场景中探索的,由于其简单性和有效性,最近引起了广泛关注。 伪标签学习的目标是通过使用在标记数据上训练的模型为未标记样本生成和更新伪标签来充分利用未标记数据。
因此,它可以应用于各种任务,例如半监督学习 、进行主要适应和噪声标签 学习。
还有一些利用伪标签学习技术的 SOD 方法。 与它们不同的是,我们提出的方法利用了一种不确定性感知的伪学习策略,该策略对每个伪标签进行不同的处理,并且还没有像全连接 CRF 那样耗时的后处理。
4、Proposed Dataset(SYNSOD 数据集)
4.1、图片集
由于显着物体通常是场景的前景物体,我们可以通过将前景物体粘贴到背景图像上来直观地获得具有显着物体的合成图像。 因此,为了构建一个新的合成 SOD 数据集,我们首先从几个具有非版权设计资源的网站收集大量具有透明背景(RGBA 颜色)的对象图像,每个网站都包含单个或多个不同的对象外观和类别。 接下来,我们从多个无版权的摄影网站收集背景照片,其中包含森林、草地、天空、海洋等各种非显着场景。收集过程通过设计的蜘蛛程序和低分辨率图像执行 将被自动删除。
4.2、数据生成
在收集到的前景和背景图像的前提下,我们可以通过简单的复制粘贴策略轻松生成合成 SOD 数据集。如图 2 所示,我们将每个前景对象图像与唯一的非显着背景图像匹配。 然后,我们以 0.5 到 1.1 的比例随机缩放对象图像。 接下来,我们在背景图像中设置一个对象中心,用不透明的对象像素覆盖其周围的像素,从而生成 SOD 的合成图像。 像素级合成标签可以通过二值化合成图像中前景对象像素的相应 alpha 通道来轻松获得。 通过这种方式,我们构建了一个大规模的合成 SOD 数据集(SYNSOD),其中包含 11,197 个合成图像和相应的像素级标签。

图 2:SYN SOD 数据集构建示例。 每个前景对象都与一个独特的背景相匹配,以通过简单的复制粘贴策略生成合成样本。 像素级合成标签可以从前景图像的 alpha 通道中获得。
4.3、数据集统计
如图 3 所示,我们展示了我们提出的 SYNSOD 数据集和五个公共基准 SOD 数据集的以下数据集统计数据
1)对象大小。 如图 3 (a) 所示,SYNSOD 中显着对象大小的比例在 0.39% 到 86.96% 之间(平均:14.72%),产生一个边界范围。
2) 中心偏差。 为了揭示中心偏差的程度,我们计算了每个数据集所有图像的平均显着图。
如图 3 (b) 所示,SYNSOD 是中心偏向的,并且中心偏向的程度略强于其他数据集,这表明与其他现实世界数据集的领域差距很大。

图 3:我们提出的 SYNSOD 数据集的统计数据,包括显着对象大小和中心偏差的分布
5、方法
5.1、问题表述
为了在不借助手动注释或噪声标签的情况下实现 SOD,我们建议通过一种新颖的无监督自适应显着性对象检测 (UDASOD) 框架从合成但干净的标签中学习显着性。 如图 4 所示,UDASOD 被制定为一种迭代训练范式,它可以利用现有的基于深度学习的显着性检测器从合成源数据中学习显着性预测,并在无监督的情况下使其适应真实的目标场景。 为了充分利用未标记的目标图像,UDASOD 与目标图像的伪标签和源图像的合成标签联合训练。

图 4:我们提出的无监督域自适应显着目标检测方法的总体框架。 它迭代地从合成标签(源域)和真实图像的伪标签(目标域)中学习显着性。 伪标签将在每轮训练后通过不确定性感知伪标签学习策略动态更新,该策略包含三个主要步骤,即(a)基于一致性的不确定性估计(b)图像级样本选择, © 逐像素伪标签重新加权。 我们使用三种数据增强来进行基于一致性的不确定性估计,包括 1) 水平翻转 (Flip),2) 将输入图像重新缩放为 224 × 224 (Scale),以及 3) 通过 FDA 与其他目标图像随机交换图像样式。
为了制定 UDASOD,我们从表示为源域 Dsrc = {(Is, ys)}Si s=1 的合成训练集开始,其中 Is 是大小为 H × W 的合成 RGB 彩色图像,ys ∈ {0 , 1}H×W 为对应的二值显着图,Si 为第 i 轮源图像的数量。 所提出的 UDASOD 框架将无监督地将显着性检测器从合成数据集调整到表示为目标域 Dtrg = {(It, y^t)}Ti t=1 的真实SOD数据集。
其中 It 它是真实的 RGB 彩色图像,y^t ∈ [0, 1]H×W是对应的伪标签,Ti是第i轮的伪标签个数。 因此,第 i 轮的训练过程可以表述为显着性检测器的网络参数 θ 的优化,如下所示:

其中源 Dsrc 和目标 Dtrg 域联合监督下的损失函数 L(θ, i) 定义为:

这里,Ys 和 Y^t 分别表示合成源标签集和伪目标标签集。 Lsrc 和 Ltrg 指的是源和目标样本的具体损失计算,后面会详细介绍。
然而,由于目标域的伪标签是由最初训练的显着性检测器生成源域,由于分布显着,伪标签不可避免地包含不正确的像素级预测两个域之间的差距。 避免错误累积在迭代训练过程中,我们提出需要仔细选择目标域的样本参与训练,并且选择的每个像素样本应该被自适应地分配不同的权重。因此,每个预测的显着图的损失函数p ∈ [0, 1]H×W 用权重矩阵 ω ∈ 表示(0, 1]H×W 如下:
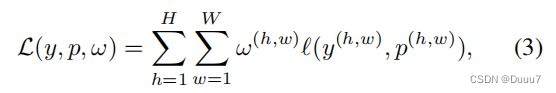
其中 ℓ(.) 表示每个像素的二元交叉熵损失,y ∈ [0, 1]H×W 表示 p 的密集标签。 然后,源样本和目标样本的损失函数可以表示为:
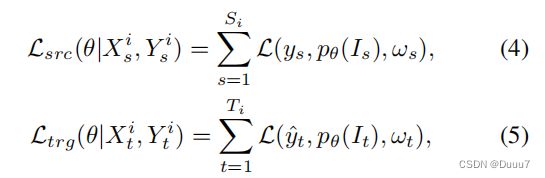
其中 pθ(I) 表示具有参数 θ 的显着性检测器对输入图像 I 的预测。在实践中,我们仅在源域中设置 ωs = 1 ∈ RH×W 时将不同的像素级权重标记为伪标签 . 在每一轮结束时,具有伪标签的目标训练集将根据我们提出的不确定性感知伪标签学习策略动态更新并分配像素级权重。
5.2、不确定性感知伪标签学习
我们建议通过包含以下三个主要步骤的不确定性感知伪标签学习策略(UPL)来选择目标伪标签并分配具有不同权重的像素,而不是平等地使用所有伪标签。
1)基于一致性的不确定性估计。 为了更新目标伪标签,我们首先执行基于一致性的不确定性估计。 具体来说,如图 4 所示,给定一个具有固定参数 θ~ 的显着性检测器,我们将每个真实目标图像 It 输入显着性检测器以获得其伪标签 y^t = pθ~(It)。 为了对目标伪标签的不确定性进行建模,我们考虑以下两个方面。 首先,显着性检测器对高置信度/低不确定性目标样本上的不同小噪声具有鲁棒性。 其次,众所周知,数据增强可以被视为一种噪声注入方法,我们通过评估目标图像在多个数据增强下的显着性预测的一致性来对不确定性进行建模。 数据增强 {αj (.)}Nj=1 下的显着预测可以表述为:
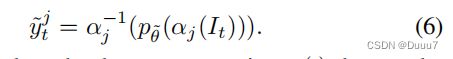
在这里,我们只采用可以反转的数据增强 α(.),并且 α-1(.) 将应用于每个显着性预测 y~tj 以将其转换回相同的条件(例如,方向、比例) 作为伪标签 y^t。 受…的启发,我们利用方差来评估伪标签的一致性和其他显着性预测数据增强的不同变体。 为简化起见,我们令 y∼t1 = ˆyt。 样本的方差图 vt 可以表示为: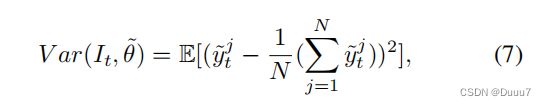
其中 E(.) 表示数学期望。 密集方差图 vt ∈ RH×W 可用于表示目标伪标签 y^t 的像素级不确定性。
2)图像级样本选择(ISS)
由于显着性检测器在早期训练阶段普遍较弱,在迭代训练中逐渐改进,我们提出1)只选择低不确定性的伪标签,2)伪标签的数量应该慢慢增加 随着训练轮次的增加。 如图 4 所示,方差图可以反映目标伪标签的像素级不确定性,其中红色和蓝色分别表示不确定性的高低。 因此,为了根据目标样本的不确定性对目标样本进行排序,我们引入了基于方差平均值的图像级不确定性得分 U(等式(7))。 目标图像的不确定性得分可以表示为:

我们根据不确定的分数对所有目标域样本进行排序,并为每一轮选择一定比例的低不确定性目标样本。 该比例会随着显着性检测器的改进而增加。 请注意,这里我们还凭经验丢弃了那些由几乎所有显着或非显着像素组成的伪标签
3)逐像素伪标签重加权(PPR)
尽管选择的目标伪标签通常反映了低不确定性水平,但仍然存在高不确定性区域,例如其方差图中所示的对象边界。 因此,我们建议在训练过程中对伪标签的每个像素进行不同的处理,并进一步提出基于方差图 V ar 的逐像素伪标签重加权策略 Ω。 等式(5)中提到的逐像素权重矩阵 wt ∈ (0, 1]H×W 可以替换为 Ω(It, θ~),其计算如下:
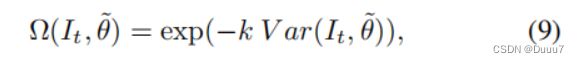
其中 k ∈ R+ 表示软权重的下降程度。 我们在实验中设置 k = 20。
6、实验
6.1、实验细节
我们采用基于 ResNet-50 (He et al. 2016) LDF (Wei et al. 2020) 作为我们的显着性检测器。 在训练过程中,我们采用 SYNSOD(11197 张图像)作为源域,将 DUTS 的训练集(Wang et al. 2017)(10533 张图像)作为目标域。 我们将训练轮次的总数设置为六轮。 六轮中选择的源域和目标域样本的比例分别设置为{1.0, 0.5, 0.25, 0.125, 0.0625, 0.03125}和{0.0, 0.1, 0.2, 0.4, 0.6, 0.6}。 源样本是随机选择的,而目标样本是通过提出的图像级样本选择策略 ISS 选择的。 我们使用 SGD 优化器并采用线性单周期学习率策略(Smith 和 Topin 2019)来安排每一轮训练。 在配备 NVDIA GTX 1080 GPU 的工作站上,批量大小为 32 的整个训练过程大约需要 20 个小时。 在测试过程中,将每张图像的大小调整为 352 × 352,并输入网络进行显着性预测,无需任何后处理。 补充材料中提供了更多实施细节。
6.2、数据集和评估指标
为了评估我们方法的性能,我们对六个真实世界的基准 SOD 数据集进行了测试,包括 DUTS-TE (Wang et al. 2017) (5,017 个图像)、ECSSD (Yan et al. 2013) (1,000 个图像)、 DUT-O (Yang et al. 2013) (5,168 张图片), HKU-IS (Li and Yu 2015) (4,447 张图片), PASCAL-S (Li et al. 2014) (850 张图片), SOD (Movahedi and Elder 2010) )(300 张图片)。 我们采用四种广泛使用的评估指标,即精确召回 (PR) 曲线、平均绝对误差 (MAE, M) (Perazzi et al. 2012)、加权 F-measure (Fβw) (Margolin, Zelnik-Manor, 和 Tal 2014),以及 S-measure (Sm) (Fan et al. 2017)。
6.3、定量比较
定量比较。 在表 1 中,我们比较了我们的具有八种全监督深度显着性预测的方法
方法:R3Net、DGRL、Capsal、TSPOA、BASNet、MINet、GateNet,LDF,两种手工制作的无监督方法:MB+、RBD 和五种深度弱/无监督方法:ASMO、MWS、SCRIB、USPS、EDNL。 为了公平比较,我们使用相同的评估代码评估作者提供的所有显着性图。 如表所示,我们的方法在所有六个数据集上始终优于现有的弱监督和无监督 SOD 方法。 具体来说,我们的方法实现了平均收益 3.65%, 5.56% 1.61% w.r.t Sm, Fβw和 M 与之前最先进的弱监督方法 SCRIB (Zhang et al. 2020b) 在六个数据集。 至于以前最先进的深度无监督方法 EDNL (Zhang, Xie, and Barnes 2020),我们的方法在六个数据集上获得 2.4%、6.23%、2.15% w.r.t Sm、Fβw 和 M 的平均增益。 此外,性能我们提出的 UDASOD 方法与最先进的全监督 SOD 方法相当,甚至更好比其中几个,例如 R3Net (Deng et al. 2018),DGRL (Wang et al. 2018), TSPOA (Liu et al. 2019)。 图 5展示了不同 SOD 方法在五个数据集上的精确召回曲线,其中弱/无监督方法用虚线表示。 从图中可以看出,我们的方法总体上优于其他弱/无监督方法,甚至可以与一些完全监督的方法相媲美监督方法。
6.4、定性比较
图 6 展示了预测显着性图的几个代表性视觉示例。 这些示例反映了各种场景,包括小对象(第 1 行),具有复杂背景的对象(第 2 行),具有线状边界的对象(第 3 行),低对比度在显着对象和图像背景之间(第 4 行),和具有边界连接区域的对象(第 5 行)。 它可以可以看出,我们提出的方法产生了准确和具有清晰边界和连贯细节的完整显着图,始终优于弱/无监督模型,甚至一些完全监督模型。

不同类型 SOD 方法的视觉比较,其中每行显示一个输入图像。 我们提出的方法(我们的)始终生成接近地面实况(GT)的显着性图。
6.5、消融实验
UDASOD 的有效性。为了证明我们提出的无监督域自适应显着性的有效性通过不确定性感知的物体检测(UDASOD)伪标签学习(UPL)策略,我们从以下方面进行消融研究,并在表2中报告不同变体的性能。
1) 综合数据。显着性检测器仅用合成源数据(仅限源)实现可比性其他无监督模型的性能(如表 1 所示),表明从所提出的合成数据集 SYNSOD 学习显着目标检测的可行性。
2)无监督域适应。通过香草伪标签学习(Vanilla PL)策略引入未标记的真实目标数据可以提高
仅源模型,这表明通过伪标签学习的简单无监督域适应可以有助于减轻合成和真实域名。虽然我们提出的方法(UPL)可以进一步大幅提升 vanilla PL 的性能通过利用图像级样本选择(ISS)和像素级伪标签重新加权(PPR)。
3)不确定性感知伪标签学习。进一步验证提议中每个组件的有效性UPL。我们通过去除 PPR 和ISS 分别来自 UPL,即 UPL w/o PPR 和 ISS w/oISS在表2中。与UPL相比,UPL的性能w/o PPR 在五个数据集上略有下降,这表明选择的低不确定性伪标签仍然包含一些错误分类的像素和 PPR 模块可以缓解通过调整像素权重来消除伪标签的噪声。 UPL w/o ISS 与所有目标进行迭代训练没有图像级选择的伪标签,导致与 UPL 相比,性能严重下降。从理论上讲,图像级选择可以近似为像素级重新加权的特殊情况。然而,在实践中,仅使用像素级重新加权(UPL w/o ISS)执行比图像级选择(UPL w/o PPR)差。我们推测,如果没有图像级别的选择,伪标签这些高不确定性样本中自然有许多错误分类的像素,这些像素将被逐像素抑制重新加权。正如 (Shin et al. 2020) 所建议的那样,这将导致稀疏伪标签不可避免地增加了难度网络融合。鉴于 ISS 和 PPR 模块相辅相成,可以进一步提升我们提出的方法的性能。
6.6、对数据增强的敏感性。
我们提出的方法利用多个数据增强作为注入方法中的噪声来估计伪标签的不确定性。为了证明我们的方法适用于不同的数据增强,我们使用第 2 节中提到的增强。 .如表 3 所示,我们的所提出的方法不限于单一类型的数据增强。仅应用一种数据增强时(即,Flip, Scale, FDA) 提出的不确定性感知伪标签学习 (UPL) 策略仍然可以工作并且表现出色vanilla 伪标签学习策略(表 2 中的 Vanilla PL)大幅度提高,这表明我们提出的 UPL 的鲁棒性。此外,当组合不同的数据增强(Flip+Scale+FDA),性能UPL 可以进一步改进,因为该组合导致更稳定的不确定度测量。
6.7、对训练回合的敏感性。
我们提出的方法采用包含多轮的迭代训练范式。展示每一轮训练的表现更直观地,我们呈现 MAE 结果并预测图 7 中的显着性图。如图 7(a)所示,MAE 为随着训练轮次的增加不断提高在所有数据集上。此外,如图7(b)所示,预测显着图的非显着像素逐渐抑制并导致更准确的结果。
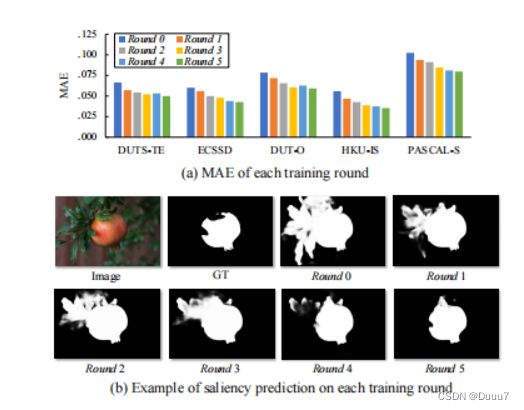
图 7:我们提出的方法在每一轮训练中的定量和视觉表现。
7、结论
在本文中,我们建议从一个新颖的角度解决深度无监督显着目标检测,即从合成但干净的标签中学习。 为了实现这一目标,我们构建了一个新的合成显着对象检测数据集,并引入了一种新的无监督域自适应显着对象检测框架来学习和适应合成数据集。 具体来说,所提出的算法利用不确定性感知伪标签学习策略来减轻合成源域和真实目标域之间的域差距。 在多个基准数据集上进行的大量实验证明了我们提出的方法的有效性和鲁棒性,这使其优于所有最先进的深度无监督方法,甚至可以与全监督方法相媲美。