Spark(3):Spark运行环境
目录
0. 相关文章链接
1. Local 模式
1.1. 解压缩文件
1.2. 启动 Local 环境
1.3. 命令行工具
1.4. 退出本地模式
1.5. 提交应用
2. Standalone 模式
2.1. 解压缩文件
2.2. 修改配置文件
2.3. 启动集群
2.4. 提交应用
2.5. 提交参数说明
2.6. 配置历史服务
2.7. 配置高可用( HA)
3. Yarn模式
3.1. 解压缩文件
3.2. 修改配置文件
3.3. 提交应用
3.4. 配置历史服务器
4. K8S 模式
5. Windows 模式
5.1. 启动本地环境
5.2. 命令行提交应用
6. 部署模式对比
7. 端口号
0. 相关文章链接
Spark文章汇总
1. Local 模式
所谓的 Local 模式,就是不需要其他任何节点资源就可以在本地执行 Spark 代码的环境,一般用于教学,调试,演示等,在 IDEA 中运行代码的环境我们称之为开发环境,不太一样。
1.1. 解压缩文件
将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到 Linux 并解压缩,放置在指定位置,路径中不要包含中文或空格。
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-local 1.2. 启动 Local 环境
1) 进入解压缩后的路径,执行如下指令
bin/spark-shell2) 启动成功后,可以输入网址进行 Web UI 监控页面访问
http://虚拟机地址:40401.3. 命令行工具
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
1.4. 退出本地模式
按键 Ctrl+C 或输入 Scala 指令
:quit 1.5. 提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.0.0.jar \
101) --class 表示要执行程序的主类, 此处可以更换为咱们自己写的应用程序
2) --master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟 CPU 核数量
3) spark-examples_2.12-3.0.0.jar 运行的应用类所在的 jar 包, 实际使用时,可以设定为咱们自己打的 jar 包
4) 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
2. Standalone 模式
local 本地模式毕竟只是用来进行练习演示的,真实工作中还是要将应用提交到对应的集群中去执行,这里我们来看看只使用 Spark 自身节点运行的集群模式,也就是我们所谓的独立部署(Standalone)模式。Spark 的 Standalone 模式体现了经典的 master-slave 模式。
集群规划如下:
linux1:Master、Worker
linux2:Worker
linux3:Worker
2.1. 解压缩文件
将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到 Linux 并解压缩在指定位置
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-standalone
2.2. 修改配置文件
1)进入解压缩后路径的 conf 目录,修改 slaves.template 文件名为 slaves
mv slaves.template slaves 2) 修改 slaves 文件,添加 work 节点
linux1
linux2
linux3 3) 修改 spark-env.sh.template 文件名为 spark-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
SPARK_MASTER_HOST=linux1
SPARK_MASTER_PORT=7077 注意:7077 端口,相当于 hadoop3 内部通信的 8020 端口,此处的端口需要确认自己的 Hadoop配置
5) 分发 spark-standalone 目录
xsync spark-standalone 2.3. 启动集群
1)执行脚本命令:
sbin/start-all.sh 
2)查看三台服务器运行进程
================linux1================
3330 Jps
3238 Worker
3163 Master
================linux2================
2966 Jps
2908 Worker
================linux3================
2978 Worker
3036 Jps3) 查看 Master 资源监控 Web UI 界面: http://linux1:8080

2.4. 提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://linux1:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
101) --class 表示要执行程序的主类
2) --master spark://linux1:7077 独立部署模式,连接到 Spark 集群
3) spark-examples_2.12-3.0.0.jar 运行类所在的 jar 包
4) 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
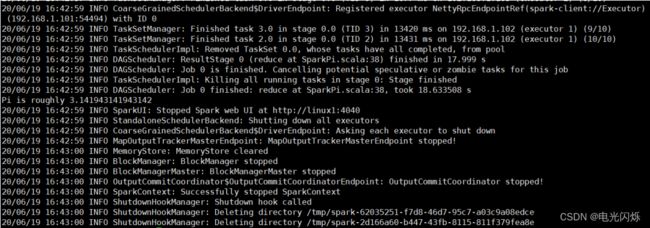
执行任务时,会产生多个 Java 进程

执行任务时,默认采用服务器集群节点的总核数,每个节点内存 1024M。

2.5. 提交参数说明
在提交应用中,一般会同时一些提交参数
bin/spark-submit \
--class
--master \
... # other options
\
[application-arguments] | 参数 | 解释 | 可选值举例 |
| --class | Spark 程序中包含主函数的类 | |
| --master | Spark 程序运行的模式(环境) | 模式: local[*]、spark://linux1:7077、Yarn |
| --executor-memory 1G | 指定每个 executor 可用内存为 1G | 符合集群内存配置即可,具体情况具体分析。 |
| --total-executor-cores 2 | 指定所有executor使用的cpu核数 为 2 个 |
|
| --executor-cores | 指定每个executor使用的cpu核数 | |
| application-jar | 打包好的应用 jar,包含依赖。这个 URL 在集群中全局可见。 比如 hdfs:// 共享存储系统,如果是file:// path,那么所有的节点的path 都包含同样的 jar | |
| application-arguments | 传给 main()方法的参数 |
2.6. 配置历史服务
由于 spark-shell 停止掉后,集群监控 linux1:4040 页面就看不到历史任务的运行情况,所以开发时都配置历史服务器记录任务运行情况。
1) 修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf 2) 修改 spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://linux1:8020/directory
-- 注意:需要启动 hadoop 集群,HDFS 上的 directory 目录需要提前存在。
sbin/start-dfs.sh
hadoop fs -mkdir /directory3) 修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://linux1:8020/directory
-Dspark.history.retainedApplications=30"- 参数 1 含义: WEB UI 访问的端口号为 18080
- 参数 2 含义:指定历史服务器日志存储路径
- 参数 3 含义:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
4) 分发配置文件
xsync conf5) 重新启动集群和历史服务
sbin/start-all.sh
sbin/start-history-server.sh6) 重新执行任务
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://linux1:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10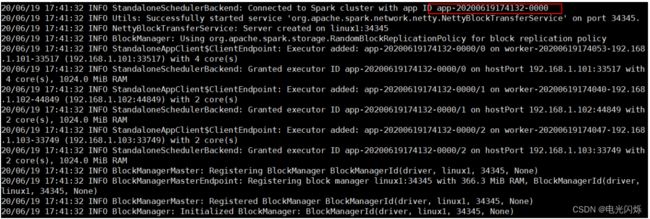
7) 查看历史服务: http://linux1:18080

2.7. 配置高可用( HA)
所谓的高可用是因为当前集群中的 Master 节点只有一个,所以会存在单点故障问题。 所以为了解决单点故障问题,需要在集群中配置多个 Master 节点,一旦处于活动状态的 Master发生故障时,由备用 Master 提供服务,保证作业可以继续执行。 这里的高可用一般采用Zookeeper 设置。
0)集群规划
Linux1:Master、Zookeeper、Worker
Linux2:Master、Zookeeper、Worker
Linux3:Zookeeper、Worker1)停止集群
sbin/stop-all.sh2)启动 Zookeeper
xstart zk3)修改 spark-env.sh 文件添加如下配置
注释如下内容:
#SPARK_MASTER_HOST=linux1
#SPARK_MASTER_PORT=7077
添加如下内容:
#Master 监控页面默认访问端口为 8080,但是可能会和 Zookeeper 冲突,所以改成 8989,也可以自定义,访问 UI 监控页面时请注意
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=linux1,linux2,linux3
-Dspark.deploy.zookeeper.dir=/spark"4)分发配置文件
xsync conf/5)启动集群
sbin/start-all.sh
6)启动 linux2 的单独 Master 节点,此时 linux2 节点 Master 状态处于备用状态
[root@linux2 spark-standalone]# sbin/start-master.sh
7)提交应用到高可用集群
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://linux1:7077,linux2:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
108)停止 linux1 的 Master 资源监控进程

9)查看 linux2 的 Master 资源监控 Web UI,稍等一段时间后, linux2 节点的 Master 状态提升为活动状态

3. Yarn模式
独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其他框架提供资源。 这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住, Spark 主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成会更靠谱一些。 所以接下来我们来学习在强大的 Yarn 环境下 Spark 是如何工作的(其实是因为在国内工作中, Yarn 使用的非常多) 。
3.1. 解压缩文件
将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到 linux 并解压缩,放置在指定位置。
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-yarn3.2. 修改配置文件
1)修改 hadoop 配置文件/opt/module/hadoop/etc/hadoop/yarn-site.xml, 并分发
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
2)修改 conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR 配置
mv spark-env.sh.template spark-env.sh
。。。
export JAVA_HOME=/opt/module/jdk1.8.0_144
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop3.3. 提交应用
注意:提交应用之前需要先启动 HDFS 以及 YARN 集群
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10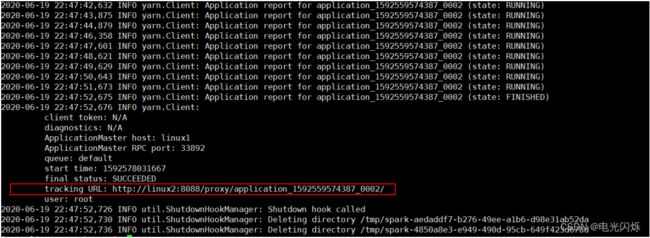
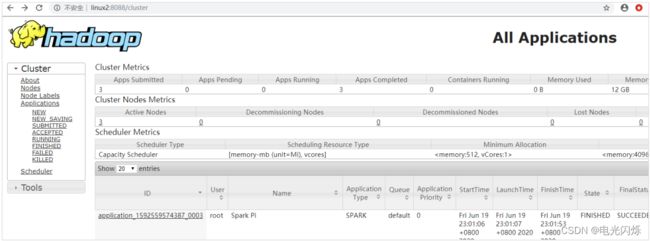
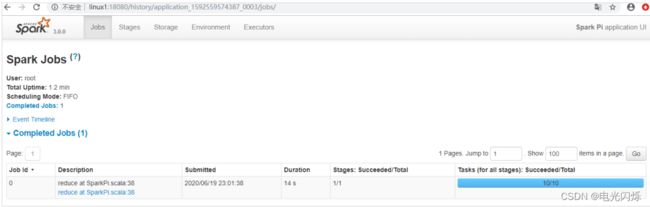
查看 http://linux2:8088 页面,点击 History,查看历史页面
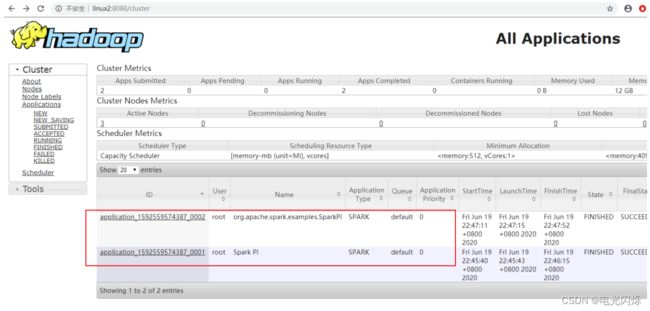

3.4. 配置历史服务器
1)修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf2)修改 spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://linux1:8020/directory
-- 注意:需要启动 hadoop 集群, HDFS 上的目录需要提前存在。
[root@linux1 hadoop]# sbin/start-dfs.sh
[root@linux1 hadoop]# hadoop fs -mkdir /directory3)修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://linux1:8020/directory
-Dspark.history.retainedApplications=30"- 参数 1 含义: WEB UI 访问的端口号为 18080
- 参数 2 含义:指定历史服务器日志存储路径
- 参数 3 含义:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
4)修改 spark-defaults.conf
spark.yarn.historyServer.address=linux1:18080
spark.history.ui.port=180805)启动历史服务
sbin/start-history-server.sh6)重新提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
7)Web 页面查看日志: http://linux2:8088
4. K8S 模式
容器化部署是目前业界很流行的一项技术,基于 Docker 镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是 Kubernetes(k8s),而 Spark也在最近的版本中支持了 k8s 部署模式。
官网链接:https://spark.apache.org/docs/latest/running-on-kubernetes.html
5. Windows 模式
自己学习时,每次都需要启动虚拟机,启动集群,这是一个比较繁琐的过程,并且会占大量的系统资源,导致系统执行变慢,不仅仅影响学习效果,也影响学习进度,Spark 非常暖心地提供了可以在 windows 系统下启动本地集群的方式,这样,在不使用虚拟机的情况下,也能学习 Spark 的基本使用。
5.1. 启动本地环境
0)将文件 spark-3.0.0-bin-hadoop3.2.tgz 解压缩到无中文无空格的路径中
1)执行解压缩文件路径下 bin 目录中的 spark-shell.cmd 文件,启动 Spark 本地环境

2)在 bin 目录中创建 input 目录,并添加 word.txt 文件, 在命令行中输入脚本代码

5.2. 命令行提交应用
在 DOS 命令行窗口中执行提交指令
spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/spark-examples_2.12-3.0.0.jar 10
6. 部署模式对比
| 模式 | Spark 安装机器数 | 需启动的进程 | 所属者 | 应用场景 |
| Local | 1 | 无 | Spark | 测试 |
| Standalone | 3 | Master 及 Worker | Spark | 单独部署 |
| Yarn | 1 | Yarn 及 HDFS | Hadoop | 混合部署 |
7. 端口号
- Spark 查看当前 Spark-shell 运行任务情况端口号: 4040(计算)
- Spark Master 内部通信服务端口号: 7077
- Standalone 模式下, Spark Master Web 端口号: 8080(资源)
- Spark 历史服务器端口号: 18080
- Hadoop YARN 任务运行情况查看端口号: 8088
注:其他Spark相关系列文章链接由此进 -> Spark文章汇总