MySQL表的增删改查(基础)
目录
- 数据库介绍
- MySQL数据库基础
-
- 创建数据库
- 查看所有数据库
- 选中指定的数据库
- 删除数据库
- 数据库表操作
-
- mysql的数据类型
- 表操作
- MySQL表的增删改查(基础)
-
- 新增 insert
- 查询retrieve
- 修改(update)
- 删除(delete)
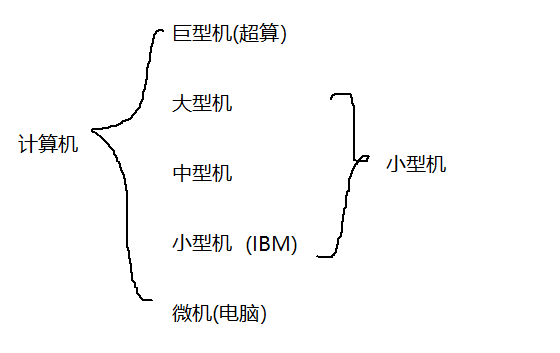
数据库介绍
数据库是一类软件,这种软件能对数据进行管理(增删改查)。数据库是一个基于数据结构实现出来的软件。数据库里面已经把数据结构封装好了。
数据库典型代表:
1.MySQL
2.Oracle
3.SQL Server
网站开发四剑客LAMP:
L:Linux
A:apache
M:mysql
P:php
MariaDB(MySQL的一个分支)
Java现在的版权属于Oracle公司
企业中使用的服务器系统主要是Linux

MySQL/Oracle/SQLServer是软件,SQL是一个编程语言(结构化的查询语言),这个语言是运行在MySQL/Oracle/SQLServer之上的,就像Java运行在JVM之上)。
这几个数据库软件上支持的SQL其实在语法上上稍有不同,但大体相当。
MySQL数据库基础
MySQL是一个客户端(client),服务器(server)结构的软件。客户端:主动发送数据的一方。
服务器:被动接受数据的一方。
请求(request):客户端给服务器发送的数据。
相应(response):服务器给客户端返回的数据。
-
客户端和服务器之间是通过网络来进行通信的。
-
一个服务器是可以同时给多个客户端提供服务的。多个客户- 端可以同时给服务器发请求,服务器进行相应的响应。
-
特殊情况:一个服务器只给特定的客户端提供服务,一般出现在分布式系统,各个节点之间的通信。
-
客户端和服务器,可以在同一个主机上,也可以在不同的主机上。无论是不是同一个主机,都是通过网络来进行通信的。当客户端和服务器都在一个主机上,电脑不联网不影响数据库的使用,电脑上有一个特殊的环回网卡,可以让自己发自己收,不通过网线/wifi都可以进行通信。
-
服务器是存储数据的本体。
-
客户端是和用户交互的部分。
-
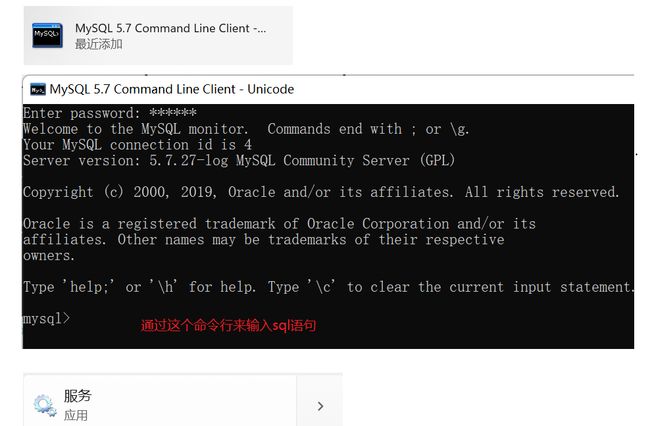
命令行客户端是自带的客户端。
除此之外还有图形化客户端。navicat/mysql workbench/idea自带了客户端。 -
数据是存储在主机的硬盘上的。
一个计算机的组成部分(4个):CPU,存储器,输入设备,输出设备。(冯诺依曼体系结构)
存储器:
内存:平时说的内存,比如电脑是16GB内存, 机带RAM
外存:硬盘,软盘,U盘,光盘。
(硬盘:比如电脑硬盘512GB,C盘+D盘。比如手机128GB内存。)
(软盘:存储空间很小,一般几M)
(6G运存其实是内存)
(手机也是计算机,也是遵循冯诺依曼体系结构的)
内存和外存的区别:
1.内存上读写数据的速度快,外存的读写速度慢,(速度能差3-4个数量级,也就是几千倍甚至上万倍)
2.内存空间比较小,外存空间比较大。(比如电脑是16GB内存,电脑外存512GB)
3.内存比外存贵。
4.内存的数据是“易失”的,断电后数据会丢失。外存的数据是持久的,断电后数据还在。
(系统文件之类的必须持久化存储)
-
数据库存储的数据,存储空间很大,持久化保存。
-
关系型数据库,具体组织数据的格式/结构。
-
每一个数据库是一个数据集合,每一个数据集合中又有一些数据表(类似于excel表格)。

一个表中每一行是一条数据,称为是一条记录(record)。一行里又有很多列,每一列称为一个字段(field)。
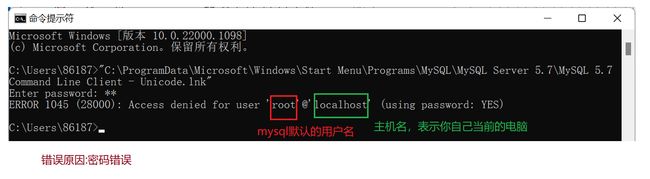
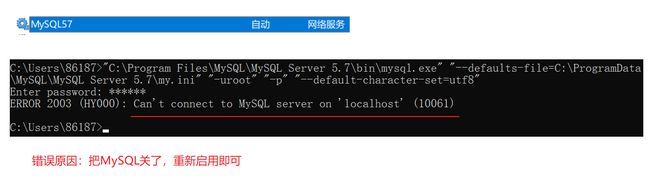
出错情况:

创建数据库
create database 数据库名;

-
数据库是在操作硬盘。
-
创建数据库的时候还可以指定数据库的字符集。
-
一般常用的是utf8,mysql里面的utf8不完整。utf8里面无法表示emoji(表情),后来mysql弄了个utf8mb4(完全体utf8)。
在计算机中,一个汉字占几个字节取决于你当前所使用的字符集,编码方式。先声明字符集,再说占的字节数。
ascii码:计算机中用数字来表示英文字母。
(英文字母比较少,算上阿拉伯数字和标点符号,一个字节足够)
(但是汉字有6万个左右,可以用2个字节来编码,2个字节表示的数据范围是0-65535)
使用2个字节来表示汉字的方式最典型的就是GBK。
(windows简体中文版默认的编码方式就是gbk)
GBK虽然能表示汉字,但是世界上还有很多其他语言文字,2个字节不够了,就是用更多的字节来表示。
utf-8(可以支持各种语言文学,是当前最主流使用的编码方式),变长编码,长度是不固定的,对于汉字来说,utf-8一般是3个字节。
if not exists
加上这个就不报错(只是有个警告),存在就不创建,不存在就创建
- SQL很多时候是写到一个文件中,批量执行,如果执行过程中,某个操作报错了,后续代码无法继续执行。
查看所有数据库
show databases;

mysql是在硬盘上持久化存在的。
选中指定的数据库
use 数据库名;
- 一个mysql服务器上有很多个数据库,要进行操作得先确定是对哪个数据库进行操作。
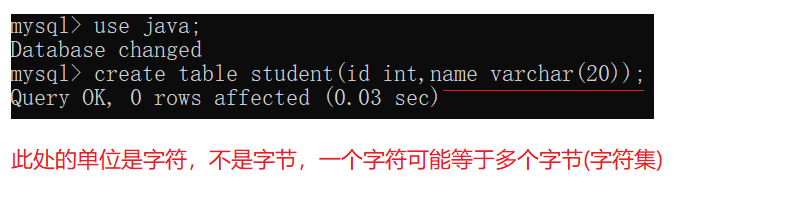
删除数据库
drop database 数据库名;
删库是个非常危险的操作,谨慎操作!!!
数据库表操作
mysql的数据类型
数值类型:
| 数据类型 | 大小 | 说明 | 对应Java类型 |
|---|---|---|---|
| BIT[ (M) ] | M指定位数,默认为1 | 二进制数,M范围从1到64,存储数值范围从0到2^M-1 | 常用Boolean对应Bit,此时默认是1位,即只能存0和1 |
| TINYINT | 1字节 | Byte | |
| SMALLINT | 2字节 | Short | |
| INT | 4字节 | Integer | |
| BIGINT | 8字节 | Long | |
| FLOAT(M,D) | 4字节 | 单精度,M指定长度,D指定小数位数。会发生精度丢失 | Float |
| DOUBLE(M,D) | 8字节 | Double | |
| DECIMAL(M,D) | M/D最大值+2 | 单精度,M指定长度,D表示小数点位数。精确数值 | BigDecimal |
| NUMERIC(M,D) | M/D最大值+2 | 和DECIMAL一样 | BigDecimal |
(SQL先于Java出现,所以数据类型不统一)
单精度/双精度浮点数
指定类型带参数,M表示有效数字位数,D表示小数点后保留几位。
(并不保存精确的数据)
IEEE 754 标准(C语言数据在内存中的存储),内存模型就决定了无法精确表示数据,存在误差。
decimal精确的表示浮点数,牺牲了存储空间,牺牲了运算速度,换来了更精确的表示方式。
常用类型:int , double ,decimal
字符串类型:
| 数据类型 | 大小 | 说明 | 对应Java类型 |
|---|---|---|---|
| VARCHAR(SIZE) | 0-65535字节 | 可变长度字符串 | String |
| TEXT | 0-65535字节 | 长文本数据 | String |
| MEDIUMTEXT | 0-16777215字节 | 中等长度文本数据 | String |
| BLOB | 0-65535字节 | 二进制形式的长文本数据 | byte[] |
varchar 最常用的字符串的类型,带有一个参数,约定了存储的最大空间。(根据实际需求,来决定设置个多长的合适)
text和mediumtext更适合于更长的字符串(很少见)
blob主要存二进制数据
如何区分一个文件是文本还是二进制?
文本文件里存的是字符值,二进制文件存的是二进制值。
用记事本打开这个文件,如果能看懂说明是文本,如果看不懂说明是二进制
(word.docx和excel.xlsx都是二进制)
日期类型:
| 数据类型 | 大小 | 说明 | 对应Java类型 |
|---|---|---|---|
| DATETIME | 8字节 | 范围从1000到9999年,不会进行时区的检索和转换 | java.util.Date、java.sql.Timestamp |
| TIMESTAMP | 4字节 | 范围从1970到2038年,自动检索当前时区并进行转换 | java.util.Date、java.sql.Timestamp |
srand(time(0));
C语言生成随机数(伪随机,随机种子,只要种子一样生成的随机数就一样,就需要每次程序启动都设置个不同的随机种子,典型的就是"时间戳")
计算机里面生成随机数,大多数是伪随机,通过一系列复杂的数学公式,针对某个数字进行数学变换,就会得到一个新的数字,这个新数字和之前的数字看起来就毫无关联,并且生成的数字足够多,概率分布也是均匀的。
表操作
1.创建表
create table 表名(列名 类型;列名 类型;列名 类型…);
- 要想进行表操作,务必要先选中数据库(先use某个数据库名)
全世界的编程语言主要是两大类:
C类:
C++,Java,Pythion,Go…(市面上见到的语言大多是这个类别,代码好理解,但是不一定对,容易出bug)Lisp类:
Haskell,Scala(函数式编程,代码大概率对,但是不好理解)
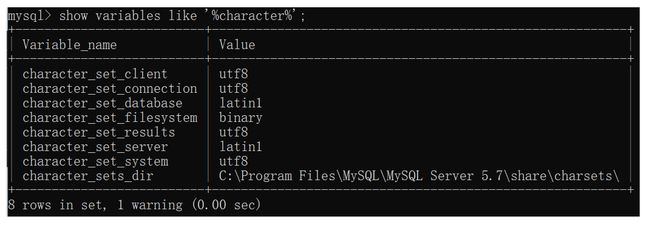
mysql默认是拉丁文,不支持中文
-
同一个数据库中不能有两个表名字相同
-
表名和列名不能和sql的关键字重复。
-
如果是在要用关键字当表名,可以用``反引号括起来。
create table stu_test (
id int,
name varchar(20) comment '姓名',
password varchar(50) comment '密码',
age int,
sex varchar(1),
birthday timestamp,
amout decimal(13,2)
resume text
);
-
comment表示注释,这个注释只能在创建表的时候使用,其他时候用不了。
-
更建议用–来表示,–和//都表示行注释。
2.查看所有表
-
前提是已经选中了数据库。
-
选中哪个数据库,就能看到哪些数据表。
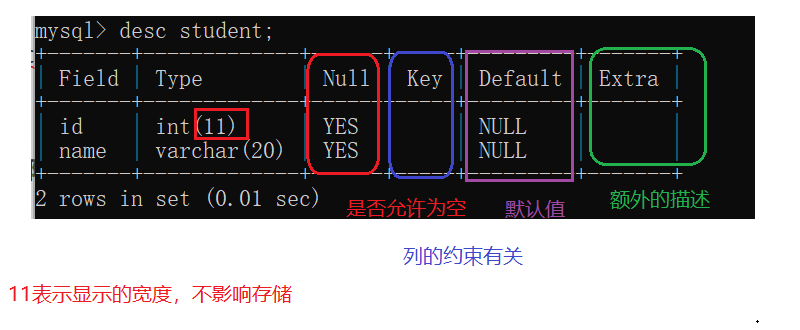
3.查看指定表的结构
- 就是看表里的内容。
desc 表名;
- desc->desribe描述
4.删除表
drop table 表名;
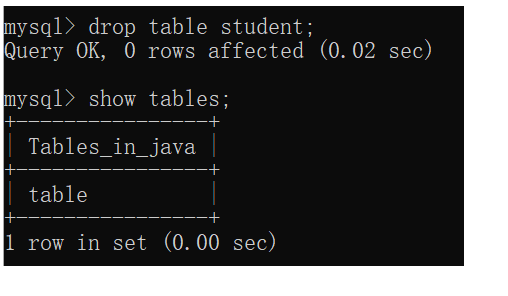
删除表比删除库更危险。一个数据库里有很多个数据表,只删一个表比把表全删了更危险。(只删一个表,难以发现,此时问题被隐藏起来了,海量数据不知道哪些是对的,哪些是错的)
decimal精确的表示浮点数,牺牲了存储空间,牺牲了运算速度。
能否有办法能既快,又能省空间,还能精确?
用Int 来表示钱,单位用分即可。
MySQL表的增删改查(基础)
操作数据库最主要的操作是增删改查(CURD)
C create 新增
U update 修改
R retrieve 查询
D delete 删除
新增 insert
insert into 表名 values (列,列,列…);
-
每次新增都是新增一行(一条记录)
-
进行增删改查之前务必要先选中数据库
-
在SQL中,‘和“都可以表示字符串(SQL中没有字符类型,只有字符串类型,其他没有字符类型的编程语言也基本上是单引号双引号都行的)
-
values()括号里的内容,个数和类型要和表的结构匹配

- 比如列名不匹配报错。
创建数据库的时候,是可以手动指定字符集的。如果没有显式指定,此时默认的字符集拉丁文,不能支持中文。
创建数据库,如果手动指定了字符集,以手动指定的为准。如果没有手动指定,此时就会读取mysql的配置文件(my.ini),配置文件里面也会写一个字符集,配置文件如果从来没有改过,默认情况下是拉丁文。
my.ini这个配置文件可以用everything这个工具来找,也可以用地址来找。
- 通过地址找到my.ini配置文件,修改两个字符集,然后保存文件,重启mysql服务器。(如果重启失败,说明配置文件改错了,所以改之前先备份)
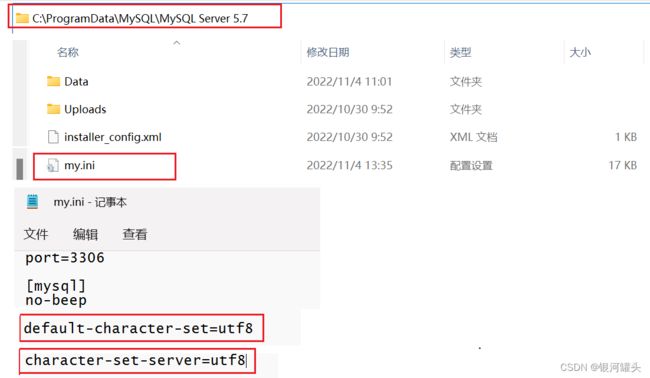
显示出mysql内置的一些变量的值,这些变量的值可以改。
insert 除了可以插入完整的一行数据外,还可以指定插入,此时未被指定的列是以默认值来进行填充的
还可以一次插入多行
insert into student (id, name) values
(2, '张三'),
(3, '李四');
在mysql中,一次插入1条记录分10次插入效率要低于一次把10条记录一起插入。
(mysql是客户端服务器结构,客户端insert语句到服务器,服务器返回1 row affected)
(原因1:通过网络访问,发起网络请求,和返回网络响应,每一次都有时间开销)
(原因2:数据库服务器是把数据保存在硬盘上的)
(原因3:mysql关系型数据库,每次进行一个sql操作,内部会开启一个事务,每次开启事务也有一定的开销)
查询retrieve
- select是sql中最复杂的操作。
select * from 表名;
*叫做通配符,代表了所有的列。
2)指定列查询查询操作会遍历所有的数据,把数据从硬盘上读出来, 通过网卡进行发送,如果数据量很大,就很容易把硬盘IO吃满,或者把网络带宽吃满。
服务器的硬件资源是有限的,包括不限于CPU,内存,硬盘,网络带宽,如果在一些场景中,把某个资源吃满了,很容易导致程序出现严重问题。
(正是有上述矛盾的存在,才有了分布式,本质上就是增加更多的机器,提供更多的硬件资源)
select 列名 from 表名;
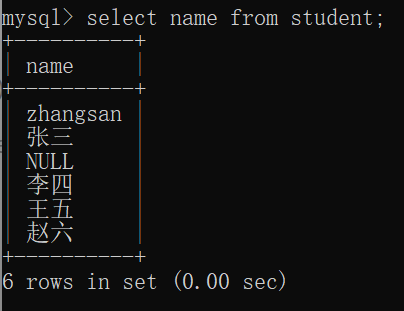
decimal精度问题



在命令行中,ctrl+c 是终止当前要执行/输入的内容。这个操作相当于放弃了之前输入的内容,或者某个sql执行时间太长,也可以通过ctrl+c来放弃。
3)查询列为表达式,在查询过程中进行简单的计算,(列和列之间)。在命令行中,选中sql语句,按enter,就是复制这一行内容,再按鼠标右键就是粘贴。
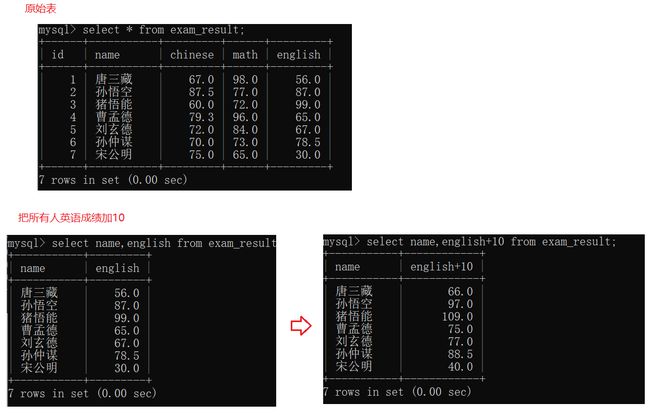
在进行表达式查询时,查询结果是一个临时表,这个临时表没有写入硬盘,这个临时表的类型也不是和原始表完全一致(会尽可能的把数据表示进去),比如猪悟能的英语成绩临时表中为109.0,不符合原始表中有效数字3位的要求。

可见原始表数据不变。select只是查询,无论如何操作select,都不会影响到硬盘上的数据。
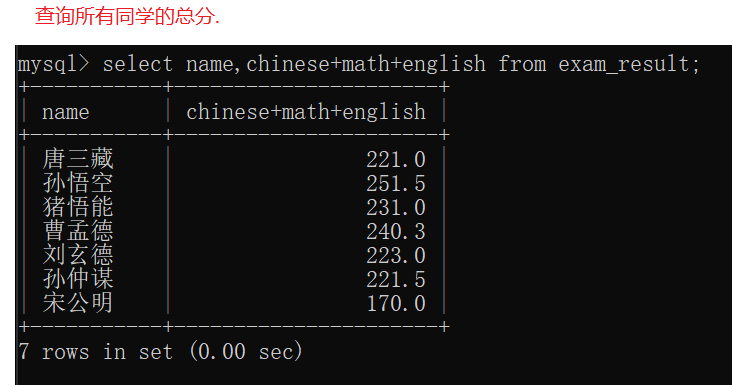
表达式查询只是针对每一行的对应列进行运算,无法进行"行和行"之间的计算。
4)给查询结果的列,指定别名。使用表达式查询时,查询的临时表的列名,就是写的表达式。

这样写别名,容易让人看错。

5)查询的时候针对列进行去重操作(把有重复的记录合并成一个)。
关键字:distinct
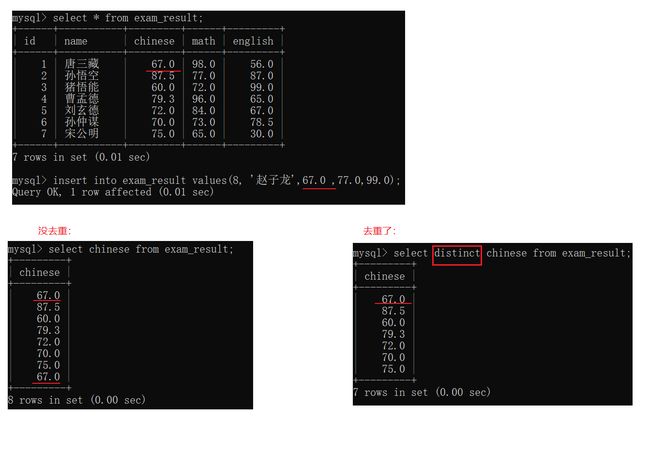
distinct也可以指定多个列去重

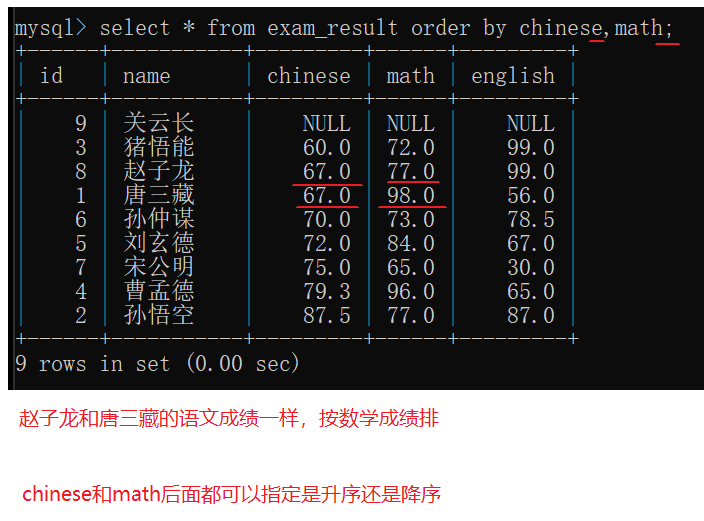
6)针对查询结果进行排序
order by子句

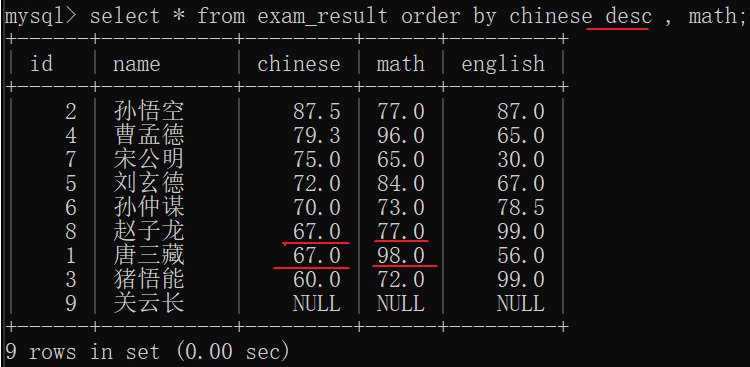
order by默认升序排序
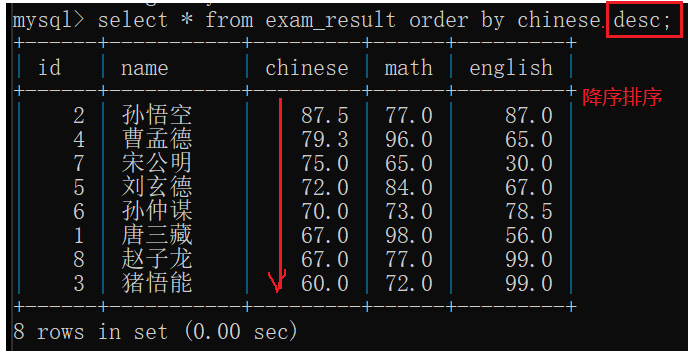
之前查看表结构也出现desc(desribe)
这里降序出现的desc(descend)
升序:asc(可以省略不写)
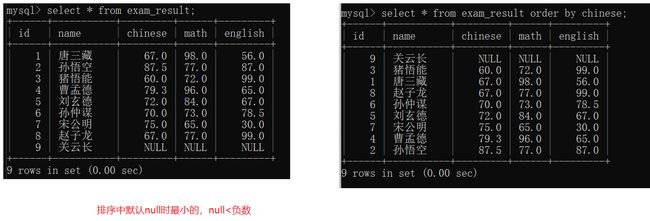
排序可以针对表达式/别名来排序
比如对所有人总分进行排序:
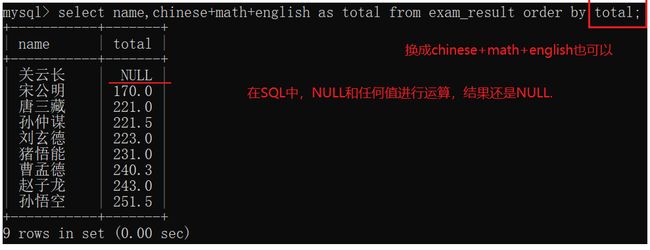
排序还可以指定多个列进行排序(优先级)
7)条件查询,针对查询结果,按照一定的条件进行筛选。
条件查询:where
(通过where指定一个"条件",把查询到的每一行,都带入到结果中,看条件是真还是假,是真就保留作为临时表结果,假的就舍弃)
要想能够描述一个"条件",需要一些逻辑运算符和关系运算符。
比较运算符:
| 运算符 | 说明 |
|---|---|
| >,>=,<,<= | |
| = | 等于,NULL不安全,例如NULL=NULL的结果是NULL |
| <=> | 等于,NULL安全,例如NULL<=>NULL的结果是TRUE(1) |
| !=,<> | 不等于 |
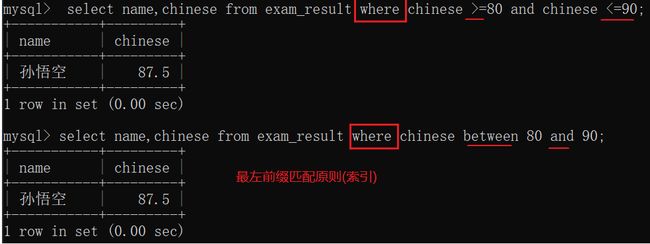
| BETWEEN a0 AND a1 | 范围匹配,[a0,a1],如果a0<=value<=a1,返回TRUE(1) |
| IN(option,…) | 如果是option中的任意一个,返回TRUE(1) |
| IS NULL | |
| IS NOT NULL | |
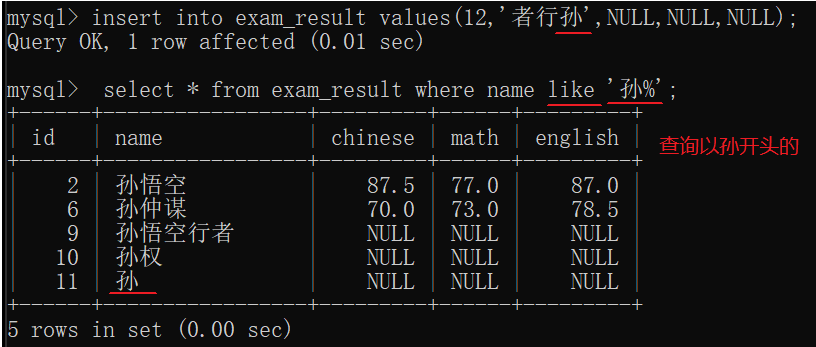
| LIKE | 模糊匹配。%表示多个(包括0个)任意字符,_表示任意一个字符。 |
注意:
在sql的where子句中,=的作用是比较相等。
使用=来比较某个值和NULL的相等关系,结果是NULL。NULL又会被当成false.
<=>是针对NULL特殊处理.
计算机中提到区间一般是[),前闭后开区间。而SQL是[],因为SQL诞生太早。
逻辑运算符:and , or , not.
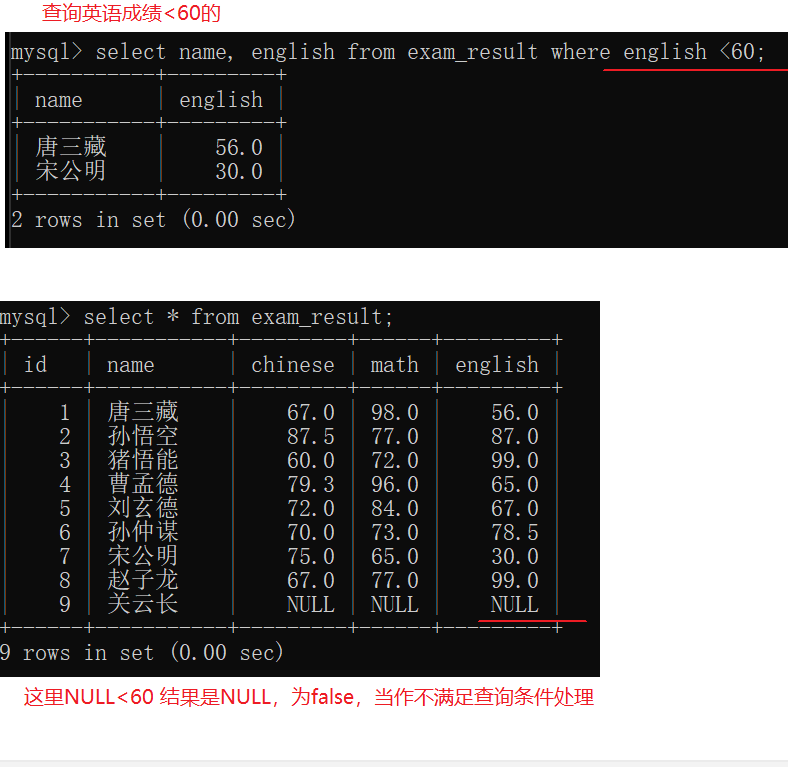

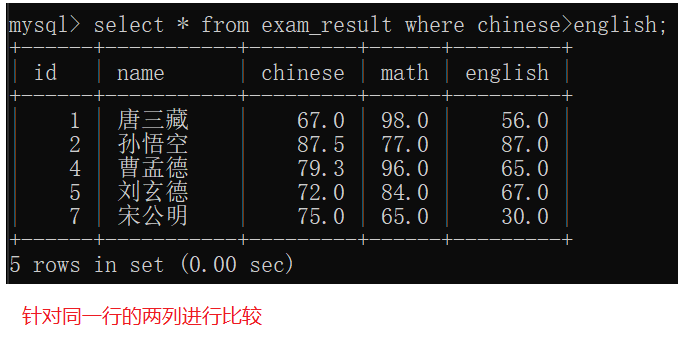

- mysql里执行查询操作时,先针对每一条记录计算条件,筛选,满足条件的记录才会去计算表达式生成别名。
(先执行where再执行as total)
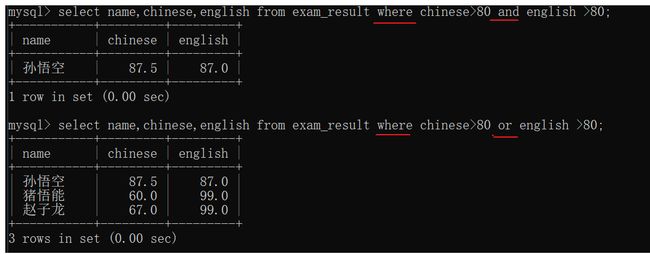
- 条件中同时有and和or,先计算and后计算or.最好的办法是加上().


-
注意:把’孙‘换成任意字符串同理。
-
模糊查询对于数据库来说开销是比较大的。
-
(正则表达式:使用一些特殊的规则来描述一个字符串,查询/进行其他操作时,按照这套规则进行匹配)
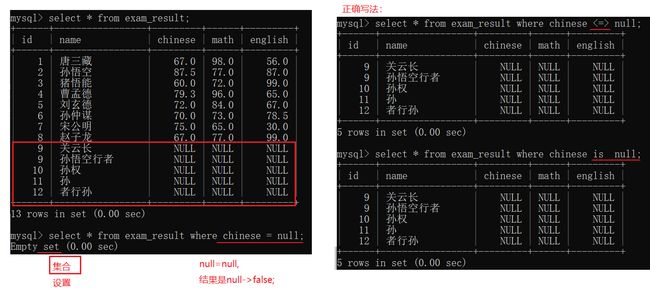
is null只能比较一个列是否为空,<=>可以直接比较两个列

条件查询where很关键,可以搭配select/update/delete使用,对应条件的用法也是相同的。
- (where子句可以对查询结果数量进行控制,让select这个操作相对没那么"危险")
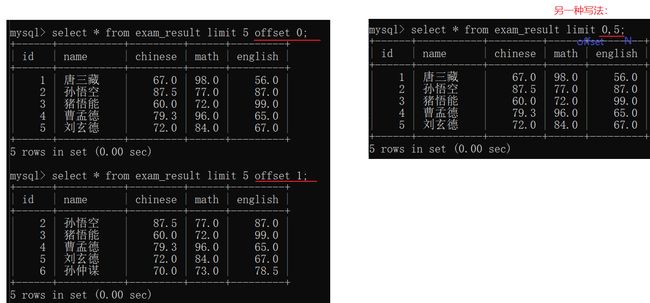
在数据库中,针对分页查询是通过limit来实现的
limit N,查到的是前N条。搭配offset就可以指定从第几条开始筛选了。
关于select:
1.全列查询 select * from 表名;
2.指定列查询 select 列名 from 表名;
3.带表达式的查询 select 表达式 from 表名;
4.带别名的查询 select 列名/表达式 as 表达式 from 表名;
5.去重查询 select distinct 列名 from 表名;
6.排序 select 列名 from 表名 order by 列名/表达式/别名 asc/desc;
7.条件 select 列名 from 表名 where 条件;
8.分页查询 select 列名 from 表名 limit N offset N;
修改(update)
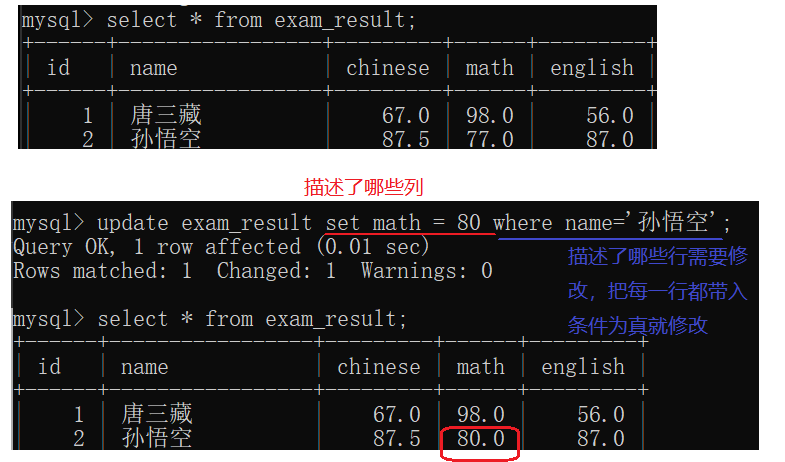
update 表名 set 列名 = 值 where 条件;
- 这个修改操作是在改服务器的硬盘数据,是持久生效的。
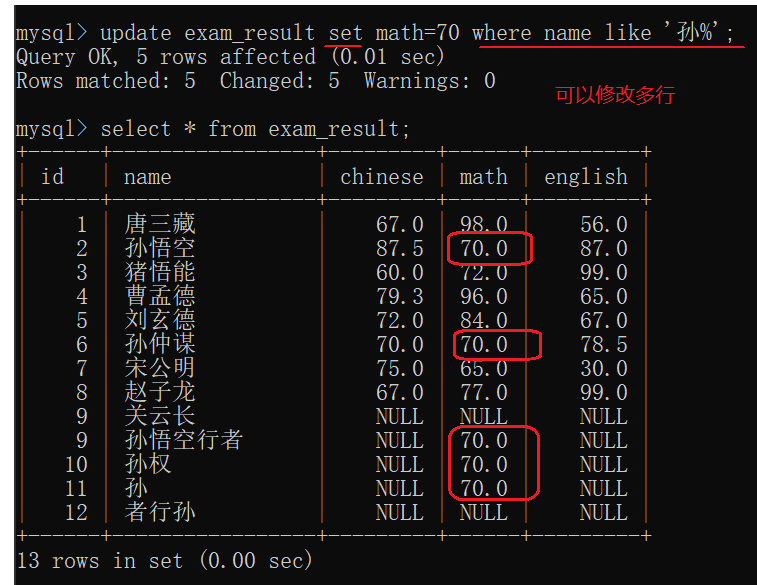
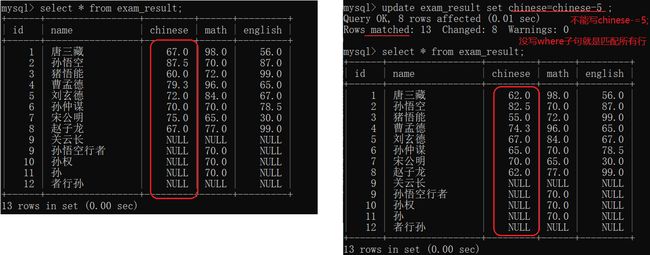
- update还可以修改多个列。
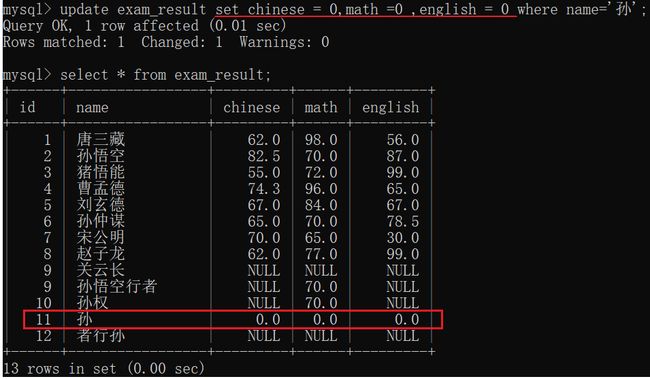
- update还可以搭配order by/limit等子句使用

删除(delete)
delete from 表名 where 条件;
注意区分:
insert into 表名;
select from 表名;
update 表名;
delete from 表名;

