数据仓库Hive——DDL详细数据操作
文章目录
- 一、Hive基本概念
-
- 1.什么是Hive
- 2.Hive的优缺点
- 3.Hive的架构原理
- 4.Hive和数据库的比较
- 二、Hive DDL的基本操作指令
-
- 1.展示数据库
- 2.使用数据库
- 3.展示表
- 4.导入数据
- 5.用Hive查看HDFS目录文件
- 6.用Hive查看本地目录
- 7.查看hive历史操作命令
- 8.查看表的详细信息
- 9.创建表
-
- 9.1 这是创建csv的方法,创建tsv就是by '\t'
- 9.2 创建内部表:
- 9.3 根据查询结果创建表
- 9.4根据已经存在的表创建表
- 9.5 创建外部表
- 10.关于分区表
-
- 10.1 创建分区表并且导入数据
- 10.2 对于多个分区表的联合查询操作(这样的对表操作会比单区表快很多,使用一个MapReduce案例就知道了)
- 10.3 创建一个新的分区
- 10.4 创建多个分区
- 10.5 查询已创建的所有分区
- 10.6 删除一个分区
- 10.7 查看分区表结构
- 10.8 创建二级分区表
- 11.将数据直接上传到HDFS
-
- 11.1 上传数据之后修复
- 11.2 上传数据后再添加分区
- 11.3 上传数据后load数据到分区
- 12.修改表
-
- 12.1 修改表名
- 12.2 对列进行修改操作
一、Hive基本概念
1.什么是Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类sql查询功能。
本质是:将HQL转化成MapReduce程序,因为
(1)Hive处理的数据存储在HDFS
(2)Hive分析数据底层的实现是MapReduce
(3)执行程序在yarn上
2.Hive的优缺点
优点:
(1)操作接口采用类sql语法,提供快速开发的能力(简单容易上手)
(2)避免去写MapReduce,减少学习成本
(3)Hive的执行延迟比较高,因此Hive常常用于数据分析,不适用于实时
(4)Hive擅长处理大数据,不擅长处理小数据,因此执行延迟比较高
(5)Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
缺点:
(1)Hive的HQL表达能力有限(迭代式算法无法表达,数据挖掘方面不擅长)
(2)Hive效率低(Hive自带的MapReduce作业,通常情况下 不够智能化,调优很困难,粒度较粗)
3.Hive的架构原理
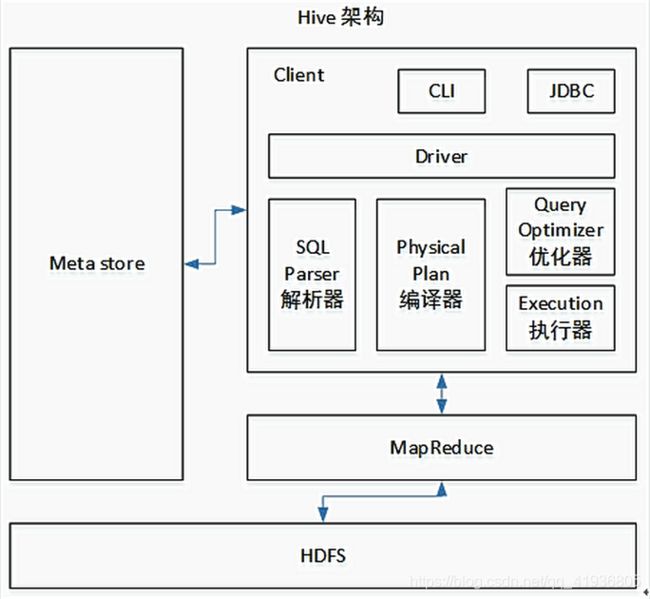
左侧,MetaStore元数据,我们会把元数据存放到Mysql里面,元数据包括表名,表所属的数据库(默认是default)、表的拥有者、字段、表的类型(是否是外部表)、表的数据所在目录等等。
中间的Client,主要使用的还是ssm框架去访问hive,满足C/S(client/Server)架构
其中最重要的是
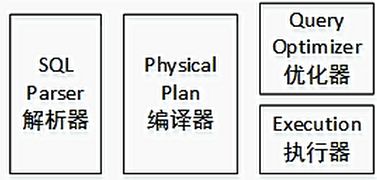
在这个部分,Hive将sql语句翻译成了Mapreduce,首先,用sql解析器去解析sql语句,解析之后用编译器去编译,然后把编译计划进行调优处理,最后进行执行器处理,执行器调用底层的MapReduce。
4.Hive和数据库的比较
由于Hive所采用的是HQL语言,因此很容易将Hive理解成数据库,其实从结构上来说,除了sql查询语言差不多以外,也没什么一样的了,因为大多数据库是为了Online而服务的,但是Hive是为了当做数据仓库。
<1>Hive的数据存储位置
Hive是建立在Hadoop之上的,所以Hive的数据都是存储在HDFS中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
<2>Hive数据更新
由于Hive是针对数据仓库设计的,而数据仓库的内容是读多写少。因此Hive不支持对数据的改写和添加,所有的数据都是在加载的时候就确定好的。而数据库中的数据通常是经常需要修改的,所以就可以使用Insert into…values添加数据,使用update set 修改数据,和mysql语法也差不多。
<3>索引
Hive加载数据的时候不会对key进行扫描,所以要是查询满足条件的数据的时候就要扫描全部数据,这就会产生很大的延迟,但是我们用到Hive的时候时常会应用到MapReduce,而MapReduce支持大规模的并行计算,这也就让Hive能够很好的处理大数据,而不适合处理延迟时间长的小数据,所以,Hive不适合实时处理数据。(这里建议实时处理数据还是老老实实用storm或者kafka+SparkStreaming,可以看我之前的文章)
<4>执行
Hive中大多数查询的执行是通过Hadoop提供的MR进行实现的,而数据库常常有自己的搜索引擎。
<5>数据规模
由于Hive建立在集群上并且可以使用MR进行并行计算,因此可以支持很大规模的数据;对应的,数据库支持的数据规模较小。
二、Hive DDL的基本操作指令
1.展示数据库
hive> show databases;
OK
default
Time taken: 0.024 seconds, Fetched: 1 row(s)
2.使用数据库
hive> use default;
OK
Time taken: 0.022 seconds
3.展示表
hive> show tables;
OK
sougou
Time taken: 0.124 seconds, Fetched: 1 row(s)
4.导入数据
hive> load data local inpath '/home/centos01/modules/apache-hive-1.2.2-bin/iotmp/mfd_day_share_interest.csv' into table default.mfd_interest_data;
5.用Hive查看HDFS目录文件
hive> dfs -lsr /;
lsr: DEPRECATED: Please use 'ls -R' instead.
drwxr-xr-x - centos01 supergroup 0 2019-02-22 14:55 /user/hive/warehouse
drwxr-xr-x - centos01 supergroup 0 2019-02-22 14:55 /user/hive/warehouse/mfd_interest_data
-rwxr-xr-x 1 centos01 supergroup 9740 2019-02-22 14:55 /user/hive/warehouse/mfd_interest_data/mfd_day_share_interest.csv
drwxr-xr-x - centos01 supergroup 0 2019-01-11 10:50 /user/hive/warehouse/sougou
也可以用
hive> dfs -ls /;
查看根目录文件,不导出所有文件了就
6.用Hive查看本地目录
hive> ! ls /home;
centos01
总结,在Hive控制台,使用!后可以直接使用本地命令的查看预览操作
7.查看hive历史操作命令
[centos01@linux01 ~]$ cat .hivehistory
8.查看表的详细信息
hive> desc formatted mfd_interest_external;
OK
# col_name data_type comment
tdate bigint
interest double
year_interest double
# Detailed Table Information
Database: default
Owner: centos01
CreateTime: Fri Feb 22 16:55:46 CST 2019
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://linux01:8020/user/hive/warehouse/mfd_interest_external
Table Type: EXTERNAL_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE true
EXTERNAL TRUE
numFiles 1
totalSize 9740
transient_lastDdlTime 1550835770
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim ,
serialization.format ,
Time taken: 0.083 seconds, Fetched: 33 row(s)
9.创建表
9.1 这是创建csv的方法,创建tsv就是by ‘\t’
hive> create table mfd_interest_data(tdate bigint,interest_rate double,year_date double) row format delimited fields terminated by ',';
OK
Time taken: 2.071 seconds
9.2 创建内部表:
我们平时所创建的表,默认都是管理表,也就是内部表,因为这种表,Hive会或多或少的控制着数据的生命周期。Hive默认情况下会将这些数据存储存在由配置项hive.metastore.warehouse.dir所定义的目录的子目录之下。而且,当我们删除这个表的时候,Hive也会删除这个表中的数据,管理表不适合和其他工具共享数据。
hive> create table if not exists stu (id int,name string) row format delimited fields terminated by ',' stored as textfile location '/user/hive/warehouse/student';
OK
Time taken: 0.077 seconds
hive>
9.3 根据查询结果创建表
create table if not exists stu3 as select tdate,interest_rate,year_date;
9.4根据已经存在的表创建表
create if not exists stu4 like stu3;
9.5 创建外部表
因为表是外部表,所以Hive并非认为其完全拥有这份数据。删除该表也不会删除表所拥有的数据,不过描述表的metastore信息会被删除。
外部表和内部表的使用场景:每天将收集到的网站日志定期流入HDFS文本文件。在外部表(原始日志表)的基础上做大量分析,用到的中间表和结果表使用内部表存储,数据通过Select + Insert进入内部表。
hive> create external table if not exists mfd_interest_external (tdate bigint,interest double,year_interest double) row format delimited fields terminated by ',';
OK
Time taken: 0.144 seconds
10.关于分区表
分区表实际上就是针对HDFS的文件系统上的独立文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过where的子句中的表达式选择查询所需要的指定的分区,这样的查询效率会高很多
10.1 创建分区表并且导入数据
hive> create table if not exists user_interst_partition(ttdate bigint,interest double,seven_interest double) partitioned by (tdate string) row format delimited fields terminated by ',';
OK
Time taken: 0.114 seconds
hive> load data local inpath '/home/centos01/modules/apache-hive-1.2.2-bin/iotmp/mfd_day_share_interest.csv' into table user_interst_partition partition(tdate='201408');
Loading data to table default.user_interst_partition partition (tdate=201408)
Partition default.user_interst_partition{tdate=201408} stats: [numFiles=1, numRows=0, totalSize=9773, rawDataSize=0]
OK
Time taken: 1.075 seconds
10.2 对于多个分区表的联合查询操作(这样的对表操作会比单区表快很多,使用一个MapReduce案例就知道了)
hive> select * from user_interst_partition where (tdate='201407') union select * from user_interst_partition where tdate='201408';
Query ID = centos01_20190223090920_78d319dd-50c7-4f9c-b441-835a6589bd46
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2019-02-23 09:09:24,277 Stage-1 map = 100%, reduce = 0%
2019-02-23 09:09:25,297 Stage-1 map = 100%, reduce = 100%
Ended Job = job_local1321650509_0001
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 29319 HDFS Write: 29319 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
10.3 创建一个新的分区
hive> alter table user_interst_partition add partition (tdate='201407');
OK
Time taken: 0.143 seconds
10.4 创建多个分区
hive> alter table user_interst_partition add partition (tdate='201401')partition(tdate='201402');
OK
Time taken: 0.223 seconds
10.5 查询已创建的所有分区
hive> show partitions user_interst_partition;
OK
tdate=201401
tdate=201402
tdate=201407
tdate=201408
Time taken: 0.08 seconds, Fetched: 4 row(s)
10.6 删除一个分区
hive> alter table user_interst_partition drop partition(tdate='201807');
OK
Time taken: 0.064 seconds
删除多分区的话,就用逗号隔开每一个partition即可,但是创建却不需要逗号。
10.7 查看分区表结构
hive> desc formatted user_interst_partition;
OK
# col_name data_type comment
ttdate bigint
interest double
seven_interest double
# Partition Information
# col_name data_type comment
tdate string
# Detailed Table Information
Database: default
Owner: centos01
CreateTime: Sat Feb 23 09:04:42 CST 2019
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://linux01:8020/user/hive/warehouse/user_interst_partition
Table Type: MANAGED_TABLE
Table Parameters:
transient_lastDdlTime 1550883882
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim ,
serialization.format ,
Time taken: 0.064 seconds, Fetched: 34 row(s)
10.8 创建二级分区表
hive> create table if not exists user_interest_partition(ttdate bigint,interest double,seven_interest double) partitioned by (tyear string,tmonth string) row format delimited fields terminated by ',';
OK
Time taken: 0.09 seconds
其他方法雷同,就是多了个分区
11.将数据直接上传到HDFS
把数据直接上传到分区目录上,让分区表和数据产生关联的三种方式
11.1 上传数据之后修复
数据准备
hive> create table short_table (name string,age int) partitioned by (year string,month string)row format delimited fields terminated by '\t';
OK
Time taken: 0.061 seconds
hive> select * from short_table;
OK
Time taken: 0.055 seconds
hive> load data local inpath '/home/centos01/modules/apache-hive-1.2.2-bin/examples/files/x.txt' into table short_table partition(year='2010',month='01');
Loading data to table default.short_table partition (year=2010, month=01)
Partition default.short_table{year=2010, month=01} stats: [numFiles=1, numRows=0, totalSize=13, rawDataSize=0]
OK
先在hdfs创建文件
hive> dfs -mkdir -p /user/hive/warehouse/short_table/year=2010/month=01;
hive> dfs -put /home/centos01/modules/apache-hive-1.2.2-bin/examples/files/x.txt /user/hive/warehouse/short_table/year=2010/month=01;

然后数据导入
hive> dfs -put /home/centos01/modules/apache-hive-1.2.2-bin/iotmp/mfd_day_share_interest.csv /user/hive/warehouse/user_interest_partition/year=2013/month=09;
hive> dfs -put /home/centos01/modules/apache-hive-1.2.2-bin/iotmp/mfd_day_share_interest.csv /user/hive/warehouse/user_interest_partition/year=2013/month=10;
查询我们导入的数据
hive> select * from short_table where year='2010' and month='01';
OK
Time taken: 0.285 seconds
发现什么也没有,所以下面执行修复命令
hive> msck repair table short_table;
OK
Partitions not in metastore: user_interest_partition:year=2013/month=09
Time taken: 0.101 seconds, Fetched: 1 row(s)
然后在查看就可以了
hive> select * from short_table where year='2010' and month='01';
OK
Joe 2 2010 01
Hank 2 2010 01
Time taken: 0.09 seconds, Fetched: 2 row(s)
11.2 上传数据后再添加分区
上传数据
hive> dfs -mkdir -p /user/hive/warehouse/short_table/year=2010/month=03;
hive> dfs -put /home/centos01/modules/apache-hive-1.2.2-bin/examples/files/x.txt /user/hive/warehouse/short_table/year=2010/month=03;
然后查询,发现没有
hive> select * from short_table where year = '2010' and month ='03';
OK
Time taken: 0.07 seconds
这个时候我们添加分区
hive> alter table short_table add partition(year='2010',month='03');
OK
Time taken: 0.145 seconds
然后发现会查询成功
hive> select * from short_table where year='2010' and month='03';
OK
Joe 2 2010 03
Hank 2 2010 03
Time taken: 0.354 seconds, Fetched: 2 row(s)
11.3 上传数据后load数据到分区
创建目录
hive> dfs -mkdir -p /user/hive/warehouse/short_table/year=2010/month=04;
导入数据
hive> load data local inpath '/home/centos01/modules/apache-hive-1.2.2-bin/examples/files/x.txt' into table short_table partition(year='2010',month='04');
Loading data to table default.short_table partition (year=2010, month=04)
Partition default.short_table{year=2010, month=04} stats: [numFiles=1, numRows=0, totalSize=13, rawDataSize=0]
OK
Time taken: 0.267 seconds
查询数据
hive> select * from short_table where year=
> '2010' and month='04';
OK
Joe 2 2010 04
Hank 2 2010 04
Time taken: 0.113 seconds, Fetched: 2 row(s)
12.修改表
12.1 修改表名
hive> alter table short_table rename to shortTable;
OK
Time taken: 0.218 seconds
12.2 对列进行修改操作
添加列
hive> alter table shortTable add columns(sex string);
OK
Time taken: 0.211 seconds
更新列
hive> alter table shortTable change column age desc float;
OK
Time taken: 0.108 seconds
hive> select * from shortTable;
OK
Joe 2.0 NULL 2010 01
Hank 2.0 NULL 2010 01
Joe 2.0 NULL 2010 03
Hank 2.0 NULL 2010 03
Joe 2.0 NULL 2010 04
Hank 2.0 NULL 2010 04
Time taken: 0.07 seconds, Fetched: 6 row(s)
替换列
hive> alter table shortTable replace columns(dname string,dage string);
OK
Time taken: 0.043 seconds
hive> select * from shortTable;
OK
Joe 2 2010 01
Hank 2 2010 01
Joe 2 2010 03
Hank 2 2010 03
Joe 2 2010 04
Hank 2 2010 04