通过这篇笔记,希望能初步了解 oneflow 在 eager 模式下对设备的管理方式、设备执行计算的过程、如何充分利用设备计算能力。
这里的设备主要指类似 CUDA 这样的并行计算加速设备。
1 设备相关的类之间的关系
框架通过 Stream 向设备提交计算任务。一个 Stream 是一个命令序列,可以类比 CUDA Stream,或者 CPU Thread 的指令序列。同一个 Stream 中的命令按顺序执行;不同 Stream 之间的命令有依赖关系时,需要同步。
oneflow 中设备相关的部分类如下所示:
2 忽略与当前进程无关的计算任务
2.1 placement 的 parallel_id
在 oneflow 的分布式环境下,各个 host 上需要有相同数量的加速设备,每个进程使用一个加速设备。这样根据环境变量 RANK 可以得出 machine_id,LOCAL_RANK 就是进程在 host 上使用的 device_id。
如果 input tensor 的 placement 与当前进程无关,可以省掉很多不必要的计算。通过 placement 的 parallel_id 可以判断计算任务是否与当前进程相关。
placement 在 C++ 中的对应类型是 ParallelDesc,其中并没有 parallel_id 字段,这个信息隐含在其它字段中。
ParallelDesc 在构造时会调用 ClearUp 函数,从中可以看到
ParallelDesc::parallel_id2machine_id_是 placement 分布的 machine。ParallelDesc::parallel_id2device_id_是 placement 分布的 device_id。- parallel_id 是上述 2 个数组的索引,一个 parallel_id 对应一个
machine_id:device_id组合。这样,根据parallel_id可以查到对应的 machine_id 和 device_id。 - 反过来,根据
machine_id:device_id也可以从machine_id2device_id2parallel_id_查到 parallel_id。
parallel_id 不是 placement 的唯一标识。而是 placement 所分布的设备在该对象内的唯一标识。如果一个 placement 分布在 N 个设备,其 parallel_id 的取值范围是[0, N)。
2.2 eager 模式下根据 parallel_id 忽略无关计算任务
在 eager 分布时场景处理计算任务时,会调用 GetTensorDevice4CurrentProcessCtx,获取当前进程的 machine_id、device_id 在 placement 中的 parallel_id 值。
如果当前进程与该 placement 无关,parallel_id 就是空,后续处理时就可以忽略一些计算:
- EagerConsistentTensorImpl::New 中只需要用 functional::Empty 构造一个 shape 为 0 的空的 tensor。
- GetBoxingOutput 可以提前返回。
- Interpret 可以不给 vm 提交指令、提前返回。
3 根据 placement 获取逻辑Stream
在 ConsistentTensorInferCache 中推导 SBP Signature 时,也会同时推导出当前的 tensor 计算任务、在当前进程所用的设备。推导时,会先确认所有 inputs 的 placement 是一致的,都分布在相同的设备上。
如前所述,如果计算任务与当前进程无关,会提前返回;而一个进程只使用一个加速设备。所以 result->set_stream(...) 只需要获取当前进程使用的设备类型和ID。这里设置的对象类型是 oneflow::Stream,StreamRole 是 kCompute。
类图如下。从这里可以看出,oneflow::Stream 描述了计算设备的逻辑信息,它并不包含计算执行的相关组件。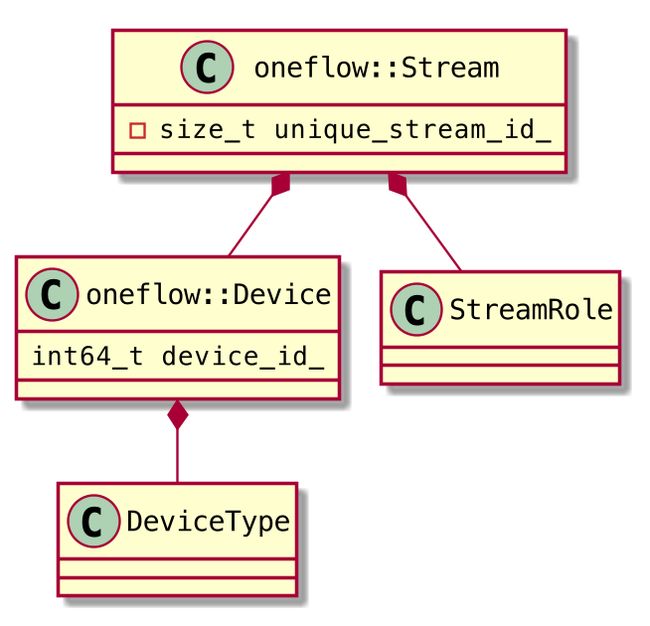
3.1 unique_stream_id
unique_stream_id 表示 oneflow::Stream 对象的创建次序。
所有的 oneflow::Stream 对象都保存在全局的 StreamMgr::stream2unique_stream_id_ 中。unique_stream_id2stream_symbol_ 可看作是引用类型的副本,unique_stream_id 就是 Stream 对象在这个数组中的索引。与 parallel_id 不同,unique_stream_id 是 Stream 对象在进程内的唯一标识。
并不是每次都需要加锁访问 StreamMgr。 oneflow::Stream 包含的都是描述性信息,其引用是以 ThreadLocal 的方式存储的,可以提升后续读取的效率。虚拟机在执行指令时,也会用 unique_stream_id 进行逻辑判断。
oneflow::Stream 对象构造、设置唯一 ID 的具体过程参考附录 6.1。
4 构造指令时创建(查找)必要的设备对象
PhysicalRun 执行的功能如下:
vm::InstructionList instruction_list;
InstructionsBuilder instructions_builder(&instruction_list);
builder->Call(kernel, input_eager_blob_objects, output_eager_blob_objects, result, ctx, result->stream());
JUST(vm::Run(instructions_builder.mut_instruction_list()));在 builder->Call 中构造指令时,首先执行的是 SoftSyncStream,必要时会在指令列表中添加同步指令。这个放到后面讨论。先看看指令创建过程中设备和 Stream 对象是怎么构造(查询)的。
在 builder->Call 中对 GetVmStream 的调用会由 VirtualMachine 返回一个 vm::Stream 对象。创建对象的过程分两步完成,首先是获取 ThreadCtx 对象,然后构造 vm::Stream。4.1-4.3 的详细过程参考附录 6.2。
4.1 构造 ThreadCtx 对象,启动执行指令的线程
ThreadCtx 对象指针保存在 VirtualMachine 的 HashMap 中。每个 DeviceType(CPU或CUDA)对应一个 ThreadCtx 对象;临界区和 LazyJob 有自己的 ThreadCtx 对象。
首次访问 HashMap 时得到的是零值(空指针),需要调用 CreateThreadCtx 创建对象。实际通过虚拟机指令创建对象,ThreadCtx 对象保存在 VirtualMachineEngine::thread_ctx_list_ 中。
ThreadCtx 对象构造后,会创建一个 worker 线程、执行 WorkerLoop 方法,并添加到 worker_threads_。所以 worker_threads_ 是与 ThreadCtx 对象一一对应的。
这个线程负责其所归属的指令的执行:
- WorkerLoop 在收到通知后,会调用 ThreadCtx::TryReceiveAndRun 处理指令。
- 在这个函数中,将 ThreadCtx 的指令挪到临时列表、通过 StreamType 执行每个指令。
- ThreadCtx 的指令,是 VirtualMachineEngine 在 DispatchInstruction 时添加进去的。
4.2 构造 vm::Stream 对象
通过虚拟机指令创建、并由 ThreadCtx 持有 vm::Stream 对象。
4.3 设备对象的初始化
vm::Stream 初始化过程中会创建设备相关对象。
首先会根据 StreamRole 和 DeviceType 确定 StreamType,比如执行 kernel 计算的 EpStreamType。
然后由 EpStreamType 初始化 vm::Stream 的 device_ctx_ 变量。这个过程中会创建 ep::Device 对象,过程如下(与调用链路相反):
- 系统启动时注册 CudaDeviceManagerFactory,保存到全局的 factories(),注册设备类型名到类型的映射。
- 根据设备类型获取工厂实例,创建设备管理器,比如 CudaDeviceManager。
- 设备管理器创建 Device 对象,比如 CudaDevice。这就是 InitDeviceCtx 得到的设备对象。
4.4 ep::Stream 对象的创建
有几个场景会创建(获取) ep::Stream 对象。比如 kernel 执行时。
op instruction 在构造时,指令类型是 OpCallInstructionType。
虚拟机在 DispatchInstruction 时,无论哪个分支,后续都会调用 EpStreamType::Run,最终执行 kernel 的 Compute 方法,例如 GpuL2NormalizeKernel::Compute,其中的 ctx->stream()会创建(获取)ep::Stream 对象、launch kernel 执行计算。细节可以参考附录 6.3。
4.5 输入与输出的设备不一样的情形
例如 tensor.cuda()方法,inputs 在 CPU 上, outputs 在 CUDA,二者的设备类型不同。这时就不会通过 inputs[0].placement 推导 Stream,而是利用 op 注册的推导函数获取 oneflow::Stream。例如 CopyOp::InferDeviceAndStream。细节可以参考附录 6.4。
4.6 SoftSyncStream: eager 模式下的指令同步
设想这样一种场景:将 CPU 下的 tensor 拷贝到 CUDA 设备,然后在 CUDA 上再进行 tensor add 的计算。这涉及到两个流,一个是 Host2Device,一个是 CUDA Compute。这两个流的计算任务是并发执行的。需要有同步措施,才能保证拷贝完再执行 add 计算。
eager 模式下,在 InstructionsBuilder::Call 中构造指令时,对 SoftSyncStream 的调用会在必要时向指令列表插入同步指令。细节可以参考附录 6.5。
SoftSyncStream 中,last_used_streams 保存的是当前计算需要同步等待的流:
- 我们现在要用的数据是 eager_blob_objects,
- 最后一个用到这些数据的流是 last_used_stream,
- 如果 last_used_stream 与当前计算执行的流 stream 不同,就需要同步,也就是要把 last_used_stream 放到集合中。
通过集合的构造过程可以知道,对于每一个要同步等待的流 S,至少有一个数据对象的流和 S 相等。这些数据对象的 compute_local_dep_object 数组,连同 S 一起构造一个同步指令。指令的构成如下:
操作数类型为 ConsumeLocalDepObjectPhyInstrOperand,包含上述 compute_local_dep_object 数组
- 操作数在构造时会将各个 compute_local_dep_object 保存到 output_dependences_
- 虚拟机在处理指令时,会检查操作数的 output_dependences,应该会创建指令之间的依赖关系。
- 指令的 vm::Stream 是 last_used_stream,其 StreamType 是 上述 EventRecordedEpStreamType。
- Host2Device 场景的指令类型是 EpRecordEventInstructionType
同步指令执行过程的要点如下:
- 同步指令会先于当前指令执行。EventRecordedEpStreamType::Compute 是一个空方法,没有任何操作。同步指令执行前会通过 cudaEventCreateWithFlags 创建一个 CUDA event,在初始化指令状态时调用 cudaEventRecord 记录 Stream 的操作。
- 同步操作貌似是在虚拟机中以查询、等待的方式完成的(细节还不太清楚)。对于同步指令,Instruction::Done 返回 event 记录的操作是否都已完成。VirtualMachineEngine 中通过这个信息释放指令。释放应该会影响指令之间的依赖关系,从而达到同步目的。
4.7 CPU 下的并行计算
CpuStream 只有一个线程。CPU kernel 应该是通过 OpenMP 或者 Intel OneApi 等实现并行计算加速。
5 总结
根据 inputs 的 placement(或定制的推导方法) 可以得到 oneflow::Device,加上 StreamRole 可以得到 oneflow::Stream,进而得到 vm::Stream。
每个实际用到的
kernel 计算的每种设备(CPU 和 CUDA),以及临界区和 LazyJob,都有一个 ThreadCtx 对象和线程。
vm::Stream 的数量与 oneflow::Stream 相同。vm::Stream 按照
不同的任务,比如 kernel 计算、host2device、device2host 等都有自己独立的 Stream,可以并发执行,从而在 eager 模式下尽可能充分利用设备的异步并发执行能力。
6 附录
6.1 oneflow::Stream 的构造过程
result->set_stream(...)会保存 InferDeviceAndStream 返回的结果。如果 UserOpExpr 没有自定义设备推导方法(比如非 Copy 等场景),会调用 GetDefaultStreamByPlacement。这个函数的执行过程如下:
-
RawGetDefaultStreamByPlacement
-
-
- [GetCurrentMachineIdAndDeviceId](): 这里的 machine_id 其实是进程 ID,不是 NodeId。
- Device::ThreadLocalGetOrNew
-
-
6.2 指令构造过程中线程、设备和流对象的初始化(查询)
Singleton
6.3 指令执行过程中 ep::Stream 的创建(获取)
- SetAsActiveDevice
6.4 输入与输出的设备不一样时,获取 Stream 的过程
op_generated.cpp 中,op copy 注册的设备推导函数为 CopyOp::InferDeviceAndStream。这个函数调用 MakeCopyStream 获取 oneflow::Stream 对象,实际根据输入输出的设备类型等,确定 StreamRole。tensor.cuda()场景下的目标设备是 CUDA。InitDeviceCtx 以及后续的设备对象都是 CUDA。kernel 执行时会从 host 拷贝数据到 CUDA 设备(具体方向根据指针值判断)。
根据 oneflow::Stream 创建 vm::Stream 时,会推导 StreamType,推导得到的类型是 EventRecordedEpStreamType。
自动生成的代码文件
functional::To: build/oneflow/core/functional/functional_api.yaml.cppREGISTER_USER_OP("copy"): build/oneflow/core/framework/op_generated.cpp
6.5 同步指令的执行过程
同步指令在虚拟机中的执行过程。
-
instruction_type().InitInstructionStatusIf
EpRecordEventInstructionType::InitInstructionStatus
- 获取指令的 status_buffer,这个用于存储 EpOptionalEventRecordStatusQuerier
EventRecordedEpStreamType::InitInstructionStatus
- [构造 EpOptionalEventRecordStatusQuerier]()。对象存储在指令的 status_buffer。EpEvent 就存储在这个对象。
- 虚拟机调度 ...
EventRecordedEpStreamType::Run
- SetAsActiveDevice
- EpRecordEventInstructionType::Compute 函数体是空的。