Python深度学习14——Keras实现Transformer中文文本十分类
背景介绍
Transformer有多火就不用说啦,在NLP领域大放异彩。现在的Transformer早就迁移到别的领域去了,比如图像处理,音频文件,时间序列等。本次案例还是演示最经典 的文本分类问题。
比上次的外卖数据集高级一点,这次的数据集是一个主题分类,十个主题,而且数据量很大,有6w多条。Transformer在序列文本数据,尤其是超大量数据上的表现会很好。所以用这个数据集来验证Transformer比其他类型的网络(RNN,LSTM,GRU,CNN1D)的优越性。
当然,需要这个文本数据集和停用词的还是可以留言评论找博主要,留下邮箱 有空会发你的。
模型介绍
我知道很多同学来看我这篇博客都是为了Transformer的代码,但是别急, 我做这个案例还构建了很多其他的模型,总共14个模型——MLP、1DCNN、RNN、LSTM、GRU、CNN+LSTM、TextCNN、BILSTM、Attention、MultiHeadAttention、Attention+BiLSTM、BiGRU+Attention、Transformer、PositionalEmbedding+Transformer。
要一起对比才能说明Transformer的优越性不是吗。
为了方便代码复用,我模型定义都是一块定义的,都在build_model() 函数里面
急不可耐的同学可以直接翻到我的 build_model() 函数里面的最后两个模型处,那里就是Transformer的代码,当然都是Transformer的编码器结构,如下图:
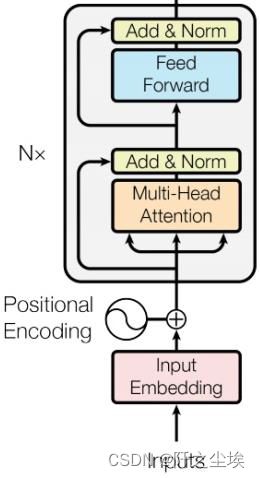
对于文本分类的问题,Transformer的编码器就已经够用了,如果是文本生成或者是翻译等任务才需要解码器。
本次构建的核心模型就是Transformer的编码器,是 有带着位置编码和不带位置编码的两种情况。可以对比一下他们的准确率。
开始上代码了
中文数据预处理
由于中文不像英文中间有空白可以直接划分词语,需要依靠jieba库切词,然后把没有用的标点符号,或者是“了”,‘的’,‘也’,‘就’,‘很’.....等等没有用的虚词去掉。这就需要一个停用词库,大家可以网上找常用的停用词文本,也可以留言找博主要。我这有一个比较全的停用词,我还有一个简化版的。本次使用的是简化版的停用词。
首先看数据长这样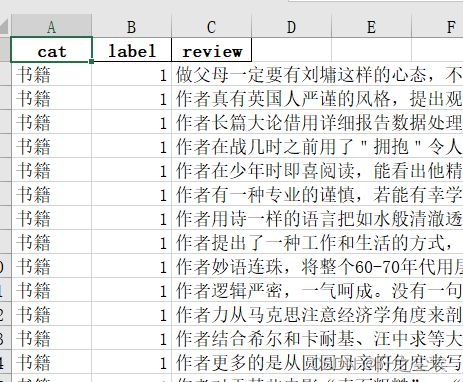
cat就是标签,review就是文本。
导入包和数据,读取停用词,用jieba库划分词汇并处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['KaiTi'] #指定默认字体 SimHei黑体
plt.rcParams['axes.unicode_minus'] = False #解决保存图像是负号'
import jieba
stop_list = pd.read_csv("stopwords_简略版.txt",index_col=False,quoting=3,
sep="\t",names=['stopword'], encoding='utf-8')#Jieba分词函数
def txt_cut(juzi):
lis=[w for w in jieba.lcut(juzi) if w not in stop_list.values]
return " ".join(lis)
df=pd.read_excel('十分类文本.xlsx')
data=pd.DataFrame()
data['label']=df['cat']
data['cutword']=df['review'].astype('str').apply(txt_cut)
data词汇切割好了,得到如下结果

查看标签y的分布
data['label'].value_counts().plot(kind='bar')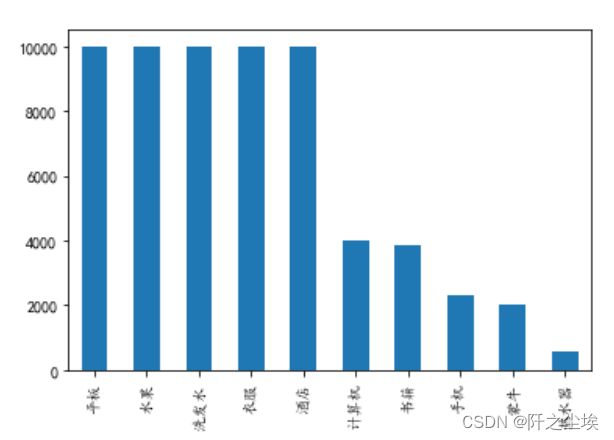
样本量不是很平衡,有的主题多有的少。
下面将文本变为数组,利用Keras里面的Tokenizer类实现,首先将词汇都索引化。这里有个参数num_words=6000很重要,意思是选择6000个词汇作为索引字典,也就是这个模型里面最多只有6000个词。
from os import listdir
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
# 将文件分割成单字, 建立词索引字典
tok = Tokenizer(num_words=6000)
tok.fit_on_texts(data['cutword'].values)
print("样本数 : ", tok.document_count)
print({k: tok.word_index[k] for k in list(tok.word_index)[:10]}) 打印查看文字对应的序号
由于每条文本的词汇长度不一样,我们训练时需要弄成一样长的张量(多剪少补),需要确定这个词汇最大长度为多少,也就是max_words参数,这个是循环神经网络的时间步的长度,也是注意力机制的维度。如果max_words过小则很多语句的信息损失了,而max_words过大数据矩阵又会过于稀疏,并且计算量过大。我们查看一下X的长度的分布频率:
查看X的长度分布:
X= tok.texts_to_sequences(data['cutword'].values)
#查看x的长度的分布
length=[]
for i in X:
length.append(len(i))
v_c=pd.Series(length).value_counts()
print(v_c[v_c>50]) #频率大于50才展现
v_c[v_c>50].plot(kind='bar',figsize=(12,5))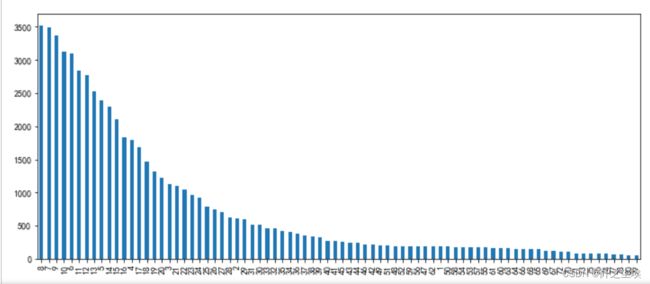
可以看出绝大多数的句子单词长度不超过50....长度为8的文本是最多的,本次选择max_words=60,将句子都裁剪为长为60 的向量。并取出y,查看X和y的形状
# 将序列数据填充成相同长度
X= sequence.pad_sequences(X, maxlen=60)
#Y=pd.get_dummies(data['label']).values
dic={'水果':0,'洗发水':1,'酒店':2,'衣服':3,'平板':4,'计算机':5,'书籍':6,'手机':7,'蒙牛':8,'热水器':9}
dic2=dict([(value,key) for (key,value) in dic.items()])
Y=data['label'].map(dic).values
print("X.shape: ", X.shape)
print("Y.shape: ", Y.shape)
#X=np.array(X)
#Y=np.array(Y)划分训练测试集,20%数据测试。查看其形状:
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, stratify=Y, random_state=0)
X_train.shape,X_test.shape,Y_train.shape, Y_test.shape
将y进行独立热编码,并且保留原始的测试集y_test,方便后面做评价。
Y_test_original=Y_test.copy()
Y_train = to_categorical(Y_train)
Y_test = to_categorical(Y_test)查看x第100到103个,和y前3个
print(X_train[100:103])
print(Y_test[:3])
Y_test_original[:3] 
数据看起来没问题,我们就准备开始建模了。
构建神经网络
定义Transformer层,和上面的结构图是一模一样的。有多头注意力层,全连接层,残差连接,层归一化。还有掩码
from tensorflow.keras import layers
import tensorflow as tf
from tensorflow import keras
class TransformerEncoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
self.dense_dim = dense_dim
self.num_heads = num_heads
self.attention = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.dense_proj = keras.Sequential(
[layers.Dense(dense_dim, activation="relu"),layers.Dense(embed_dim),] )
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
def call(self, inputs, mask=None):
if mask is not None:
mask = mask[:, tf.newaxis, :]
attention_output = self.attention(inputs, inputs, attention_mask=mask)
proj_input = self.layernorm_1(inputs + attention_output)
proj_output = self.dense_proj(proj_input)
return self.layernorm_2(proj_input + proj_output)
def get_config(self):
config = super().get_config()
config.update({
"embed_dim": self.embed_dim,
"num_heads": self.num_heads,
"dense_dim": self.dense_dim, })
return config上面的Transformer没有加入位置编码,位置编码需要手动加入,下面定义一个位置编码的嵌入层。
class PositionalEmbedding(layers.Layer):
def __init__(self, sequence_length, input_dim, output_dim, **kwargs):
super().__init__(**kwargs)
self.token_embeddings = layers.Embedding(input_dim=input_dim, output_dim=output_dim)
self.position_embeddings = layers.Embedding(input_dim=sequence_length, output_dim=output_dim)
self.sequence_length = sequence_length
self.input_dim = input_dim
self.output_dim = output_dim
def call(self, inputs):
length = tf.shape(inputs)[-1]
positions = tf.range(start=0, limit=length, delta=1)
embedded_tokens = self.token_embeddings(inputs)
embedded_positions = self.position_embeddings(positions)
return embedded_tokens + embedded_positions
def compute_mask(self, inputs, mask=None):
return tf.math.not_equal(inputs, 0)
def get_config(self):
config = super().get_config()
config.update({
"output_dim": self.output_dim,
"sequence_length": self.sequence_length,
"input_dim": self.input_dim,})
return config准备后,导入keras的很多层,定义参数
from keras.preprocessing import sequence
from keras.models import Sequential,Model
from keras.layers import Dense,Input, Dropout, Embedding, Flatten,MaxPooling1D,Conv1D,SimpleRNN,LSTM,GRU,Multiply,GlobalMaxPooling1D
from keras.layers import Bidirectional,Activation,BatchNormalization,GlobalAveragePooling1D,MultiHeadAttention
from keras.callbacks import EarlyStopping
from keras.layers.merge import concatenate
np.random.seed(0) # 指定随机数种子
#单词索引的最大个数6000,单句话最大长度60
top_words=6000
max_words=60 #序列长度
embed_dim=32 #嵌入维度
num_labels=10 #10分类重点来了!!!!!模型定义函数,想看transformer就直接看最后两个模型就行
def build_model(top_words=top_words,max_words=max_words,num_labels=num_labels,mode='LSTM',hidden_dim=[64]):
if mode=='RNN':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim, mask_zero=True))
model.add(Dropout(0.25))
model.add(SimpleRNN(hidden_dim[0]))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='MLP':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim, mask_zero=True))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(hidden_dim[0], activation="relu"))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='LSTM':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim))
model.add(Dropout(0.25))
model.add(LSTM(hidden_dim[0]))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='GRU':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim))
model.add(Dropout(0.25))
model.add(GRU(hidden_dim[0]))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='CNN': #一维卷积
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim, mask_zero=True))
model.add(Dropout(0.25))
model.add(Conv1D(filters=32, kernel_size=3, padding="same",activation="relu"))
model.add(MaxPooling1D(pool_size=2))
model.add(Flatten())
model.add(Dense(hidden_dim[0], activation="relu"))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='CNN+LSTM':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim))
model.add(Dropout(0.25))
model.add(Conv1D(filters=32, kernel_size=3, padding="same",activation="relu"))
model.add(MaxPooling1D(pool_size=2))
model.add(LSTM(hidden_dim[0]))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='BiLSTM':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim))
model.add(Bidirectional(LSTM(64)))
model.add(Dense(hidden_dim[0], activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation='softmax'))
#下面的网络采用Funcional API实现
elif mode=='TextCNN':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
## 词嵌入使用预训练的词向量
layer = Embedding(top_words, input_length=max_words, output_dim=embed_dim)(inputs)
## 词窗大小分别为3,4,5
cnn1 = Conv1D(32, 3, padding='same', strides = 1, activation='relu')(layer)
cnn1 = MaxPooling1D(pool_size=2)(cnn1)
cnn2 = Conv1D(32, 4, padding='same', strides = 1, activation='relu')(layer)
cnn2 = MaxPooling1D(pool_size=2)(cnn2)
cnn3 = Conv1D(32, 5, padding='same', strides = 1, activation='relu')(layer)
cnn3 = MaxPooling1D(pool_size=2)(cnn3)
# 合并三个模型的输出向量
cnn = concatenate([cnn1,cnn2,cnn3], axis=-1)
x = Flatten()(cnn)
x = Dense(hidden_dim[0], activation='relu')(x)
output = Dense(num_labels, activation='softmax')(x)
model = Model(inputs=inputs, outputs=output)
elif mode=='Attention':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x = Embedding(top_words, input_length=max_words, output_dim=embed_dim, mask_zero=True)(inputs)
x = MultiHeadAttention(1, key_dim=embed_dim)(x, x,x)
x = GlobalAveragePooling1D()(x)
x = Dropout(0.2)(x)
x = Dense(32, activation='relu')(x)
output = Dense(num_labels, activation='softmax')(x)
model = Model(inputs=[inputs], outputs=output)
elif mode=='MultiHeadAttention':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x = Embedding(top_words, input_length=max_words, output_dim=embed_dim, mask_zero=True)(inputs)
x = MultiHeadAttention(8, key_dim=embed_dim)(x, x,x)
x = GlobalAveragePooling1D()(x)
x = Dropout(0.2)(x)
x = Dense(32, activation='relu')(x)
output = Dense(num_labels, activation='softmax')(x)
model = Model(inputs=[inputs], outputs=output)
elif mode=='Attention+BiLSTM':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x = Embedding(top_words, input_length=max_words, output_dim=embed_dim)(inputs)
x = MultiHeadAttention(2, key_dim=embed_dim)(x, x,x)
x = Bidirectional(LSTM(hidden_dim[0]))(x)
x = Dense(64, activation='relu')(x)
x = Dropout(0.2)(x)
output = Dense(num_labels, activation='softmax')(x)
model = Model(inputs=inputs, outputs=output)
elif mode=='BiGRU+Attention':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x = Embedding(top_words, input_length=max_words, output_dim=embed_dim)(inputs)
x = Bidirectional(GRU(32,return_sequences=True))(x)
x = MultiHeadAttention(2, key_dim=embed_dim)(x,x,x)
x = Bidirectional(GRU(32))(x)
x = Dropout(0.2)(x)
output = Dense(num_labels, activation='softmax')(x)
model = Model(inputs=[inputs], outputs=output)
elif mode=='Transformer':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x = Embedding(top_words, input_length=max_words, output_dim=embed_dim, mask_zero=True)(inputs)
x = TransformerEncoder(embed_dim, 32, 4)(x)
x = GlobalMaxPooling1D()(x)
x = Dropout(0.5)(x)
outputs = Dense(num_labels, activation='softmax')(x)
model = Model(inputs, outputs)
elif mode=='PositionalEmbedding+Transformer':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x= PositionalEmbedding(sequence_length=max_words, input_dim=top_words, output_dim=embed_dim)(inputs)
x = TransformerEncoder(embed_dim, 32, 4)(x)
x = GlobalMaxPooling1D()(x)
x = Dropout(0.5)(x)
outputs = Dense(num_labels, activation='softmax')(x)
model = Model(inputs, outputs)
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
return model再定义一些画损失图,混淆矩阵,计算科恩指标等函数
#定义损失和精度的图,和混淆矩阵指标等等
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import cohen_kappa_score
def plot_loss(history):
# 显示训练和验证损失图表
plt.subplots(1,2,figsize=(10,3))
plt.subplot(121)
loss = history.history["loss"]
epochs = range(1, len(loss)+1)
val_loss = history.history["val_loss"]
plt.plot(epochs, loss, "bo", label="Training Loss")
plt.plot(epochs, val_loss, "r", label="Validation Loss")
plt.title("Training and Validation Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.subplot(122)
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
plt.plot(epochs, acc, "b-", label="Training Acc")
plt.plot(epochs, val_acc, "r--", label="Validation Acc")
plt.title("Training and Validation Accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.tight_layout()
plt.show()
def plot_confusion_matrix(model,X_test,Y_test_original):
#预测概率
prob=model.predict(X_test)
#预测类别
pred=np.argmax(prob,axis=1)
#数据透视表,混淆矩阵
pred=pd.Series(pred).map(dic2)
Y_test_original=pd.Series(Y_test_original).map(dic2)
table = pd.crosstab(Y_test_original, pred, rownames=['Actual'], colnames=['Predicted'])
#print(table)
sns.heatmap(table,cmap='Blues',fmt='.20g', annot=True)
plt.tight_layout()
plt.show()
#计算混淆矩阵的各项指标
print(classification_report(Y_test_original, pred))
#科恩Kappa指标
print('科恩Kappa'+str(cohen_kappa_score(Y_test_original, pred)))定义训练函数:
#定义训练函数
def train_fuc(max_words=max_words,mode='BiLSTM+Attention',batch_size=32,epochs=10,hidden_dim=[32],show_loss=True,show_confusion_matrix=True):
#构建模型
model=build_model(max_words=max_words,mode=mode)
print(model.summary())
es = EarlyStopping(patience=5)
history=model.fit(X_train, Y_train,batch_size=batch_size,epochs=epochs,validation_split=0.2, verbose=1,callbacks=[es])
print('——————————-----------------——训练完毕—————-----------------------------———————')
# 评估模型
loss, accuracy = model.evaluate(X_test, Y_test)
print("测试数据集的准确度 = {:.4f}".format(accuracy))
if show_loss:
plot_loss(history)
if show_confusion_matrix:
plot_confusion_matrix(model=model,X_test=X_test,Y_test_original=Y_test_original)这样,后面使用不同的模型就只需要该mode这个参数就行了,很方便。
下面开始一个一个模型的训练:
模型训练
设定训练的超参数
top_words=6000
max_words=60
batch_size=128
epochs=6
show_confusion_matrix=True
show_loss=True
mode='MLP' 使用MLP进行训练:(我这里只训练6轮,因为测试的时候发现10轮就容易过拟合)
train_fuc(mode='MLP',batch_size=batch_size,epochs=epochs)训练完成结果:
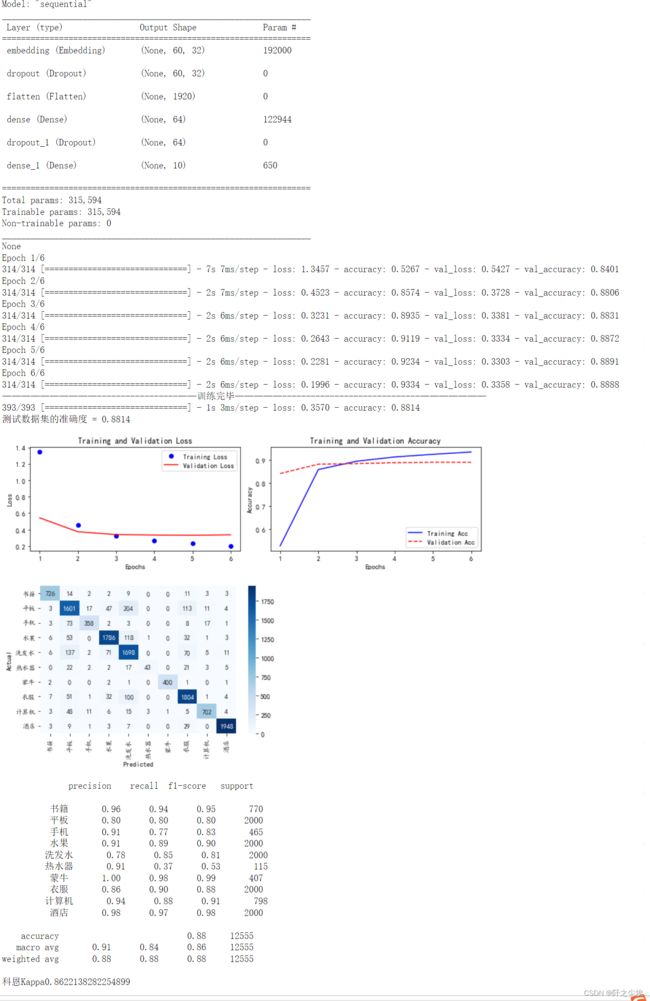
如图,使用训练函数可以打印模型的信息,模型训练的每一轮的情况 ,还有模型的损失和准确率的变化图,训练集和验证集都有,还有评价的混淆矩阵,和混淆矩阵的各种指标,科恩系数。非常方便。
当然我们这里就简单的使用测试集上的准确率来进行评价好了,实际科研应该要做K折交叉验证来验证模型的好坏。
MLP的测试集准确率为88.14%,在训练损失图上面,可以很清楚的看到。
MLP在这里效果还不错,而且运行速度很快。
下面进行CNN训练:
train_fuc(mode='CNN',batch_size=batch_size,epochs=epochs)就改一下mode参数就行,很方便。
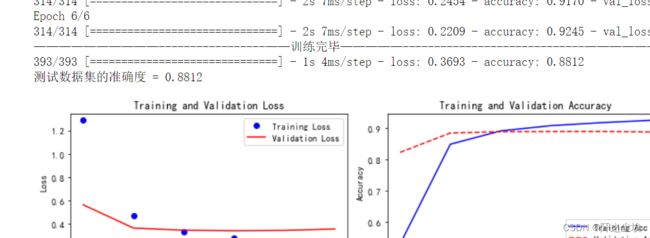
就不截取那么多了,可以看到准确率为88.12%。而且只训练六轮看不到过拟合现象,CNN也很快。
RNN训练:
model='RNN'
train_fuc(mode=model,epochs=epochs)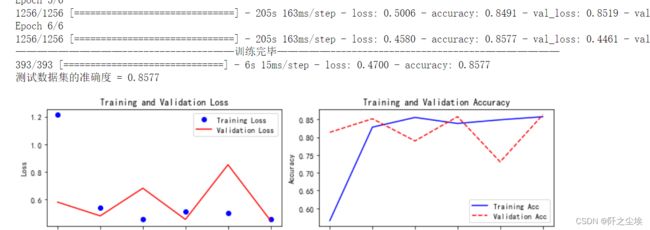
RNN的运行速度就太慢了.....mlp每轮2秒,他每轮200多秒.......而且每轮的损失波动还很大,不稳健,最后的准确率也不高,85.77%。
LSTM训练:现在的主流循环神经网络,效果还不错
train_fuc(mode='LSTM',epochs=epochs)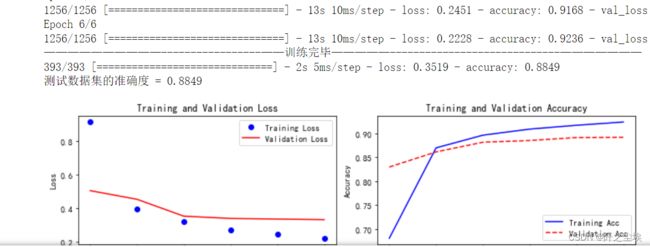
准确率为88.49%,目前最高,而且也没有过拟合现象。
GRU:
train_fuc(mode='GRU',epochs=epochs)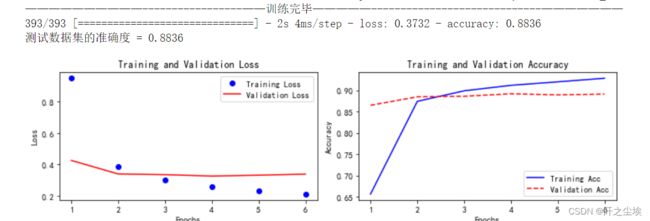
准确率为88.36%,还不错。
CNN+LSTM:
train_fuc(mode='CNN+LSTM',epochs=epochs)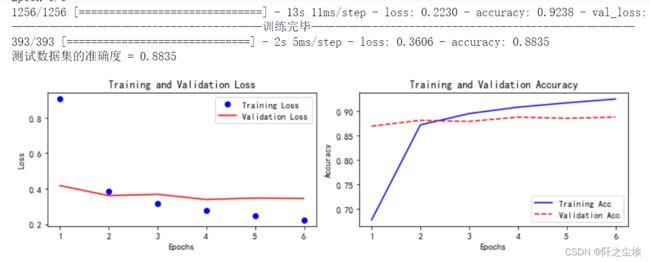
组合模型,准确率为88.35%,还不错。
双向LSTM:
train_fuc(mode='BiLSTM',epochs=epochs)
emmm,只有87.77%。按道理双向应该比LSTM效果好的,可能我这个网络设计得不太行(加了一个全连接层),大家可以试试其他的结构,改改超参数,或者堆叠两层双向LSTM试试,说不定效果会更好。
文本CNN:
train_fuc(mode='TextCNN',epochs=3)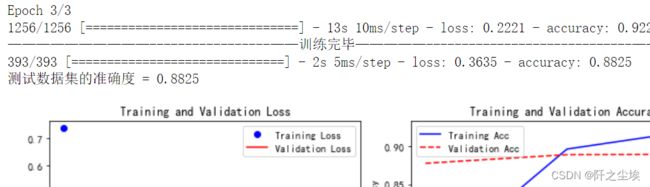
这也是一个将图像领域的CNN迁移到文本领域的网络架构,3层特定的CNN在文本上表现还不错。
准确率为88.25%,这里只训练了3轮,因为很容易过拟合。
后面的模型都比较容易过拟合,所以都只训练少量轮数就行。
Attention:
train_fuc(mode='Attention',epochs=4)除了卷积核循环外,第三种神经网络登场了,注意力机制,准确率87.03%,还行
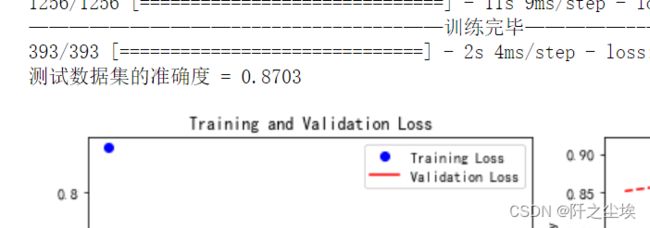
MultiHeadAttention:
train_fuc(mode='MultiHeadAttention',epochs=3)注意力的升级版,多头注意力,这里用了8个头,准确率87.61%
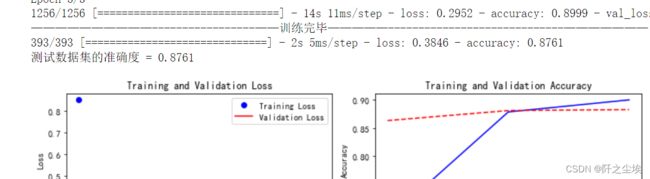
Attention+BiLSTM:
train_fuc(mode='Attention+BiLSTM',epochs=8) 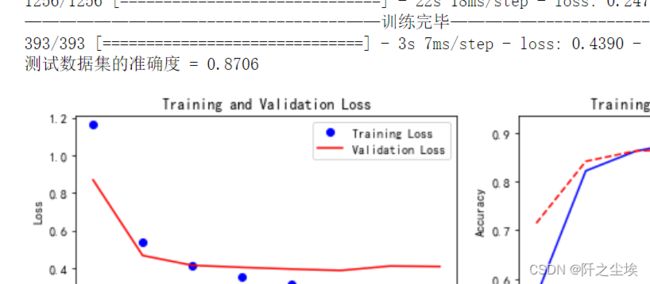
组合模型,先注意力,然后再循环层,准确率87.06%,一般般
BiGRU+Attention
train_fuc(mode='BiGRU+Attention',epochs=4)这个是先循环,然后再注意力,准确率87.01%,就不放图了....
Transformer:
train_fuc(mode='Transformer',epochs=3) 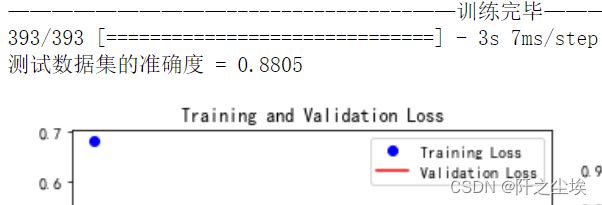
终于到了激动人心的transformer了,准确率emmm 88.05%,还行。只训练了3轮,因为很容易过拟合。
PositionalEmbedding+Transformer:
train_fuc(mode='PositionalEmbedding+Transformer',epochs=3)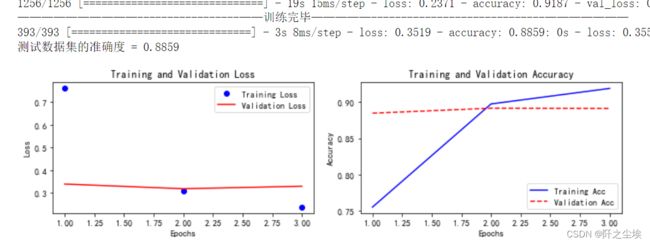
加入了位置编码后,准确率确实变高了,88.59%,全场模型最高!!!!虽然好像不是高很多.....
总结
只能说未来可期,因为我数据量小(6w对于深度学习来说太少了),每条文本的数据也不长,Transformer没有在这个数据集上展现强大的力量。
希望后面的同学可以多调调参数,改改模型架构,比如在Transformer前面或者后面塞一个循环层或者卷积层,或者全连接层,换一下神经元个数什么的,说不定能得到更好的结果。
(可以找博主要数据集,数据共享,要是能跑出更好的模型结构也可以分享博主哟)