【菜菜的sklearn课堂笔记】逻辑回归与评分卡-二元逻辑回归损失函数的数学解释,公式推导与解惑
视频作者:菜菜TsaiTsai
链接:【技术干货】菜菜的机器学习sklearn【全85集】Python进阶_哔哩哔哩_bilibili
白板推导里有写过程,但是当时理解的不太好, ψ ( x i , ω ) \psi(x_{i},\omega) ψ(xi,ω)的理解有点问题也就是下面的 y θ ( x i ) y_{\theta}(x_{i}) yθ(xi)
我们基于极大似然法来推导二元逻辑回归的损失函数,这个推导过程能够帮助我们了解损失函数怎么得来的,以及为什么 J ( θ ) J(\theta) J(θ)的最小化能够实现模型在训练集上的拟合最好。
请时刻记得我们的目标:让模型对训练数据的效果好,追求损失最小。
关键概念:损失函数
衡量参数 θ \theta θ的优劣的评估指标,用来求解最优参数的工具
损失函数小,模型在训练集上表现优异,拟合充分,参数优秀
损失函数大,模型在训练集上表现差劲,拟合不足,参数糟糕
我们追求,能够让损失函数最小化的参数组合注意:没有”求解参数“需求的模型没有损失函数,比如KNN,决策树
二元逻辑回归的标签服从伯努利分布(即0-1分布),因此我们可以将一个特征向量为 x x x,参数为 θ \theta θ的模型的一个样本 i i i的预测情况表现为如下形式:
样本 i i i在由特征向量 x i x_{i} xi和参数 θ \theta θ组成的预测函数中,样本标签被预测为1的概率为
P 1 = P ( y i ^ = 1 ∣ x i , θ ) = y θ ( x i ) P_{1}=P(\hat{y_{i}}=1|x_{i},\theta)=y_{\theta}(x_{i}) P1=P(yi^=1∣xi,θ)=yθ(xi)
样本 i i i在由特征向量 x i x_{i} xi和参数 θ \theta θ组成的预测函数中,样本标签被预测为0的概率为
P 1 = P ( y i ^ = 0 ∣ x i , θ ) = 1 − y θ ( x i ) P_{1}=P(\hat{y_{i}}=0|x_{i},\theta)=1-y_{\theta}(x_{i}) P1=P(yi^=0∣xi,θ)=1−yθ(xi)
预测值与真实值之间的关系以及信息损失的关系如下图
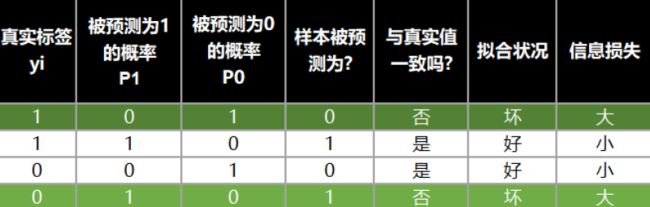
将两种取值的概率整合,我们可以定义如下等式:
P ( y i ^ ∣ x i , θ ) = P 1 y i ⋅ P 0 1 − y i P(\hat{y_{i}}|x_{i},\theta)=P_{1}^{y_{i}}\cdot P_{0}^{1-y_{i}} P(yi^∣xi,θ)=P1yi⋅P01−yi
这个等式同时代表了 P 1 P_{1} P1和 P 0 P_{0} P0。
当样本 i i i的真实标签 y i y_{i} yi为1的时候, 1 − y i 1-y_{i} 1−yi就等于0, P 0 P_{0} P0的0次方就是1,所以 P ( y i ^ ∣ x i , θ ) P(\hat{y_{i}}|x_{i},\theta) P(yi^∣xi,θ)就等于 P 1 P_{1} P1,这个时候,如果 P 1 P_{1} P1为1,模型的效果就最好,损失最小。
同理,当 y i y_{i} yi为0的时候, P ( y i ^ ∣ x i , θ ) P(\hat{y_{i}}|x_{i},\theta) P(yi^∣xi,θ)就等于 P 0 P_{0} P0,此时如果 P 0 P_{0} P0非常接近1,模型的效果就很好,损失就很小。
为了达成让模型拟合好,损失小的目的,我希望任何取值下 P ( y i ^ ∣ x i , θ ) P(\hat{y_{i}}|x_{i},\theta) P(yi^∣xi,θ)的值等于1。
而 P ( y i ^ ∣ x i , θ ) P(\hat{y_{i}}|x_{i},\theta) P(yi^∣xi,θ)的本质是样本 i i i由特征向量 x i x_{i} xi和参数 θ \theta θ组成的预测函数中,预测处所有可能的 y i ^ \hat{y_{i}} yi^的概率,因此1是它的最大值。也就是说,每时每刻,我们都在追求 P ( y i ^ ∣ x i , θ ) P(\hat{y_{i}}|x_{i},\theta) P(yi^∣xi,θ)的最大值,这就将模型拟合中的“最小化损失”问题,转化成函数求解极值的问题
P ( y i ^ ∣ x i , θ ) P(\hat{y_{i}}|x_{i},\theta) P(yi^∣xi,θ)是对单个样本 i i i而言的函数,对一个训练集的 n n n个样本来说,我们可以定义如下等式来表达所有样本在特征矩阵 X X X和参数 θ \theta θ组成的预测函数中,预测处所有可能的 y ^ \hat{y} y^的概率 P P P为
P = ∏ i = 1 n P ( y i ^ ∣ x i , θ ) = ∏ i = 1 n ( P 1 y i ⋅ P 0 1 − y i ) = ∏ i = 1 n ( y θ ( x i ) y i ⋅ ( 1 − y θ ( x i ) ) 1 − y i ) \begin{aligned} P&=\prod\limits_{i=1}^{n}P(\hat{y_{i}}|x_{i},\theta)\\ &=\prod\limits_{i=1}^{n}(P_{1}^{y_{i}}\cdot P_{0}^{1-y_{i}})\\ &=\prod\limits_{i=1}^{n}(y_{\theta}(x_{i})^{y_{i}}\cdot (1-y_{\theta}(x_{i}))^{1-y_{i}}) \end{aligned} P=i=1∏nP(yi^∣xi,θ)=i=1∏n(P1yi⋅P01−yi)=i=1∏n(yθ(xi)yi⋅(1−yθ(xi))1−yi)
两侧同时取对数
log P = log ∏ i = 1 n ( y θ ( x i ) y i ⋅ ( 1 − y θ ( x i ) ) 1 − y i ) = ∑ i = 1 n log ( y θ ( x i ) y i ⋅ ( 1 − y θ ( x i ) ) 1 − y i ) = ∑ i = 1 n ( y i ⋅ log y θ ( x i ) + ( 1 − y i ) ⋅ log ( 1 − y θ ( x i ) ) ) \begin{aligned} \log P&=\log \prod\limits_{i=1}^{n}(y_{\theta}(x_{i})^{y_{i}}\cdot (1-y_{\theta}(x_{i}))^{1-y_{i}})\\ &=\sum\limits_{i=1}^{n}\log(y_{\theta}(x_{i})^{y_{i}}\cdot (1-y_{\theta}(x_{i}))^{1-y_{i}})\\ &=\sum\limits_{i=1}^{n}(y_{i} \cdot \log y_{\theta}(x_{i})+(1-y_{i})\cdot \log(1-y_{\theta}(x_{i}))) \end{aligned} logP=logi=1∏n(yθ(xi)yi⋅(1−yθ(xi))1−yi)=i=1∑nlog(yθ(xi)yi⋅(1−yθ(xi))1−yi)=i=1∑n(yi⋅logyθ(xi)+(1−yi)⋅log(1−yθ(xi)))
这就是我们的交叉熵函数。为了数学上的便利以及更好地定义”损失”的含义,我们希望将极大值问题转换为极小值问题,因此我们对 log P \log P logP取负,并且让参数 θ \theta θ作为函数的自变量,就得到了损失函数 J ( θ ) J(\theta) J(θ)
J ( θ ) = − ∑ i = 1 n ( y i ⋅ log y θ ( x i ) + ( 1 − y i ) ⋅ log ( 1 − y θ ( x i ) ) ) J(\theta)=-\sum\limits_{i=1}^{n}(y_{i} \cdot \log y_{\theta}(x_{i})+(1-y_{i})\cdot \log(1-y_{\theta}(x_{i}))) J(θ)=−i=1∑n(yi⋅logyθ(xi)+(1−yi)⋅log(1−yθ(xi)))
这就是一个,基于逻辑回归的返回值 y θ ( x i ) y_{\theta}(x_{i}) yθ(xi)的概率性质得出的损失函数。在这个函数上,我们只要追求最小值,就能让模型在训练数据上的拟合效果最好,损失最低。
其中 θ \theta θ表示求解出来的一组参数, n n n是样本个数, y i y_{i} yi是样本 i i i上的真实标签, y θ ( x i ) y_{\theta}(x_{i}) yθ(xi)是样本 i i i上基于参数 θ \theta θ计算出来的逻辑回归返回值, x i x_{i} xi是样本 i i i各个特征的取值
注意,在逻辑回归的本质函数 y ( x ) y(x) y(x)例,特征矩阵 x x x是自变量,参数㐊 θ \theta θ。但在损失函数中,参数 θ \theta θ是损失函数的自变量, x x x和 y y y都是已知的特征矩阵和标签,相当于是损失函数的参数。
不同的函数中,自变量和参数各有不同,因此大家需要在数学计算中,尤其是求导的时候避免混淆。
关键概念:似然与概率
以样本 i i i为例,我们有表达式
P ( y i ^ ∣ x i , θ ) P(\hat{y_{i}}|x_{i},\theta) P(yi^∣xi,θ)
对于这个表达式而言,如果参数 θ \theta θ是一致的,特征向量 x i x_{i} xi是未知的,我们便称 P P P是在探索不同特征取值下获取所有可能的 y ^ \hat{y} y^的可能性,这种可能性就被称为概率,研究的是自变量和因变量之间的关系
如果特征向量 x i x_{i} xi是已知的,参数 θ \theta θ是未知的,我们便称 P P P是探索不同参数下获取所有可能的 y ^ \hat{y} y^的可能性,这种可能性就被称作似然,研究的是参数取值与因变量之间的关系
在逻辑回归的建模过程中,我们的特征矩阵是已知的,参数是未知的,因此我们讨论的所有“概率”其实严格来说都是“似然”,所以逻辑回归的损失函数推导方法叫做“极大似然法”。也因此,一下式子又被称为“极大似然函数”
P ( y i ^ ∣ x i , θ ) = y θ ( x i ) y i ⋅ ( 1 − y θ ( x i ) ) 1 − y i P(\hat{y_{i}}|x_{i},\theta)=y_{\theta}(x_{i})^{y_{i}}\cdot (1-y_{\theta}(x_{i}))^{1-y_{i}} P(yi^∣xi,θ)=yθ(xi)yi⋅(1−yθ(xi))1−yi