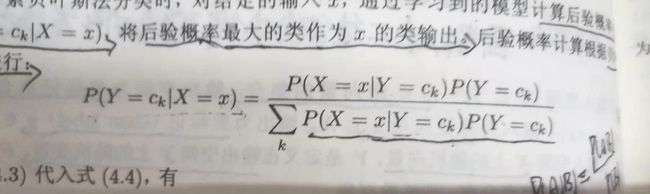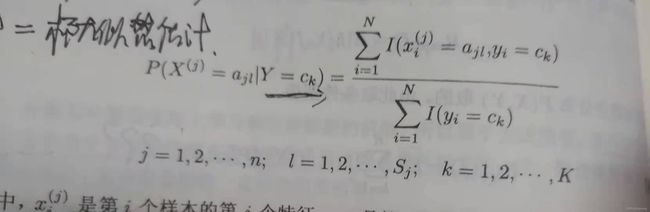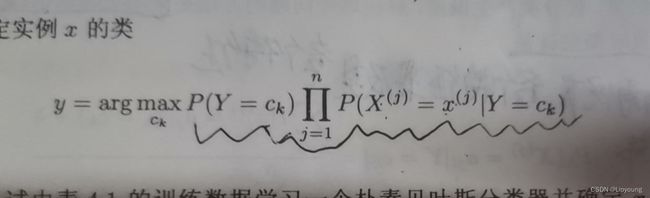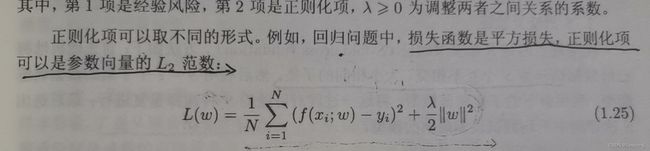- C++11堆操作深度解析:std::is_heap与std::is_heap_until原理解析与实践
文章目录堆结构基础与函数接口堆的核心性质函数签名与核心接口std::is_heapstd::is_heap_until实现原理深度剖析std::is_heap的验证逻辑std::is_heap_until的定位策略算法优化细节代码实践与案例分析基础用法演示自定义比较器实现最小堆检查边缘情况处理性能分析与实际应用时间复杂度对比典型应用场景与手动实现的对比注意事项与最佳实践迭代器要求比较器设计C++标
- 冒泡、选择、插入排序:三大基础排序算法深度解析(C语言实现)
xienda
算法排序算法数据结构
在算法学习道路上,排序算法是每位程序员必须掌握的基石。本文将深入解析冒泡排序、选择排序和插入排序这三种基础排序算法,通过C语言代码实现和对比分析,帮助读者彻底理解它们的差异与应用场景。算法原理与代码实现1.冒泡排序(BubbleSort)工作原理:通过重复比较相邻元素,将较大元素逐步"冒泡"到数组末尾。voidbubbleSort(intarr[],intn){ for(inti=0;iarr[
- Leetcode 148. 排序链表
文章目录前引题目代码(首刷看题解)代码(8.9二刷部分看解析)代码(9.15三刷部分看解析)前引综合性比较强的一道题,要求时间复杂度必须O(logn)才能通过,最适合链表的排序算法就是归并。这里采用自顶向下的方法步骤:找到链表中点(双指针)对两个子链表排序(递归,直到只有一个结点,记得将子链表最后指向nullptr)归并(引入dummy结点)题目Leetcode148.排序链表代码(首刷看题解)c
- 全面触摸屏输入法设计与实现
长野君
本文还有配套的精品资源,点击获取简介:触摸屏输入法是针对触摸设备优化的文字输入方案,包括虚拟键盘、手写、语音识别和手势等多种输入方式。本方案通过提供主程序文件、用户手册、界面截图、示例图、说明文本和音效文件,旨在为用户提供一个完整的、多样的文字输入体验。开发者通过持续优化算法和用户界面,使用户在无物理键盘环境下也能高效准确地进行文字输入。1.触摸屏输入法概述简介在现代信息技术飞速发展的今天,触摸屏
- FPGA小白到项目实战:Verilog+Vivado全流程通关指南(附光学类岗位技能映射)
阿牛的药铺
算法移植部署fpga开发verilog
FPGA小白到项目实战:Verilog+Vivado全流程通关指南(附光学类岗位技能映射)引言:为什么这个FPGA入门路线能帮你快速上岗?本文设计了一条**"Verilog语法→工具链操作→光学项目实战→岗位技能对标"的阶梯式学习路径。不同于泛泛而谈的FPGA教程,我们聚焦光学类产品开发**核心能力(时序接口设计、图像处理算法移植、高速接口应用),通过3个递进式项目(从LED闪烁到图像边缘检测),
- PyTorch & TensorFlow速成复习:从基础语法到模型部署实战(附FPGA移植衔接)
阿牛的药铺
算法移植部署pytorchtensorflowfpga开发
PyTorch&TensorFlow速成复习:从基础语法到模型部署实战(附FPGA移植衔接)引言:为什么算法移植工程师必须掌握框架基础?针对光学类产品算法FPGA移植岗位需求(如可见光/红外图像处理),深度学习框架是算法落地的"桥梁"——既要用PyTorch/TensorFlow验证算法可行性,又要将训练好的模型(如CNN、目标检测)转换为FPGA可部署的格式(ONNX、TFLite)。本文采用"
- 算法学习笔记:17.蒙特卡洛算法 ——从原理到实战,涵盖 LeetCode 与考研 408 例题
在计算机科学和数学领域,蒙特卡洛算法(MonteCarloAlgorithm)以其独特的随机抽样思想,成为解决复杂问题的有力工具。从圆周率的计算到金融风险评估,从物理模拟到人工智能,蒙特卡洛算法都发挥着不可替代的作用。本文将深入剖析蒙特卡洛算法的思想、解题思路,结合实际应用场景与Java代码实现,并融入考研408的相关考点,穿插图片辅助理解,帮助你全面掌握这一重要算法。蒙特卡洛算法的基本概念蒙特卡
- 算法学习笔记:15.二分查找 ——从原理到实战,涵盖 LeetCode 与考研 408 例题
呆呆企鹅仔
算法学习算法学习笔记考研二分查找
在计算机科学的查找算法中,二分查找以其高效性占据着重要地位。它利用数据的有序性,通过不断缩小查找范围,将原本需要线性时间的查找过程优化为对数时间,成为处理大规模有序数据查找问题的首选算法。二分查找的基本概念二分查找(BinarySearch),又称折半查找,是一种在有序数据集合中查找特定元素的高效算法。其核心原理是:通过不断将查找范围减半,快速定位目标元素。与线性查找逐个遍历元素不同,二分查找依赖
- LeetCode算法题:电话号码的字母组合
吱屋猪_
算法leetcodejava
题目描述:给定一个仅包含数字2-9的字符串,返回所有它能表示的字母组合。答案可以按任意顺序返回。给出数字到字母的映射如下(与电话按键相同)。注意1不对应任何字母。2->"abc"3->"def"4->"ghi"5->"jkl"6->"mno"7->"pqrs"8->"tuv"9->"wxyz"例如,给定digits="23",返回["ad","ae","af","bd","be","bf","cd
- 霍夫变换(Hough Transform)算法原来详解和纯C++代码实现以及OpenCV中的使用示例
点云SLAM
算法图形图像处理算法opencv图像处理与计算机视觉算法直线提取检测目标检测霍夫变换算法
霍夫变换(HoughTransform)是一种经典的图像处理与计算机视觉算法,广泛用于检测图像中的几何形状,例如直线、圆、椭圆等。其核心思想是将图像空间中的“点”映射到参数空间中的“曲线”,从而将形状检测问题转化为参数空间中的峰值检测问题。一、霍夫变换基本思想输入:边缘图像(如经过Canny边缘检测)输出:一组满足几何模型的形状(如直线、圆)关键思想:图像空间中的一个点→参数空间中的一个曲线参数空
- Java三年经验程序员技术栈全景指南:从前端到架构,对标阿里美团全栈要求
可曾去过倒悬山
java前端架构
Java三年经验程序员技术栈全景指南:从前端到架构,对标阿里美团全栈要求三年经验是Java程序员的分水岭,技术栈深度决定你成为“业务码农”还是“架构师候选人”。本文整合阿里、美团、滴滴等大厂招聘要求,为你绘制可落地的进阶路线。一、Java核心:从语法糖到JVM底层三年经验与初级的核心差异在于系统级理解,大厂面试常考以下能力:JVM与性能调优内存模型(堆外内存、元空间)、GC算法(G1/ZGC适用场
- 被动降噪的概念及编程实现
CodeByte
人工智能算法javascript编程
被动降噪是指通过编程技术和算法,对输入的数据进行处理,以减少或消除其中的噪声。噪声可以是各种形式的干扰,例如来自传感器、通信信号或其他外部源的干扰。在本文中,我们将探讨被动降噪的意义以及如何使用编程来实现这一目标。被动降噪的意义:噪声对数据的准确性和可靠性产生负面影响。在许多应用领域,例如图像处理、音频处理和信号处理中,噪声的存在可能导致数据质量下降,使得后续的分析和处理变得困难。因此,被动降噪技
- 传统检测响应慢?陌讯多模态引擎提速90+FPS实战
2501_92473147
算法计算机视觉目标检测
开篇痛点:实时目标检测在安防监控中的核心挑战在安防监控领域,实时目标检测是保障公共安全的关键技术。然而,传统算法如YOLOv5或开源框架MMDetection常面临两大痛点:误报率高(复杂光照或遮挡场景下检测不稳定)和响应延迟(高分辨率视频流处理FPS低于30)。实测数据显示,城市交通监控系统误报率达15%,导致安保资源浪费;客户反馈表明,延迟超100ms时,目标跟踪可能失效。这些问题源于算法泛化
- 反光衣识别漏检率 30%?陌讯多尺度模型实测优化
在建筑工地、交通指挥等场景中,反光衣是保障作业人员安全的重要装备,对其进行精准识别是智能监控系统的核心功能之一。但传统视觉算法在实际应用中却屡屡碰壁:强光下反光衣易与背景混淆、远距离小目标漏检率高达30%、复杂场景下模型泛化能力不足[实测数据来源:某智慧工地项目2024年Q1日志]。这些问题直接导致安全监控系统预警滞后,给安全生产埋下隐患。一、技术解析:反光衣识别的核心难点与陌讯算法创新反光衣识别
- 【GESP】C++三级真题 luogu-B4359 [GESP202506 三级] 分糖果
CoderCodingNo
GESPc++java开发语言
GESPC++三级,2025年6月真题,模拟算法,难度★★☆☆☆。本次三级题目个人感觉比较简单。题目题解详见:【GESP】C++三级真题luogu-B4359[GESP202506三级]分糖果|OneCoder【GESP】C++三级真题luogu-B4359[GESP202506三级]分糖果|OneCoderGESPC++三级,2025年6月真题,模拟算法,难度★★☆☆☆。本次三级题目个人感觉比较
- 【华为机试】HJ61 放苹果
不爱熬夜的Coder
算法华为机试golang华为golang算法面试
文章目录HJ61放苹果描述输入描述输出描述示例1示例2解题思路算法分析问题本质分析状态定义与转移递推关系详解动态规划表构建算法流程图示例推导过程代码实现思路时间复杂度分析关键优化点边界情况处理递归解法对比实际应用场景测试用例分析算法特点数学原理完整题解代码HJ61放苹果描述我们需要将m个相同的苹果放入n个相同的盘子中,允许有的盘子空着不放。求解有多少种不同的分法。输入描述输入两个整数m,n(0B[
- LangChain中的向量数据库接口-Weaviate
洪城叮当
langchain数据库经验分享笔记交互人工智能知识图谱
文章目录前言一、原型定义二、代码解析1、add_texts方法1.1、应用样例2、from_texts方法2.1、应用样例3、similarity_search方法3.1、应用样例三、项目应用1、安装依赖2、引入依赖3、创建对象4、添加数据5、查询数据总结前言 Weaviate是一个开源的向量数据库,支持存储来自各类机器学习模型的数据对象和向量嵌入,并能无缝扩展至数十亿数据对象。它提供存储文档嵌
- .NET中的安全性之数字签名、数字证书、强签名程序集、反编译
hezudao25
NET.netassembly加密算法referenceheader
本文将探讨数字签名、数字证书、强签名程序集、反编译等以及它们在.NET中的运用(一些概念并不局限于.NET在其它技术、平台中也存在)。1.数字签名数字签名又称为公钥数字签名,或者电子签章等,它借助公钥加密技术实现。数字签名技术主要涉及公钥、私钥、非对称加密算法。1.1公钥与私钥公钥是公开的钥匙,私钥则是与公钥匹配的严格保护的私有密钥;私钥加密的信息只有公钥可以解开,反之亦然。在VisualStud
- 数据结构:导论
梁辰兴
数据结构学习笔记数据结构导论算法时间复杂度空间复杂度
目录一,数据结构的研究内容二,基本概念与术语(一)数据、数据元素、数据项与数据对象(二)数据结构(三)数据类型与抽象数据类型️三,抽象数据类型的表示与实现⚙️四,算法与算法分析⚖️(一)算法的定义及特性(二)评价算法优劣的基本标准⏱️(三)算法的时间复杂度(四)算法的空间复杂度章结一,数据结构的研究内容数据结构是计算机科学的核心基础,其研究内容可概括为三大维度:数据组织形式:探索如何将现实世界中的
- C++ 标准库 <numeric>
以下对C++标准库中头文件所提供的数值算法与工具做一次系统、深入的梳理,包括算法功能、示例代码、复杂度分析及实践建议。一、概述中定义了一组对数值序列进行累加、内积、差分、扫描等操作的算法,以及部分辅助工具(如std::iota、std::gcd/std::lcm等)。所有算法均作用于迭代器区间,符合STL风格,可与任意容器或原始数组配合使用。从C++17、20起,又陆续加入了并行友好的std::r
- 具身语义导航算法总揽
Shilong Wang
具身导航算法算法
端到端方法小脑大脑GNMNavDPNaVILAViNTNomadNavidStreamVLNMapNavNavGPTUni-NavidOctoNavNavGPT2模仿学习行为克隆BCDAgger模块化方法GOATVLFMSayPlanLM-NavETPNavVoroNavEmbodiedRAGVL-NavStairwaytoSuccess业内大佬北大王鹤NavidUni-NavidOctoNav吴
- android去除gps漂移代码,GPS漂移过滤算法
扇贝君
GPS漂移过滤算法基本思想:逐点过滤,再经过基础过滤后,进行判断运动状态,静止状态和运动中。如果静止,则使用电子围栏;如果运动,则先过滤大速度,再过滤加速度,然后过滤距离(包括超大距离,和速度相关距离)。对于要过滤的点,采用之前最近的可靠点,进行替换,同时,无效次数+1,如果后面是有效点,则无效次数-1,如果无效次数归0,认为这个点才是真正可靠点(无效次数为正时,都为要被替换的点)。如果遇到不定点
- Python的科学计算库NumPy(一)
linlin_1998
pythonnumpy开发语言
NumPy(NumericalPython)是Python中最基础、最重要的科学计算库之一,提供了高性能的多维数组(ndarray)对象和大量数学函数,是许多数据科学、机器学习库(如Pandas、SciPy、TensorFlow等)的基础依赖。1.创建一个numpy里面的一维数组importnumpyasnp###通过array方法创建一个ndarrayarray1=np.array([1,2,3
- 项目开发日记
框架整理学习UIMgr:一、数据结构与算法1.1关键数据结构成员变量类型说明m_CtrlsList当前正在显示的所有UI页面m_CachesList已打开过、但现在不显示的页面(缓存池)1.2算法逻辑查找缓存页面:从m_Caches中倒序查找是否已有对应ePageType页面,找到则重用。页面加载:从资源管理器ResMgr加载prefab并绑定控制器/视图组件。页面关闭:从m_Ctrls移除,添加
- 深度学习图像分类数据集—桃子识别分类
AI街潜水的八角
深度学习图像数据集深度学习分类人工智能
该数据集为图像分类数据集,适用于ResNet、VGG等卷积神经网络,SENet、CBAM等注意力机制相关算法,VisionTransformer等Transformer相关算法。数据集信息介绍:桃子识别分类:['B1','M2','R0','S3']训练数据集总共有6637张图片,每个文件夹单独放一种数据各子文件夹图片统计:·B1:1601张图片·M2:1800张图片·R0:1601张图片·S3:
- 《C++性能优化指南》 linux版代码及原理解读 第一章
v俊逸
C++性能优化指南性能优化C++性能优化性能优化
概述:目录概述:性能优化的必要性:C++代码优化策略总结用好的编译器并用好编译器使用更好的算法使用更好的库减少内存分配和复制移除计算使用更好的数据结构提高并发性优化内存管理性能优化的必要性:按照当今的CPU运行速度来说,执行一条指令所需要的时间是10的-9次方的时间单位,如此快速的执行速度是否就没有性能优化的必要了呢?其实不然,性能优化与CPU的执行速度并无非常大的关系,试想一下,一段代码,如果用
- 《C++性能优化指南》 linux版代码及原理解读 第四章
v俊逸
C++性能优化指南性能优化C++性能优化指南性能优化
目录概述为什么字符串很麻烦字符串是动态分配的字符串赋值背后的操作如何面对字符串会进行大量复制写时复制COW(copyonwrite)尝试优化字符串避免临时字符串通过预留存储空间减少内存分配通过传递引用减少实参复制使用迭代器操作减少循环中的比较操作减少返回值的复制还没有结束,使用字符数组代替字符串再次优化字符串尝试其他的算法叠加以前的优化方式使用其他的编译器使用其他字符串的库功能丰富的字符串库使用s
- rtos内存管理
林内克思
javalinux算法
FreeRTOS将内存分配API保留在其可移植层,提供了五种内存管理算法:heap_1:最简单,不允许释放内存。heap_2:允许释放内存,但不会合并相邻的空闲块。heap_3:简单包装了标准malloc()和free(),以保证线程安全。heap_4:合并相邻的空闲块以避免碎片化。包含绝对地址放置选项。heap_5:如同heap_4,能够跨越多个不相邻内存区域的堆。特点缺点heap_1简单、不支
- c++中迭代器的本质
三月微风
c++开发语言
C++迭代器的本质与实现原理迭代器是C++标准模板库(STL)的核心组件之一,它作为容器与算法之间的桥梁,提供了统一访问容器元素的方式。下面从多个维度深入解析迭代器的本质特性。一、迭代器的基本定义与分类迭代器的本质迭代器是一种行为类似指针的对象,用于遍历和操作容器中的元素。它提供了一种统一的方式来访问不同容器中的元素,而无需关心容器的具体实现细节。标准分类体系C++标准定义了5种迭代器类型,按功能
- 微算法科技的前沿探索:量子机器学习算法在视觉任务中的革新应用
MicroTech2025
量子计算算法
在信息技术飞速发展的今天,计算机视觉作为人工智能领域的重要分支,正逐步渗透到我们生活的方方面面。从自动驾驶到人脸识别,从医疗影像分析到安防监控,计算机视觉技术展现了巨大的应用潜力。然而,随着视觉任务复杂度的不断提升,传统机器学习算法在处理大规模、高维度数据时遇到了计算瓶颈。在此背景下,量子计算作为一种颠覆性的计算模式,以其独特的并行处理能力和指数级增长的计算空间,为解决这一难题提供了新的思路。微算
- jvm调优总结(从基本概念 到 深度优化)
oloz
javajvmjdk虚拟机应用服务器
JVM参数详解:http://www.cnblogs.com/redcreen/archive/2011/05/04/2037057.html
Java虚拟机中,数据类型可以分为两类:基本类型和引用类型。基本类型的变量保存原始值,即:他代表的值就是数值本身;而引用类型的变量保存引用值。“引用值”代表了某个对象的引用,而不是对象本身,对象本身存放在这个引用值所表示的地址的位置。
- 【Scala十六】Scala核心十:柯里化函数
bit1129
scala
本篇文章重点说明什么是函数柯里化,这个语法现象的背后动机是什么,有什么样的应用场景,以及与部分应用函数(Partial Applied Function)之间的联系 1. 什么是柯里化函数
A way to write functions with multiple parameter lists. For instance
def f(x: Int)(y: Int) is a
- HashMap
dalan_123
java
HashMap在java中对很多人来说都是熟的;基于hash表的map接口的非同步实现。允许使用null和null键;同时不能保证元素的顺序;也就是从来都不保证其中的元素的顺序恒久不变。
1、数据结构
在java中,最基本的数据结构无外乎:数组 和 引用(指针),所有的数据结构都可以用这两个来构造,HashMap也不例外,归根到底HashMap就是一个链表散列的数据
- Java Swing如何实时刷新JTextArea,以显示刚才加append的内容
周凡杨
java更新swingJTextArea
在代码中执行完textArea.append("message")后,如果你想让这个更新立刻显示在界面上而不是等swing的主线程返回后刷新,我们一般会在该语句后调用textArea.invalidate()和textArea.repaint()。
问题是这个方法并不能有任何效果,textArea的内容没有任何变化,这或许是swing的一个bug,有一个笨拙的办法可以实现
- servlet或struts的Action处理ajax请求
g21121
servlet
其实处理ajax的请求非常简单,直接看代码就行了:
//如果用的是struts
//HttpServletResponse response = ServletActionContext.getResponse();
// 设置输出为文字流
response.setContentType("text/plain");
// 设置字符集
res
- FineReport的公式编辑框的语法简介
老A不折腾
finereport公式总结
FINEREPORT用到公式的地方非常多,单元格(以=开头的便被解析为公式),条件显示,数据字典,报表填报属性值定义,图表标题,轴定义,页眉页脚,甚至单元格的其他属性中的鼠标悬浮提示内容都可以写公式。
简单的说下自己感觉的公式要注意的几个地方:
1.if语句语法刚接触感觉比较奇怪,if(条件式子,值1,值2),if可以嵌套,if(条件式子1,值1,if(条件式子2,值2,值3)
- linux mysql 数据库乱码的解决办法
墙头上一根草
linuxmysql数据库乱码
linux 上mysql数据库区分大小写的配置
lower_case_table_names=1 1-不区分大小写 0-区分大小写
修改/etc/my.cnf 具体的修改内容如下:
[client]
default-character-set=utf8
[mysqld]
datadir=/var/lib/mysql
socket=/va
- 我的spring学习笔记6-ApplicationContext实例化的参数兼容思想
aijuans
Spring 3
ApplicationContext能读取多个Bean定义文件,方法是:
ApplicationContext appContext = new ClassPathXmlApplicationContext(
new String[]{“bean-config1.xml”,“bean-config2.xml”,“bean-config3.xml”,“bean-config4.xml
- mysql 基准测试之sysbench
annan211
基准测试mysql基准测试MySQL测试sysbench
1 执行如下命令,安装sysbench-0.5:
tar xzvf sysbench-0.5.tar.gz
cd sysbench-0.5
chmod +x autogen.sh
./autogen.sh
./configure --with-mysql --with-mysql-includes=/usr/local/mysql
- sql的复杂查询使用案列与技巧
百合不是茶
oraclesql函数数据分页合并查询
本片博客使用的数据库表是oracle中的scott用户表;
------------------- 自然连接查询
查询 smith 的上司(两种方法)
&
- 深入学习Thread类
bijian1013
javathread多线程java多线程
一. 线程的名字
下面来看一下Thread类的name属性,它的类型是String。它其实就是线程的名字。在Thread类中,有String getName()和void setName(String)两个方法用来设置和获取这个属性的值。
同时,Thr
- JSON串转换成Map以及如何转换到对应的数据类型
bijian1013
javafastjsonnet.sf.json
在实际开发中,难免会碰到JSON串转换成Map的情况,下面来看看这方面的实例。另外,由于fastjson只支持JDK1.5及以上版本,因此在JDK1.4的项目中可以采用net.sf.json来处理。
一.fastjson实例
JsonUtil.java
package com.study;
impor
- 【RPC框架HttpInvoker一】HttpInvoker:Spring自带RPC框架
bit1129
spring
HttpInvoker是Spring原生的RPC调用框架,HttpInvoker同Burlap和Hessian一样,提供了一致的服务Exporter以及客户端的服务代理工厂Bean,这篇文章主要是复制粘贴了Hessian与Spring集成一文,【RPC框架Hessian四】Hessian与Spring集成
在
【RPC框架Hessian二】Hessian 对象序列化和反序列化一文中
- 【Mahout二】基于Mahout CBayes算法的20newsgroup的脚本分析
bit1129
Mahout
#!/bin/bash
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information re
- nginx三种获取用户真实ip的方法
ronin47
随着nginx的迅速崛起,越来越多公司将apache更换成nginx. 同时也越来越多人使用nginx作为负载均衡, 并且代理前面可能还加上了CDN加速,但是随之也遇到一个问题:nginx如何获取用户的真实IP地址,如果后端是apache,请跳转到<apache获取用户真实IP地址>,如果是后端真实服务器是nginx,那么继续往下看。
实例环境: 用户IP 120.22.11.11
- java-判断二叉树是不是平衡
bylijinnan
java
参考了
http://zhedahht.blog.163.com/blog/static/25411174201142733927831/
但是用java来实现有一个问题。
由于Java无法像C那样“传递参数的地址,函数返回时能得到参数的值”,唯有新建一个辅助类:AuxClass
import ljn.help.*;
public class BalancedBTree {
- BeanUtils.copyProperties VS PropertyUtils.copyProperties
诸葛不亮
PropertyUtilsBeanUtils
BeanUtils.copyProperties VS PropertyUtils.copyProperties
作为两个bean属性copy的工具类,他们被广泛使用,同时也很容易误用,给人造成困然;比如:昨天发现同事在使用BeanUtils.copyProperties copy有integer类型属性的bean时,没有考虑到会将null转换为0,而后面的业
- [金融与信息安全]最简单的数据结构最安全
comsci
数据结构
现在最流行的数据库的数据存储文件都具有复杂的文件头格式,用操作系统的记事本软件是无法正常浏览的,这样的情况会有什么问题呢?
从信息安全的角度来看,如果我们数据库系统仅仅把这种格式的数据文件做异地备份,如果相同版本的所有数据库管理系统都同时被攻击,那么
- vi区段删除
Cwind
linuxvi区段删除
区段删除是编辑和分析一些冗长的配置文件或日志文件时比较常用的操作。简记下vi区段删除要点备忘。
vi概述
引文中并未将末行模式单独列为一种模式。单不单列并不重要,能区分命令模式与末行模式即可。
vi区段删除步骤:
1. 在末行模式下使用:set nu显示行号
非必须,随光标移动vi右下角也会显示行号,能够正确找到并记录删除开始行
- 清除tomcat缓存的方法总结
dashuaifu
tomcat缓存
用tomcat容器,大家可能会发现这样的问题,修改jsp文件后,但用IE打开 依然是以前的Jsp的页面。
出现这种现象的原因主要是tomcat缓存的原因。
解决办法如下:
在jsp文件头加上
<meta http-equiv="Expires" content="0"> <meta http-equiv="kiben&qu
- 不要盲目的在项目中使用LESS CSS
dcj3sjt126com
Webless
如果你还不知道LESS CSS是什么东西,可以看一下这篇文章,是我一朋友写给新人看的《CSS——LESS》
不可否认,LESS CSS是个强大的工具,它弥补了css没有变量、无法运算等一些“先天缺陷”,但它似乎给我一种错觉,就是为了功能而实现功能。
比如它的引用功能
?
.rounded_corners{
- [入门]更上一层楼
dcj3sjt126com
PHPyii2
更上一层楼
通篇阅读完整个“入门”部分,你就完成了一个完整 Yii 应用的创建。在此过程中你学到了如何实现一些常用功能,例如通过 HTML 表单从用户那获取数据,从数据库中获取数据并以分页形式显示。你还学到了如何通过 Gii 去自动生成代码。使用 Gii 生成代码把 Web 开发中多数繁杂的过程转化为仅仅填写几个表单就行。
本章将介绍一些有助于更好使用 Yii 的资源:
- Apache HttpClient使用详解
eksliang
httpclienthttp协议
Http协议的重要性相信不用我多说了,HttpClient相比传统JDK自带的URLConnection,增加了易用性和灵活性(具体区别,日后我们再讨论),它不仅是客户端发送Http请求变得容易,而且也方便了开发人员测试接口(基于Http协议的),即提高了开发的效率,也方便提高代码的健壮性。因此熟练掌握HttpClient是很重要的必修内容,掌握HttpClient后,相信对于Http协议的了解会
- zxing二维码扫描功能
gundumw100
androidzxing
经常要用到二维码扫描功能
现给出示例代码
import com.google.zxing.WriterException;
import com.zxing.activity.CaptureActivity;
import com.zxing.encoding.EncodingHandler;
import android.app.Activity;
import an
- 纯HTML+CSS带说明的黄色导航菜单
ini
htmlWebhtml5csshovertree
HoverTree带说明的CSS菜单:纯HTML+CSS结构链接带说明的黄色导航
在线体验效果:http://hovertree.com/texiao/css/1.htm代码如下,保存到HTML文件可以看到效果:
<!DOCTYPE html >
<html >
<head>
<title>HoverTree
- fastjson初始化对性能的影响
kane_xie
fastjson序列化
之前在项目中序列化是用thrift,性能一般,而且需要用编译器生成新的类,在序列化和反序列化的时候感觉很繁琐,因此想转到json阵营。对比了jackson,gson等框架之后,决定用fastjson,为什么呢,因为看名字感觉很快。。。
网上的说法:
fastjson 是一个性能很好的 Java 语言实现的 JSON 解析器和生成器,来自阿里巴巴的工程师开发。
- 基于Mybatis封装的增删改查实现通用自动化sql
mengqingyu
DAO
1.基于map或javaBean的增删改查可实现不写dao接口和实现类以及xml,有效的提高开发速度。
2.支持自定义注解包括主键生成、列重复验证、列名、表名等
3.支持批量插入、批量更新、批量删除
<bean id="dynamicSqlSessionTemplate" class="com.mqy.mybatis.support.Dynamic
- js控制input输入框的方法封装(数字,中文,字母,浮点数等)
qifeifei
javascript js
在项目开发的时候,经常有一些输入框,控制输入的格式,而不是等输入好了再去检查格式,格式错了就报错,体验不好。 /** 数字,中文,字母,浮点数(+/-/.) 类型输入限制,只要在input标签上加上 jInput="number,chinese,alphabet,floating" 备注:floating属性只能单独用*/
funct
- java 计时器应用
tangqi609567707
javatimer
mport java.util.TimerTask; import java.util.Calendar; public class MyTask extends TimerTask { private static final int
- erlang输出调用栈信息
wudixiaotie
erlang
在erlang otp的开发中,如果调用第三方的应用,会有有些错误会不打印栈信息,因为有可能第三方应用会catch然后输出自己的错误信息,所以对排查bug有很大的阻碍,这样就要求我们自己打印调用的栈信息。用这个函数:erlang:process_display (self (), backtrace).需要注意这个函数只会输出到标准错误输出。
也可以用这个函数:erlang:get_s