PyTorch官方demo:图像分类 LeNet
是参考B站一位up主的,感觉讲的很好,讲解的每节课程在csdn上做了一个目录:
https://blog.csdn.net/qq_37541097/article/details/103482003
这一节的up主的参考资料如下:
- b站讲解视频:
https://www.bilibili.com/video/BV187411T7Ye - 代码:
https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_classification/Test1_official_demo
这个例子是在PyTorch官网上讲解的:
- https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html#
中文翻译版可以参考:
- https://pytorch.apachecn.org/docs/1.4/blitz/cifar10_tutorial.html
01 运行demo
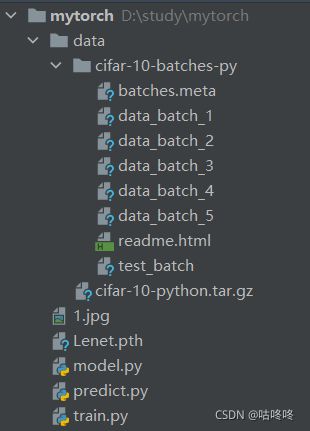
1.1 文件结构
-
model.py——定义LeNet网络模型 -
train.py——加载数据集并训练,训练集计算loss,测试集计算accuracy,保存训练好的网络参数 -
predict.py——得到训练好的网络参数后,用自己找的图像进行分类测试
1.2 下载数据集
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_set = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
运行结果:

1.3 代码
model.py
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 定义卷积层,参数in_channels输入特征矩阵的深度(如果输入RBG彩色图像就为3),outchannels卷积核的个数,kernelsize卷积核的大小
self.conv1 = nn.Conv2d(3, 16, 5)
# 定义下采样层,2×2说明缩小为一半
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# output 28=(w-f+2p)/s+1=32(图像尺寸大小)-5(卷积核大小)+0(padding=0)/stride(步距为1)+1 = 28
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
train.py
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
def main():
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)
# 导入训练数据集,batch_size 批次处理,shuffle是否打乱数据,默认true
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=5000,
shuffle=False, num_workers=0)
# 把val_loader转为可迭代的迭代器
val_data_iter = iter(val_loader)
val_image, val_label = val_data_iter.next()
# 定义分类
# classes = ('plane', 'car', 'bird', 'cat',
# 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
# 定义损失函数
loss_function = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.Adam(net.parameters(), lr=0.001)
# 同一个训练集多次训练
for epoch in range(5): # loop over the dataset multiple times
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
# get the inputs; data is a list of [inputs, labels]
# inputs表示训练的图片,labels表示图片的正确分类
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
# outputs表示输出训练数据的分类结果
outputs = net(inputs)
# 训练结果和真实结果计算loss
loss = loss_function(outputs, labels)
# 损失反向传播
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
# 每500次打印输出
if step % 500 == 499: # print every 500 mini-batches
with torch.no_grad():
# 输入验证数据集
outputs = net(val_image) # [batch, 10]
# 分类的概率最大的那个类就是结果
predict_y = torch.max(outputs, dim=1)[1]
# 计算准确度
accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0
print('Finished Training')
save_path = './Lenet.pth'
# 训练模型存储
torch.save(net.state_dict(), save_path)
if __name__ == '__main__':
main()
predict.py
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
def main():
transform = transforms.Compose(
[transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
net.load_state_dict(torch.load('Lenet.pth'))
im = Image.open('1.jpg')
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # [N, C, H, W]
with torch.no_grad():
outputs = net(im)
predict = torch.max(outputs, dim=1)[1].data.numpy()
print(classes[int(predict)])
if __name__ == '__main__':
main()
1.4 预测
- 先运行train.py生成网络。运行结果如下:
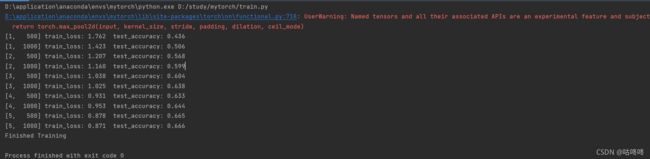
好像PyTorch1.90有点问题,所以会报下面的警告,但不影响正常使用。
D:\application\anaconda\envs\mytorch\python.exe D:/study/mytorch/train.py
D:\application\anaconda\envs\mytorch\lib\site-packages\torch\nn\functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at ..\c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
- 然后运行predict.py预测图片
02 代码说明
关于代码的说明基本都已经在上面的代码中注释了。
其他还可以参考下面的两个:
- 代码说明参考: https://blog.csdn.net/m0_37867091/article/details/107136477
- 有关卷积网络的函数可参考:https://blog.csdn.net/qq_37541097/article/details/102926037
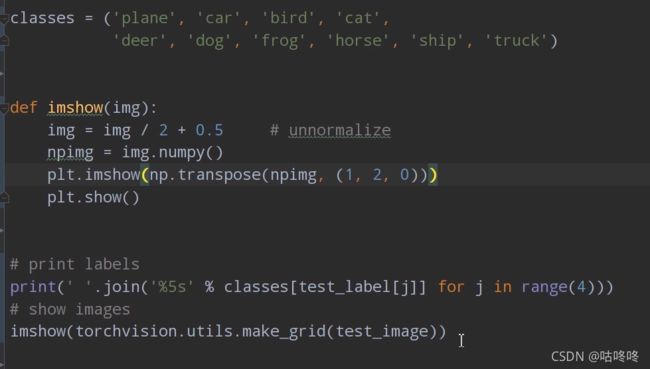
想查看数据集中的图片可以使用下述代码:
需要注意的是,
pytorch的数据张量形式为:[batch, channel, height, width]
而图片的数据形式为:[height,width,channel]
所以图片转pytorch中张量,就需要换数据形式,并且在最前面扩增一维;
pytorch中张量转图片,也需要话数据顺序,比如plt.imshow(np.tr anspose(npimg, (1, 2, 0)))
在windows下,num_worker只能为0
在Ubuntu下,将num_worker改大一点,可以加快训练速度

03 使用gpu运行train.py
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)
# 导入训练数据集,batch_size 批次处理,shuffle是否打乱数据,默认true
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=5000,
shuffle=False, num_workers=0)
# 把val_loader转为可迭代的迭代器
val_data_iter = iter(val_loader)
val_image, val_label = val_data_iter.next()
# 定义分类
# classes = ('plane', 'car', 'bird', 'cat',
# 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
net.to(device) # 将网络分配到指定的device中
# 定义损失函数
loss_function = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.Adam(net.parameters(), lr=0.001)
# 同一个训练集多次训练
for epoch in range(5): # loop over the dataset multiple times
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
# get the inputs; data is a list of [inputs, labels]
# inputs表示训练的图片,labels表示图片的正确分类
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
# outputs表示输出训练数据的分类结果
# outputs = net(inputs)
outputs = net(inputs.to(device)) # 将inputs分配到指定的device中
# 训练结果和真实结果计算loss
# loss = loss_function(outputs, labels)
loss = loss_function(outputs, labels.to(device)) # 将labels分配到指定的device中
# 损失反向传播
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
# 每500次打印输出
if step % 500 == 499: # print every 500 mini-batches
with torch.no_grad():
# 输入验证数据集
# outputs = net(val_image) # [batch, 10]
outputs = net(val_image.to(device)) # 将test_image分配到指定的device中
# 分类的概率最大的那个类就是结果
predict_y = torch.max(outputs, dim=1)[1]
# 计算准确度
# accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
accuracy = (predict_y == val_label.to(device)).sum().item() / val_label.size(0) # 将test_label分配到指定的device中
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0
print('Finished Training')
save_path = './Lenet.pth'
# 训练模型存储
torch.save(net.state_dict(), save_path)
if __name__ == '__main__':
main()
说明
- 定义device为gpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
或直接指定
device = torch.device("cuda")
- 需要用
to()函数来将Tensor在CPU和GPU之间相互移动,分配到指定的device中计算
① 定义网络后,将网络分配到gpu
net = LeNet()
net.to(device) # 将网络分配到指定的device中
② 将训练过程中的inputs和labels分配到gpu中
outputs = net(inputs.to(device)) # 将inputs分配到指定的device中
loss = loss_function(outputs, labels.to(device)) # 将labels分配到指定的device中
③ 将val_image分配到指定的gpu中
outputs = net(val_image.to(device)) # 将val_image分配到指定的device中
accuracy = (predict_y == val_label.to(device)).sum().item() / val_label.size(0) # 将val_image分配到指定的device中
综上,定义device+把张量放入device,一共有6处需要修改