交通标志识别项目教程
项目结构图

下载好项目压缩包后解压,得到以上的文件,首先将画红圈的文件删除(如果有)
安装软件
安装Anaconda
安装Pycharm
安装格式工厂

在上图中这个位置输入cmd回车,即可打开命令终端。用这样的方式打开命令终端可以确保输入命令的位置就是当前文件夹所在的位置:

如果不放心,可以输入dir验证一下:

接下来我们开始虚拟环境的创建虚拟环境,并且安装本项目中python用到的第三方库
创建虚拟环境
conda create -n tranfficSignRec python=3.8
激活虚拟环境
activate tranfficSignRec
国内常用镜像源地址
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:https://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
豆瓣:http://pypi.douban.com/simple/
安装项目所需的包
安装格式如下(==版本号可以省略)
pip install XXX==版本号 -i 镜像源地址
方案一
分别执行以下命令:
pip install tensorflow-cpu==2.5.0
pip install pandas==1.4.1
pip install matplotlib==3.5.1
pip install scikit-image==0.19.2
pip install playsound ==1.3.0
# 如果报错尝试加上在版本号后面加上( --user)或者(-i 镜像源地址)比如:
# pip install tensorflow-cpu==2.5.0 --user
# pip install tensorflow-cpu==2.5.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
# pip install tensorflow-cpu==2.5.0 -i --user https://pypi.tuna.tsinghua.edu.cn/simple
# 如果还是报错可以选择相近的版本,比如:
# pip install tensorflow-cpu==2.4.0
方案二
一步到位直接安装requirements.txt中所有的依赖包,确保requirements.txt文件在当前文件夹,如果不在当前文件夹就需要加上requirements.txt的路径。
pip install -r requirements.txt
用pycharm打开项目
打开pycharm后鼠标在左上角找到File点击Open

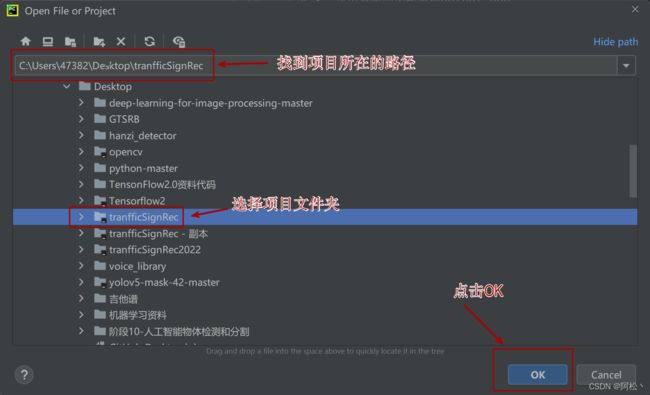
选择项目所在路径,选择项目对应的文件夹点击打开。注意图片中文件夹下面的黑点表示之前打开过这个项目,相当于一个小标记,方便我们寻找自己的项目文件。
选择python解释器(也就是我们创建的虚拟环境)

运行代码

整个神经网络训练的过程大概需要“30分钟–3个小时“,具体取决于你的电脑的性能。
预测部分的代码
在此之前简单科普一下Python中的正斜杠与反斜杠:
首先,"/“左倾斜是正斜杠,”"右倾斜是反斜杠,可以记为:除号是正斜杠一般来说对于目录分隔符,Linux和Web用正斜杠/,Windows用反斜杠。
比如我们要用python读取windows电脑中的一张图片它的路径为C:\Users\47382\Desktop\tranfficSignRec\prediction\pre.jpg

直接用path = “C:\Users\47382\Desktop\tranfficSignRec\prediction\pre.jpg"是会报错的。
因为python代码默认会对”\t"、"\r"等进行转义,正确方式如下:
# 1.可以再加一个反斜杠"\"进行反转义,
path = "C:\\Users\\47382\\Desktop\\tranfficSignRec\\prediction\\pre.jpg"
# 2.或是在最前面加上一个"r"取消转义。
path = r"C:\Users\47382\Desktop\tranfficSignRec\prediction\pre.jpg"
# 3.直接用正斜杠"/"拼接路径(同时适用Linux和Windows的python环境)
path = r"C:/Users/47382/Desktop/tranfficSignRec/prediction/pre.jpg"
用训练好的神经网络识别交通标志
关于语音提示功能
本项目额外的一个功能是识别出交通标志的同时给出语音提示。打开文件voice_library这个文件夹里面有对应(0-42)一共43个标志的语音提示。

上图这(0-42)一共43个标志的语音提示,对应的就是下图的顺序。这个交通标志的语音提示,需要我们自己录一下(可以根据自己的喜好弄得有个性一点哦*-*),但是注意语音包的命名和格式需要跟上面保持一致。命名是0-42,格式是wav格式。可以下载一个叫“格式工厂”的软件转化一下,很简单弄的。
然后还需要安装一个python的语音模块的第三方库:
# 安装之前同样需要先进入我们创建的虚拟环境
pip install playsound ==1.3.0
如下图所示,我们用的数据集德国的交通标志的数据集,所以你得先知道各个交通标志的含义,自己百度一下。

预测我们选择的一张交通标志
找一张交通标志图像(格式最好是jpg)将它放在prediction这个目录下面.

复制这个图片的路径:
右击选择copy path选项,可以选择图片的绝对路径:
我这里是:C:\Users\47382\Desktop\tranfficSignRec\prediction\pre.jpg

用这中方法将代码predict.py里的路径换成自己实际的路径。然后运行就可以实现交通标志的识别和语音提示了。

点击运行
