ncnn源码学习(六):模型量化原理笔记
1.请直接去学习大佬们的文章:
章小龙的:
Int8量化-介绍(一):https://zhuanlan.zhihu.com/p/58182172
Int8量化-python实现以及代码分析(二):https://zhuanlan.zhihu.com/p/58208691
虫叔的:
Int8量化-ncnn社区Int8重构之路(三):https://zhuanlan.zhihu.com/p/61451372
Int8量化-Winograd量化原理及实现(四):https://zhuanlan.zhihu.com/p/67718316
田子寰的:
NCNN Conv量化详解(一):https://zhuanlan.zhihu.com/p/71881443
NCNN 量化详解(二):https://zhuanlan.zhihu.com/p/72375164
大家都去了吗?都去了我就开始写自己的笔记了。
2. 为什么int8量化?
(1) CNN对噪声不敏感 -> Int8有用;
(2) 模型太大,对存储和计算需求较大 -> 量化能有效降低推理过程中对存储和算力需求;
(3) 每个层weights波动范围不大 -> 适合做量化。
注意,上面这段话摘抄自章小龙大佬的知乎文章:Int8量化-介绍(一):https://zhuanlan.zhihu.com/p/58182172
3. int8量化基本思路
由于在一个卷积神经网络(CNN)中,最耗时的模块一般都是卷积,所以一般优先对卷积进行优化。基本思路就是将原来的32位浮点型(fp32)运算转换成int8类型卷积运算,这样就可以有效降低计算量。最粗糙原理如图1所示:
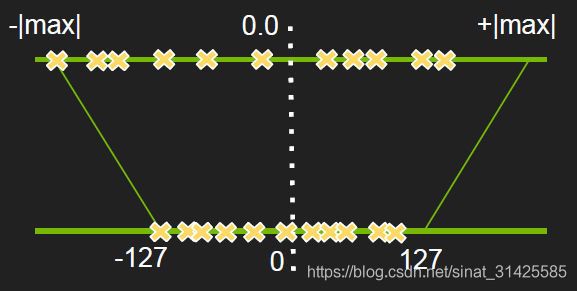
图1 量化的粗糙原理(摘自参考资料[1])
其实就是将卷积当前层权重和输入的取值范围按照比例映射到[-127, +127],但是这里取值范围不均衡,有部分空出来了,部分值域被浪费,精度损失就会很大很明显,所有一般会采取截断其中一部分的方式建立映射关系,如图2所示:

图2 实际量化截取区段(摘自参考资料[2])
量化时,对应的因子:
![]()
那么quantize(量化)公式为:
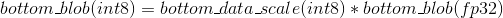
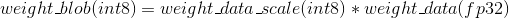
在做前向inference(推理)时,计算输入和权重的乘积:

所以dequantize(反量化)时,反量化因子为:
![]()
进行前向推理运算时,有:
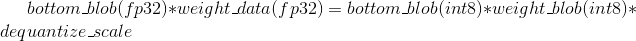
可以将这个分为两步:
第一步为int8计算部分:
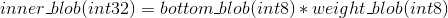
第二步为实际内积计算部分:
![]()
4.如何得到缩放因子scale?
前面提到,缩放因子计算公式为:
![]()
因此,计算缩放因子scale,实际上就是等效于寻找合适的阈值T,使得量化前后两个分布的差异最小,这里采用的就是KL散度。现在假设量化前fp32数据分布为P,量化后int8的数据分布为Q,那么P、Q之间散度公式为:
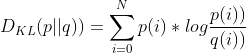
这个公式就用于筛选最优阈值T的评价指标,既然有了评价指标,我们就可以通过穷举的方式得到所有T的可能,然后从中选取最优的那组参数T即可。
这里,我们再回去看一下图2,实际上量化过程就是找原始fp32类型数据分布与int8类型量化后数据分布之间的映射关系,所以第一步需要找到weight的最大绝对值:
![]()
第二步,穷举所有可能的截断阈值T,并设定准则来选取最优的T,这里设定的准则为KL散度:

这里P表示原始fp32的数值分布,Q为量化后int8类型数值分布,散度越小,表明量化前后P和Q分布的差异越小,总体过程就是:
(1) 计算fp类型数据的最大绝对值,即最大值和最小值绝对值的最大值:
![]()
(2) 将原始的fp类型数据离散化,并计算对应统计直方图,这里ncnn默认将fp类型数据划分为2048个bin,每个bin宽度为:
![]()
(3) 穷举所有截断阈值T,并选取量化前后KL散度最小时对应的截断阈值T:
for num_bins from 128 to 2048:
(a)current_T = interval * num_bins, 计算截断后fp32数据对应统计直方图;
(b)将P映射到Q,Q的bins为128;
(c)将Q拓展到P一样长度,得到分布Q_expand;
(d)计算P和Q_expand的KL散度,并判断当前KL散度是否为最小;这里有一个步骤是要将Q拓展到P一样的长度,因为P的长度是随着截断阈值T变化而变化的,而计算两个分布的KL散度时,要求二者具有相同数目的bins,拓展过程如下:
P=[1 2 2 3 5 3 1 7] // fp32的统计直方图,T=8
// 假设只量化到两个bins,即量化后的值只有-1/0/+1三种
Q=[1+2+2+3, 5+3+1+7] = [8, 16]
// P 和 Q现在没法做KL散度,所以要将Q扩展到和P一样的长度
Q_expand = [8/4, 8/4, 8/4, 8/4, 16/4, 16/4, 16/4, 16/4] = [2 2 2 2 4 4 4 4]
D = KL(P||Q_expand) // 这样就可以做KL散度计算了注意,上面这部分是从参考资料[6]copy过来的,通过这样一个过程,就可以得到最佳的截断阈值T了。ncnn做模型量化过程中还做了一些算子融合的操作,具体详见ncnn的quantinize部分代码。
5. ncnn的int8量化工具使用
(1)Optimization graphic
./ncnnoptimize mobilenet-fp32.param mobilenet-fp32.bin mobilenet-nobn-fp32.param mobilenet-nobn-fp32.bin (2)Create the calibration table file
./ncnn2table --param mobilenet-nobn-fp32.param --bin mobilenet-nobn-fp32.bin --images images/ --output mobilenet-nobn.table --mean 104,117,123 --norm 0.017,0.017,0.017 --size 224,224 --thread 2(3) Quantization
./ncnn2int8 mobilenet-nobn-fp32.param mobilenet-nobn-fp32.bin mobilenet-int8.param mobilenet-int8.bin mobilenet-nobn.table~~~未完待续~~~
参考资料:
[1] https://zhuanlan.zhihu.com/p/58182172
[2] https://zhuanlan.zhihu.com/p/58208691
[3] https://zhuanlan.zhihu.com/p/61451372
[4] https://zhuanlan.zhihu.com/p/67718316
[5] https://zhuanlan.zhihu.com/p/71881443
[6] https://zhuanlan.zhihu.com/p/72375164
[7] https://github.com/Tencent/ncnn/tree/master/tools/quantize