netty学习笔记
io.netty
PART1 Netty——异步和事件驱动
1.netty概述
Netty 是一款异步的事件驱动的网络应用程序框架,支持快速地开发可维护的高性能的面向协议的服务器和客户端。
在网络编程领域,Netty是Java的卓越框架。它驾驭了Java高级API的能力,并将其隐藏在一个易于使用的API之后。Netty使你可以专注于自己真正感兴趣的——你的应用程序的独一无二的价值。
2.netty特性
非阻塞网络调用使得我们可以不必等待一个操作的完成。完全异步的 I/O 正是基于这个特性构建的,并且更进一步:异步方法会立即返回,并且在它完成时,会直接或者在稍后的某个时间点通知用户。
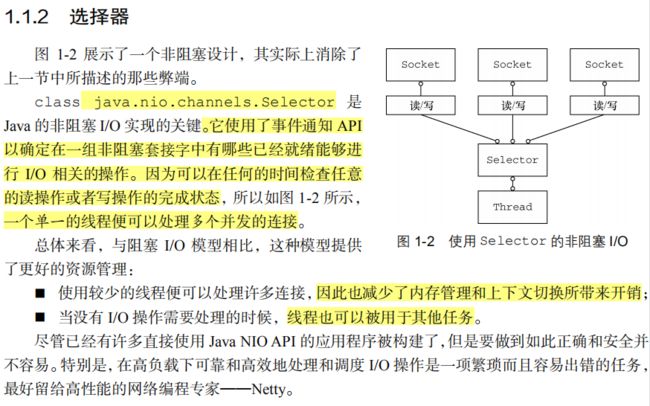
选择器使得我们能够通过较少的线程便可监视许多连接上的事件。
3.Netty核心组件
1.Channel;
2.回调;
3.Future;
4.事件和 ChannelHandler。
3.1 Channel
Channel 是 Java NIO 的一个基本构造。
它代表一个到实体(如一个硬件设备、一个文件、一个网络套接字或者一个能够执行一个或者多个不同的I/O操作的程序组件)的开放连接,如读操作和写操作 。
目前,可以把 Channel 看作是传入(入站)或者传出(出站)数据的载体。因此,它可以被打开或者被关闭,连接或者断开连接。
3.2 回调
一个回调其实就是一个方法,一个指向已经被提供给另外一个方法的方法的引用。这使得后者 可以在适当的时候调用前者。回调在广泛的编程场景中都有应用,而且也是在操作完成后通知相关方最常见的方式之一。
Netty 在内部使用了回调来处理事件;当一个回调被触发时,相关的事件可以被一个 interface-ChannelHandler 的实现处理。
如下方代码段,当一个新的连接已经被建立时,ChannelHandler 的 channelActive()回调方法将会被调用,并将打印出一条信息。
public class ConnectHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelActive(ChannelHandlerContext ctx)throws Exception {
System.out.println(
"Client " + ctx.channel().remoteAddress() + " connected");
} }
当一个新的连接被建立channelActive(ChannelHandlerContext)将会被调用。
3.3 Future
Future 提供了另一种在操作完成时通知应用程序的方式。这个对象可以看作是一个异步操作的结果的占位符;它将在未来的某个时刻完成,并提供对其结果的访问。
JDK 预置了 interface java.util.concurrent.Future,但是其所提供的实现,只允许手动检查对应的操作是否已经完成,或者一直阻塞直到它完成。这是非常繁琐的,所以 Netty提供了它自己的实现——ChannelFuture,用于在执行异步操作的时候使用。
ChannelFuture提供了几种额外的方法,这些方法使得我们能够注册一个或者多个ChannelFutureListener实例。监听器的回调方法operationComplete(),将会在对应的操作完成时被调用 。然后监听器可以判断该操作是成功地完成了还是出错了。如果是后者,我们可以检索产生的Throwable。简而 言之 ,由ChannelFutureListener提供的通知机制消除了手动检查对应的操作是否完成的必要。
每个 Netty 的出站 I/O 操作都将返回一个 ChannelFuture;也就是说,它们都不会阻塞。
正如我们前面所提到过的一样,Netty 完全是异步和事件驱动的。
connect()方法将会直接返回,而不会阻塞,该调用将会在后台完成。这究竟什么时候会发生则取决于若干的因素,但这个关注点已经从代码中抽象出来了。因为线程不用阻塞以等待对应的操作完成,所以它可以同时做其他的工作,从而更加有效地利用资源。
异步建立连接:
Channel channel = ...;
ChannelFuture future = channel.connect(new InetSocketAddress("192.168.0.1", 25));
如何利用 ChannelFutureListener?首先,要连接到远程节点上。然后,要注册一个新的 ChannelFutureListener 到connect()方法的调用所返回的 ChannelFuture 上。当该监听器被通知连接已经建立的时候,要检查对应的状态 。如果该操作是成功的,那么将数据写到该 Channel。否则,要从 ChannelFuture 中检索对应的 Throwable。
Channel channel = ...;
//异步地连接到远程节点
ChannelFuture future = channel.connect(new InetSocketAddress("192.168.0.1", 25));
future.addListener(new ChannelFutureListener() {
//注册一个 ChannelFutureListener,以便在操作完成时获得通知
public void operationComplete(ChannelFuture future) {
if (future.isSuccess()){
//如果操作是成功的,则创建一个 ByteBuf 以持有数据
ByteBuf buffer = Unpooled.copiedBuffer("Hello", Charset.defaultCharset());
//将数据异步地发送到远程节点。返回一个 ChannelFuture
ChannelFuture wf = future.channel().writeAndFlush(buffer);
} else {
//如果发生错误,则访问描述原因的 Throwable
Throwable cause = future.cause();
cause.printStackTrace();
} }
});
3.4 事件和ChannelHandler
Netty 使用不同的事件来通知我们状态的改变或者是操作的状态。这使得我们能够基于已经发生的事件来触发适当的动作。这些动作可能是:
记录日志;
数据转换;
流控制;
应用程序逻辑。
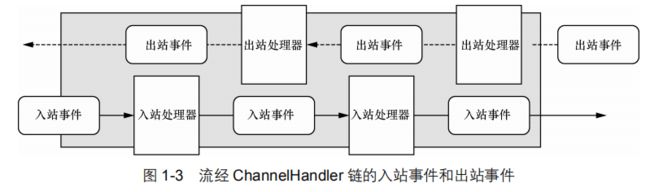
Netty 是一个网络编程框架,所以事件是按照它们与入站或出站数据流的相关性进行分类的。可能由入站数据或者相关的状态更改而触发的事件包括:
连接已被激活或者连接失活;
数据读取;
用户事件;
错误事件。
出站事件是未来将会触发的某个动作的操作结果,这些动作包括:
打开或者关闭到远程节点的连接;
将数据写到或者冲刷到套接字。
每个事件都可以被分发给 ChannelHandler 类中的某个用户实现的方法。这是一个很好的将事件驱动范式直接转换为应用程序构件块的例子。
你可以认为每个 ChannelHandler 的实例都类似于一种为了响应特定事件而被执行的回调。
Netty 提供了大量预定义的可以开箱即用的 ChannelHandler 实现,包括用于各种协议(如 HTTP 和 SSL/TLS)的 ChannelHandler。在内部,ChannelHandler 自己也使用了事件和 Future,使得它们也成为了你的应用程序将使用的相同抽象的消费者。
Netty的异步编程模型是建立在Future和回调的概念之上的,而将事件派发到ChannelHandler的方法则发生在更深的层次上。结合在一起,这些元素就提供了一个处理环境,使你的应用程序逻辑可以独立于任何网络操作相关的顾虑而独立地演变。
拦截操作以及高速地转换入站数据和出站数据,都只需要你提供回调或者利用操作所返回的Future。这使得链接操作变得既简单又高效,并且促进了可重用的通用代码的编写。
Netty 通过触发事件将 Selector 从应用程序中抽象出来,消除了所有本来将需要手动编写的派发代码。
在内部,将会为每个 Channel 分配一个 EventLoop,用以处理所有事件,包括:
注册感兴趣的事件;
将事件派发给 ChannelHandler;
安排进一步的动作。
EventLoop 本身只由一个线程驱动,其处理了一个 Channel 的所有 I/O 事件,并且在该EventLoop 的整个生命周期内都不会改变。这个简单而强大的设计消除了你可能有的在ChannelHandler 实现中需要进行同步的任何顾虑,因此,你可以专注于提供正确的逻辑,用来在有感兴趣的数据要处理的时候执行。
4.netty实战
4.1 netty - Echo服务器
所有的 Netty 服务器都需要以下两部分。
至少一个 ChannelHandler—该组件实现了服务器对从客户端接收的数据的处理,即它的业务逻辑。(ChannelHandler,它是一个接口族的父接口,它的实现负责接收并响应事件通知。)
引导—这是配置服务器的启动代码。至少,它会将服务器绑定到它要监听连接请求的端口上。
因为你的 Echo 服务器会响应传入的消息,所以它需要实现 ChannelInboundHandler 接口,用 来定义响应入站事件的方法。这个简单的应用程序只需要用到少量的这些方法,所以继承 ChannelInboundHandlerAdapter 类也就足够了,它提供了 ChannelInboundHandler 的默认实现。
我们感兴趣的方法是:
channelRead()—对于每个传入的消息都要调用;
channelReadComplete()—通知ChannelInboundHandler最后一次对channelRead()的调用是当前批量读取中的最后一条消息;
exceptionCaught()—在读取操作期间,有异常抛出时会调用
@ChannelHandler.Sharable
public class EchoServerHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf in = (ByteBuf) msg;
//将消息记录到控制台
System.out.println(
"Server received: " + in.toString(CharsetUtil.UTF_8));
//讲收到的消息写给发送者而不冲刷出站消息
ctx.write(in);
}
@Override
public void channelReadComplete(ChannelHandlerContext ctx) {
//将未决消息冲刷到远程节点 并关闭该channel
ctx.writeAndFlush(Unpooled.EMPTY_BUFFER)
.addListener(ChannelFutureListener.CLOSE);
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx,
Throwable cause) {
cause.printStackTrace();
ctx.close();
}
}
ChannelInboundHandlerAdapter 有一个直观的 API,并且它的每个方法都可以被重写以挂钩到事件生命周期的恰当点上。因为需要处理所有接收到的数据,所以你重写了 channelRead()方法。在这个服务器应用程序中,你将数据简单地回送给了远程节点。重写 exceptionCaught()方法允许你对 Throwable 的任何子类型做出反应,在这里你记录了异常并关闭了连接。虽然一个更加完善的应用程序也许会尝试从异常中恢复,但在这个场景下,只是通过简单地关闭连接来通知远程节点发生了错误

针对不同类型的事件来调用 ChannelHandler;
应用程序通过实现或者扩展 ChannelHandler 来挂钩到事件的生命周期,并且提供自
定义的应用程序逻辑;
在架构上,ChannelHandler 有助于保持业务逻辑与网络处理代码的分离。这简化了开发过程,因为代码必须不断地演化以响应不断变化的需求。
4.2 引导服务器
绑定到服务器将在其上监听并接受传入连接请求的端口;
配置 Channel,以将有关的入站消息通知给 EchoServerHandler 实例。
除了一些由 Java NIO 实现提供的服务器端性能增强之外,NIO 传输大多数时候指的就是 TCP 传输。
引导过程中所需要的步骤如下:
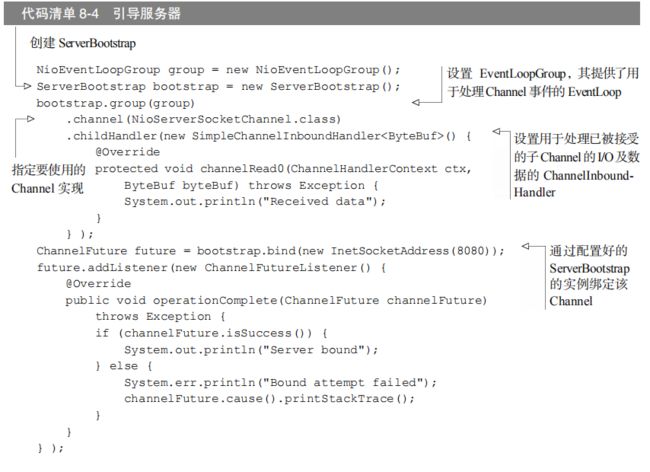
创建一个 ServerBootstrap 的实例以引导和绑定服务器;
创建并分配一个 NioEventLoopGroup 实例以进行事件的处理,如接受新连接以及读/写数据;
指定服务器绑定的本地的 InetSocketAddress;
使用一个 EchoServerHandler 的实例初始化每一个新的 Channel;
调用 ServerBootstrap.bind()方法以绑定服务器。
public class EchoServer {
private final int port;
public EchoServer(int port) {
this.port = port;
}
public static void main(String[] args) throws Exception {
// if (args.length != 1) {
// System.err.println(
// "Usage: " + EchoServer.class.getSimpleName() + " ");
// }
// int port = Integer.parseInt(args[0]);
int port = 3991;
new EchoServer(port).start();
}
public void start() throws Exception {
final EchoServerHandler serverHandler = new EchoServerHandler();
//创建EventLoopGroup
EventLoopGroup group = new NioEventLoopGroup();
try {
//创建服务器启动类
ServerBootstrap b = new ServerBootstrap();
b.group(group)
//指定所使用的的NIO传输channel
.channel(NioServerSocketChannel.class)
//使用指定的端口设置套接字地址
.localAddress(new InetSocketAddress(port))
//添加一个EchoServerHandler到子channel的ChannelPipeline
.childHandler(new ChannelInitializer<SocketChannel>(){
@Override
public void initChannel(SocketChannel ch)
throws Exception {
//EchoServerHandler被标注为@Shareable所以我们可以总是使用相同的实例
ch.pipeline().addLast(serverHandler);
}
});
//异步绑定服务器 调用sync方法阻塞直到绑定完成
ChannelFuture f = b.bind().sync();
//获取Channel的CloseFutrue并阻塞当前线程直到他完成
f.channel().closeFuture().sync();
} finally {
//关闭EventLoopGroup释放所有资源。
group.shutdownGracefully().sync();
}
}
}
4.3 netty - Echo客户端
Echo 客户端将会:
(1)连接到服务器;
(2)发送一个或者多个消息;
(3)对于每个消息,等待并接收从服务器发回的相同的消息;
(4)关闭连接。
如同服务器,客户端将拥有一个用来处理数据的ChannelInboundHandler。在这个场景下,你将拓展SimpleChannelInboundHandler 类以处理所有必须的任务
@ChannelHandler.Sharable
public class EchoClientHandler extends
SimpleChannelInboundHandler<ByteBuf> {
//当被通知channel是活跃的时候发送一条消息
//重写了 channelActive()方法,其将在一个连接建立时被调用。这确保了数据
//将会被尽可能快地写入服务器,其在这个场景下是一个编码了字符串"Netty rocks!"的字节缓冲区。
@Override
public void channelActive(ChannelHandlerContext ctx) {
ctx.writeAndFlush(Unpooled.copiedBuffer("Netty rocks!",
CharsetUtil.UTF_8)); }
//记录已接收消息的转储
@Override
public void channelRead0(ChannelHandlerContext ctx, ByteBuf in) {
System.out.println(
"Client received: " + in.toString(CharsetUtil.UTF_8));
}
//发生异常时记录错误并关闭
@Override
public void exceptionCaught(ChannelHandlerContext ctx,
Throwable cause) {
cause.printStackTrace();
ctx.close();
}
}
你重写了 channelRead0()方法。每当接收数据时,都会调用这个方法。需要注意的是,由服务器发送的消息可能会被分块接收。也就是说,如果服务器发送了 5 字节,那么不能保证这 5 字节会被一次性接收。即使是对于这么少量的数据,channelRead0()方法也可能会被调用两次,第一次使用一个持有 3 字节的ByteBuf(Netty 的字节容器),第二次使用一个持有 2 字节的 ByteBuf。作为一个面向流的协议,TCP 保证了字节数组将会按照服务器发送它们的顺序被接收。

4.4 引导客户端
引导客户端类似于引导服务器,不同的是,客户端是使用主机和端口参数来连接远程地址,也就是这里的 Echo 服务器的地址,而不是绑定到一个一直被监听的端口。
为初始化客户端,创建了一个 Bootstrap 实例;
为进行事件处理分配了一个 NioEventLoopGroup 实例,其中事件处理包括创建新的连接以及处理入站和出站数据;
为服务器连接创建了一个 InetSocketAddress 实例;
当连接被建立时,一个 EchoClientHandler 实例会被安装到(该 Channel 的)ChannelPipeline 中;
在一切都设置完成后,调用 Bootstrap.connect()方法连接到远程节点;
注意:你可以在客户端和服务器上分别使用不同的传输。分别使用NIO与OIO
public class EchoClient {
private final String host;
private final int port;
public EchoClient(String host, int port) {
this.host = host;
this.port = port;
}
public void start() throws Exception {
EventLoopGroup group = new NioEventLoopGroup();
try {
Bootstrap b = new Bootstrap();
b.group(group)
.channel(NioSocketChannel.class)
.remoteAddress(new InetSocketAddress(host, port))
.handler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch)
throws Exception {
ch.pipeline().addLast(
new EchoClientHandler());
}
});
ChannelFuture f = b.connect().sync();
f.channel().closeFuture().sync();
} finally {
group.shutdownGracefully().sync();
} }
public static void main(String[] args) throws Exception {
// if (args.length != 2) {
// System.err.println(
// "Usage: " + EchoClient.class.getSimpleName() + " ");
// return;
// }
// String host = args[0];
// int port = Integer.parseInt(args[1]);
String host="192.168.222.130";
int port = 3391;
new EchoClient(host, port).start();
} }
注意理解: 每个 Channel 分配一个 EventLoop 一个Channel能有多个ChannelHandler。EventLoop 本身只由一个线程驱动,其处理了一个 Channel 的所有 I/O 事件,并且在该EventLoop 的整个生命周期内都不会改变。这个简单而强大的设计消除了你可能有的在ChannelHandler 实现中需要进行同步的任何顾虑,因此,你可以专注于提供正确的逻辑,用来在有感兴趣的数据要处理的时候执行。
5.netty组件和设计
netty —基于 Java NIO 的基于异步和事件驱动—基于future和回调的概念
保证了高负载下应用程序性能的最大化和可伸缩性。其次,Netty 也包含了一组设计模式,将应用程序逻辑从网络层解耦,简化了开发过程,同时也最大限度地提高了可测试性、模块化以及代码的可重用性。
- Channel—Socket;
- EventLoop—控制流、多线程处理、并发;
- ChannelFuture—异步通知。
5.1 Channel
基本的 I/O 操作(bind()、connect()、read()和 write())依赖于底层网络传输所提供的原语。在基于 Java 的网络编程中,其基本的构造是 class Socket。Netty 的 Channel 接 口所提供的 API,大大地降低了直接使用 Socket 类的复杂性。此外,Channel 也是拥有许多预定义的、专门化实现的广泛类层次结构的根,下面是一个简短的部分清单:
EmbeddedChannel;
LocalServerChannel;
NioDatagramChannel;
NioSctpChannel;
NioSocketChannel。
5.2 EventLoop接口
EventLoop 定义了 Netty 的核心抽象,用于处理连接的生命周期中所发生的事件。
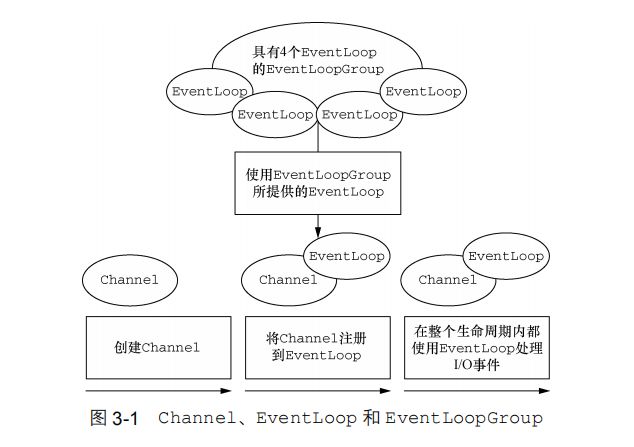
- 一个 EventLoopGroup 包含一个或者多个 EventLoop;
- 一个 EventLoop 在它的生命周期内只和一个 Thread 绑定;
- 所有由 EventLoop 处理的 I/O 事件都将在它专有的 Thread 上被处理;
- 一个 Channel 在它的生命周期内只注册于一个 EventLoop;
- 一个 EventLoop 可能会被分配给一个或多个 Channel。
- 注意,在这种设计中,一个给定 Channel 的 I/O 操作都是由相同的 Thread 执行的,实际上消除了对于同步的需要。
5.3 ChannelFuture接口
Netty 中所有的 I/O 操作都是异步的。因为一个操作可能不会立即返回,所以我们需要一种用于在之后的某个时间点确定其结果的方法。为此,Netty 提供了ChannelFuture 接口,其 addListener()方法注册了一个 ChannelFutureListener,以便在某个操作完成时(无论是否成功)得到通知。
所有属于同一个 Channel 的操作都被保证其将以它们被调用的顺序被执行。
5.4 ChannelHandler与ChannelPipeline
从应用程序开发人员的角度来看,Netty 的主要组件是 ChannelHandler,它充当了所有处理入站和出站数据的应用程序逻辑的容器。这是可行的,因为 ChannelHandler 的方法是由网络事件(其中术语“事件”的使用非常广泛)触发的。事实上,ChannelHandler 可专门用于几乎任何类型的动作,例如将数据从一种格式转换为另外一种格式,或者处理转换过程中所抛出的异常。
ChannelPipeline 提供了 ChannelHandler 链的容器,并定义了用于在该链上传播入站和出站事件流的 API。当 Channel 被创建时,它会被自动地分配到它专属的 ChannelPipeline。
ChannelHandler 安装到 ChannelPipeline 中的过程如下所示:
- 一个ChannelInitializer的实现被注册到了ServerBootstrap中
- 当 ChannelInitializer.initChannel()方法被调用时ChannelInitializer将在 ChannelPipeline 中安装一组自定义的 ChannelHandler;
- ChannelInitializer 将它自己从 ChannelPipeline 中移除。
ChannelHandler 是专为支持广泛的用途而设计的,可以将它看作是处理往来 ChannelPipeline 事件(包括数据)的任何代码的通用容器。

使得事件流经 ChannelPipeline 是 ChannelHandler 的工作,它们是在应用程序的初始化或者引导阶段被安装的。这些对象接收事件、执行它们所实现的处理逻辑,并将数据传递给链中的下一个 ChannelHandler。它们的执行顺序是由它们被添加的顺序所决定的。实际上,被我们称为 ChannelPipeline 的是这些 ChannelHandler 的编排顺序。
从一个客户端应用程序的角度来看,如果事件的运动方向是从客户端到服务器端,那么我们称这些事件为出站的,反之则称为入站的。

入站和出站 ChannelHandler 可以被安装到同一ChannelPipeline
如果一个消息或者任何其他的入站事件被读取,那么它会从 ChannelPipeline 的头部开始流动,并被传递给第一个 ChannelInboundHandler。这个 ChannelHandler 不一定会实际地修改数据,具体取决于它的具体功能,在这之后,数据将会被传递给链中的下一个ChannelInboundHandler。最终,数据将会到达 ChannelPipeline 的尾端,届时,所有处理就都结束了。
数据的出站运动(即正在被写的数据)在概念上也是一样的。在这种情况下,数据将从ChannelOutboundHandler 链的尾端开始流动,直到它到达链的头部为止。在这之后,出站数据将会到达网络传输层,这里显示为 Socket。
通过使用作为参数传递到每个方法的 ChannelHandlerContext,事件可以被传递给当前ChannelHandler 链中的下一个 ChannelHandler。因为你有时会忽略那些不感兴趣的事件,所以 Netty提供了抽象基类 ChannelInboundHandlerAdapter 和 ChannelOutboundHandlerAdapter。通过调用 ChannelHandlerContext 上的对应方法,每个都提供了简单地将事件传递给下一个ChannelHandler的方法的实现。随后,你可以通过重写你所感兴趣的那些方法来扩展这些类。
鉴于出站操作和入站操作是不同的,你可能会想知道如果将两个类别的 ChannelHandler都混合添加到同一个 ChannelPipeline 中会发生什么。虽然 ChannelInboundHandle 、ChannelOutboundHandle 都扩展自 ChannelHandler,但是 Netty 能区分 ChannelInboundHandler 实现和 ChannelOutboundHandler 实现,并确保数据只会在具有相同定向类型的两个 ChannelHandler 之间传递。
当ChannelHandler 被添加到ChannelPipeline 时,它将会被分配一个ChannelHandlerContext,其代表了 ChannelHandler 和 ChannelPipeline 之间的绑定。虽然这个对象可以被用于获取底层的 Channel,但是它主要还是被用于写出站数据。
在 Netty 中,有两种发送消息的方式。你可以直接写到 Channel 中,也可以 写到和 ChannelHandler相关联的ChannelHandlerContext对象中。前一种方式将会导致消息从ChannelPipeline 的尾端开始流动,而后者将导致消息从 ChannelPipeline 中的下一个 ChannelHandler 开始流动。
Netty 以适配器类的形式提供了大量默认的 ChannelHandler 实现,其旨在简化应用程序处理逻辑的开发过程。你已经看到了,ChannelPipeline中的每个ChannelHandler将负责把事件转发到链中的下一个 ChannelHandler。这些适配器类(及它们的子类)将自动执行这个操作,所以你可以只重写那些你想要特殊处理的方法和事件。

5.5 编码器和解码器
当你通过 Netty 发送或者接收一个消息的时候,就将会发生一次数据转换。入站消息会被解码;也就是说,从字节转换为另一种格式,通常是一个 Java 对象。如果是出站消息,则会发生相反方向的转换:它将从它的当前格式被编码为字节。这两种方向的转换的原因很简单:网络数据总是一系列的字节。
所有由 Netty 提供的编码器/解码器适配器类都实现了 ChannelOutboundHandler 或者 ChannelInboundHandler 接口。
你将会发现对于入站数据来说,channelRead 方法/事件已经被重写了。对于每个从入站Channel 读取的消息,这个方法都将会被调用。随后,它将调用由预置解码器所提供的 decode()方法,并将已解码的字节转发给 ChannelPipeline 中的下一个ChannelInboundHandler。
5.6 引导
Netty 的引导类为应用程序的网络层配置提供了容器,这涉及将一个进程绑定到某个指定的端口,或者将一个进程连接到另一个运行在某个指定主机的指定端口上的进程。
面向连接的协议 请记住,严格来说,“连接”这个术语仅适用于面向连接的协议,如 TCP,其保证了两个连接端点之间消息的有序传递。
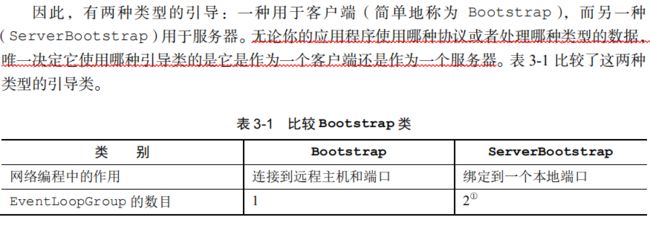
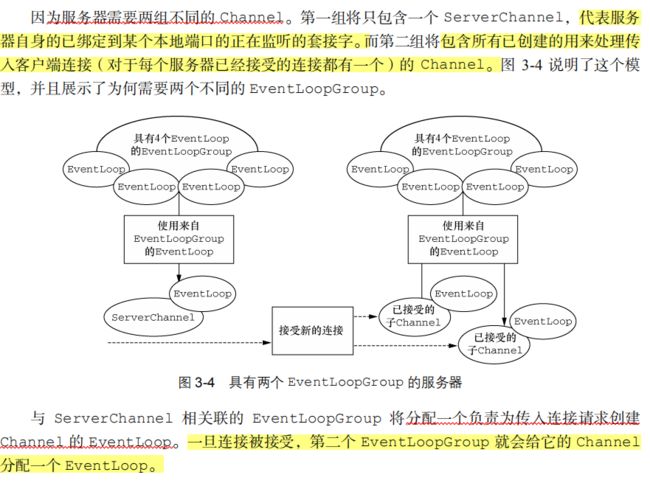
6.传输
6.1 阻塞IO(OIO/BIO)

未使用netty的阻塞网络编程:
public class PlainOioServer {
public void serve(int port) throws IOException {
final ServerSocket socket = new ServerSocket(port);
try {
for (;;) {
final Socket clientSocket = socket.accept();
System.out.println(
"Accepted connection from " + clientSocket);
//如上图所示,每有一个新连接,则开启一个新线程来进行读写操作。无法支持高并发。线程上下文切换开销大。
new Thread(new Runnable() {
@Override
public void run() {
OutputStream out;
try {
out = clientSocket.getOutputStream();
//将消息写给已连接的客户端。
out.write("Hi!\r\n".getBytes(
Charset.forName("UTF-8")));
out.flush();
clientSocket.close();
}
catch (IOException e) {
e.printStackTrace();
}
finally {
try {
clientSocket.close();
}
catch (IOException ex) {
// ignore on close
} } }
}).start();
} }
catch (IOException e) {
e.printStackTrace();
} } }
6.2 非阻塞IO(NIO)
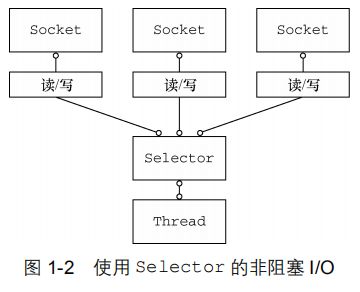
为了支持高并发 需要改成非阻塞IO的异步网络编程。
public class PlainNioServer {
public void serve(int port) throws IOException {
ServerSocketChannel serverChannel = ServerSocketChannel.open();
serverChannel.configureBlocking(false);
ServerSocket ssocket = serverChannel.socket();
InetSocketAddress address = new InetSocketAddress(port);
ssocket.bind(address);
Selector selector = Selector.open();
//将ServerSocket注册到selector以接受连接。
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
final ByteBuffer msg = ByteBuffer.wrap("Hi!\r\n".getBytes());
for (; ; ) {
try {
//等待需要处理的新事件;阻塞 将一直持续到下一个传入事件。
selector.select();
} catch (IOException ex) {
ex.printStackTrace();
// handle exception
break;
}
//获取所有接受时间的SelectionKey实例。
Set<SelectionKey> readyKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = readyKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
try {
if (key.isAcceptable()) {
//检查事件是否是一个新的已经就绪可以被接受的连接
ServerSocketChannel server =
(ServerSocketChannel) key.channel();
SocketChannel client = server.accept();
//接受客户端,并将它注册到选择器
client.configureBlocking(false);
client.register(selector, SelectionKey.OP_WRITE |
SelectionKey.OP_READ, msg.duplicate());
System.out.println(
"Accepted connection from " + client);
}
if (key.isWritable()) {
//检查套接字是否已经准备好写数据。
SocketChannel client =
(SocketChannel) key.channel();
ByteBuffer buffer =
(ByteBuffer) key.attachment();
while (buffer.hasRemaining()) {
if (client.write(buffer) == 0) {
break;
}
}
client.close();
}
} catch (IOException ex) {
key.cancel();
try {
key.channel().close();
} catch (IOException cex) {
// ignore on close
}
}
}
}
}
}
6.3 netty+OIO
public class NettyOioServer {
public void server(int port) throws Exception {
final ByteBuf buf = Unpooled.unreleasableBuffer(
Unpooled.copiedBuffer("Hi!\r\n", Charset.forName("UTF-8")));
EventLoopGroup group = new OioEventLoopGroup();
try {
//创建ServerBootStrap类
ServerBootstrap b = new ServerBootstrap();
b.group(group)
//使用OIOEventLoopGroup以阻塞模式
.channel(OioServerSocketChannel.class)
.localAddress(new InetSocketAddress(port))
//指定channelInitializer对于每个已接收的连接都调用它
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch)
throws Exception {
ch.pipeline().addLast(
//添加一个handler拦截和处理事件
new ChannelInboundHandlerAdapter() {
@Override
public void channelActive(
ChannelHandlerContext ctx)
throws Exception {
ctx.writeAndFlush(buf.duplicate())
//添加一个listener以便消息一写完就关闭连接。
.addListener(
ChannelFutureListener.CLOSE);
}
});
}
});
//绑定服务器以接受连接
ChannelFuture f = b.bind().sync();
f.channel().closeFuture().sync();
} finally {
//释放所有资源
group.shutdownGracefully().sync();
}
}
}
6.4 netty+NIO
public class NettyNioServer {
public void server(int port) throws Exception {
final ByteBuf buf = Unpooled.copiedBuffer("Hi!\r\n",
Charset.forName("UTF-8"));
EventLoopGroup group = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(group).channel(NioServerSocketChannel.class)
.localAddress(new InetSocketAddress(port))
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch)
throws Exception {
ch.pipeline().addLast(
new ChannelInboundHandlerAdapter() {
@Override
public void channelActive(
ChannelHandlerContext ctx) throws Exception {
ctx.writeAndFlush(buf.duplicate())
.addListener(
ChannelFutureListener.CLOSE);
}
});
}
});
ChannelFuture f = b.bind().sync();
f.channel().closeFuture().sync();
} finally {
group.shutdownGracefully().sync();
}
}
}
可以看到netty+NIO只在netty+OIO的代码上修改了两行。
比之前不使用netty时修改的幅度要小许多,代码可重用性更强。
因为 Netty 为每种传输的实现都暴露了相同的 API,所以无论选用哪一种传输的实现,你的代码都仍然几乎不受影响。在所有的情况下,传输的实现都依赖于 interface Channel、ChannelPipeline 和 ChannelHandler。
6.5 传输API
传输 API 的核心是 interface Channel,它被用于所有的 I/O 操作。
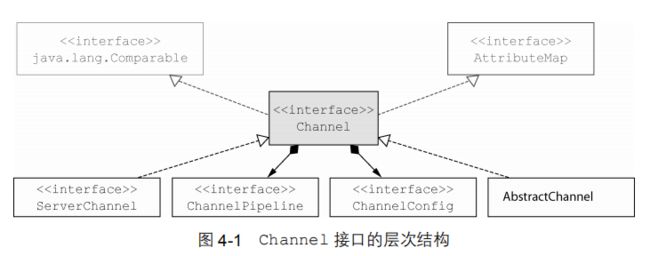
每个 Channel 都将会被分配一个 ChannelPipeline 和 ChannelConfig。ChannelConfig 包含了该 Channel 的所有配置设置,并且支持热更新。由于特定的传输可能具有独特的设置,所以它可能会实现一个 ChannelConfig 的子类型。(请参考 ChannelConfi实现对应的 Javadoc。)
由于 Channel 是独一无二的,所以为了保证顺序将 Channel 声明为 java.lang.Comparable 的一个子接口。因此,如果两个不同的 Channel 实例都返回了相同的散列码,那 么 AbstractChannel 中的 compareTo()方法的实现将会抛出一个 Error。
ChannelPipeline 持有所有将应用于入站和出站数据以及事件的 ChannelHandler 实例,这些 ChannelHandler 实现了应用程序用于处理状态变化以及数据处理的逻辑。
ChannelHandler 的典型用途包括:
- 将数据从一种格式转换为另一种格式;
- 提供异常的通知;
- 提供 Channel 变为活动的或者非活动的通知;
- 提供当 Channel 注册到 EventLoop 或者从 EventLoop 注销时的通知;
- 提供有关用户自定义事件的通知。
拦截过滤器 ChannelPipeline 实现了一种常见的设计模式—拦截过滤器(Intercepting Filter)。UNIX 管道是另外一个熟悉的例子:多个命令被链接在一起,其中一个命令的输出端将连接到命令行中下一个命令的输入端。
除了访问所分配的 ChannelPipeline 和 ChannelConfig 之外,也可以利用 Channel的其他方法,
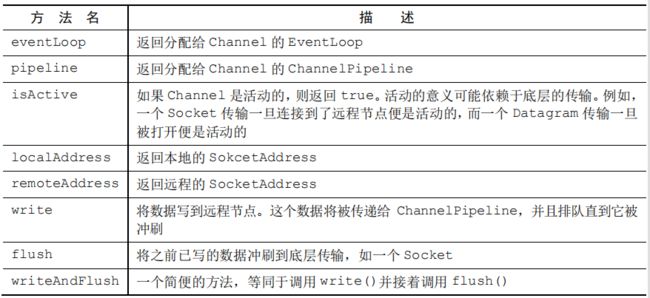
请记住,Netty 所提供的广泛功能只依赖于少量的接口。这意味着,你可以对你的应用程序逻辑进行重大的修改,而又无需大规模地重构你的代码库。
考虑一下写数据并将其冲刷到远程节点这样的常规任务。
Channel channel=...
ByteBuf buf=Unpooled.copiedBuffer("your data",CharsetUtil.UTF_8);
ChannelFuture cf=channel.writeAndFlush(buf);
cf.addListener(new ChannelFutureListener(){
@Override
public void operationComplete(ChannelFuture future){
if(future.isSuccess()){
System.out.println("Write successful");
}else{System.err.println("Write error");
future.cause().printStackTrace();
}}
});
Netty 的 Channel 实现是线程安全的
因此你可以存储一个到 Channel 的引用,并且每当你需要向远程节点写数据时,都可以使用它,即使当时许多线程都在使用它,需要注意的是,消息将会被保证按顺序发送。
final Channel channel = ...
final ByteBuf buf = Unpooled.copiedBuffer("your data",
CharsetUtil.UTF_8).retain();
Runnable writer = new Runnable() {
@Override
public void run() {
channel.writeAndFlush(buf.duplicate());
}
};
Executor executor = Executors.newCachedThreadPool();
// write in one thread
executor.execute(writer);
// write in another thread
executor.execute(writer);
6.6 内置传输
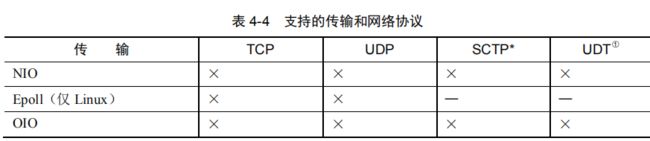
Netty 内置了一些可开箱即用的传输。因为并不是它们所有的传输都支持每一种协议,所以你必须选择一个和你的应用程序所使用的协议相容的传输。
| 名称 | 包 | 描述 |
|---|---|---|
| NIO | io.netty.channel.socket.nio | 使用 java.nio.channels 包作为基础——基于选择器的方式 |
| Epoll | io.netty.channel.epoll | 由 JNI 驱动的epoll()和非阻塞 IO。这个传输支持只有在Linux上可用的多种特性,如SO_REUSEPORT,比 NIO 传输更快,而且是完全非阻塞的 |
| OIO | io.netty.channel.socket.oio | 使用 java.net 包作为基础——使用阻塞流 |
| Local | io.netty.channel.local | 可以在 VM 内部通过管道进行通信的本地传输 |
| Embedded | io.netty.channel.embedded | Embedded 传输,允许使用 ChannelHandler 而又不需要一个真正的基于网络的传输。这在测试你的ChannelHandler 实现时非常有用 |
Epoll是Netty 特有的实现,更加适配 Netty 现有的线程模型,具有更高的性能以及更低的垃圾回收压力,详见 https://github.com/netty/netty/wiki/Native-transports。
6.6.1 NIO–非阻塞IO
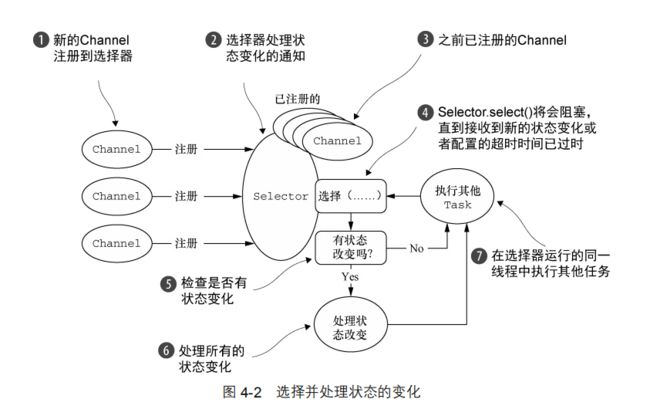
NIO 提供了一个所有 I/O 操作的全异步的实现。它利用了自 NIO 子系统被引入 JDK 1.4 时便可用的基于选择器的 API。
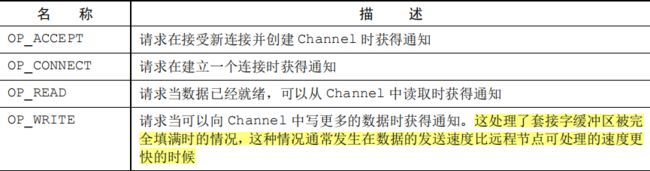
选择器背后的基本概念是充当一个注册表,在那里你将可以请求在 Channel 的状态发生变化时得到通知。可能的状态变化有:
新的 Channel 已被接受并且就绪;
Channel 连接已经完成;
Channel 有已经就绪的可供读取的数据;
Channel 可用于写数据。
选择器运行在一个检查状态变化并对其做出相应响应的线程上,在应用程序对状态的改变做出响应之后,选择器将会被重置,并将重复这个过程。
由class java.nio.channels.SelectionKey定义的位模式。这些位模式可以组合起来定义一组应用程序正在请求通知的状态变化集。
对于所有 Netty 的传输实现都共有的用户级别 API 完全地隐藏了这些 NIO 的内部细节。

6.6.2 Epoll—用于 Linux 的本地非阻塞传输
Netty 的 NIO 传输基于 Java 提供的异步/非阻塞网络编程的通用抽象。虽然这保证了 Netty 的非阻塞 API 可以在任何平台上使用,但它也包含了相应的限制,因为 JDK为了在所有系统上提供相同的功能,必须做出妥协。
epoll——一个高度可扩展的I/O事件通知特性。
Netty为Linux提供了一组NIO API,其以一种和它本身的设计更加一致的方式使用epoll,并且以一种更加轻量的方式使用中断。如果你的应用程序旨在运行于Linux系统,那么请考虑利用这个版本的传输;你将发现在高负载下它的性能要优于JDK的NIO实现。
在之前的6.4的代码清单中使用 epoll 替代 NIO,只需要将 NioEventLoopGroup替换为 EpollEventLoopGroup ,并且将 NioServerSocketChannel.class 替换为EpollServerSocketChannel.class 即可。
6.6.3 OIO—旧的阻塞 I/O
Netty 的 OIO 传输实现代表了一种折中:它可以通过常规的传输 API 使用,但是由于它是建立在 java.net 包的阻塞实现之上的,所以它不是异步的。
在 java.net API 中,你通常会有一个用来接受到达正在监听的 ServerSocket 的新连接的线程。会创建一个新的和远程节点进行交互的套接字,并且会分配一个新的用于处理相应通信流量的线程。这是必需的,因为某个指定套接字上的任何 I/O 操作在任意的时间点上都可能会阻塞。使用单个线程来处理多个套接字,很容易导致一个套接字上的阻塞操作也捆绑了所有其他的套接字。
有了这个背景,你可能会想,Netty是如何能够使用和用于异步传输相同的API来支持OIO的呢。 答案就是,Netty利用SO_TIMEOUT这个Socket标志,它指定了等待一个I/O操作完成的最大毫秒数。如果操作在指定的时间间隔内没有完成,则将会抛出一个SocketTimeout Exception。Netty将捕获这个异常并继续处理循环。在EventLoop下一次运行时,它将再次尝试。这实际上也是类似于Netty这样的异步框架能够支持OIO的唯一方式。

6.6.4 用于 JVM 内部通信的 Local 传输
Netty 提供了一个 Local 传输,用于在同一个 JVM 中运行的客户端和服务器程序之间的异步通信。同样,这个传输也支持对于所有 Netty 传输实现都共同的 API。
在这个传输中,和服务器 Channel 相关联的 SocketAddress 并没有绑定物理网络地址;相反,只要服务器还在运行,它就会被存储在注册表里,并在 Channel 关闭时注销。因为这个传输并不接受真正的网络流量,所以它并不能够和其他传输实现进行互操作。因此,客户端希望连接到(在同一个 JVM 中)使用了这个传输的服务器端时也必须使用它。除了这个限制,它的使用方式和其他的传输一模一样。
6.6.5 Embedded 传输
Netty 提供了一种额外的传输,使得你可以将一组 ChannelHandler 作为帮助器类嵌入到其他的 ChannelHandler 内部。通过这种方式,你将可以扩展一个 ChannelHandler 的功能,而又不需要修改其内部代码。
6.7 传输用例
并不是所有的传输都支持所有的核心协议,其可能会限制你的选择。
非阻塞代码库——如果你的代码库中没有阻塞调用(或者你能够限制它们的范围),那么在 Linux 上使用 NIO 或者 epoll 始终是个好主意。虽然 NIO/epoll 旨在处理大量的并发连接,但是在处理较小数目的并发连接时,它也能很好地工作,尤其是考虑到它在连接之间共享线程的方式。
阻塞代码库——正如我们已经指出的,如果你的代码库严重地依赖于阻塞 I/O,而且你的应用程序也有一个相应的设计,那么在你尝试将其直接转换为 Netty 的 NIO 传输时,你将可能会遇到和阻塞操作相关的问题。不要为此而重写你的代码,可以考虑分阶段迁移:先从OIO 开始,等你的代码修改好之后,再迁移到 NIO(或者使用 epoll,如果你在使用 Linux)
在同一个 JVM 内部的通信——在同一个 JVM 内部的通信,不需要通过网络暴露服务,是Local 传输的完美用例。这将消除所有真实网络操作的开销,同时仍然使用你的 Netty 代码库。如果随后需要通过网络暴露服务,那么你将只需要把传输改为 NIO 或者 OIO 即可。
测试你的 ChannelHandler 实现——如果你想要为自己的 ChannelHandler 实现编写单元测试,那么请考虑使用 Embedded 传输。这既便于测试你的代码,而又不需要创建大量的模拟(mock)对象。你的类将仍然符合常规的 API 事件流,保证该 ChannelHandler在和真实的传输一起使用时能够正确地工作。

7.ByteBuf
网络数据的基本单位总是字节。
Java NIO 提供了 ByteBuffer 作为它的字节容器,但是这个类使用起来过于复杂,而且也有些繁琐。
Netty 的 ByteBuffer 替代品是 ByteBuf,一个强大的实现,既解决了 JDK API 的局限性, 又为网络应用程序的开发者提供了更好的 API。
7.1 ByteBuf的API优点
Netty 的数据处理 API 通过两个组件暴露——abstract class ByteBuf 和 interface ByteBufHolder
ByteBuf API 的优点:
- 它可以被用户自定义的缓冲区类型扩展;
- 通过内置的复合缓冲区类型实现了透明的零拷贝;
- 容量可以按需增长(类似于 JDK 的 StringBuilder);
- 在读和写这两种模式之间切换不需要调用 ByteBuffer 的 flip()方法;
- 读和写使用了不同的索引;
- 支持方法的链式调用;
- 支持引用计数;
- 支持池化。
7.2 ByteBuf类–Netty的数据容器
所有的网络通信都涉及字节序列的移动,所以高效易用的数据结构明显是必不可少的。
7.2.1 ByteBuf类的工作原理
ByteBuf 维护了两个不同的索引:一个用于读取,一个用于写入。当你从 ByteBuf 读取时,它的 readerIndex 将会被递增已经被读取的字节数。同样地,当你写入 ByteBuf 时,其writerIndex 也会被递增。下图为一个空的ByteBuf布局结构和状态。

如果打算读取字节直到 readerIndex 达到和 writerIndex 同样的值时会发生什么?在那时,你将会到达“可以读取的”数据的末尾。就如同试图读取超出数组末尾的数据一样,试图读取超出该点的数据将会触发一个 IndexOutOfBoundsException
名称以 read 或者 write 开头的 ByteBuf 方法,将会推进其对应的索引,而名称以 set 或者 get 开头的操作则不会。
可以指定 ByteBuf 的最大容量。试图移动写索引(writerIndex)超过这个值将会触发一个异常( 也就是说用户直接或者间接使 capacity(int)或者 ensureWritable(int)方法来增加超过该最大容量时抛出异常)(默认的限制Integer.MAX_VALUE)
7.2.2 ByteBuf的使用模式
在使用 Netty 时,你将遇到几种常见的围绕 ByteBuf 而构建的使用模式。把其当做一个由不同的索引分别控制读访问和写访问的字节数组会帮助理解。
7.2.2.1 堆缓冲区
最常用的 ByteBuf 模式是将数据存储在 JVM 的堆空间中。这种模式被称为支撑数组(backing array),它能在没有使用池化的情况下提供快速的分配和释放。
ByteBuf heapBuf = ...;
if (heapBuf.hasArray()) {//检查ByteBuf是否有一个支撑数组
byte[] array = heapBuf.array();
int offset = heapBuf.arrayOffset() + heapBuf.readerIndex();//计算第一个字节的偏移量
int length = heapBuf.readableBytes();
handleArray(array, offset, length);
}
1)堆缓冲的优点是:由于数据存储在JVM的堆中可以快速创建和快速释放,并且提供了数组的直接快速访问的方法。
2)堆缓冲缺点是:每次读写数据都要先将数据拷贝到直接缓冲区再进行传递。
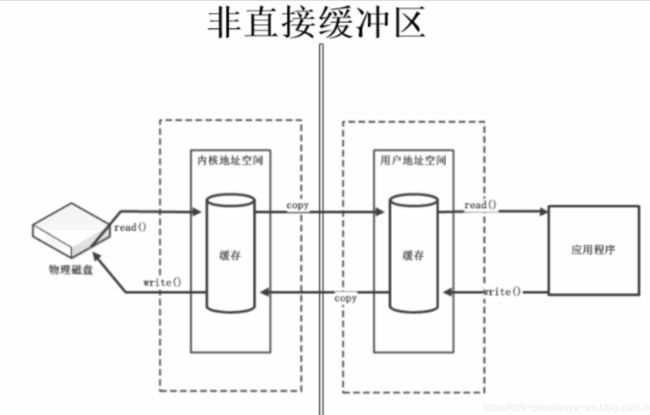

当我们的程序想要从硬盘中读取数据 需要
1.先从物理硬盘把数据读取到物理内存中
2再将内容复制到JVM的内存中
3然后读取应用程序才可以读取到内容
读写都是这样需要复制这一个动作 当遇到大文本的文件时 效率及其低下.
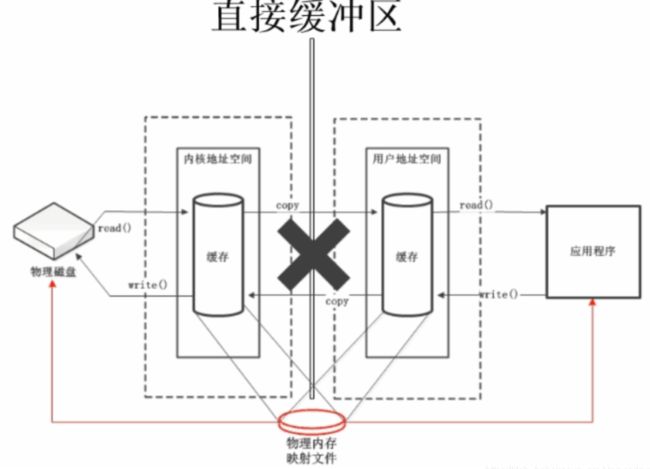
7.2.2.2 直接缓冲区
直接缓冲区是另外一种 ByteBuf 模式。我们期望用于对象创建的内存分配永远都来自于堆中,但这并不是必须的。
NIO 在 JDK 1.4 中引入的 ByteBuffer 类允许 JVM 实现通过本地调用来分配内存。这主要是为了避免在每次调用本地 I/O 操作之前(或者之后)将缓冲区的内容复制到一个中间缓冲区(或者从中间缓冲区把内容复制到缓冲区)。
ByteBuffer的Javadoc①明确指出:“直接缓冲区的内容将驻留在常规的会被垃圾回收的堆之外。”这也就解释了为何直接缓冲区对于网络数据传输是理想的选择。如果你的数据包含在一个在堆上分配的缓冲区中,那么事实上,在通过套接字发送它之前,JVM将会在内部把你的缓冲区复制到一个直接缓冲区中。(所以才有直接缓冲区这个概念,直接在内存中的直接缓冲区中进行操作,不需要再传来传去。)
Direct Buffer在堆之外直接分配内存,直接缓冲区不会占用堆的容量。
(1)Direct Buffer的优点是:在使用Socket传递数据时性能很好,由于数据直接在内存中,不存在从JVM拷贝数据到直接缓冲区的过程,性能好。
(2)缺点是:因为Direct Buffer是直接在内存中,所以分配内存空间和释放内存比堆缓冲区更复杂和慢。
虽然netty的Direct Buffer有这个缺点,但是netty通过内存池来解决这个问题。直接缓冲池不支持数组访问数据,但可以通过间接的方式访问数据数组
ByteBuf directBuf = Unpooled.directBuffer(16);
if(!directBuf.hasArray()){ //因为直接缓冲区是没有支撑数组的 所以这个if语句必须写成!directbuf。hasArray否则代表他是堆缓冲区!而非直接缓冲区。
int len = directBuf.readableBytes();
byte[] arr = new byte[len];
directBuf.getBytes(0, arr);
//无法直接directbuf[i]访问 则采用间接方式访问 拷贝数组
}
7.2.2.3 复合缓冲区
第三种也是最后一种模式使用的是复合缓冲区,它为多个 ByteBuf 提供一个聚合视图。在这里你可以根据需要添加或者删除 ByteBuf 实例,这是一个 JDK 的 ByteBuffer 实现完全缺失的特性。Netty 通过一个 ByteBuf 子类——CompositeByteBuf——实现了这个模式,它提供了一个将多个缓冲区表示为单个合并缓冲区的虚拟表示。
CompositeByteBuf 中的 ByteBuf 实例可能同时包含直接内存分配和非直接内存分配如果其中只有一个实例,那么对 CompositeByteBuf 上的 hasArray()方法的调用将返回该组件上的 hasArray()方法的值;否则它将返回 false(因为直接缓冲区是没有支撑数组的!所以代码段中if语句应该是if(! directbuf.hasArray())…)。
为了举例说明,让我们考虑一下一个由两部分——头部和主体——组成的将通过 HTTP 协议传输的消息。这两部分由应用程序的不同模块产生,将会在消息被发送的时候组装。该应用程序可以选择为多个消息重用相同的消息主体。当这种情况发生时,对于每个消息都将会创建一个新的头部。因为我们不想为每个消息都重新分配这两个缓冲区,所以使用 CompositeByteBuf 是一个完美的选择。它在消除了没必要的复制的同时,暴露了通用的 ByteBuf API。

使用JDK的ByteBuffer实现这一需求:创建了一个包含两个 ByteBuffer 的数组用来保存这些消息组件,同时创建了第三个 ByteBuffer 用来保存所有这些数据的副本。(注意:虽然 ByteBuf 同时具有读索引和写索引,但是 JDK 的 ByteBuffer 却只有一个索引,这也就是为什么必须调用 flip()方法来在读模式和写模式之间进行切换的原因)
// Use an array to hold the message parts
ByteBuffer[] message = new ByteBuffer[] { header, body };
// Create a new ByteBuffer and use copy to merge the header and body
//allocate分配的空间是非直接缓冲区
ByteBuffer message2 =
ByteBuffer.allocate(header.remaining() + body.remaining());
message2.put(header);
message2.put(body);
//flip函数用来在读模式与写模式中进行切换
message2.flip();
分配和复制操作导致效率低下;
使用CompositeByteBuf的复合缓冲区模式
CompositeByteBuf messageBuf = Unpooled.compositeBuffer();
ByteBuf headerBuf = ...; // can be backing or direct
ByteBuf bodyBuf = ...; // can be backing or direct
messageBuf.addComponents(headerBuf, bodyBuf);
.....
messageBuf.removeComponent(0); // remove the header
for (ByteBuf buf : messageBuf) {
System.out.println(buf.toString());
}
CompositeByteBuf 可能不支持访问其支撑数组,因此访问数据类似于(访问)直接缓冲区的模式
访问CompositeByteBuf中数据:(类比之前的,无法提供直接的数组访问,只能间接拷贝来进行随机访问)
CompositeByteBuf compBuf = Unpooled.compositeBuffer();
int length = compBuf.readableBytes();
byte[] array = new byte[length];
compBuf.getBytes(compBuf.readerIndex(), array);
handleArray(array, 0, array.length);
需要注意的是,Netty使用了CompositeByteBuf来优化套接字的
I/O操作,尽可能地消除了由JDK的缓冲区实现所导致的性能以及内存使用率的惩罚。
7.3 字节级操作
7.3.1 随机访问索引
如同在普通的 Java 字节数组中一样,ByteBuf 的索引是从零开始的:第一个字节的索引是0,最后一个字节的索引总是 capacity() - 1。
ByteBuf buffer = ...;
for (int i = 0; i < buffer.capacity(); i++) {
byte b = buffer.getByte(i);
System.out.println((char)b);
}
需要注意的是,使用那些需要一个索引值参数的方法之一来访问数据既不会改变readerIndex 也不会改变writerIndex。如果有需要,也可以通过调用 readerIndex(index)或writerIndex(index)来手动移动这两者。
7.3.2 顺序访问索引
虽然 ByteBuf 同时具有读索引和写索引,但是 JDK 的 ByteBuffer 却只有一个索引,这也就是为什么必须调用 flip()方法来在读模式和写模式之间进行切换的原因。
如下是ByteBuf的内部分段

7.3.3 可丢弃字节
在图 5-3 中标记为可丢弃字节的分段包含了已经被读过的字节。通过调用 discardReadBytes()方法,可以丢弃它们并回收空间。这个分段的初始大小为 0,存储在 readerIndex 中,会随着 read 操作的执行而增加(get*操作不会移动 readerIndex)。
展示了图 5-3 中所展示的缓冲区上调用discardReadBytes()方法后的结果。可以看到,可丢弃字节分段中的空间已经变为可写的了。注意,在调用discardReadBytes()之后,对可写分段的内容并没有任何的保证。
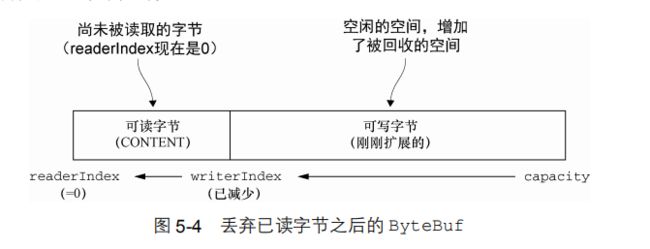
虽然你可能会倾向于频繁地调用 discardReadBytes()方法以确保可写分段的最大化,但是请注意,这将极有可能会导致内存复制(将原来的[r,w]那段移到[0,w-r]段),因为可读字节(图中标记为 CONTENT 的部分)必须被移动到缓冲区的开始位置。
7.3.4 可读字节
ByteBuf 的可读字节分段存储了实际数据。新分配的、包装的或者复制的缓冲区(如执行discardReadBytes()后)的默认的readerIndex 值为 0。任何名称以 read 或者 skip 开头的操作都将检索或者跳过位于当前readerIndex 的数据,并且将它增加已读字节数。
如果被调用的方法需要一个 ByteBuf 参数作为写入的目标,并且没有指定目标索引参数,那么该目标缓冲区的 writerIndex 也将被增加。
ByteBuf buffer = ...;
while (buffer.isReadable()) {
System.out.println(buffer.readByte());
}
7.3.5 可写字节
可写字节分段是指一个拥有未定义内容的、写入就绪的内存区域。新分配的缓冲区的writerIndex 的默认值为 0。任何名称以 write 开头的操作都将从当前的 writerIndex 处开始写数据,并将它增加已经写入的字节数。如果写操作的目标也是 ByteBuf,并且没有指定源索引的值,则源缓冲区的 readerIndex 也同样会被增加相同的大小。
是一个用随机整数值填充缓冲区,直到它空间不足为止的例子。writeableBytes()方法在这里被用来确定该缓冲区中是否还有足够的空间。
// Fills the writable bytes of a buffer with random integers.
ByteBuf buffer = ...;
while (buffer.writableBytes() >= 4) {
buffer.writeInt(random.nextInt());
}
7.3.6 索引管理
JDK 的 InputStream 定义了 mark*(int readlimit)和 reset()方法,这些方法分别被用来将流中的当前位置标记为指定的值,以及将流重置到该位置。
同样可以通过调用 markReaderIndex()、markWriterIndex()、resetWriterIndex()和 resetReaderIndex()来标记和重置 ByteBuf 的 readerIndex 和 writerIndex。这些和InputStream 上的调用类似,只是没有 readlimit 参数来指定标记什么时候失效。也可以通过调用 readerIndex(int)或者 writerIndex(int)来将索引移动到指定位置。试 图将任何一个索引设置到一个无效的位置都将导致一个 IndexOutOfBoundsException。可以通过调用 clear()方法来将 readerIndex 和 writerIndex 都设置为 0。注意,这并不会清除内存中的内容。图 5-5(重复上面的图 5-3)展示了它是如何工作的。


调用 clear()比调用 discardReadBytes()轻量得多,因为它将只是重置索引而不会复制任何的内存。
7.3.7 查找操作
在ByteBuf中有多种可以用来确定指定值的索引的方法。最简单的是使用indexOf()方法。较复杂的查找可以通过那些需要一个ByteBufProcessor,ByteBufProcessor针对一些常见的值定义了许多便利的方法。假设你的应用程序需要和所谓的包含有以NULL结尾的内容的Flash套接字作为参数的方法达成。这个接口只定
义了一个方法:boolean process(byte value)它将检查输入值是否是正在查找的值。
forEachByte(ByteBufProcessor.FIND_NUL)
将简单高效地消费该 Flash 数据,因为在处理期间只会执行较少的边界检查 (查找回车符\r的例子)
ByteBuf buffer = ...;
int index = buffer.forEachByte(ByteBufProcessor.FIND_CR);
7.3.8 派生缓冲区
派生缓冲区为 ByteBuf 提供了以专门的方式来呈现其内容的视图(类比数据库视图,并非真正创建一个备份,而是一个专注于同一副本中不同关注点的不同视图)。这类视图是通过以下方法被创建的:
- duplicate();
- slice();
- slice(int, int);
- Unpooled.unmodifiableBuffer(…);
- order(ByteOrder);
- readSlice(int)。
每个这些方法都将返回一个新的 ByteBuf 实例,它具有自己的读索引、写索引和标记索引。其内部存储和 JDK 的 ByteBuffer 一样也是共享的。
这使得派生缓冲区的创建成本是很低廉的,但是这也意味着,如果你修改了它的内容,也同时修改了其对应的源实例
ByteBuf 复制 如果需要一个现有缓冲区的真实副本,请使用 copy()或者 copy(int, int)方法。不同于派生缓冲区,由这个调用所返回的 ByteBuf 拥有独立的数据副本。
使用slice(int,int)进行切片分段。
Charset utf8 = Charset.forName("UTF-8");
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);
//创建改ByteBuf从0开始到索引15结束的一个新切片
ByteBuf sliced = buf.slice(0, 15);
//将打印Netty in Action
System.out.println(sliced.toString(utf8));
//更新索引0处的字节。
buf.setByte(0, (byte)'J');
//下面这个断言将会成功 因为数据是共享的,对其中一个的更改对另外一个也是可见的。
assert buf.getByte(0) == sliced.getByte(0);
与下面的copy(int,int)是不同的
Charset utf8 = Charset.forName("UTF-8");
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);
ByteBuf copy = buf.copy(0, 15);
System.out.println(copy.toString(utf8));
buf.setByte(0, (byte) 'J');
//将会成功 因为数据是不共享的
assert buf.getByte(0) != copy.getByte(0);
除了修改原始 ByteBuf 的切片或者副本的效果以外,这两种场景是相同的。只要有可能,使用 slice()方法来避免复制内存的开销。
7.3.9 读/写操作
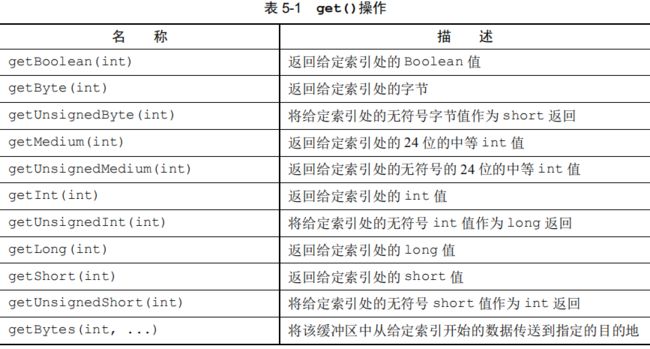
有两种类别的读/写操作:
- get()和 set()操作,从给定的索引开始,并且保持索引不变;
- read()和 write()操作,从给定的索引开始,并且会根据已经访问过的字节数对索引进行调整。
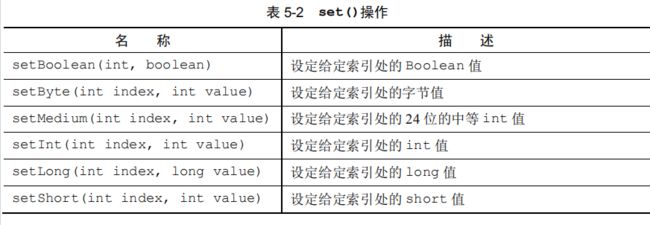

现在,让我们研究一下 read()操作,其作用于当前的 readerIndex 或 writerIndex。这些方法将用于从 ByteBuf 中读取数据,如同它是一个流。
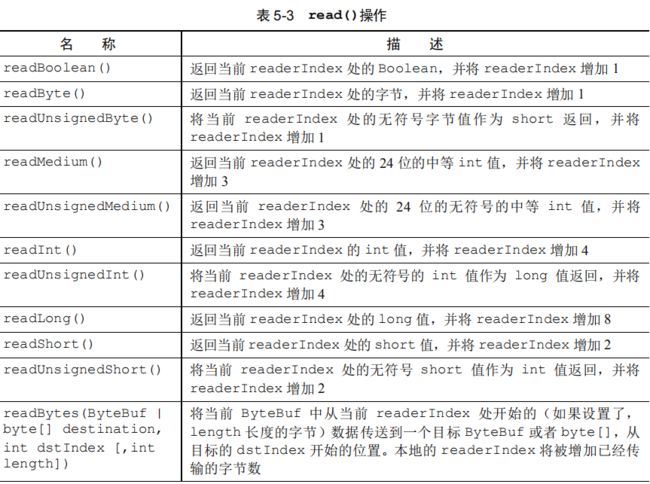
write这些方法的参数是需要写入的值,而不是索引值。
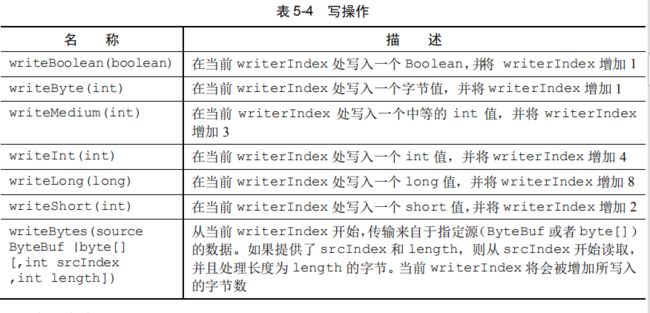

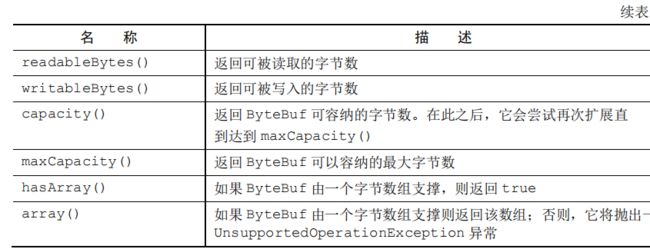
7.3.10 更多的操作

7.4 ByteBufHolder
我们经常发现,除了实际的数据负载之外,我们还需要存储各种属性值。HTTP 响应便是一个很好的例子,除了表示为字节的内容,还包括状态码、cookie 等。
为了处理这种常见的用例,Netty 提供了 ByteBufHolder。ByteBufHolder 也为 Netty 的高级特性提供了支持,如缓冲区池化,其中可以从池中借用 ByteBuf,并且在需要时自动释放、ByteBufHolder 只有几种用于访问底层数据和引用计数的方法。

如果想要实现一个将其有效负载存储在 ByteBuf 中的消息对象,那么 ByteBufHolder 将是个不错的选择。
7.5 ByteBuf分配
管理 ByteBuf 实例的不同方式:
7.5.1 按需分配:ByteBufAllocator 接口
为了降低分配和释放内存的开销,Netty 通过 interface ByteBufAllocator 实现了(ByteBuf 的)池化(参考线程池 放池里统一管理),它可以用来分配我们所描述过的任意类型的 ByteBuf 实例。

默认地,当所运行的环境具有 sun.misc.Unsafe 支持时,返回基于直接内存存储的 ByteBuf,否则返回基于堆内存存储的ByteBuf;当指定使用 PreferHeapByteBufAllocator 时,则只会返回基于堆内存存储的 ByteBuf。
可以通过 Channel(每个都可以有一个不同的 ByteBufAllocator 实例)或者绑定到ChannelHandler 的 ChannelHandlerContext 获取一个到 ByteBufAllocator 的引用。

Netty提供了两种ByteBufAllocator的实现:PooledByteBufAllocator和UnpooledByteBufAllocator。前者池化了ByteBuf的实例以提高性能并最大限度地减少内存碎片。此实现使用了一种称为jemalloc的已被大量现代操作系统所采用的高效方法来分配内存。后者的实现不池化ByteBuf实例,并且在每次它被调用时都会返回一个新的实例。
虽然Netty默认使用了PooledByteBufAllocator,但这可以很容易地通过ChannelConfig API或者在引导你的应用程序时指定一个不同的分配器来更改。
7.5.2 Unpooled 缓冲区
可能某些情况下,你未能获取一个到 ByteBufAllocator 的引用。对于这种情况,Netty 提供了一个简单的称为 Unpooled 的工具类,它提供了静态的辅助方法来创建未池化的 ByteBuf实例。

7.5.3 ByteBufUtil 类
ByteBufUtil 提供了用于操作 ByteBuf 的静态的辅助方法。因为这个 API 是通用的,并且和池化无关,所以这些方法已然在分配类的外部实现。
这些静态方法中最有价值的可能就是 hexdump()方法,它以十六进制的表示形式打印ByteBuf 的内容。这在各种情况下都很有用,例如,出于调试的目的记录 ByteBuf 的内容。十六进制的表示通常会提供一个比字节值的直接表示形式更加有用的日志条目,此外,十六进制的版本还可以很容易地转换回实际的字节表示。另一个有用的方法是 boolean equals(ByteBuf, ByteBuf),它被用来判断两个 ByteBuf实例的相等性。如果你实现自己的ByteBuf 子类,你可能会发现 ByteBufUtil 的其他有用方法。
7.6 引用计数
引用计数是一种通过在某个对象所持有的资源不再被其他对象引用时释放该对象所持有的资源来优化内存使用和性能的技术。Netty 在第 4 版中为 ByteBuf 和 ByteBufHolder 引入了引用计数技术,它们都实现了 interface ReferenceCounted。(与JVM类似)
引用计数背后的想法并不是特别的复杂;它主要涉及跟踪到某个特定对象的活动引用的数量。一个 ReferenceCounted 实现的实例将通常以活动的引用计数为 1 作为开始。只要引用计数大于 0,就能保证对象不会被释放。当活动引用的数量减少到 0 时,该实例就会被释放。注意,虽然释放的确切语义可能是特定于实现的,但是至少已经释放的对象应该不可再用了。
引用计数对于池化实现(如 PooledByteBufAllocator)来说是至关重要的,它降低了内存分配的开销。(引用计数大于0则可以一直分配这个实例来用帮助实现池化。)

试图访问一个已经被释放的引用计数的对象,将会导致一个 IllegalReferenceCountException。注意,一个特定的(ReferenceCounted 的实现)类,可以用它自己的独特方式来定义它的引用计数规则。例如,我们可以设想一个类,其 release()方法的实现总是将引用计数设为零,而不用关心它的当前值,从而一次性地使所有的活动引用都失效。
谁负责释放 一般来说,是由最后访问(引用计数)对象的那一方来负责将它释放。
8 ChannelHandler与ChannelHandlerPipeline
8.1 ChannelHandler家族
8.1.1 Channel的生命周期
Interface Channel 定义了一组和 ChannelInboundHandler API 密切相关的简单但功能强大的状态模型


Channel 的正常生命周期如图。当这些状态发生改变时,将会生成对应的事件。这些事件将会被转发给 ChannelPipeline 中的 ChannelHandler,其可以随后对它们做出响应。

8.1.2 ChannelHandler的生命周期
6-2 中列出了 interface ChannelHandler 定义的生命周期操作,在 ChannelHandler被添加到 ChannelPipeline 中或者被从 ChannelPipeline 中移除时会调用这些操作。这些方法中的每一个都接受一个 ChannelHandlerContext 参数。

Netty 定义了下面两个重要的 ChannelHandler 子接口:
- ChannelInboundHandler——处理入站数据以及各种状态变化;
- ChannelOutboundHandler——处理出站数据并且允许拦截所有的操作。
8.1.3 ChannelInboundHandler 生命周期
表 6-3 列出了 interface ChannelInboundHandler 的生命周期方法。这些方法将会在数据被接收时或者与其对应的 Channel 状态发生改变时被调用。正如我们前面所提到的,这些方法和 Channel 的生命周期密切相关。

当某个 ChannelInboundHandler 的实现重写 channelRead()方法时,它将负责显式地释放与池化的 ByteBuf 实例相关的内存。Netty 为此提供了一个实用方法 ReferenceCountUtil.release()

Netty 将使用 WARN 级别的日志消息记录未释放的资源,使得可以非常简单地在代码中发现违规的实例。但是以这种方式管理资源可能很繁琐。一个更加简单的方式是使用SimpleChannelInboundHandler。
@Sharable
public class SimpleDiscardHandler
extends SimpleChannelInboundHandler<Object> {
@Override
public void channelRead0(ChannelHandlerContext ctx,
Object msg) {
//不需要任何显式的资源释放
// No need to do anything special
} }
由于 SimpleChannelInboundHandler 会自动释放资源,所以你不应该存储指向任何消息的引用供将来使用,因为这些引用都将会失效。
8.1.4 ChannelOutboundHandler生命周期
出站操作和数据将由 ChannelOutboundHandler 处理。它的方法将被 Channel、ChannelPipeline 以及 ChannelHandlerContext 调用。
ChannelOutboundHandler 的一个强大的功能是可以按需推迟操作或者事件,这使得可以通过一些复杂的方法来处理请求。例如,如果到远程节点的写入被暂停了,那么你可以推迟冲刷操作并在稍后继续。
ChannelPromise与ChannelFuture ChannelOutboundHandler中的大部分方法都需要一个ChannelPromise参数,以便在操作完成时得到通知。ChannelPromise是ChannelFuture的一个子类,其定义了一些可写的方法,如setSuccess()和setFailure(),从而使ChannelFuture不可变
这里借鉴的是 Scala 的 Promise 和 Future 的设计,当一个Promise 被完成之后,其对应的 Future 的值便不能再进行任何修改了。
8.1.5 ChannelHandler适配器
你可以使用 ChannelInboundHandlerAdapter 和 ChannelOutboundHandlerAdapter类作为自己的ChannelHandler 的起始点。这两个适配器分别提供了ChannelInboundHandler和 ChannelOutboundHandler 的基本实现。通过扩展抽象类 ChannelHandlerAdapter,它们获得了它们共同的超接口 ChannelHandler 的方法。
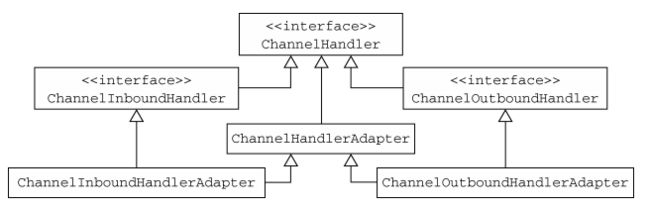
ChannelHandlerAdapter 还提供了实用方法 isSharable()。如果其对应的实现被标注为 Sharable,那么这个方法将返回 true,表示它可以被添加到多个 ChannelPipeline中。
在 ChannelInboundHandlerAdapter 和ChannelOutboundHandlerAdapter 中所提供的方法体调用了其相关联的 ChannelHandlerContext 上的等效方法,从而将事件转发到了 ChannelPipeline 中的下一个 ChannelHandler 中。
8.1.6 资源管理
每当通过调用ChannelInboundHandler.channelRead()或者 ChannelOutboundHandler.write()方法来处理数据时,你都需要确保没有任何的资源泄漏。Netty 使用引用计数来处理池化的 ByteBuf。所以在完全使用完某个ByteBuf 后,调整其引用计数是很重要的。
为了帮助你诊断潜在的(资源泄漏)问题,Netty提供了class ResourceLeakDetector它将对你应用程序的缓冲区分配做大约 1%的采样来检测内存泄露。相关的开销是非常小的。
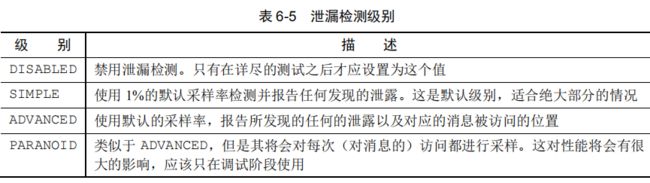
泄露检测级别可以通过将下面的 Java 系统属性设置为表中的一个值来定义:
java -Dio.netty.leakDetectionLevel=ADVANCED
实现 ChannelInboundHandler.channelRead()和 ChannelOutboundHandler.write()方法时,应该如何使用这个诊断工具来防止泄露呢?让我们看看你的 channelRead()操作直接消费入站消息的情况;也就是说,它不会通过调用ChannelHandlerContext.fireChannelRead()方法将入站消息转发给下一个 ChannelInboundHandler。

消费入站消息的简单方式 由于消费入站数据是一项常规任务,所以 Netty 提供了一个特殊的被称为SimpleChannelInboundHandler 的 ChannelInboundHandler 实现。这个实现会在消息被 channelRead0()方法消费之后自动释放消息。
在出站方向这边,如果你处理了 write()操作并丢弃了一个消息,那么你也应该负责释放它。代码清单 6-4 展示了一个丢弃所有的写入数据的实现。

总之,如果一个消息被消费或者丢弃了,并且没有传递给 ChannelPipeline 中的下一个ChannelOutboundHandler,那么用户就有责任调用 ReferenceCountUtil.release()。如果消息到达了实际的传输层,那么当它被写入时或者 Channel 关闭时,都将被自动释放。
8.2 ChannelPipeline接口
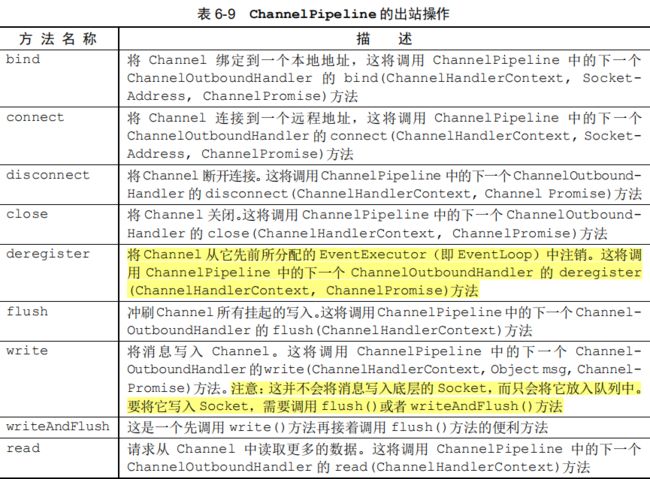
如果你认为ChannelPipeline是一个拦截流经Channel的入站和出站事件的ChannelHandler 实例链,那么就很容易看出这些ChannelHandler 之间的交互是如何组成一个应用程序数据和事件处理逻辑的核心的。
每一个新创建的 Channel 都将会被分配一个新ChannelPipeline。这项关联是永久性的;Channel 既不能附加另外一个ChannelPipeline,也不能分离其当前的。在 Netty 组件的生命周期中,这是一项固定的操作,不需要开发人员的任何干预。(透明的)
根据事件的起源,事件将会被 ChannelInboundHandler 或者 ChannelOutboundHandler处理。随后,通过调用ChannelHandlerContext 实现,它将被转发给同一超类型(入站传入站或出站传出站)的下一个ChannelHandler。

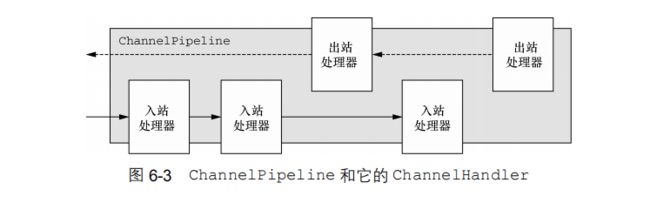

在 ChannelPipeline 传播事件时,它会测试 ChannelPipeline 中的下一个 ChannelHandler 的类型是否和事件的运动方向相匹配。如果不匹配,ChannelPipeline 将跳过该ChannelHandler 并前进到下一个,直到它找到和该事件所期望的方向相匹配的为止。(当然,ChannelHandler 也可以同时实现 ChannelInboundHandler 接口和 ChannelOutboundHandler 接口。))
8.2.1 修改ChannelPipeline
ChannelHandler可以通过添加、删除修改替换其他的ChannelHandler来实时修改ChannelPipeline的布局。


ChannelHandler 的执行和阻塞
通常 ChannelPipeline 中的每一个 ChannelHandler 都是通过它的 EventLoop(I/O 线程)来处理传递给它的事件的。所以至关重要的是不要阻塞这个(EventLoop)线程,因为这会对整体的 I/O 处理产生负面的影响。但有时可能需要与那些使用阻塞 API 的遗留代码进行交互。对于这种情况,ChannelPipeline 有一些接受一个 EventExecutorGroup 的 add()方法。如果一个事件被传递给一个自定义的 EventExecutorGroup,它将被包含在这个 EventExecutorGroup 中的某个 EventExecutor 所处理,从而被从该Channel 本身的 EventLoop 中移除。对于这种用例,Netty 提供了一个叫 DefaultEventExecutorGroup 的默认实现。

8.2.2 触发事件
这些带fire的方法都是channelpipeline用来传递到下一个相同的Channelhandler的方法 (用来传递的!)
入站:

出站:
8.3 ChannelHandlerContext接口
ChannelHandlerContext 代表了 ChannelHandler 和 ChannelPipeline 之间的关联,每当有 ChannelHandler 添加到 ChannelPipeline 中时,都会创建 ChannelHandlerContext。ChannelHandlerContext 的主要功能是管理它所关联的ChannelHandler 和在同一个 ChannelPipeline 中的其他 ChannelHandler 之间的交互。
ChannelHandlerContext 有很多的方法,其中一些方法也存在于 Channel 和 ChannelPipeline 本身上,但是有一点重要的不同。如果调用 Channel 或者 ChannelPipeline 上的这些方法,它们将沿着整个 ChannelPipeline 进行传播。而调用位于ChannelHandlerContext上的相同方法,则将从当前所关联的 ChannelHandler 开始,并且只会传播给位于该ChannelPipeline 中的下一个能够处理该事件的 ChannelHandler。


当使用 ChannelHandlerContext 的 API 的时候,请牢记以下两点:
ChannelHandlerContext 和 ChannelHandler 之间的关联(绑定)是永远不会改变的,所以缓存对它的引用是安全的;
如同我们在本节开头所解释的一样,相对于其他类的同名方法,ChannelHandler Context的方法将产生更短的事件流,应该尽可能地利用这个特性来获得最大的性能。
8.3.1 使用ChannelHandlerContext
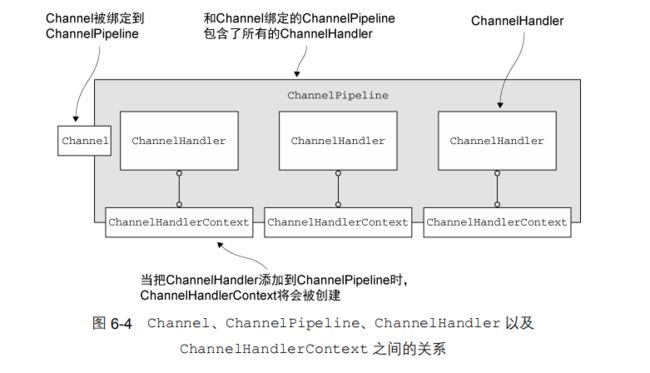
ChannelHandlerContext 获取到 Channel 的引用。调用Channel 上的 write()方法将会导致写入事件从尾端到头部地流经 ChannelPipeline。
ChannelHandlerContext ctx = ..;
Channel channel = ctx.channel();
//通过Channel写入缓冲区
channel.write(Unpooled.copiedBuffer("Netty in Action",
CharsetUtil.UTF_8));
通过channelpipeline写入缓冲区:
ChannelHandlerContext ctx = ..;
ChannelPipeline pipeline = ctx.pipeline();
pipeline.write(Unpooled.copiedBuffer("Netty in Action",
CharsetUtil.UTF_8));
虽然被调用的 Channel 或 ChannelPipeline 上的 write()方法将一直传播事件通过整个 ChannelPipeline,但是在 ChannelHandler 的级别上,事件从一个 ChannelHandler到下一个 ChannelHandler 的移动是由 ChannelHandlerContext 上的调用完成的。
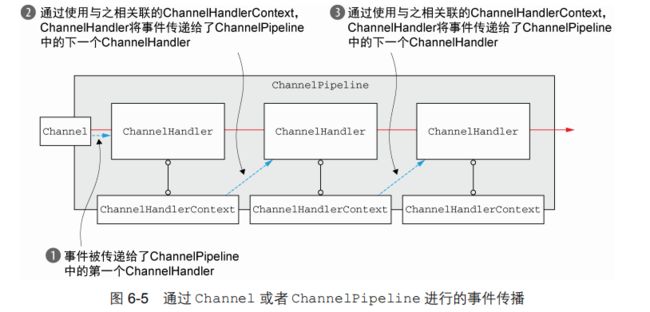
为什么会想要从 ChannelPipeline 中的某个特定点开始传播事件呢?
- 为了减少将事件传经对它不感兴趣的 ChannelHandler 所带来的开销。
- 为了避免将事件传经那些可能会对它感兴趣的 ChannelHandler。
要想调用从某个特定的 ChannelHandler 开始的处理过程,必须获取到在(ChannelPipeline)该 ChannelHandler 之前的 ChannelHandler 所关联的 ChannelHandlerContext。这个 ChannelHandlerContext 将调用和它所关联的 ChannelHandler 之后的ChannelHandler。
ChannelHandlerContext ctx = ..;
ctx.write(Unpooled.copiedBuffer("Netty in Action", CharsetUtil.UTF_8));
//write()方法将把缓冲区数据发送到下一个 ChannelHandler
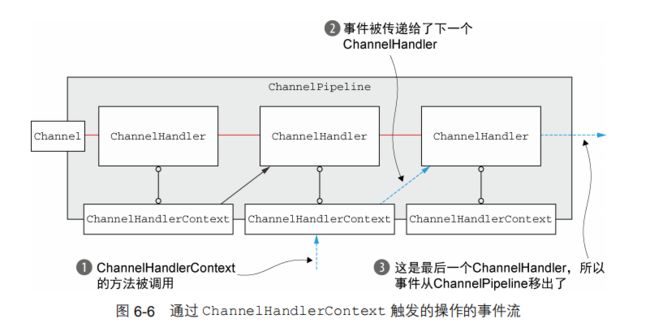
8.3.2 高级用法
你可以通过调用 ChannelHandlerContext 上的pipeline()方法来获得被封闭的 ChannelPipeline 的引用。这使得运行时得以操作ChannelPipeline 的 ChannelHandler,我们可以利用这一点来实现一些复杂的设计。例如,你可以通过将 ChannelHandler 添加到 ChannelPipeline 中来实现动态的协议切换。
另一种高级的用法是缓存到 ChannelHandlerContext 的引用以供稍后使用,这可能会发生在任何的 ChannelHandler 方法之外,甚至来自于不同的线程。代码清单 6-9 展示了用这种模式来触发事件。


这段代码的问题在于它拥有状态,即用于跟踪方法调用次数的实例变量count。将这个类的一个实例添加到ChannelPipeline将极有可能在它被多个并发的Channel访问时导致问题。(当然,这个简单的问题可以通过使channelRead()方法变为同步方法来修正。)
总之,只应该在确定了你的 ChannelHandler 是线程安全的时才使用@Sharable 注解。
为何要共享同一个ChannelHandler: 在多个ChannelPipeline中安装同一个ChannelHandler的一个常见的原因是用于收集跨越多个 Channel 的统计信息。
8.4 异常处理
8.4.1 处理入站异常
如果在处理入站事件的过程中有异常被抛出,那么它将从它在 ChannelInboundHandler里被触发的那一点开始流经 ChannelPipeline。要想处理这种类型的入站异常,你需要在你的 ChannelInboundHandler 实现中重写下面的方法。
public void exceptionCaught(ChannelHandlerContext
ctx, Throwable cause) throws Exception
public class InboundExceptionHandler extends ChannelInboundHandlerAdapter {
@Override
public void exceptionCaught(ChannelHandlerContext ctx,
Throwable cause) {
cause.printStackTrace();
ctx.close();
} }
因为异常将会继续按照入站方向流动(就像所有的入站事件一样),所以实现了前面所示逻辑的 ChannelInboundHandler 通常位于 ChannelPipeline 的最后。这确保了所有的入站异常都总是会被处理,无论它们可能会发生在 ChannelPipeline 中的什么位置。
你应该如何响应异常,可能很大程度上取决于你的应用程序。你可能想要关闭Channel(和连接),也可 能会尝试进行恢复。如果你不实现任何处理入站异常的逻辑(或者没有消费该异常),那么Netty将会记录该异常没有被处理的事实
- ChannelHandler.exceptionCaught()的默认实现是简单地将当前异常转发给ChannelPipeline 中的下一个 ChannelHandler;
- 如果异常到达了 ChannelPipeline 的尾端,它将会被记录为未被处理;
- 要想定义自定义的处理逻辑,你需要重写 exceptionCaught()方法。然后你需要决定是否需要将该异常传播出去。
8.4.2 处理出站异常
用于处理出站操作中的正常完成以及异常的选项,都基于以下的通知机制。
每个出站操作都将返回一个 ChannelFuture。注册到 ChannelFuture 的 ChannelFutureListener 将在操作完成时被通知该操作是成功了还是出错了。
几乎所有的 ChannelOutboundHandler 上的方法都会传入一个 ChannelPromise的实例。作为 ChannelFuture 的子类,ChannelPromise 也可以被分配用于异步通知的监听器。但是,ChannelPromise 还具有提供立即通知的可写方法:
ChannelPromise setSuccess();
ChannelPromise setFailure(Throwable cause);
添加 ChannelFutureListener 只需要调用 ChannelFuture 实例上的 addListener(ChannelFutureListener)方法,并且有两种不同的方式可以做到这一点。其中最常用的方式是,调用出站操作(如 write()方法)所返回的 ChannelFuture 上的 addListener()方法。
ChannelFuture future = channel.write(someMessage);
future.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture f) {
if (!f.isSuccess()) {
f.cause().printStackTrace();
f.channel().close();
} }
});
第二种方式是将 ChannelFutureListener 添加到即将作为参数传递给 ChannelOutboundHandler 的方法的 ChannelPromise。下面代码中所展示的代码和上面代码中所展示的具有相同的效果。
public class OutboundExceptionHandler extends ChannelOutboundHandlerAdapter {
@Override
public void write(ChannelHandlerContext ctx, Object msg,
ChannelPromise promise) {
promise.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture f) {
if (!f.isSuccess()) {
f.cause().printStackTrace();
f.channel().close();
} }
});
} }
ChannelPromise 的可写方法通过调用 ChannelPromise 上的 setSuccess()和 setFailure()方法,可以使一个操作的状态在 ChannelHandler 的方法返回给其调用者时便即刻被感知到。
如果你的 ChannelOutboundHandler 本身抛出了异常会发生什么呢?在这种情况下,Netty 本身会通知任何已经注册到对应 ChannelPromise 的监听器。
9 EventLoop与线程模型
简单地说,线程模型指定了操作系统、编程语言、框架或者应用程序的上下文中的线程管理的关键方面。
9.1 线程模型概述
在早期的 Java 语言中,我们使用多线程处理的主要方式无非是按需创建和启动新的 Thread 来执行并发的任务单元——一种在高负载下工作得很差的原始方式。Java 5 随后引入了 Executor API,其线程池通过缓存和重用Thread 极大地提高了性能。
基本的线程池化模式可以描述为:
- 从池的空闲线程列表中选择一个 Thread,并且指派它去运行一个已提交的任务(一个Runnable 的实现);
- 当任务完成时,将该 Thread 返回给该列表,使其可被重用。
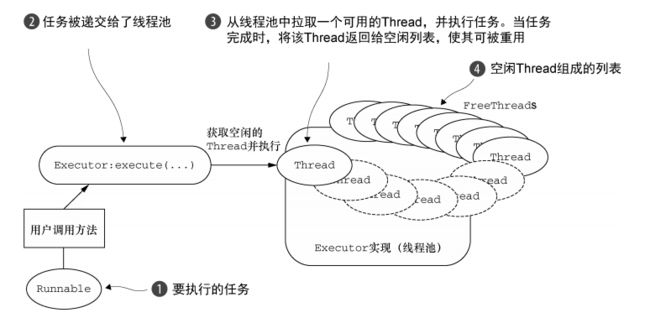
虽然池化和重用线程相对于简单地为每个任务都创建和销毁线程是一种进步,但是它并不能消除由上下文切换所带来的开销,其将随着线程数量的增加很快变得明显,并且在高负载下愈演愈烈。
9.2 EventLoop 接口
运行任务来处理在连接的生命周期内发生的事件是任何网络框架的基本功能。与之相应的编程上的构造通常被称为事件循环----一个 Netty 使用了 interface io.netty.channel.EventLoop 来适配的术语。
while (!terminated) {
List<Runnable> readyEvents = blockUntilEventsReady();//阻塞 直到有事件已经就绪可被运行
for (Runnable ev: readyEvents) {
ev.run();//循环遍历 并处理所有事件
} }
Netty 的 EventLoop 是协同设计的一部分,它采用了两个基本的 API:并发和网络编程。
首先,io.netty.util.concurrent 包构建在 JDK 的java.util.concurrent 包上,用来提供线程执行器。其次,io.netty.channel 包中的类,为了与 Channel 的事件进行交互,扩展了这些接口/类。
在这个模型中,一个 EventLoop 将由一个永远都不会改变的 Thread 驱动,同时任务(Runnable 或者 Callable)可以直接提交给 EventLoop 实现,以立即执行或者调度执行。根据配置和可用核心的不同,可能会创建多个 EventLoop 实例用以优化资源的使用,并且单个EventLoop 可能会被指派用于服务多个 Channel。需要注意的是,Netty的EventLoop在继承了ScheduledExecutorService的同时,只定义了一个方法,parent()①。(重写了 EventExecutor 的 EventExecutorGroup.parent()方法。)这个方法,如下面的代码片断所示,用于返回到当前EventLoop实现的实例所属的EventLoopGroup的引用。
事件/任务的执行顺序 事件和任务是以先进先出(FIFO)的顺序执行的。这样可以通过保证字节内容总是按正确的顺序被处理,消除潜在的数据损坏的可能性。
9.3 任务调度
偶尔,你将需要调度一个任务以便稍后(延迟)执行或者周期性地执行。例如,你可能想要注册一个在客户端已经连接了 5 分钟之后触发的任务。一个常见的用例是,发送心跳消息到远程节点,以检查连接是否仍然还活着。如果没有响应,你便知道可以关闭该Channel 了。
9.3.1 JDK的任务调度API
在 Java 5 之前,任务调度是建立在 java.util.Timer 类之上的,其使用了一个后台 Thread,并且具有与标准线程相同的限制。
JDK 提供了 java.util.concurrent 包,它定义了interface ScheduledExecutorService。


9.3.2 netty的EventLop调度任务
ScheduledExecutorService 的实现具有局限性,例如,事实上作为线程池管理的一部分,将会有额外的线程创建。如果有大量任务被紧凑地调度,那么这将成为一个瓶颈。Netty 通过 Channel 的 EventLoop 实现任务调度解决了这一问题
Channel ch = ...
ScheduledFuture<?> future =ch.eventLoop().schedule(
new Runnable() {
@Override
public void run() {
System.out.println("60 seconds later");
}
}, 60, TimeUnit.SECONDS);
经过 60 秒之后,Runnable 实例将由分配给 Channel 的 EventLoop 执行。如果要调度任务以每隔 60 秒执行一次,请使用 scheduleAtFixedRate()方法,
Channel ch = ...
ScheduledFuture<?> future = ch.eventLoop().scheduleAtFixedRate(
new Runnable() {
@Override
public void run() {
System.out.println("Run every 60 seconds");
}
}, 60, 60, TimeUnit.Seconds);
要想取消或者检查(被调度任务的)执行状态,可以使用每个异步操作所返回的 ScheduledFuture。
ScheduledFuture<?> future = ch.eventLoop().scheduleAtFixedRate(...);
// Some other code that runs...
boolean mayInterruptIfRunning = false;
//取消该任务,防止它再次运行。
future.cancel(mayInterruptIfRunning);
9.4 实现细节
9.4.1 线程管理
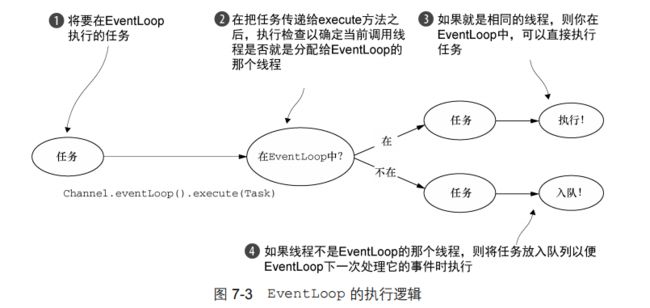
Netty线程模型的卓越性能取决于对于当前执行的Thread的身份的确定,也就是说,确定它是否是分配给当前Channel以及它的EventLoop的那一个线程。(回想一下EventLoop将负责处理一个Channel的整个生命周期内的所有事件。)
如果(当前)调用线程(执行excute(task)方法的线程)正是支撑 EventLoop 的线程,那么所提交的代码块将会被(直接)执行。否则,EventLoop 将调度该任务以便稍后执行,并将它放入到内部队列中。当 EventLoop下次处理它的事件时,它会执行队列中的那些任务/事件。这也就解释了任何的 Thread 是如何与 Channel 直接交互而无需在 ChannelHandler 中进行额外同步的。
每个 EventLoop 都有它自已的任务队列,独立于任何其他的 EventLoop
“永远不要将一个长时间运行的任务放入到执行队列中,因为它将阻塞需要在同一线程上执行的任何其他任务。”
如果必须要进行阻塞调用或者执行长时间运行的任务,我们建议使用一个专门的EventExecutor。(参考8.2.1中ChannelHandler的执行和阻塞)
9.4.2 EventLoop/线程的分配
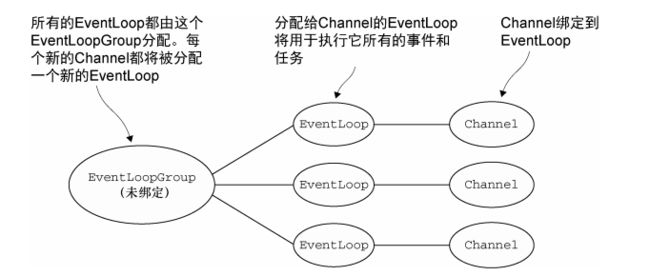
服务于 Channel 的 I/O 和事件的 EventLoop 包含在EventLoopGroup 中。根据不同的传输实现,EventLoop 的创建和分配方式也不同。
9.4.2.1 异步传输
异步传输实现只使用了少量的 EventLoop(以及和它们相关联的 Thread),而且在当前的线程模型中,它们可能会被多个 Channel 所共享。这使得可以通过尽可能少量的 Thread 来支撑大量的 Channel,而不是每个 Channel 分配一个 Thread。
下图显示了一个 EventLoopGroup,它具有 3 个固定大小的 EventLoop(每个 EventLoop都由一个 Thread 支撑)。在创建 EventLoopGroup 时就直接分配了 EventLoop(以及支撑它们的 Thread),以确保在需要时它们是可用的。
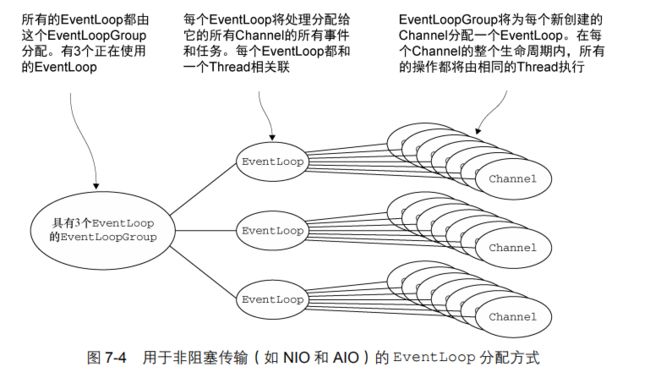
(注意图中 每个channel的整个生命周期内,所有操作都由相同的Thread执行。EventLoop:Thread=1:1)
一旦一个 Channel 被分配给一个 EventLoop,它将在它的整个生命周期中都使用这个EventLoop(以及相关联的 Thread)。请牢记这一点,因为它可以使你从担忧你的 ChannelHandler 实现中的线程安全和同步问题中解脱出来。(单线程 不存在线程安全和同步问题)
另外,需要注意的是,EventLoop 的分配方式对 ThreadLocal 的使用的影响。因为一个EventLoop 通常会被用于支撑多个 Channel,所以对于所有相关联的 Channel 来说,ThreadLocal 都将是一样的。这使得它对于实现状态追踪等功能来说是个糟糕的选择。然而,在一些无状态的上下文中,它仍然可以被用于在多个 Channel 之间共享一些重度的或者代价昂贵的对象,甚至是事件。
9.4.2.2 阻塞传输
用于像 OIO(旧的阻塞 I/O)这样的其他传输的设计略有不同,如图
这里每一个 Channel 都将被分配给一个 EventLoop(以及它的 Thread)。
但是,正如同之前一样,得到的保证是每个 Channel 的 I/O 事件都将只会被一个 Thread(用于支撑该 Channel 的 EventLoop 的那个 Thread)处理。这也是另一个 Netty 设计一致性的例子,它(这种设计上的一致性)对 Netty 的可靠性和易用性做出了巨大贡献。
10 引导
10.1 BootStrap类
引导类的层次结构包括一个抽象的父类和两个具体的引导子类

相对于将具体的引导类分别看作用于服务器和客户端的引导来说,记住它们的本意是用来支撑不同的应用程序的功能的将有所裨益。
服务器致力于使用一个父 Channel 来接受来自客户端的连接,并创建子 Channel 以用于它们之间的通信;而客户端将最可能只需要一个单独的、没有父 Channel 的 Channel 来用于所有的网络交互。(正如同我们将要看到的,这也适用于无连接的传输协议,如 UDP(面向无连接的),因为它们并不是每个连接都需要一个单独的 Channel。)
其中一些在客户端和服务器都有用到。两种应用程序类型之间通用的引导步骤由 AbstractBootstrap 处理,而特定于客户端或者服务器的引导步骤则分别由 Bootstrap 或 ServerBootstrap 处理。

为什么EventLoopGroup是浅拷贝呢?因为cloneable中的clone函数是浅拷贝,对于基本类型赋值,但是对于引用类型如对象则采取浅拷贝,赋值对象的引用,指向这个对象。所以EventLoopGroup此对象也是浅拷贝。
10.2 引导客户端和无连接协议
Bootstrap 类被用于客户端或者使用了无连接协议的应用程序中。
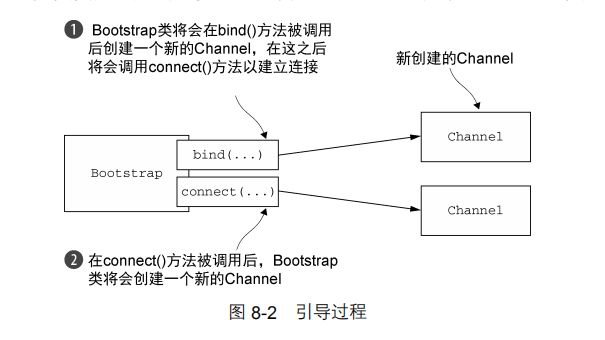
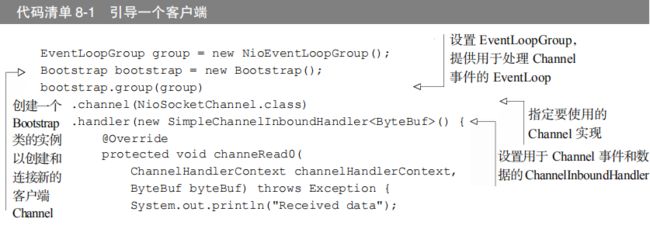
10.2.1 引导客户端
Bootstrap 类负责为客户端和使用无连接协议的应用程序创建 Channel,如图所示

10.2.2 Channel与EventLoopGroup的兼容性


10.3 引导服务器
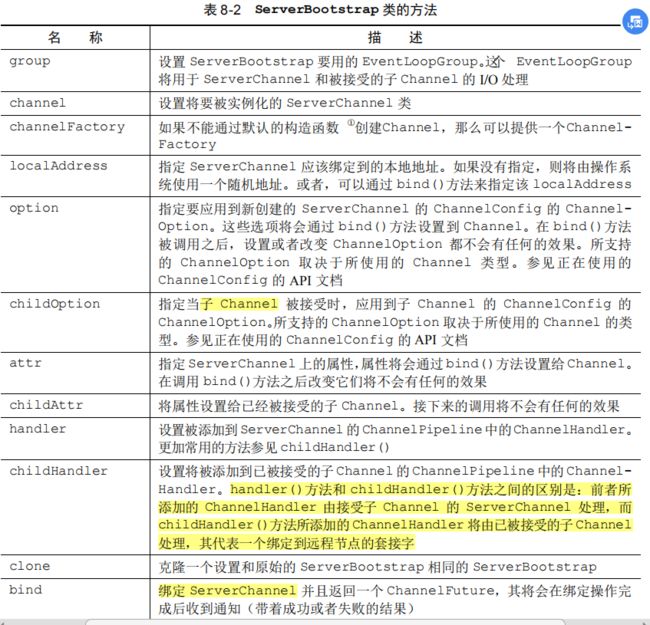
10.3.1 ServerBootStrap类
10.3.2 引导服务器
你可能已经注意到了,表 8-2 中列出了一些在表 8-1 中不存在的方法:childHandler()、childAttr()和 childOption()。这些调用支持特别用于服务器应用程序的操作。具体来说,ServerChannel 的实现负责创建子 Channel,这些子 Channel 代表了已被接受的连接。
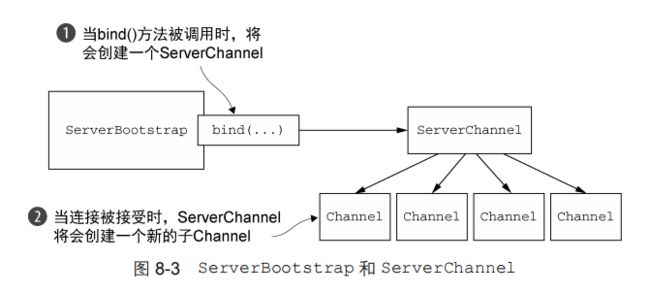
ServerBootstrap 在 bind()方法被调用时创建了一个ServerChannel,并且该 ServerChannel 管理了多个子 Channel。
10.4 从Channel引导客户端
假设你的服务器正在处理一个客户端的请求,这个请求需要它充当第三方系统的客户端。当一个应用程序(如一个代理服务器)必须要和组织现有的系统(如 Web 服务或者数据库)集成时,就可能发生这种情况。在这种情况下,将需要从已经被接受的子 Channel 中引导一个客户端 Channel。
一个更好的解决方案是:通过将已被接受的子 Channel 的 EventLoop 传递给 Bootstrap的 group()方法来共享该 EventLoop。因为分配给 EventLoop 的所有 Channel 都使用同一个线程,所以这避免了额外的线程创建,以及前面所提到的相关的上下文切换。
这样就能单线程操作两个channel 这样就能避免子Channel与客户端Channel之间交换数据时不可避免的上下文切换
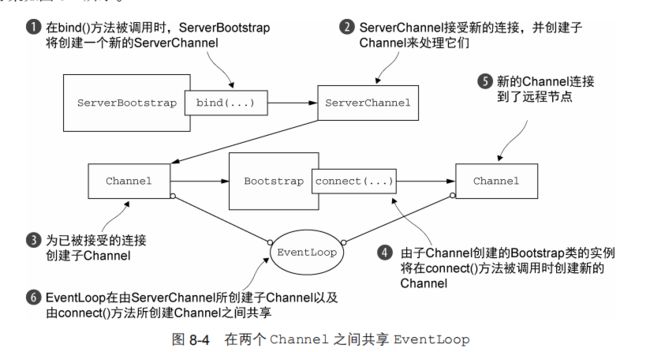
代码实现如下:bootstrap.group(ctx.channel().eventloop())实现eventloop的共享



Netty 应用程序的一个一般准则:尽可能地重用 EventLoop,以减少线程创建所带来的开销。
10.5 在引导过程中添加多个ChannelHandler
在所有我们展示过的代码示例中,我们都在引导的过程中调用了 handler()或者 childHandler()方法来添加单个的 ChannelHandler。这对于简单的应用程序来说可能已经足够了,但是它不能满足更加复杂的需求。例如,一个必须要支持多种协议的应用程序将会有很多的ChannelHandler,而不会是一个庞大而又笨重的类。
正是针对于这个用例,Netty 提供了一个特殊的 ChannelInboundHandlerAdapter 子类:
public abstract class ChannelInitializer<C extends Channel> extends ChannelInboundHandlerAdapter
它定义了下面的方法:
protected abstract void initChannel(C ch) throws Exception;
这个方法提供了一种将多个 ChannelHandler 添加到一个 ChannelPipeline 中的简便方法。你只需要简单地向 Bootstrap 或 ServerBootstrap 的实例提供你的 ChannelInitializer 实现即可,并且一旦 Channel 被注册到了它的 EventLoop 之后,就会调用你的initChannel()版本。在该方法返回之后,ChannelInitializer 的实例将会从 ChannelPipeline 中移除它自己。
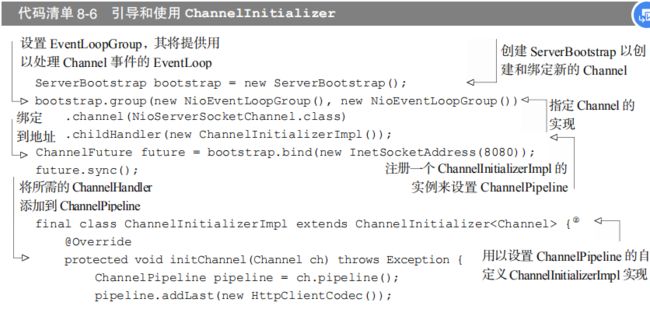

如果你的应用程序使用了多个 ChannelHandler,请定义你自己的 ChannelInitializer实现来将它们安装到 ChannelPipeline 中。
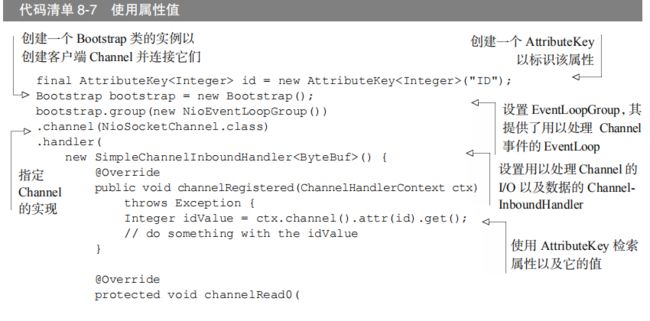
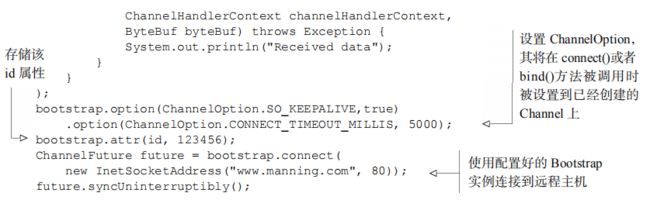
10.6 使用netty的ChannelOption属性
在每个 Channel 创建时都手动配置它可能会变得相当乏味。幸运的是,你不必这样做。相反,你可以使用 option()方法来将ChannelOption 应用到引导。你所提供的值将会被自动应用到引导所创建的所有 Channel。可用的 ChannelOption 包括了底层连接的详细信息,如keep-alive 或者超时属性以及缓冲区设置。
Netty 应用程序通常与组织的专有软件集成在一起,而像 Channel 这样的组件可能甚至会在正常的 Netty 生命周期之外被使用。
在某些常用的属性和数据不可用时,Netty 提供了AttributeMap 抽象(一个由 Channel 和引导类提供的集合)以AttributeKey(一个用于插入和获取属性值的泛型类)。使用这些工具,便可以安全地将任何类型的数据项与客户端和服务器 Channel(包含 ServerChannel 的子 Channel)相关联了。
10.7 引导DatagramChannel
前面的引导代码示例使用的都是基于 TCP 协议的 SocketChannel,但是 Bootstrap 类也可以被用于无连接的协议。为此,Netty 提供了各种 DatagramChannel 的实现。唯一区别就是,不再调用 connect()方法,而是只调用 bind()方法。
10.8 关闭
引导使你的应用程序启动并且运行起来,但是迟早你都需要优雅地将它关闭。当然,你也可以让 JVM 在退出时处理好一切,但是这不符合优雅的定义,优雅是指干净地释放资源。关闭 Netty应用程序并没有太多的魔法,但是还是有些事情需要记在心上。
最重要的是,你需要关闭 EventLoopGroup,它将处理任何挂起的事件和任务,并且随后释放所有活动的线程。这就是调用 EventLoopGroup.shutdownGracefully()方法的作用。这个方法调用将会返回一个 Future,这个 Future 将在关闭完成时接收到通知。需要注意的是,shutdownGracefully()方法也是一个异步的操作,所以你需要阻塞等待直到它完成,或者向所返回的 Future 注册一个监听器以在关闭完成时获得通知
(shutdownGracefully()方法将释放所有的资源,并且关闭所有的当前正在使用中的 Channel)

11 单元测试
虽然单元测试没有统一的定义,但是大多数的从业者都有基本的共识。其基本思想是,以尽可能小的区块测试你的代码,并且尽可能地和其他的代码模块以及运行时的依赖(如数据库和网络)相隔离。如果你的应用程序能通过测试验证每个单元本身都能够正常地工作,那么在出了问题时将可以更加容易地找出根本原因。
EmbeddedChannel,它是 Netty 专门为改进针对 ChannelHandler 的单元测试而提供的。
11.1 EmbeddedChannel概述
Netty 提供了它所谓的 Embedded 传输,用于测试ChannelHandler。这个传输是一种特殊的Channel 实现—EmbeddedChannel—的功能,这个实现提供了通过ChannelPipeline传播事件的简便方法。
这个想法是直截了当的:**将入站数据或者出站数据写入到 EmbeddedChannel 中,然后检查是否有任何东西到达了 ChannelPipeline 的尾端。**以这种方式,你便可以确定消息是否已经被编码或者被解码过了,以及是否触发了任何的 ChannelHandler 动作。

入站数据由 ChannelInboundHandler 处理,代表从远程节点(即服务器端)读取的数据。出站数据由ChannelOutboundHandler 处理,代表将要写到远程节点的数据。根据你要测试的 ChannelHandler,你将使用Inbound()或者Outbound()方法对,或者兼而有之。
下图展示了使用 EmbeddedChannel 的方法,数据是如何流经 ChannelPipeline 的。你可以使用 writeOutbound()方法将消息写到 Channel 中,并通过 ChannelPipeline 沿着出站的方向传递。随后,你可以使用 readOutbound()方法来读取已被处理过的消息,以确定结果是否和预期一样。类似地,对于入站数据,你需要使用writeInbound()和readInbound()方法。
在每种情况下,消息都将会传递过 ChannelPipeline,并且被相关的 ChannelInboundHandler 或者 ChannelOutboundHandler 处理。如果消息没有被消费,那么你可以使用readInbound()或者readOutbound()方法来在处理过了这些消息之后,酌情把它们从Channel中读出来

11.2 使用EmbeddedChannel测试ChannelHandler
11.2.1 测试入站消息
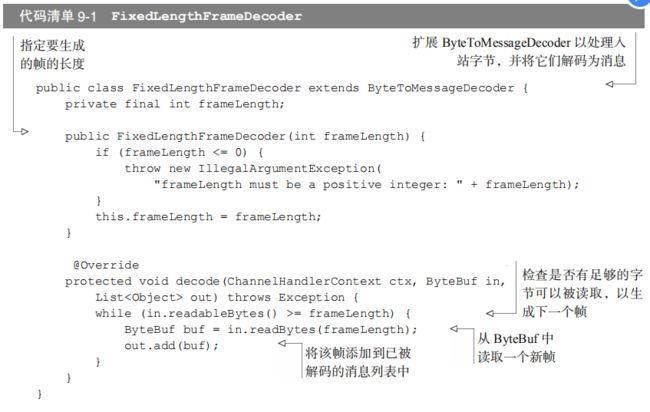
下图展示了一个简单的 ByteToMessageDecoder 实现。给定足够的数据,这个实现将产生固定大小的帧。如果没有足够的数据可供读取,它将等待下一个数据块的到来,并将再次检查是否能够产生一个新的帧。

这个特定的解码器将产生固定为 3 字节大小的帧。因此,它可能会需要多个事件来提供足够的字节数以产生一个帧。
使用 EmbeddedChannel 对于前面代码进行单元测试:
public class FixedLengthFrameDecoderTest {
@Test
public void testFramesDecoded() {
ByteBuf buf = Unpooled.buffer();
for (int i = 0; i < 9; i++) {
buf.writeByte(i);
}
ByteBuf input = buf.duplicate();
//因为FixedLengthFrameDecoder继承了BytoToMessageDecoder而这个Decoder又继承了InboundHandler是个Handler 可以直接注册到channel中。 EmbeddedChannel有个构造函数参数为(Handler)的 从而可以直接再后面channel.write/read了
EmbeddedChannel channel = new EmbeddedChannel(new FixedLengthFrameDecoder(3));
// write bytes
assertTrue(channel.writeInbound(input.retain()));
assertTrue(channel.finish());
// read messages
ByteBuf read = (ByteBuf) channel.readInbound();
assertEquals(buf.readSlice(3), read);
read.release();
read = (ByteBuf) channel.readInbound();
assertEquals(buf.readSlice(3), read);
read.release();
read = (ByteBuf) channel.readInbound();
assertEquals(buf.readSlice(3), read);
read.release();
assertNull(channel.readInbound());
buf.release();
}
@Test
public void testFramesDecoded2() {
ByteBuf buf = Unpooled.buffer();
for (int i = 0; i < 9; i++) {
buf.writeByte(i);
}
ByteBuf input = buf.duplicate();
EmbeddedChannel channel = new EmbeddedChannel(new FixedLengthFrameDecoder(3));
//先传入2个字节 发现解码器无法添加数据到输出out中(理解为channel中)于是assertFalse..... 同时readbytes方法将readindex坐标加2 紧接着在2后又读入7个字节 总共还是write了9个字节 此时decoder将其3个3个分成不同帧 传入channel中。还有需要注意的是 writeInbound函数返回true的前提是readinbound能返回true 即能读到符合条件的数据 本场景中是至少write3个字符
assertFalse(channel.writeInbound(input.readBytes(2)));
assertTrue(channel.writeInbound(input.readBytes(7)));
assertTrue(channel.finish());
ByteBuf read = (ByteBuf) channel.readInbound();
assertEquals(buf.readSlice(3), read);
read.release();
read = (ByteBuf) channel.readInbound();
assertEquals(buf.readSlice(3), read);
read.release();
read = (ByteBuf) channel.readInbound();
assertEquals(buf.readSlice(3), read);
read.release();
assertNull(channel.readInbound());
buf.release();
}
}
该 testFramesDecoded()方法验证了:一个包含 9 个可读字节的 ByteBuf 被解码为 3 个 ByteBuf,每个都包含了 3 字节。需要注意的是,仅通过一次对 writeInbound()方法的调用,ByteBuf 是如何被填充了 9 个可读字节的。在此之后,通过执行 finish()方法,将EmbeddedChannel 标记为了已完成状态。最后,通过调用readInbound()方法,从 EmbeddedChannel 中正好读取了 3 个帧和一个 null。testFramesDecoded2()方法也是类似的,只有一处不同:入站 ByteBuf 是通过两个步骤写入的。当writeInbound(input.readBytes(2))被调用时,返回了 false。为什么呢?
正如同表中所描述的,如果对 readInbound()的后续调用将会返回数据,那么 writeInbound()方法将会返回 true。但是只有当有 3 个或者更多的字节可供读取时,FixedLengthFrameDecoder 才会产生输出。该测试剩下的部分和 testFramesDecoded()是相同的。
11.2.2 测试出站消息
编码器是一种将一种消息格式转换为另一种的组件。
将在下一章中非常详细地学习编码器和解码器,所以现在我们只需要简单地提及我们正在测试的处理器—AbsIntegerEncoder,它是 Netty 的MessageToMessageEncoder 的一个特殊化的实现,用于将负值整数转换为绝对值。
- 持有 AbsIntegerEncoder 的 EmbeddedChannel 将会以 4 字节的负整数的形式写出站数据;
- 编码器将从传入的 ByteBuf 中读取每个负整数,并将会调用 Math.abs()方法来获取其绝对值;
- 编码器将会把每个负整数的绝对值写到 ChannelPipeline 中。

public class AbsIntegerEncoder extends
MessageToMessageEncoder<ByteBuf> {
@Override
protected void encode(ChannelHandlerContext channelHandlerContext,ByteBuf in, List<Object> out) throws Exception {
while (in.readableBytes() >= 4) {
int value = Math.abs(in.readInt());
out.add(value);
} } }
public class AbsIntegerEncoderTest {
@Test
public void testEncoded() {
ByteBuf buf = Unpooled.buffer();
for (int i = 1; i < 10; i++) {
buf.writeInt(i * -1);
}
EmbeddedChannel channel = new EmbeddedChannel(
new AbsIntegerEncoder());
assertTrue(channel.writeOutbound(buf));
assertTrue(channel.finish());
// read bytes
for (int i = 1; i < 10; i++) {
assertEquals(i, channel.readOutbound());
}
assertNull(channel.readOutbound());
注意 出站时编码器Encoder 写数据时writeOutbound,入站时解码器Decoder writeInbound。
11.2.3 测试异常处理
应用程序通常需要执行比转换数据更加复杂的任务。例如,你可能需要处理格式不正确的输入或者过量的数据。在下一个示例中,如果所读取的字节数超出了某个特定的限制,我们将会抛出一个TooLongFrameException。这是一种经常用来防范资源被耗尽的方法。
在图中,最大的帧大小已经被设置为 3 字节。如果一个帧的大小超出了该限制,那么程序将会丢弃它的字节,并抛出一个TooLongFrameException。位于 ChannelPipeline 中的其他ChannelHandler 可以选择在 exceptionCaught()方法中处理该异常或者忽略它。

public class FrameChunkDecoder extends ByteToMessageDecoder {
private final int maxFrameSize;
public FrameChunkDecoder(int maxFrameSize) {
this.maxFrameSize = maxFrameSize;
}
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in,
List<Object> out) throws Exception {
int readableBytes = in.readableBytes();
if (readableBytes > maxFrameSize) {
// discard the bytes
in.clear();
throw new TooLongFrameException();
}
ByteBuf buf = in.readBytes(readableBytes);
out.add(buf);
}
}
public class FrameChunkDecoderTest {
@Test
public void testFramesDecoded() {
ByteBuf buf = Unpooled.buffer();
for (int i = 0; i < 9; i++) {
buf.writeByte(i);
}
ByteBuf input = buf.duplicate();
EmbeddedChannel channel = new EmbeddedChannel(
new FrameChunkDecoder(3));
assertTrue(channel.writeInbound(input.readBytes(2)));
try {
channel.writeInbound(input.readBytes(4));
//如果上面没有抛出异常,那么就会到达这个断言,并且测试失败
Assert.fail();
} catch (TooLongFrameException e) {
// expected exception
}
assertTrue(channel.writeInbound(input.readBytes(3)));
assertTrue(channel.finish());
// Read frames
ByteBuf read = (ByteBuf) channel.readInbound();
assertEquals(buf.readSlice(2), read);
read.release();
read = (ByteBuf) channel.readInbound();
assertEquals(buf.skipBytes(4).readSlice(3), read);
read.release();
buf.release();
}
}
它有一个有趣的转折点,即对TooLongFrameException的处理。这里使用的try/catch块是EmbeddedChannel的一个特殊功能。如果其中一个write*方法产生了一个受检查的Exception,那么它将会被包装在一个RuntimeException中并抛出.这使得可以容易地测试出一个Exception是否在处理数据的过程中已经被处理了。
PART 2 编解码器框架
12 编解码器框架
网络只将数据看作是原始的字节序列。然而,我们的应用程序则会把这些字节组织成有意义的信息。
你可能需要处理标准的格式或者协议(如 FTP 或 Telnet)、实现一种由第三方定义的专有二进制协议,或者扩展一种由自己的组织创建的遗留的消息格式。
将应用程序的数据转换为网络格式,以及将网络格式转换为应用程序的数据的组件分别叫作编码器(出站)和解码器(入站),同时具有这两种功能的单一组件叫作编解码器。
12.1 解码器
- 将字节解码为消息
ByteToMessageDecoder、ReplayingDecoder; - 将一种消息类型解码为MessageToMessageDecoder`。
每当需要为 ChannelPipeline 中的下一个 ChannelInboundHandler 转换入站数据时会用到。此外,得益于ChannelPipeline 的设计,可以将多个解码器链接在一起,以实现任意复杂的转换逻辑,这也是 Netty 是如何支持代码的模块化以及复用的一个很好的例子。
12.1.1 抽象类 ByteToMessageDecoder
将字节解码为消息(或者另一个字节序列)是一项如此常见的任务,由于你不可能知道远程节点是否会一次性地发送一个完整的消息,所以这个类会对入站数据进行缓冲,直到它准备好处理。
| 方法 | 描述 |
|---|---|
| decode(ChannelHandlerContext ctx,ByteBuf in,List out) | 这是你必须实现的唯一抽象方法。decode()方法被调用时将会传入一个包含了传入数据的 ByteBuf,以及一个用来添加解码消息的 List。对这个方法的调用将会重复进行,直到确定没有新的元素被添加到该 List,或者该 ByteBuf 中没有更多可读取的字节时为止。然后,如果该 List 不为空,那么它的内容将会被传递给ChannelPipeline 中的下一个 ChannelInboundHandler |
| decodeLast(ChannelHandlerContext ctx,ByteBuf in,List out) | Netty提供的这个默认实现只是简单地调用了decode()方法。**当Channel的状态变为非活动时,这个方法将会被调用一次。**可以重写该方法以提供特殊的处理 |
假设你接收了一个包含简单 int 的字节流,每个 int都需要被单独处理。在这种情况下,你需要从入站 ByteBuf 中读取每个 int,并将它传递给ChannelPipeline 中的下一个 ChannelInboundHandler。为了解码这个字节流,你要扩展ByteToMessageDecoder 类。(需要注意的是,原子类型的 int 在被添加到 List 中时,会被自动装箱为 Integer。)
每次从入站 ByteBuf 中读取 4 字节,将其解码为一个 int,然后将它添加到一个 List 中。当没有更多的元素可以被添加到该 List 中时,它的内容将会被发送给下一个 ChannelInboundHandler。
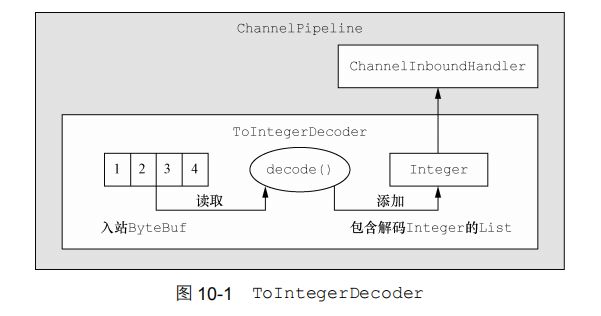
public class ToIntegerDecoder extends ByteToMessageDecoder {
@Override
public void decode(ChannelHandlerContext ctx, ByteBuf in,
List<Object> out) throws Exception {
if (in.readableBytes() >= 4) {
out.add(in.readInt());
}
}
}
虽然 ByteToMessageDecoder 使得可以很简单地实现这种模式,但是你可能会发现,在调用 readInt()方法前不得不验证所输入的 ByteBuf 是否具有足够的数据有点繁琐。在下一节中,我们将讨论 ReplayingDecoder,它是一个特殊的解码器,以少量的开销消除了这个步骤。
编解码器中的引用计数
正如我们在前面所提到的,引用计数需要特别的注意。对于编码器和解码器来说,其过程也是相当的简单:一旦消息被编码或者解码,它就会被 ReferenceCountUtil.release(message)调用自动释放。如果你需要保留引用以便稍后使用,那么你可以调用 ReferenceCountUtil.retain(message)方法。这将会增加该引用计数,从而防止该消息被释放。
12.2.2 抽象类ReplayingDecoder
ReplayingDecoder扩展了ByteToMessageDecoder类,使得我们不必调用 readableBytes()方法。它通过使用一个自定义的ByteBuf实现,ReplayingDecoderByteBuf,包装传入的ByteBuf实现了这一点,其将在内部执行该调用readableBytes()方法。这个类的完整声明是:
public abstract class ReplayingDecoder
extends ByteToMessageDecoder
类型参数 S 指定了用于状态管理的类型,其中 Void 代表不需要状态管理。
public class ToIntegerDecoder2 extends ReplayingDecoder<Void> {
@Override
public void decode(ChannelHandlerContext ctx, ByteBuf in,List<Object> out) throws Exception {
//不需要在in.readableBytes()>=4 了
out.add(in.readInt());
} }
和之前一样,从ByteBuf中提取的int将会被添加到List中。如果没有足够的字节可用,这个readInt()方法的实现将会抛出一个Error(这里实际上抛出的是一个 Signal,详见 io.netty.util.Signal 类。),其将在基类中被捕获并处理。当有更多的数据可供读取时,该decode()方法将会被再次调用。
请注意 ReplayingDecoderByteBuf 的下面这些方面:
- 并不是所有的 ByteBuf 操作都被支持,如果调用了一个不被支持的方法,将会抛出一个 UnsupportedOperationException;
- ReplayingDecoder 稍慢于 ByteToMessageDecoder。
如果使用 ByteToMessageDecoder 不会引入太多的复杂性,那么请使用它;否则,请使用 ReplayingDecoder。

12.1.2 抽象类MessageToMessageDecoder
使用下面的抽象基类在两个消息格式之间进行转换
public abstract class MessageToMessageDecoder extends ChannelInboundHandlerAdapter
类型参数 I 指定了 decode()方法的输入参数 msg 的类型,它是你必须实现的唯一方法。

在这个示例中,我们将编写一个 IntegerToStringDecoder 解码器来扩展 MessageToMessageDecoder。它的 decode()方法会把 Integer 参数转换为它的 String表示,并将拥有下列签名:
public void decode( ChannelHandlerContext ctx,Integer msg, List out ) throws Exception
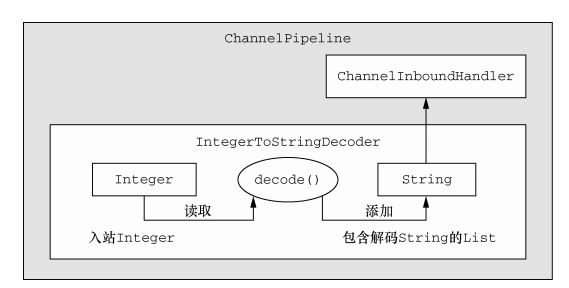
public class IntegerToStringDecoder extends
MessageToMessageDecoder<Integer> {
@Override
public void decode(ChannelHandlerContext ctx, Integer msg,List<Object> out) throws Exception {
out.add(String.valueOf(msg));
}
}
HttpObjectAggregator有关更加复杂的例子,请研究 io.netty.handler.codec.http.HttpObjectAggregator 类,它扩展了 MessageToMessageDecoder。
12.1.3 TooLongFrameException 类
由于 Netty 是一个异步框架,所以需要在字节可以解码之前在内存中缓冲它们。因此,不能让解码器缓冲大量的数据以至于耗尽可用的内存。为了解除这个常见的顾虑,Netty 提供TooLongFrameException 类,其将由解码器在帧超出指定的大小限制时抛出。
为了避免这种情况,你可以设置一个最大字节数的阈值,如果超出该阈值,则会导致抛出一 个 TooLongFrameException(随后会被 ChannelHandler.exceptionCaught()方法捕获)。然后,如何处理该异常则完全取决于该解码器的用户。某些协议(如 HTTP)可能允许你返回一个特殊的响应。而在其他的情况下,唯一的选择可能就是关闭对应的连接。
如果你正在使用一个可变帧大小的协议,那么这种保护措施将是尤为重要的。
public class SafeByteToMessageDecoder extends ByteToMessageDecoder {
private static final int MAX_FRAME_SIZE = 1024;
@Override
public void decode(ChannelHandlerContext ctx, ByteBuf in,List<Object> out) throws Exception {
int readable = in.readableBytes();
if (readable > MAX_FRAME_SIZE) {
in.skipBytes(readable);
throw new TooLongFrameException("Frame too big!");
}
// do something
...
}
}
12.2 编码器
将消息编码为字节;
将消息编码为消息;
12.2.1 抽象类MessageToByteEncoder
前面我们看到了如何使用 ByteToMessageDecoder 来将字节转换为消息。现在我们将使用 MessageToByteEncoder 来做逆向的事情。
| 方法 | 描述 |
|---|---|
| encode(ChannelHandlerContext ctx,I msg,ByteBuf out) | encode()方法是你需要实现的唯一抽象方法。它被调用时将会传入要被该类编码为 ByteBuf 的(类型为 I 的)出站消息。该 ByteBuf 随后将会被转发给 ChannelPipeline中的下个ChannelOutboundHandler |
你可能已经注意到了,这个类只有一个方法,而解码器有两个。原因是解码器通常需要在Channel 关闭之后产生最后一个消息(因此也就有了 decodeLast()方法)。这显然不适用于编码器的场景——在连接被关闭之后仍然产生一个消息是毫无意义的。
ShortToByteEncoder,其接受一个 Short 类型的实例作为消息,将它编码为 Short 的原子类型值,并将它写入 ByteBuf 中,其将随后被转发给 ChannelPipeline 中的下一个 ChannelOutboundHandler。每个传出的 Short 值都将会占用 ByteBuf 中的 2 字节。
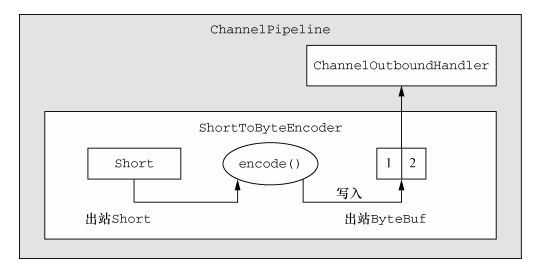
public class ShortToByteEncoder extends MessageToByteEncoder<Short> {
@Override
public void encode(ChannelHandlerContext ctx, Short msg, ByteBuf out) throws Exception {
out.writeShort(msg);
} }
Netty 提供了一些专门化的 MessageToByteEncoder,你可以基于它们实现自己的编码器。WebSocket08FrameEncoder 类提供了一个很好的实例。你可以在 io.netty.handler.codec.http.websocketx 包中找到它。
12.2.2 抽象类MessageToMessageEncoder
你已经看到了如何将入站数据从一种消息格式解码为另一种。为了完善这幅图,我们将展示对于出站数据将如何从一种消息编码为另一种。MessageToMessageEncoder 类的 encode()方法提供了这种能力,
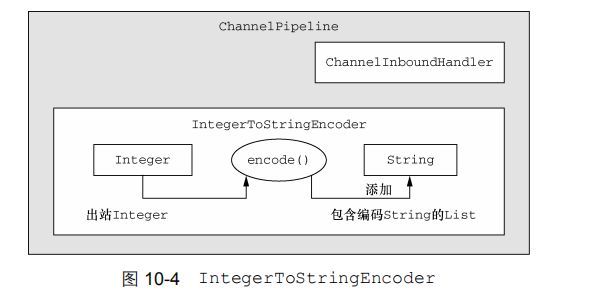

public class IntegerToStringEncoder
extends MessageToMessageEncoder<Integer> {
@Override
public void encode(ChannelHandlerContext ctx, Integer msg,List<Object> out) throws Exception {
out.add(String.valueOf(msg));
} }
12.3 抽象的编解码器类
虽然我们一直将解码器和编码器作为单独的实体讨论,但是你有时将会发现在同一个类中管理入站和出站数据和消息的转换是很有用的。Netty 的抽象编解码器类正好用于这个目的,因为它们每个都将捆绑一个解码器/编码器对,以处理我们一直在学习的这两种类型的操作。正如同你可能已经猜想到的,这些类同时实现了 ChannelInboundHandler 和 ChannelOutboundHandler 接口。
因为通过尽可能地将这两种功能分开,最大化了代码的可重用性和可扩展性,这是 Netty 设计的一个基本原则。
12.3.1 抽象类 ByteToMessageCodec
让我们来研究这样的一个场景:我们需要将字节解码为某种形式的消息,可能是 POJO,随后再次对它进行编码。ByteToMessageCodec 将为我们处理好这一切,因为它结合了ByteToMessageDecoder 以及它的逆向——MessageToByteEncoder。
任何的请求/响应协议都可以作为使用ByteToMessageCodec的理想选择。例如,在某个SMTP的实现中,编解码器将读取传入字节,并将它们解码为一个自定义的消息类型,如SmtpRequest。而在接收端,当一个响应被创建时,将会产生一个SmtpResponse,其将被编码回字节以便进行传输。

12.3.2 抽象类 MessageToMessageCodec
MessageToMessageCodec 是一个参数化的类,定义如下:
public abstract class MessageToMessageCodec

decode()方法是将INBOUND_IN类型的消息转换为OUTBOUND_IN类型的消息,而encode()方法则进行它的逆向操作。将INBOUND_IN类型的消息看作是通过网络发送的类型,而将OUTBOUND_IN类型的消息看作是应用程序所处理的类型

我们的WebSocketConvertHandler在参数化MessageToMessageCodec时将使用INBOUND_IN类型的WebSocketFrame,以及OUTBOUND_IN类型的MyWebSocketFrame,后者是WebSocketConvertHandler本身的一个静态嵌套类。
public class WebSocketConvertHandler extends
MessageToMessageCodec<WebSocketFrame,
WebSocketConvertHandler.MyWebSocketFrame> {
@Override
protected void encode(ChannelHandlerContext ctx,
WebSocketConvertHandler.MyWebSocketFrame msg,List<Object> out) throws Exception {
ByteBuf payload = msg.getData().duplicate().retain();
//实例化一个指定子类型的WebSocketFrame
switch (msg.getType()) {
case BINARY:
out.add(new BinaryWebSocketFrame(payload));
break;
case TEXT:
out.add(new TextWebSocketFrame(payload));
break;
case CLOSE:
out.add(new CloseWebSocketFrame(true, 0, payload));
break;
case CONTINUATION:
out.add(new ContinuationWebSocketFrame(payload));
break;
case PONG:
out.add(new PongWebSocketFrame(payload));
break;
case PING:
out.add(new PingWebSocketFrame(payload));
break;
default:
throw new IllegalStateException(
"Unsupported websocket msg " + msg);
}
}
@Override
protected void decode(ChannelHandlerContext ctx, WebSocketFrame msg,
List<Object> out) throws Exception {
ByteBuf payload = msg.content().duplicate().retain();
if (msg instanceof BinaryWebSocketFrame) {
out.add(new MyWebSocketFrame(
MyWebSocketFrame.FrameType.BINARY, payload));
} else
if (msg instanceof CloseWebSocketFrame) {
out.add(new MyWebSocketFrame (
MyWebSocketFrame.FrameType.CLOSE, payload));
} else
if (msg instanceof PingWebSocketFrame) {
out.add(new MyWebSocketFrame (
MyWebSocketFrame.FrameType.PING, payload));
} else
if (msg instanceof PongWebSocketFrame) {
out.add(new MyWebSocketFrame (
MyWebSocketFrame.FrameType.PONG, payload));
} else
if (msg instanceof TextWebSocketFrame) {
out.add(new MyWebSocketFrame (
MyWebSocketFrame.FrameType.TEXT, payload));
} else
if (msg instanceof ContinuationWebSocketFrame) {
out.add(new MyWebSocketFrame (
MyWebSocketFrame.FrameType.CONTINUATION, payload));
} else
{
throw new IllegalStateException(
"Unsupported websocket msg " + msg);
} }
public static final class MyWebSocketFrame {
public enum FrameType {
BINARY,
CLOSE,
PING,
PONG,
TEXT,
CONTINUATION
}
private final FrameType type;
private final ByteBuf data;
public MyWebSocketFrame(FrameType type, ByteBuf data) {
this.type = type;
this.data = data;
}
public FrameType getType() {
return type;
}
public ByteBuf getData() {
return data;
} } }
12.3.3 CombinedChannelDuplexHandler类
结合一个解码器和编码器可能会对可重用性造成影响。但是,有一种方法既能够避免这种惩罚,又不会牺牲将一个解码器和一个编码器作为一个单独的单元部署所带来的便利性。CombinedChannelDuplexHandler 提供了这个解决方案,其声明为:
public class CombinedChannelDuplexHandler
这个类充当了 ChannelInboundHandler 和ChannelOutboundHandler(该类的类型参数 I 和 O)的容器。通过提供分别继承了解码器类和编码器类的类型,我们可以实现一个编解码器,而又不必直接扩展抽象的编解码器类。
解码器:

编码器:

CombinedChannel编解码器:直接作为容器结合二者。

13 预置的ChannelHandler和编解码器
Netty 为许多通用协议提供了编解码器和处理器,几乎可以开箱即用,这减少了你在那些相当繁琐的事务上本来会花费的时间与精力。
其中包括 Netty 对于 SSL/TLS 和 WebSocket 的支持,以及如何简单地通过数据压缩来压榨HTTP,以获取更好的性能。
13.1 通过 SSL/TLS 保护 Netty 应用程序
SSL/TLS这样的安全协议,它们层叠在其他协议之上,用以实现数据安全。我们在访问安全网站时遇到过这些协议,但是它们也可用于其他不是基于HTTP的应用程序,如安全SMTP(SMTPS)邮件服务器甚至是关系型数据库系统。
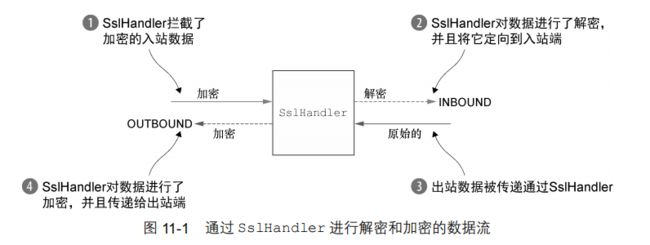
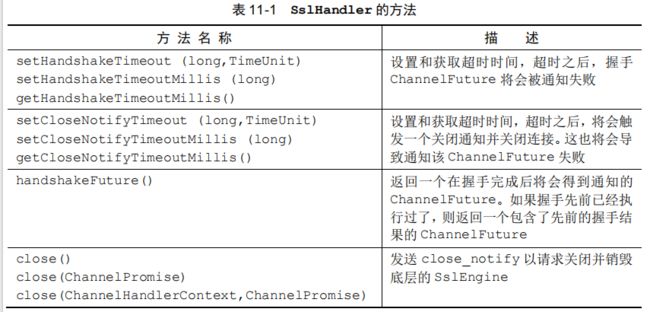
为了支持 SSL/TLS,Java 提供了 javax.net.ssl 包,它的 SSLContext 和 SSLEngine类使得实现解密和加密相当简单直接。Netty 通过一个名为 SslHandler 的 ChannelHandler实现利用了这个 API,其中 SslHandler 在内部使用 SSLEngine 来完成实际的工作。

以下代码ChannelInitializer来将SslHandler添加到ChannelPipeline 中。回想一下,ChannelInitializer 用于在 Channel 注册好时设置 ChannelPipeline。
public class SslChannelInitializer extends ChannelInitializer<Channel>{
private final SslContext context;
private final boolean startTls;
//传入要使用的SslContext 第二个参数如果设置为true 第一个写入的消息不会被加密(客户端应设置为true)
public SslChannelInitializer(SslContext context,
boolean startTls) {
this.context = context;
this.startTls = startTls;
}
@Override
protected void initChannel(Channel ch) throws Exception {
//对于每个SSLHandler实例,都使用Channel的ByteBufAllocator从SslContext获取一个新的SSLEngine
SSLEngine engine = context.newEngine(ch.alloc());
//将SSLhandler作为第一个ChannelHandler添加到ChannelPipeline中。(注意是addFirst方法)
ch.pipeline().addFirst("ssl",new SslHandler(engine, startTls));
} }
在大多数情况下,SslHandler 将是 ChannelPipeline 中的第一个 ChannelHandler。这确保了只有在所有其他的 ChannelHandler 将它们的逻辑应用到数据之后,才会进行加密。
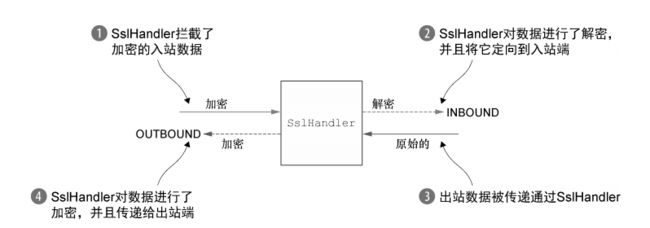
SslHandler 具有一些有用的方法,如表 11-1 所示。例如,在握手阶段,两个节点将相互验证并且商定一种加密方式。你可以通过配置 SslHandler 来修改它的行为,或者在 SSL/TLS握手一旦完成之后提供通知,握手阶段完成之后,所有的数据都将会被加密。SSL/TLS 握手将会被自动执行。
13.2 构建基于 Netty 的 HTTP/HTTPS 应用程序
接下来,我们来看看 Netty 提供的 ChannelHandler,你可以用它来处理 HTTP 和 HTTPS协议,而不必编写自定义的编解码器。
13.2.1 HTTP 解码器、编码器和编解码器
HTTP 是基于请求/响应模式的:客户端向服务器发送一个 HTTP 请求,然后服务器将会返回一个 HTTP 响应。
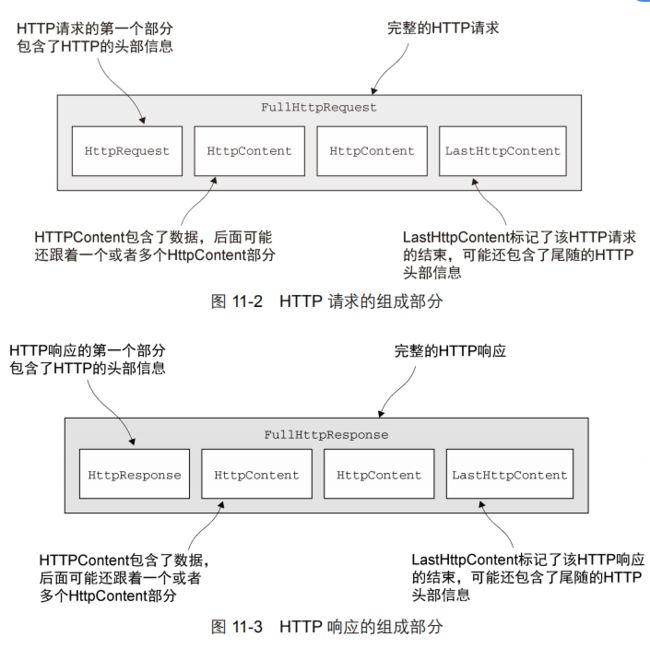
一个 HTTP 请求/响应可能由多个数据部分组成,并且它总是以一个 LastHttpContent 部分作为结束。FullHttpRequest 和FullHttpResponse 消息是特殊的子类型,分别代表了完整的请求和响应。所有类型的 HTTP 消息(FullHttpRequest、LastHttpContent 以及下面代码中展示的那些)都实现了 HttpObject 接口。
处理和生成这些消息的 HTTP 解码器和编码器:
| 名称 | 描述 |
|---|---|
| HttpRequestEncoder | 将HttpRequest、HttpContent 和 LastHttpContent 消息编码为字节 |
| HttpResponseEncoder | 将HttpResponse、HttpContent 和LastHttpContent 消息编码为字节 |
| HttpRequestDecoder | 将字节解码为HttpRequest、HttpContent 和 LastHttpContent 消息 |
| HttpResponseDecoder | 将字节解码为HttpResponse、HttpContent 和LastHttpContent 消息 |
HttpPipelineInitializer 类展示了将 HTTP 支持添加到你的应用程序是多么简单—几乎只需要将正确的 ChannelHandler 添加到ChannelPipeline 中。
添加HTTP支持:
public class HttpPipelineInitializer extends ChannelInitializer<Channel> {
private final boolean client;
public HttpPipelineInitializer(boolean client) {
this.client = client;
}
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
if (client) {
//若是客户端 则需要添加 向服务器发送请求的出站encoder和接受服务器发来响应的decoder
pipeline.addLast("decoder", new HttpResponseDecoder());
pipeline.addLast("encoder", new HttpRequestEncoder());
} else
{
//若是服务器则相反。
pipeline.addLast("decoder", new HttpRequestDecoder());
pipeline.addLast("encoder", new HttpResponseEncoder());
} } }
13.2.2 聚合HTTP消息
在 ChannelInitializer 将 ChannelHandler 安装到 ChannelPipeline 中之后,你便可以处理不同类型的 HttpObject 消息了。但是由于 HTTP 的请求和响应可能由许多部分组成,因此你需要聚合它们以形成完整的消息。为了消除这项繁琐的任务,Netty 提供了一个聚合器,它可以将多个消息部分合并为 FullHttpRequest 或者 FullHttpResponse 消息。通过这样的方式,你将总是看到完整的消息内容。
由于消息分段需要被缓冲,直到可以转发一个完整的消息给下一个 ChannelInboundHandler,所以这个操作有轻微的开销。其所带来的好处便是你不必关心消息碎片了。(自己缓冲 等待到完整 不会产生碎片)
引入这种自动聚合机制只不过是向 ChannelPipeline 中添加另外一个 ChannelHandler罢了。
自动聚合HTTP的消息片段:
public class HttpAggregatorInitializer extends ChannelInitializer<Channel> {
private final boolean isClient;
public HttpAggregatorInitializer(boolean isClient) {
this.isClient = isClient;
}
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
if (isClient) {
//如果是客户端 则添加HttpClientCodec
pipeline.addLast("codec", new HttpClientCodec());
} else {
pipeline.addLast("codec", new HttpServerCodec());
}
//把最大的消息大小为512KB的HttpObjectAggregator添加到ChannelPipeline
pipeline.addLast("aggregator",
new HttpObjectAggregator(512 * 1024));
} }
13.2.3 HTTP压缩
当使用 HTTP 时,建议开启压缩功能以尽可能多地减小传输数据的大小。虽然压缩会带来一些 CPU 时钟周期上的开销,但是通常来说它都是一个好主意,特别是对于文本数据来说。
Netty 为压缩和解压缩提供了 ChannelHandler 实现,它们同时支持 gzip 和 deflate 编码。
自动压缩HTTP消息:
public class HttpCompressionInitializer extends ChannelInitializer<Channel> {
private final boolean isClient;
public HttpCompressionInitializer(boolean isClient) {
this.isClient = isClient;
}
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
if (isClient) {
pipeline.addLast("codec", new HttpClientCodec());
//为客户端添加解压器解压来自服务器端的压缩内容
pipeline.addLast("decompressor",
new HttpContentDecompressor());
} else {
pipeline.addLast("codec", new HttpServerCodec());
//相反 压缩发送出去的内容(如果客户端支持的话)
pipeline.addLast("compressor",
new HttpContentCompressor());
} } }
13.2.4 使用HTTPS
启用 HTTPS 只需要将 SslHandler 添加到 ChannelPipeline 的ChannelHandler 组合中。
public class HttpsCodecInitializer extends ChannelInitializer<Channel> {
private final SslContext context;
private final boolean isClient;
public HttpsCodecInitializer(SslContext context, boolean isClient) {
this.context = context;
this.isClient = isClient;
}
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
SSLEngine engine = context.newEngine(ch.alloc());
//将SSLHandler添加到ChannelPipeline中以使用HTTPS
pipeline.addFirst("ssl", new SslHandler(engine));
if (isClient) {
pipeline.addLast("codec", new HttpClientCodec());
} else {
pipeline.addLast("codec", new HttpServerCodec());
} } }
Netty 的架构方式是如何将代码重用变为杠杆作用的。只需要简单地将一个 ChannelHandler 添加到 ChannelPipeline 中,便可以提供一项新功能,甚至像加密这样重要的功能都能提供。
13.2.5 WebSocket
Netty 针对基于 HTTP 的应用程序的广泛工具包中包括了对它的一些最先进的特性的支持。
WebSocket:一种在 2011 年被互联网工程任务组(IETF)标准化的协议。
WebSocket解决了一个长期存在的问题:既然底层的协议(HTTP)是一个请求/响应模式的交互序列,那么如何实时地发布信息呢?AJAX提供了一定程度上的改善,但是数据流仍然是由客户端所发送的请求驱动的。
WebSocket提供了“在一个单个的TCP连接上提供双向的通信……结合WebSocket API……它为网页和远程服务器之间的双向通信提供了一种替代HTTP轮询的方案。”
WebSocket 在客户端和服务器之间提供了真正的双向数据交换。我们不会深入地描述太多的内部细节,但是我们还是应该提到,尽管最早的实现仅限于文本数据,但是现在已经不是问题了;WebSocket 现在可以用于传输任意类型的数据,很像普通的套接字。
要想向你的应用程序中添加对于 WebSocket 的支持,你需要将适当的客户端或者服务器WebSocket ChannelHandler 添加到ChannelPipeline 中。这个类将处理由 WebSocket 定义的称为帧的特殊消息类型。
WebSocketFrame 可以被归类为数据帧或者控制帧。

WebSocketFrame类型
| 名称 | 描述 |
|---|---|
| BinaryWebSocketFrame | 数据帧:二进制数据 |
| TextWebSocketFrame | 数据帧:文本数据 |
| ContinuationWebSocketFrame | 数据帧:属于上一个 BinaryWebSocketFrame 或者 TextWebSocketFrame 的文本的或者二进制数据 |
| CloseWebSocketFrame | 控制帧:一个 CLOSE 请求、关闭的状态码以及关闭的原因 |
| PingWebSocketFrame | 控制帧:请求一个 PongWebSocketFrame |
| PongWebSocketFrame | 控制帧:对 PingWebSocketFrame 请求的响应 |
因为Netty主要是一种服务器端的技术,所以在这里我们重点创建WebSocket服务器。展示了一个使用WebSocketServerProtocolHandler的简单示例,这个类处理协议升级握手,以及 3 种控制帧——Close、Ping和Pong。Text和Binary数据帧将会被传递给下一个(由你实现的)ChannelHandler进行处理。
在服务器端支持WebSocket,代码如下:
public class WebSocketServerInitializer extends ChannelInitializer<Channel>{
@Override
protected void initChannel(Channel ch) throws Exception {
ch.pipeline().addLast(
new HttpServerCodec(),
//为握手提供聚合的HTTPRequest
new HttpObjectAggregator(65536),
//如果被请求的端点是"/websocket"那么则处理这次握手
new WebSocketServerProtocolHandler("/websocket"),
//处理特殊类型为帧的数据
new TextFrameHandler(),
new BinaryFrameHandler(),
new ContinuationFrameHandler());
}
public static final class TextFrameHandler extends
SimpleChannelInboundHandler<TextWebSocketFrame> {
@Override
public void channelRead0(ChannelHandlerContext ctx,
TextWebSocketFrame msg) throws Exception {
// Handle text frame
} }
public static final class BinaryFrameHandler extends
SimpleChannelInboundHandler<BinaryWebSocketFrame> {
@Override
public void channelRead0(ChannelHandlerContext ctx,
BinaryWebSocketFrame msg) throws Exception {
// Handle binary frame
} }
public static final class ContinuationFrameHandler extends
SimpleChannelInboundHandler<ContinuationWebSocketFrame> {
@Override
public void channelRead0(ChannelHandlerContext ctx,
ContinuationWebSocketFrame msg) throws Exception {
// Handle continuation frame
} } }
保护 WebSocket
要想为 WebSocket 添加安全性,只需要将 SslHandler 作为第一个(addFirst) ChannelHandler 添加到ChannelPipeline 中。
13.3 空闲的连接和超时
到目前为止,我们的讨论都集中在 Netty 通过专门的编解码器和处理器对 HTTP 的变型HTTPS 和 WebSocket 的支持上。只要你有效地管理你的网络资源,这些技术就可以使得你的应用程序更加高效、易用和安全。
所以,让我们一起来探讨下首先需要关注的——连接管理吧。
检测空闲连接以及超时对于及时释放资源来说是至关重要的。由于这是一项常见的任务,Netty 特地为它提供了几个 ChannelHandler 实现。

注意结合上表和代码理解整个事件触发流程 且注意黄色部分。
以下代码展示了当使用通常的发送心跳消息到远程节点的方法时,如果在 60 秒之内没有接收或者发送任何的数据,我们将如何得到通知;如果没有响应,则连接会被关闭。
public class IdleStateHandlerInitializer extends ChannelInitializer<Channel>
{
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
//IdleStateHandler将在被触发时发送一个IdleStateEvent事件
pipeline.addLast(
new IdleStateHandler(0, 0, 60, TimeUnit.SECONDS));
//将一个HeartBeatHandler添加到ChannelPipeline中
pipeline.addLast(new HeartbeatHandler());
}
//实现userEventTrigered方法发送心跳信息
public static final class HeartbeatHandler
extends ChannelInboundHandlerAdapter {
//定义发送到远程节点的心跳信息。
private static final ByteBuf HEARTBEAT_SEQUENCE =
Unpooled.unreleasableBuffer(Unpooled.copiedBuffer(
"HEARTBEAT", CharsetUtil.ISO_8859_1));
@Override
public void userEventTriggered(ChannelHandlerContext ctx,
Object evt) throws Exception {
//发送心跳信息,并在发送失败时关闭该连接。
if (evt instanceof IdleStateEvent) {
ctx.writeAndFlush(HEARTBEAT_SEQUENCE.duplicate())
.addListener(
ChannelFutureListener.CLOSE_ON_FAILURE);
} else {
//如果不是IdleStateEvent时间 所以将它传递给下一个ChannelInboundHandler
super.userEventTriggered(ctx, evt);
} } } }
这个示例演示了如何使用 IdleStateHandler 来测试远程节点是否仍然还活着,并且在它失活时通过关闭连接来释放资源。
如果连接超过 60 秒没有接收或者发送任何的数据,那么 IdleStateHandler 将会使用一个IdleStateEvent 事件来调用 **fireUserEventTriggered()**方法(fire方法表示产生一个xx并传递给下一个Handler)。HeartbeatHandler 实现了 userEventTriggered()方法,如果这个方法检测到 IdleStateEvent 事件,它将会发送心跳消息,并且添加一个将在发送操作失败时关闭该连接的 ChannelFutureListener 。
13.4 解码基于分隔符的协议和基于长度的协议
在使用 Netty 的过程中,你将会遇到需要解码器的基于分隔符和帧长度的协议。
13.4.1 基于分隔符的协议
基于分隔符的(delimited)消息协议使用定义的字符来标记的消息或者消息段(通常被称为帧)的开头或者结尾。
下表列出的解码器都能帮助你定义可以提取由任意标记(token)序列分隔的帧的自定义解码器。
| 名称 | 描述 |
|---|---|
| DelimiterBasedFrameDecoder | 使用任何由用户提供的分隔符来提取帧的通用解码器 |
| LineBasedFrameDecoder | 提取由行尾符(\n 或者\r\n)分隔的帧的解码器。这个解码器比 DelimiterBasedFrameDecoder 更快 |
下图展示了当帧由行尾序列\r\n(回车符+换行符)分隔时是如何被处理的。
使用LineBasedFrameDecoder的代码如下:
public class LineBasedHandlerInitializer extends ChannelInitializer<Channel>
{
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
//这个LineBasedFrameDecoder将提取的帧转发给下一个ChannelInboundHandler 注意自己只是其分割帧的作用自己并不处理。真正的处理由下一个handler进行 放在bytebuf中。
pipeline.addLast(new LineBasedFrameDecoder(64 * 1024));
pipeline.addLast(new FrameHandler());
}
public static final class FrameHandler
extends SimpleChannelInboundHandler<ByteBuf> {
@Override
public void channelRead0(ChannelHandlerContext ctx,
ByteBuf msg) throws Exception {
// Do something with the data extracted from the frame
} } }
如果你正在使用除了行尾符之外的分隔符分隔的帧,那么你可以以类似的方式使用 DelimiterBasedFrameDecoder,只需要将特定的分隔符序列指定到其构造函数即可。
以上这些解码器是实现你自己的基于分隔符的协议的工具。
作为示例,我们将使用下面的协议规范:
- 传入数据流是一系列的帧,每个帧都由换行符(\n)分隔;
- 每个帧都由一系列的元素组成,每个元素都由单个空格字符分隔;
- 一个帧的内容代表一个命令,定义为一个命令名称后跟着数目可变的参数。
我们用于这个协议的自定义解码器将定义以下类:
- Cmd—将帧(命令)的内容存储在 ByteBuf 中,一个 ByteBuf 用于名称,另一个用于参数;
- CmdDecoder—从被重写了的 decode()方法中获取一行字符串,并从它的内容构建一个 Cmd 的实例;
- CmdHandler—从 CmdDecoder 获取解码的 Cmd 对象,并对它进行一些处理;
- CmdHandlerInitializer —为了简便起见,我们将会把前面的这些类定义为专门的 ChannelInitializer 的嵌套类,其将会把这些ChannelInboundHandler 安装到 ChannelPipeline 中。
代码如下,这个解码器的关键是扩展 LineBasedFrameDecoder。
public class CmdHandlerInitializer extends ChannelInitializer<Channel> {
final byte SPACE = (byte)' ';
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
//添加CmdDecoder已提取Cmd对象 并将它转发给下一个ChannelInboundHandler 最大为64KB
pipeline.addLast(new CmdDecoder(64 * 1024));
pipeline.addLast(new CmdHandler());
}
//javabean
public static final class Cmd {
private final ByteBuf name;
private final ByteBuf args;
public Cmd(ByteBuf name, ByteBuf args) {
this.name = name;
this.args = args;
}
public ByteBuf name() {
return name;
}
public ByteBuf args() {
return args;
}
}
public static final class CmdDecoder extends LineBasedFrameDecoder {
public CmdDecoder(int maxLength) {
super(maxLength);
}
@Override
protected Object decode(ChannelHandlerContext ctx, ByteBuf buffer)throws Exception {
//因为解码器的Decode方法是循环调用的 所以每次有消息时都会调用父类的decode 由父类首先进行预处理 按回车符分隔传进来的帧。然后再交由我们处理需要处理的部分。
ByteBuf frame = (ByteBuf) super.decode(ctx, buffer);
if (frame == null) {
return null;
}
//获取第一个空格的下标
int index = frame.indexOf(frame.readerIndex(),
frame.writerIndex(), SPACE);
//空格前是命令参数帧 后面是参数帧提取出来初始化Cmd对象 注意返回类型为Object传给下一个CmdHandler进行处理。
return new Cmd(frame.slice(frame.readerIndex(), index),
frame.slice(index + 1, frame.writerIndex()));
}
public static final class CmdHandler
extends SimpleChannelInboundHandler<Cmd> {
@Override
public void channelRead0(ChannelHandlerContext ctx, Cmd msg) throws Exception {
//处理传经ChannelPipeline的Cmd对象。
// Do something with the command
} } }
13.4.2 基于长度的协议
基于长度的协议通过将它的长度编码到帧的头部来定义帧,而不是使用特殊的分隔符来标记它的结束。
Netty提供的用于处理这种类型的协议的两种解码器。
| 名称 | 描述 |
|---|---|
| FixedLengthFrameDecoder | 提取在调用构造函数时指定的定长帧 |
| LengthFieldBasedFrameDecoder | 根据编码进帧头部中的长度值提取帧;该字段的偏移量以及长度在构造函数中指定 |
下图展示了 FixedLengthFrameDecoder 的功能,其在构造时已经指定了帧长度为 8字节。
你将经常会遇到被编码到消息头部的帧大小不是固定值的协议。为了处理这种变长帧,你可以使用 LengthFieldBasedFrameDecoder,它将从头部字段确定帧长,然后从数据流中提取指定的字节数。
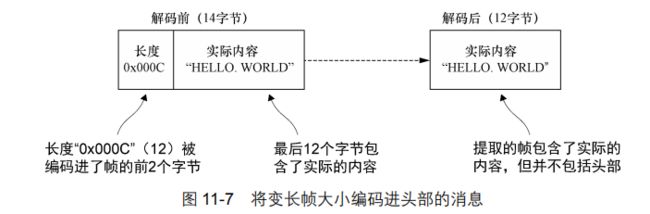
LengthFieldBasedFrameDecoder 提供了几个构造函数来支持各种各样的头部配置情况。
下面代码展示了如何使用其 3 个构造参数分别为 maxFrameLength、lengthFieldOffset 和 lengthFieldLength 的构造函数。在这个场景中,帧的长度被编码到了帧起始的前8 个字节中。
public class LengthBasedInitializer extends ChannelInitializer<Channel> {
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(
new LengthFieldBasedFrameDecoder(64 * 1024, 0, 8));
pipeline.addLast(new FrameHandler());
}
public static final class FrameHandler
extends SimpleChannelInboundHandler<ByteBuf> {
@Override
public void channelRead0(ChannelHandlerContext ctx,
ByteBuf msg) throws Exception {
// Do something with the frame
} } }
netty提供的用于支持那些通过指定协议帧的分隔符或者长度(固定的或者可变的)以定义字节流的结构的协议的编解码器。
13.5 写大型数据
因为网络饱和的可能性,如何在异步框架中高效地写大块的数据是一个特殊的问题。由于写操作是非阻塞的,所以**即使没有写出所有的数据,写操作也会在完成时返回并通知 ChannelFuture。**当这种情况发生时,如果仍然不停地写入,就有内存耗尽的风险。所以在写大型数据时,需要准备好处理到远程节点的连接是慢速连接的情况,这种情况会导致内存释放的延迟。让我们考虑下将一个文件内容写出到网络的情况。

前面提到了 NIO 的零拷贝特性,这种特性消除了将文件的内容从文件系统移动到网络栈的复制过程。
所有的这一切都发生在 Netty 的核心中,所以应用程序所有需要做的就是使用一个 FileRegion 接口的实现,其在 Netty 的 API 文档中的定义是: “通过支持零拷贝的文件传输的 Channel 来发送的文件区域。“
下面代码展示了如何通过从FileInputStream创建一个DefaultFileRegion,并将其写入Channel,(我们甚至可以利用 io.netty.channel.ChannelProgressivePromise 来实时获取传输的进度。)从而利用零拷贝特性来传输一个文件的内容。
//创建一个FileIputStream
FileInputStream in = new FileInputStream(file);
//以该文件的完整长度创建一个新的DefaultFileRegion
FileRegion region = new DefaultFileRegion(
in.getChannel(), 0, file.length());
channel.writeAndFlush(region).addListener(
//发送该DefaultFileRegion并注册一个ChanneelFutureListener
new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future)
throws Exception {
if (!future.isSuccess()) {
Throwable cause = future.cause();
// Do something
} }
});
这个示例只适用于文件内容的直接传输,不包括应用程序对数据的任何处理。在需要将数据从文件系统复制到用户内存中(这时就不是0拷贝了)时,可以使用 ChunkedWriteHandler,它支持异步写大型数据流,而又不会导致大量的内存消耗。
关键是 interface ChunkedInput,其中类型参数 B 是readChunk()方法返回的类型。
Netty 预置了该接口的 4 个实现,每个都代表了一个将由ChunkedWriteHandler 处理的不定长度的数据流。
| 名称 | 描述 |
|---|---|
| ChunkedFile | 从文件中逐块获取数据,当你的平台不支持零拷贝或者你需要转换数据时使用 |
| ChunkedNioFile | 和 ChunkedFile 类似,只是它使用了 FileChannel |
| ChunkedStream | 从 InputStream 中逐块传输内容 |
| ChunkedNioStream | 从 ReadableByteChannel 中逐块传输内容 |
下面代码说明了 ChunkedStream 的用法,它是实践中最常用的实现。所示的类使用了一个 File 以及一个 SslContext 进行实例化。当 initChannel()方法被调用时,它将使用所示的 ChannelHandler 链初始化该 Channel。
当 Channel 的状态变为活动的时,WriteStreamHandler 将会逐块地把来自文件中的数据作为 ChunkedStream 写入。数据在传输之前将会由 SslHandler 加密。
public class ChunkedWriteHandlerInitializer
extends ChannelInitializer<Channel> {
private final File file;
private final SslContext sslCtx;
public ChunkedWriteHandlerInitializer(File file, SslContext sslCtx) {
this.file = file;
this.sslCtx = sslCtx;
}
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new SslHandler(sslCtx.newEngine(ch.alloc());
//添加ChunkedWriteHandler处理作为Chunkedinput传入的数据。这是netty的类。逐块输入 要使用你自己的 ChunkedInput 实现 请在pipeline中安装一个ChunkedWriteHandler
pipeline.addLast(new ChunkedWriteHandler());
//一旦连接建立 WriteStreamHandler就开始写文件数据。
pipeline.addLast(new WriteStreamHandler());
}
public final class WriteStreamHandler
extends ChannelInboundHandlerAdapter {
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
super.channelActive(ctx);
//一旦连接建立 此方法将使用ChunkedInput写文件数据
ctx.writeAndFlush(
new ChunkedStream(new FileInputStream(file)));
} } }
到此为止,我们讨论了如何通过使用零拷贝特性来高效地传输文件,以及如何通过使用ChunkedWriteHandler 来写大型数据而又不必冒着导致 OutOfMemoryError 的风险。
13.6 序列化数据
JDK 提供了 ObjectOutputStream 和 ObjectInputStream,用于通过网络对 POJO 的基本数据类型和图进行序列化和反序列化。该 API 并不复杂,而且可以被应用于任何实现了java.io.Serializable 接口的对象。但是它的性能也不是非常高效的。
13.6.1 JDK序列化
如果你的应用程序必须要和使用了ObjectOutputStream和ObjectInputStream的远程节点交互,并且兼容性也是你最关心的,那么JDK序列化将是正确的选择。表中列出了Netty提供的用于和JDK进行互操作的序列化类。
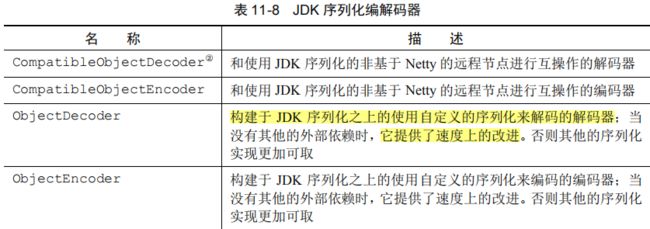
13.6.2 使用JBoss Marshalling 进行序列化
如果你可以自由地使用外部依赖,那么JBoss Marshalling将是个理想的选择:它比JDK序列化最多快 3 倍,而且也更加紧凑。
JBoss Marshalling 是一种可选的序列化 API,它修复了在 JDK 序列化 API 中所发现的许多问题,同时保留了与java.io.Serializable 及其相关类的兼容性,并添加了几个新的可调优参数以及额外的特性,所有的这些都是可以通过工厂配置(如外部序列化器、类/实例查找表、类解析以及对象替换等)实现可插拔的。
下面两组解码器/编码器对为 Boss Marshalling 提供了支持。第一组兼容只使用 JDK 序列化的远程节点。第二组提供了最大的性能,适用于和使用 JBoss Marshalling 的远程节点一起使用。
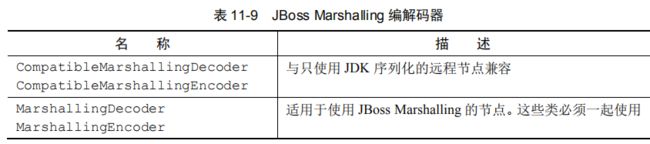
使用JBOSS Marshalling
public class MarshallingInitializer extends ChannelInitializer<Channel> {
private final MarshallerProvider marshallerProvider;
private final UnmarshallerProvider unmarshallerProvider;
public MarshallingInitializer(
UnmarshallerProvider unmarshallerProvider,
MarshallerProvider marshallerProvider) {
this.marshallerProvider = marshallerProvider;
this.unmarshallerProvider = unmarshallerProvider;
}
@Override
protected void initChannel(Channel channel) throws Exception {
//添加decoder以将bytebuf转为pojo
ChannelPipeline pipeline = channel.pipeline();
pipeline.addLast(new MarshallingDecoder(unmarshallerProvider));
//添加Encoder以将pojo转为bytebuf
pipeline.addLast(new MarshallingEncoder(marshallerProvider));
//添加ObjectHandler用于处理普通的实现了Serializable接口的POJO
pipeline.addLast(new ObjectHandler());
}
public static final class ObjectHandler
extends SimpleChannelInboundHandler<Serializable> {
@Override
public void channelRead0(
ChannelHandlerContext channelHandlerContext,
Serializable serializable) throws Exception {
// Do something
} } }
13.6.3 通过Protocol Buffers序列化
Netty序列化的最后一个解决方案是利用Protocol Buffers的编解码器。它是一种由Google公 司开发的、现在已经开源的数据交换格式。
Protocol Buffers 以一种紧凑而高效的方式对结构化的数据进行编码以及解码。它具有许多的编程语言绑定,使得它很适合跨语言的项目。
下表展示了Netty 为支持 protobuf 所提供的ChannelHandler 实现。
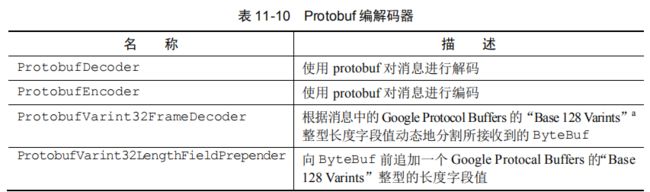
在这里我们又看到了,使用 protobuf 只不过是将正确的 ChannelHandler 添加到 ChannelPipeline 中,代码如下
public class ProtoBufInitializer extends ChannelInitializer<Channel> {
private final MessageLite lite;
public ProtoBufInitializer(MessageLite lite) {
this.lite = lite;
}
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
//分隔帧
pipeline.addLast(new ProtobufVarint32FrameDecoder());
//处理消息的编码 还需要在当前的 ProtobufEncoder 之前添加一个相应的 ProtobufVarint32LengthFieldPrepender以编码进帧长度信息。
pipeline.addLast(new ProtobufEncoder());
//解码消息
pipeline.addLast(new ProtobufDecoder(lite));
//解码消息
pipeline.addLast(new ObjectHandler());
}
public static final class ObjectHandler
extends SimpleChannelInboundHandler<Object> {
@Override
public void channelRead0(ChannelHandlerContext ctx, Object msg)
throws Exception {
// Do something with the object
} } }
Netty 零拷贝补充知识
非零拷贝 (常规模式)
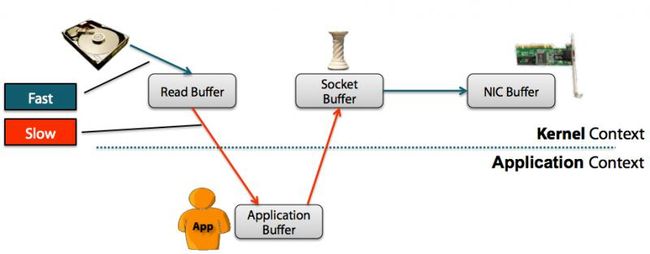
零拷贝
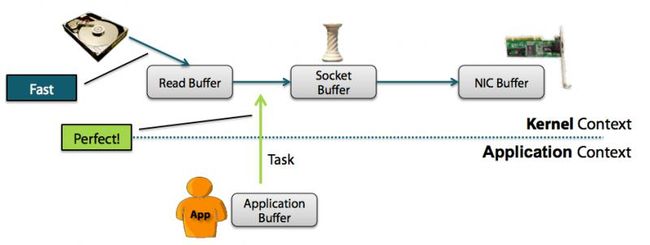
从上图中可以清楚的看到,Zero Copy的模式中,避免了数据在用户空间和内存空间之间的拷贝(直接从文件系统传入到socket中),从而提高了系统的整体性能。Linux中的sendfile()以及Java NIO中的FileChannel.transferTo()方法都实现了零拷贝的功能,而在Netty中也通过在FileRegion中包装了NIO的FileChannel.transferTo()方法实现了零拷贝。
而在Netty中还有另一种形式的零拷贝,即Netty允许我们将多段数据合并为一整段虚拟数据供用户使用,而过程中不需要对数据进行拷贝操作,这也是我们今天要讲的重点。我们都知道在stream-based transport(如TCP/IP)的传输过程中,数据包有可能会被重新封装在不同的数据包中,例如当你发送如下数据时:
![]()
有可能实际收到的数据如下:
![]()
因此在实际应用中,很有可能一条完整的消息被分割为多个数据包进行网络传输,而单个的数据包对你而言是没有意义的,只有当这些数据包组成一条完整的消息时你才能做出正确的处理,而Netty可以通过零拷贝的方式将这些数据包组合成一条完整的消息供你来使用。而此时,零拷贝的作用范围仅在用户空间中。

传统I/O做法:
File file = new File("index.html ");
RandomAccessFile raf = new RandomAccessFile(file, "rw");
byte[] arr = new byte[(int) file.length()];
raf.read(arr);
Socket socket = new ServerSocket(8080).accept();
socket.getOutputStream().write(arr);
上半部分表示用户态和内核态的上下文切换。下半部分表示数据复制操作
- read 调用导致用户态到内核态的一次变化,同时,第一次复制开始:DMA引擎从磁盘读取 index.html 文件,并将数据放入到内核缓冲区
- 发生第二次数据拷贝,即:将内核缓冲区的数据拷贝到用户缓冲区,同时,发生了一次用内核态到用户态的上下文切换
- 发生第三次数据拷贝,我们调用 write 方法,系统将用户缓冲区的数据拷贝到 Socket 缓冲区。此时,又发生了一次用户态到内核态的上下文切换
- 第四次拷贝,数据异步的从 Socket 缓冲区,使用 DMA 引擎拷贝到网络协议引擎。这一段,不需要进行上下文切换
- write 方法返回,再次从内核态切换到用户态
https://blog.csdn.net/qianlia/article/details/106123593
https://www.cnblogs.com/200911/articles/10432551.html
https://blog.csdn.net/bupttulongming/article/details/103646158
PART 3 网络协议
14 webSocket
14.1 WebSocket简介
WebSocket并不是指所谓的硬实时服务质量(QoS),硬实时服务质量是保证计算结果将在指定的时间间隔内被递交。仅 HTTP 的请求/响应模式设计就使得其很难被支持.
WebSocket 协议是完全重新设计的协议,旨在为 Web 上的双向数据传输问题提供一个切实可行的解决方案,使得客户端和服务器之间可以在任意时刻传输消息,因此,这也就要求它们异步地处理消息回执。
Netty 对于 WebSocket 的支持包含了所有正在使用中的主要实现,因此在你的下一个应 用程序中采用它将是简单直接的。和往常使用 Netty 一样,你可以完全使用该协议,而无需关心它内部的实现细节。
14.2 WebSocket示例应用程序
为了让示例应用程序展示它的实时功能,我们 将通过使用 WebSocket 协议来实现一个基于浏览器的聊天应用程序,就像你可能在 Facebook 的文本消息功能中见到过的那样。
该应用程序的逻辑:
(1)客户端发送一个消息;
(2)该消息将被广播到所有其他连接的客户端。
这正如你可能会预期的一个聊天室应当的工作方式:所有的人都可以和其他的人聊天。在示例中,我们将只实现服务器端,而客户端则是通过 Web 页面访问该聊天室的浏览器。
14.3 添加WebSocket支持
在从标准的HTTP或者HTTPS协议切换到WebSocket时,将会使用一种称为升级握手的机制。因此,使用WebSocket的应用程序将始终以HTTP/S作为开始,然后再执行升级。这个升级动作发生的确切时刻特定于应用程序;它可能会发生在启动时,也可能会发生在请求了某个特定的URL之后。
我们的应用程序将采用下面的约定:如果被请求的 URL 以/ws 结尾,那么我们将会把该协议升级为 WebSocket;否则,服务器将使用基本的 HTTP/S。在连接已经升级完成之后,所有数据都将会使用 WebSocket 进行传输。下图说明了该服务器逻辑,一如在 Netty 中一样,它由一组 ChannelHandler 实现。
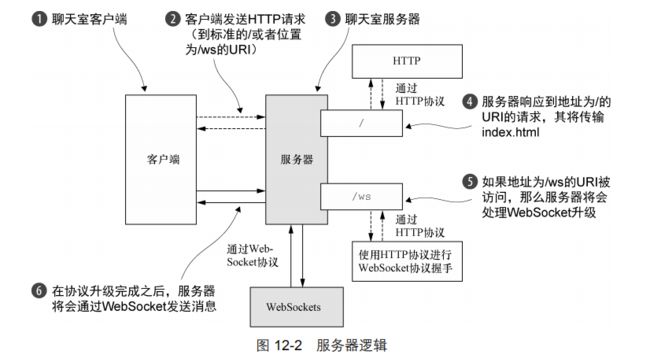
14.3.1 处理HTTP请求
首先,我们将实现该处理 HTTP 请求的组件。这个组件将提供用于访问聊天室并显示由连接的客户端发送的消息的网页。代码给出了这个 HttpRequestHandler 对应的代码,其扩展了 SimpleChannelInboundHandler 以处理 FullHttpRequest 消息。需要注意的是,channelRead0()方法的实现是如何转发任何目标 URI 为/ws 的请求的。
HTTPRequestHandler代码如下:
public class HttpRequestHandler
extends SimpleChannelInboundHandler<FullHttpRequest> {
//把泛型类定义为FullHttpRequest类 拓展handler以处理FullHttpRequest消息。
private final String wsUri;
private static final File INDEX;
static {
URL location = HttpRequestHandler.class
.getProtectionDomain()
.getCodeSource().getLocation();
try {
String path = location.toURI() + "index.html";
path = !path.contains("file:") ? path : path.substring(5);
INDEX = new File(path);
} catch (URISyntaxException e) {
throw new IllegalStateException(
"Unable to locate index.html", e);
} }
public HttpRequestHandler(String wsUri) {
this.wsUri = wsUri;
}
@Override
public void channelRead0(ChannelHandlerContext ctx,
FullHttpRequest request) throws Exception {
//如果请求了WebSocket协议升级,则增加引用计数,调用retain()方法,将它换递给下一个ChannelInboundHandler
//之所以需要调用 retain()方法,是因为调用 channelRead()方法完成之后,它将调用 FullHttpRequest 对象上的 release()方法以释放它的资源。
if (wsUri.equalsIgnoreCase(request.getUri())) {
ctx.fireChannelRead(request.retain());
} else {
//若继续用HTTP 则处理HTTP请求
//处理100Continue请求已复核HTTP1.0规范
if (HttpHeaders.is100ContinueExpected(request)) {
send100Continue(ctx);
}
//读取请求的文件
RandomAccessFile file = new RandomAccessFile(INDEX, "r");
HttpResponse response = new DefaultHttpResponse(
request.getProtocolVersion(), HttpResponseStatus.OK);
//设置response的头信息。
response.headers().set(
HttpHeaders.Names.CONTENT_TYPE,
"text/plain; charset=UTF-8");
boolean keepAlive = HttpHeaders.isKeepAlive(request);
//如果请求了KEEP-ALIVE 则添加所需要的HTTP头信息
if (keepAlive) {
response.headers().set(
HttpHeaders.Names.CONTENT_LENGTH, file.length());
response.headers().set( HttpHeaders.Names.CONNECTION,
HttpHeaders.Values.KEEP_ALIVE);
}
//将HTTPRESPONSE写到客户端
ctx.write(response);
//如果文件数据没有经过加密,那么可以直接拓展FileRegion进行零拷贝传输 提升效率,否则需要用ChunkedNioFile(前面提到的)
if (ctx.pipeline().get(SslHandler.class) == null) {
//将文件写到客户端
ctx.write(new DefaultFileRegion(
file.getChannel(), 0, file.length()));
} else {
ctx.write(new ChunkedNioFile(file.getChannel()));
}
//将最后的部分写入HttpResponse中构成一个FullHttpResponse 之前的write都是阻塞操作 需要flush才能真正传输出去,而下面这个调用之后就将前面的也一起发出去了 这样保证每次发出去的都是一个FullHttpResponse
//在这里,你将调用 writeAndFlush()方法以冲刷所有之前写入的消息
ChannelFuture future = ctx.writeAndFlush(
LastHttpContent.EMPTY_LAST_CONTENT);
//以上部分把 响应 头 体 尾 组成一个响应体都传给了客户端
//若没有请求keep-alive则这次写操作(不含header部分的response)完成后关闭channel 否则不能关要一直传输数据
if (!keepAlive) {
future.addListener(ChannelFutureListener.CLOSE);
} } }
private static void send100Continue(ChannelHandlerContext ctx) {
FullHttpResponse response = new DefaultFullHttpResponse(
HttpVersion.HTTP_1_1, HttpResponseStatus.CONTINUE);
ctx.writeAndFlush(response);
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause)
throws Exception {
cause.printStackTrace();
ctx.close();
} }
这部分代码代表了聊天服务器的第一个部分,它管理纯粹的 HTTP 请求和响应。接下来,我们将处理传输实际聊天消息的 WebSocket 帧。
WEBSOCKET 帧
WebSocket 以帧的方式传输数据,每一帧代表消息的一部分。一个完整的消息可能会包含许多帧.
14.3.2 处理WebSocket帧
由 IETF 发布的 WebSocket RFC,定义了 6 种帧,Netty 为它们每种都提供了一个 POJO 实现。
下表列出了这些帧类型,并描述了它们的用法。
WebSocketFrame的类型:
| 帧类型 | 描述 |
|---|---|
| BinaryWebSocketFrame | 包含了二进制数据 |
| TextWebSocketFrame | 包含了文本数据 |
| ContinuationWebSocketFrame | 包含属于上一个BinaryWebSocketFrame或TextWebSocketFrame 的文本数据或者二进制数据 |
| CloseWebSocketFrame | 表示一个 CLOSE 请求,包含一个关闭的状态码和关闭的原因 |
| PingWebSocketFrame | 请求传输一个 PongWebSocketFrame |
| PongWebSocketFrame | 作为一个对于 PingWebSocketFrame 的响应被发送 |
我们的聊天应用程序将使用下面几种帧类型:
- CloseWebSocketFrame;
- PingWebSocketFrame;
- PongWebSocketFrame;
- TextWebSocketFrame。
TextWebSocketFrame 是我们唯一真正需要处理的数据帧类型。
为了符合 WebSocket RFC,Netty 提供了 WebSocketServerProtocolHandler 来处理其他类型的帧。
下面代码展示了我们用于处理 TextWebSocketFrame 的 ChannelInboundHandler,其还将在它的 ChannelGroup 中跟踪所有活动的 WebSocket 连接
public class TextWebSocketFrameHandler
extends SimpleChannelInboundHandler<TextWebSocketFrame> {
//拓展Simple..handler以处理TextWebSocketFrame
private final ChannelGroup group;
public TextWebSocketFrameHandler(ChannelGroup group) {
this.group = group;
}
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
if (evt == WebSocketServerProtocolHandler
.ServerHandshakeStateEvent.HANDSHAKE_COMPLETE) {
//如果是websocket握手成功,则从pipeline中移除httprequesthandler(之前实现的)因为将不会接收到任何http消息了,因为已经采用了websocket传输 而非http了 所以从pipeline中移除。结合下段pipeline代码理解
ctx.pipeline().remove(HttpRequestHandler.class);
//通知所有已连接的webscocket客户端 新的客户端连上了
group.writeAndFlush(new TextWebSocketFrame(
"Client " + ctx.channel() + " joined"));
//将新的chanel添加到channelgroup中以便它接收到所有的消息
group.add(ctx.channel());
} else {
super.userEventTriggered(ctx, evt);
} }
@Override
public void channelRead0(ChannelHandlerContext ctx,
TextWebSocketFrame msg) throws Exception {
//增加消息的引用计数 并将它写到channel中所有练级的客户端
group.writeAndFlush(msg.retain());
} }
TextWebSocketFrameHandler 只有一组非常少量的责任。当和新客户端的 WebSocket握手成功完成之后 ,它将通过把通知消息写到ChannelGroup 中的所有 Channel 来通知所有已经连接的客户端,然后它将把这个新 Channel 加入到该 ChannelGroup 中。
如果接收到了 TextWebSocketFrame 消息 ,TextWebSocketFrameHandler 将调用TextWebSocketFrame 消息上的 retain()方法,并使用 writeAndFlush()方法来将它传输给 ChannelGroup,以便所有已经连接的 WebSocket Channel 都将接收到它。和之前一样,对于 retain()方法的调用是必需的,因为当 channelRead0()方法返回时,TextWebSocketFrame 的引用计数将会被减少。由于所有的操作都是异步的,因此,writeAndFlush()方法可能会在 channelRead0()方法返回之后完成,而且它绝对不能访问一个已经失效的引用。
因为 Netty 在内部处理了大部分剩下的功能,所以现在剩下唯一需要做的事情就是为每个新创建的 Channel 初始化其 ChannelPipeline。为此,我们将需要一个 ChannelInitializer。
14.3.3 初始化ChannelPipeline
初始化ChannelPipeline
public class ChatServerInitializer extends ChannelInitializer<Channel> {
private final ChannelGroup group;
public ChatServerInitializer(ChannelGroup group) {
this.group = group;
}
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new HttpServerCodec());
pipeline.addLast(new ChunkedWriteHandler());
pipeline.addLast(new HttpObjectAggregator(64 * 1024));
pipeline.addLast(new HttpRequestHandler("/ws"));
pipeline.addLast(new WebSocketServerProtocolHandler("/ws"));
pipeline.addLast(new TextWebSocketFrameHandler(group));
} }
对于 initChannel()方法的调用,通过安装所有必需的 ChannelHandler 来设置该新注册的 Channel 的 ChannelPipeline。这些 ChannelHandler 以及它们各自的职责都被总结在下表:
| ChannelHandler | 职责 |
|---|---|
| HttpServerCodec | 将字节解码为 HttpRequest、HttpContent 和 LastHttpContent。并将 HttpRequest、HttpContent 和 LastHttpContent 编码为字节 |
| ChunkedWriteHandler | 写入一个文件的内容 |
| HttpObjectAggregator | 将一个 HttpMessage 和跟随它的多个 HttpContent 聚合为单个 FullHttpRequest 或者 FullHttpResponse(取决于它是被用来处理请求还是响应)。安装了这个之后,ChannelPipeline 中的下一个 ChannelHandler 将只会收到完整的 HTTP 请求或响应 |
| HttpRequestHandler | 处理 FullHttpRequest(那些不发送到/ws URI 的请求) |
| WebSocketServerProtocolHandler | 按照 WebSocket 规范的要求,处理 WebSocket 升级握手、PingWebSocketFrame 、 PongWebSocketFrame、CloseWebSocketFrame |
| TextWebSocketFrameHandler | 处理 TextWebSocketFrame 和握手完成事件 |
Netty 的 WebSocketServerProtocolHandler 处理了所有委托管理的 WebSocket 帧类型以及升级握手本身。如果握手成功,那么所需的 ChannelHandler 将会被添加到 ChannelPipeline中,而那些不再需要的 ChannelHandler 则将会被移除。
WebSocket 协议升级之前的 ChannelPipeline 的状态如图所示。这代表了刚刚被ChatServerInitializer 初始化之后的 ChannelPipeline。

当 WebSocket 协议升级完成之后WebSocketServerProtocolHandler 将会把 HttpRequestDecoder 替换为 WebSocketFrameDecoder,把 HttpResponseEncoder 替换为WebSocketFrameEncoder。为了性能最大化,它将移除任何不再被 WebSocket 连接所需要的ChannelHandler。这也包括了上图所示的 HttpObjectAggregator 和 HttpRequestHandler。
下图展示了这些操作完成之后的ChannelPipeline。需要注意的是,Netty目前支持 4个版本的WebSocket协议,它们每个都具有自己的实现类。Netty将会根据客户端(这里指浏览器)所支持的版本,自动地选择正确版本的WebSocketFrameDecoder和WebSocketFrameEncoder。

14.3.4 引导
这幅拼图最后的一部分是引导该服务器,并安装 ChatServerInitializer 的代码。这将由 ChatServer 类处理,代码如下:
public class ChatServer {
//创建DefaultChannelGroup,其将保存所有已经连接的WebSocket Channel
private final ChannelGroup channelGroup =
new DefaultChannelGroup(ImmediateEventExecutor.INSTANCE);
private final EventLoopGroup group = new NioEventLoopGroup();
private Channel channel;
public ChannelFuture start(InetSocketAddress address) {
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(group)
.channel(NioServerSocketChannel.class)
.childHandler(createInitializer(channelGroup));
ChannelFuture future = bootstrap.bind(address);
future.syncUninterruptibly();
channel = future.channel();
return future;
}
protected ChannelInitializer<Channel> createInitializer(
ChannelGroup group) {
return new ChatServerInitializer(group);
}
//处理服务器关闭 并释放所有的资源
public void destroy() {
if (channel != null) {
channel.close();
}
channelGroup.close();
group.shutdownGracefully();
}
public static void main(String[] args) throws Exception {
if (args.length != 1) {
System.err.println("Please give port as argument");
System.exit(1);
}
int port = Integer.parseInt(args[0]);
final ChatServer endpoint = new ChatServer();
ChannelFuture future = endpoint.start(
new InetSocketAddress(port));
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
endpoint.destroy();
}
});
future.channel().closeFuture().syncUninterruptibly();
}
}
14.3.5 加密
在真实世界的场景中,你将很快就会被要求向该服务器添加加密。使用 Netty,这不过是将一 个 SslHandler 添加到 ChannelPipeline 中,并配置它的问题。
下列代码展示了如何通过扩展我们的ChatServerInitializer来创建一个SecureChatServerInitializer 以完成这个需求。
public class SecureChatServerInitializer extends ChatServerInitializer {
private final SslContext context;
public SecureChatServerInitializer(ChannelGroup group,
SslContext context) {
super(group);
this.context = context;
}
@Override
protected void initChannel(Channel ch) throws Exception {
super.initChannel(ch);
SSLEngine engine = context.newEngine(ch.alloc());
engine.setUseClientMode(false);
ch.pipeline().addFirst(new SslHandler(engine));
} }
调整chatServer
public class SecureChatServer extends ChatServer {
private final SslContext context;
public SecureChatServer(SslContext context) {
this.context = context;
}
@Override
protected ChannelInitializer<Channel> createInitializer(
ChannelGroup group) {
return new SecureChatServerInitializer(group, context);
}
public static void main(String[] args) throws Exception {
if (args.length != 1) {
System.err.println("Please give port as argument");
System.exit(1);
}
int port = Integer.parseInt(args[0]);
SelfSignedCertificate cert = new SelfSignedCertificate();
SslContext context = SslContext.newServerContext(
cert.certificate(), cert.privateKey());
final SecureChatServer endpoint = new SecureChatServer(context);
ChannelFuture future = endpoint.start(new InetSocketAddress(port));
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
endpoint.destroy();
}
});
future.channel().closeFuture().syncUninterruptibly();
}
}
15 使用UDP广播事件
到目前为止,你所见过的绝大多数的例子都使用了基于连接的协议,如TCP。在本章中,我们将会把重点放在一个无连接协议即用户数据报协议(UDP)上,它通常用在性能至关重要并且能够容忍一定的数据包丢失的情况下。
15.1 UDP基础知识
面向连接的传输(如 TCP)管理了两个网络端点之间的连接的建立,在连接的生命周期内的有序和可靠的消息传输,以及最后,连接的有序终止。相比之下,在类似于 UDP 这样的无连接协议中,并没有持久化连接这样的概念,并且每个消息(一个 UDP 数据报)都是一个单独的传输单元。
此外,UDP 也没有 TCP 的纠错机制,其中每个节点都将确认它们所接收到的包,而没有被确认的包将会被发送方重新传输。
通过类比,TCP 连接就像打电话,其中一系列的有序消息将会在两个方向上流动。相反,UDP 则类似于往邮箱中投入一叠明信片。你无法知道它们将以何种顺序到达它们的目的地,或者它们是否所有的都能够到达它们的目的地。
UDP的这些方面可能会让你感觉到严重的局限性,但是它们也解释了为何它会比TCP快那么多:所有的握手以及消息管理机制的开销都已经被消除了。显然,UDP很适合那些能够处理或者容忍消息丢失的应用程序,但可能不适合那些处理金融交易的应用程序
15.2 UDP广播
到目前为止,我们所有的例子采用的都是一种叫作单播的传输模式,定义为发送消息给一个由唯一的地址所标识的单一的网络目的地。面向连接的协议和无连接协议都支持这种模式。
UDP 提供了向多个接收者发送消息的额外传输模式:
- 多播——传输到一个预定义的主机组;
- 广播——传输到网络(或者子网)上的所有主机;
下面应用程序将通过发送能够被同一个网络中的所有主机所接收的消息来演示UDP 广播的使用。为此,我们将使用特殊的受限广播地址或者零网络地址 255.255.255.255。发送到这个地址的消息都将会被定向给本地网络(0.0.0.0)上的所有主机,而不会被路由器转发给其他的网络。
15.3 UDP实例应用程序
我们的示例程序将打开一个文件,随后将会通过 UDP 把每一行都作为一个消息广播到一个指定的端口。如果你熟悉类 UNIX 操作系统,你可能会认识到这是标准的 syslog (发布订阅模式)实用程序的一个非常简化的版本。UDP 非常适合于这样的应用程序,因为考虑到日志文件本身已经被存储在了文件系统中,因此,偶尔丢失日志文件中的一两行是可以容忍的。此外,该应用程序还提供了极具价值的高效处理大量数据的能力。
接收方是怎么样的呢?通过 UDP 广播,只需简单地通过在指定的端口上启动一个监听程序,便可以创建一个事件监视器来接收日志消息。需要注意的是,这样的轻松访问性也带来了潜在的安全隐患,这也就是为何在不安全的环境中并不倾向于使用 UDP 广播的原因之一。出于同样的原因,路由器通常也会阻止广播消息,并将它们限制在它们的来源网络上。
下图展示了整个系统的一个高级别视图,其由一个广播者以及一个或者多个事件监视器所组成。广播者将监听新内容的出现,当它出现时,则通过 UDP 将它作为一个广播消息进行传输。
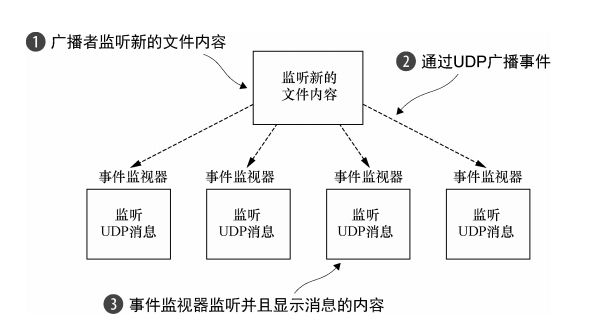
所有的在该 UDP 端口上监听的事件监视器都将会接收到广播消息。为了简单起见,我们将不会为我们的示例程序添加身份认证、验证或者加密。但是,要加入这些功能并使得其成为一个健壮的、可用的实用程序应该也不难。
15.4 消息POJO:LogEvent
在消息处理应用程序中,数据通常由 POJO 表示,除了实际上的消息内容,其还可以包含配置或处理信息。在这个应用程序中,我们将会把消息作为事件处理,并且由于该数据来自于日志文件,所以我们将它称为 LogEvent。
public final class LogEvent {
public static final byte SEPARATOR = (byte) ':';
private final InetSocketAddress source;
private final String logfile;
private final String msg;
private final long received;
public LogEvent(String logfile, String msg) {
this(null, -1, logfile, msg);
}
public LogEvent(InetSocketAddress source, long received,String logfile, String msg) {
this.source = source;
this.logfile = logfile;
this.msg = msg;
this.received = received;
}
public InetSocketAddress getSource() {
return source;
}
public String getLogfile() {
return logfile;
}
public String getMsg() {
return msg;
}
public long getReceivedTimestamp() {
return received;
}
}
定义好了消息组件,我们便可以实现该应用程序的广播逻辑了。在下一节中,我们将研究用于编码和传输 LogEvent 消息的 Netty 框架类。
15.5 编写广播者
Netty 提供了大量的类来支持 UDP 应用程序的编写。
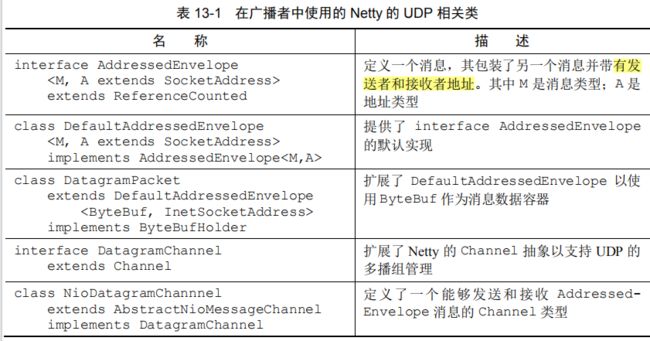
Netty 的 DatagramPacket 是一个简单的消息容器DatagramChannel 实现用它来和远程节点通信。类似于在我们先前的类比中的明信片,它包含了接收者(和可选的发送者)的地址以及消息的有效负载本身。
要将 LogEvent 消息转换为 DatagramPacket,我们将需要一个编码器。但是没有必要从头开始编写我们自己的。我们将扩展 Netty 的 MessageToessageEncoder,在之前的章节已经展示过了。

下图呈现了该 LogEventBroadcaster 的 ChannelPipeline(Channelpipeline和LogEvent的事件流) 的一个高级别视图,展示了 LogEvent 消息是如何流经它的。

正如你所看到的,所有的将要被传输的数据都被封装在了 LogEvent 消息中。LogEventBroadcaster 将把这些写入到 Channel 中,并通过 ChannelPipeline 发送它们,在那里它们将会被转换(编码)为 DatagramPacket 消息。最后,他们都将通过 UDP 被广播,并由远程节点(监视器)所捕获。
下面代码实现自定义版本编码器进行数据格式转换:
public class LogEventEncoder extends MessageToMessageEncoder<LogEvent> {
//LogEvent此昂见了即将被发送到指定地址的DatagramPacket消息
private final InetSocketAddress remoteAddress;
public LogEventEncoder(InetSocketAddress remoteAddress) {
this.remoteAddress = remoteAddress;
}
@Override
protected void encode(ChannelHandlerContext channelHandlerContext,LogEvent logEvent, List<Object> out) throws Exception {
byte[] file = logEvent.getLogfile().getBytes(CharsetUtil.UTF_8);
byte[] msg = logEvent.getMsg().getBytes(CharsetUtil.UTF_8);
ByteBuf buf = channelHandlerContext.alloc()
.buffer(file.length + msg.length + 1);
//将文件名写入ByteBuf中
buf.writeBytes(file);
//添加一个separator
buf.writeByte(LogEvent.SEPARATOR);
//将日志消息写入ByteBuf中
buf.writeBytes(msg);
//将一个拥有数据和目的地地址的新datagrampacket添加到出站的消息列表中。
out.add(new DatagramPacket(buf, remoteAddress));
} }
在 LogEventEncoder 被实现之后,我们已经准备好了引导该服务器,其包括设置各种各样的 ChannelOption,以及在 ChannelPipeline 中安装所需要的 ChannelHandler。这将通过主类 LogEventBroadcaster 完成,代码如下:
public class LogEventBroadcaster {
private final EventLoopGroup group;
private final Bootstrap bootstrap;
private final File file;
public LogEventBroadcaster(InetSocketAddress address, File file) {
group = new NioEventLoopGroup();
bootstrap = new Bootstrap();
bootstrap.group(group)
//引导无连接的NioDatagraChannel
.channel(NioDatagramChannel.class)
//设置SO_BROADCAST套接字选项
.option(ChannelOption.SO_BROADCAST, true)
.handler(new LogEventEncoder(address));
this.file = file;
}
public void run() throws Exception {
//绑定channel
Channel ch = bootstrap.bind(0).sync().channel();
long pointer = 0;
for (;;) {
long len = file.length();
if (len < pointer) {
//将文件指针指向最后一个字节
// file was reset
pointer = len;
} else if (len > pointer) {
// Content was added
RandomAccessFile raf = new RandomAccessFile(file, "r");
//设置当前文件指针已确定没有任何旧日志被发送
raf.seek(pointer);
String line;
while ((line = raf.readLine()) != null) {
//对每个日志条目写入一个LogEvent到Channel中
ch.writeAndFlush(new LogEvent(null, -1,
file.getAbsolutePath(), line));
}
//存储其在文件中的当前位置
pointer = raf.getFilePointer();
raf.close();
}
try {
//休眠1s,如果被中断则退出循环 否则重新处理它。
Thread.sleep(1000);
} catch (InterruptedException e) {
Thread.interrupted();
break;
} } }
public void stop() {
group.shutdownGracefully();
}
public static void main(String[] args) throws Exception {
if (args.length != 2) {
throw new IllegalArgumentException();
}
LogEventBroadcaster broadcaster = new LogEventBroadcaster(
new InetSocketAddress("255.255.255.255",
Integer.parseInt(args[0])), new File(args[1]));
try {
broadcaster.run();
}
finally {
broadcaster.stop();
} } }
15.6 编写监视器
我们将添加一个事件消费者,我们称之为 LogEventMonitor。
这个程序将:
(1)接收由 LogEventBroadcaster 广播的 UDP DatagramPacket;
(2)将它们解码为 LogEvent 消息;
(3)将 LogEvent 消息写出到 System.out。
和之前一样,该逻辑由一组自定义的 ChannelHandler 实现——对于我们的解码器来说,我们将扩展 MessageToMessageDecoder。下图描绘了 LogEventMonitor 的 ChannelPipeline,并且展示了 LogEvent 是如何流经它的。

ChannelPipeline 中的第一个解码器LogEventDecoder 负责将传入的DatagramPacket解码为 LogEvent 消息
public class LogEventDecoder extends MessageToMessageDecoder<DatagramPacket> {
@Override
protected void decode(
ChannelHandlerContext ctx,
DatagramPacket datagramPacket,
List<Object> out) throws Exception
{
//获取datagrampacket中的数据bytebuf引用
ByteBuf data = datagramPacket.content();
//获取分隔符的索引
int idx = data.indexOf(0, data.readableBytes(),
LogEvent.SEPARATOR);
//提取文件名与日志消息
String filename = data.slice(0, idx)
.toString(CharsetUtil.UTF_8);
String logMsg = data.slice(idx + 1,
data.readableBytes()).toString(CharsetUtil.UTF_8);
LogEvent event = new LogEvent(datagramPacket.sender(),
System.currentTimeMillis(), filename, logMsg);
//添加到列表中传输
out.add(event);
}
}
第二个 ChannelHandler 的工作是对第一个 ChannelHandler 所创建的 LogEvent 消息执行一些处理。在这个场景下,它只是简单地将它们写出到 System.out。在真实世界的应用程序中,你可能需要聚合来源于不同日志文件的事件,或者将它们发布到数据库中。代码如下:LogEventHandler,其说明了需要遵循的基本步骤。
public class LogEventHandler
extends SimpleChannelInboundHandler<LogEvent> {
@Override
public void exceptionCaught(ChannelHandlerContext ctx,Throwable cause) throws Exception {
cause.printStackTrace();
ctx.close();
}
@Override
public void channelRead0(
ChannelHandlerContext ctx,
LogEvent event) throws Exception {
StringBuilder builder = new StringBuilder();
builder.append(event.getReceivedTimestamp());
builder.append(" [");
builder.append(event.getSource().toString());
builder.append("] [");
builder.append(event.getLogfile());
builder.append("] : ");
builder.append(event.getMsg());
System.out.println(builder.toString());
}
}
LogEventHandler 将以一种简单易读的格式打印 LogEvent 消息,包括以下的各项:
- 以毫秒为单位的被接收的时间戳;
- 发送方的 InetSocketAddress,其由 IP 地址和端口组成;
- 生成 LogEvent 消息的日志文件的绝对路径名;
- 实际上的日志消息,其代表日志文件中的一行。
现在我们需要将我们的LogEventDecoder 和LogEventHandler 安装到ChannelPipeline中。
public class LogEventMonitor {
private final EventLoopGroup group;
private final Bootstrap bootstrap;
public LogEventMonitor(InetSocketAddress address) {
group = new NioEventLoopGroup();
bootstrap = new Bootstrap();
bootstrap
.group(group)
.channel(NioDatagramChannel.class)
.option(ChannelOption.SO_BROADCAST, true)
.handler(new ChannelInitializer<Channel>() {
@Override
protected void initChannel(Channel channel)throws Exception {
ChannelPipeline pipeline = channel.pipeline();
pipeline.addLast(new LogEventDecoder());
pipeline.addLast(new LogEventHandler());
}
})
.localAddress(address);
}
public Channel bind() {
return bootstrap.bind().syncUninterruptibly().channel();
}
public void stop() {
group.shutdownGracefully();
}
public static void main(String[] main) throws Exception {
if (args.length != 1) {
throw new IllegalArgumentException(
"Usage: LogEventMonitor " );
}
LogEventMonitor monitor = new LogEventMonitor(
new InetSocketAddress(Integer.parseInt(args[0])));
try {
Channel channel = monitor.bind();
System.out.println("LogEventMonitor running");
channel.closeFuture().sync();
} finally {
monitor.stop();
}
}
}
15.7 总结
在本章中,我们使用 UDP 作为例子介绍了无连接协议。我们构建了一个示例应用程序,其将日志条目转换为 UDP 数据报并广播它们,随后这些被广播出去的消息将被订阅的监视器客户端所捕获。我们的实现使用了一个 POJO 来表示日志数据,并通过一个自定义的编码器来将这个消息格式转换为 Netty 的 DatagramPacket。这个例子说明了 Netty 的 UDP 应用程序可以很轻松地被开发和扩展用以支持专业化的用途。
HTTP知识补充:
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。。
HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
HTTP协议工作于客户端-服务端架构上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。
Web服务器有:Apache服务器,IIS服务器(Internet Information Services)等。
Web服务器根据接收到的请求后,向客户端发送响应信息。
HTTP默认端口号为80,但是你也可以改为8080或者其他端口。
HTTP三点注意事项:
- HTTP是无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
- HTTP是媒体独立的:这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。客户端以及服务器指定使用适合的MIME-type内容类型。
- HTTP是无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
以下图表展示了HTTP协议通信流程:
CGI(Common Gateway Interface) 是 HTTP 服务器与你的或其它机器上的程序进行“交谈”的一种工具,其程序须运行在网络服务器上。
绝大多数的 CGI 程序被用来解释处理来自表单的输入信息,并在服务器产生相应的处理,或将相应的信息反馈给浏览器。CGI 程序使网页具有交互功能。
HTTP 消息结构
HTTP是基于客户端/服务端(C/S)的架构模型,通过一个可靠的链接来交换信息,是一个无状态的请求/响应协议。
一个HTTP"客户端"是一个应用程序(Web浏览器或其他任何客户端),通过连接到服务器达到向服务器发送一个或多个HTTP的请求的目的。
一个HTTP"服务器"同样也是一个应用程序(通常是一个Web服务,如Apache Web服务器或IIS服务器等),通过接收客户端的请求并向客户端发送HTTP响应数据。
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。
一旦建立连接后,数据消息就通过类似Internet邮件所使用的格式[RFC5322]和多用途Internet邮件扩展(MIME)[RFC2045]来传送。
客户端请求消息
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:请求行(request line)、请求头部(header)、空行和请求数据四个部分组成,下图给出了请求报文的一般格式。
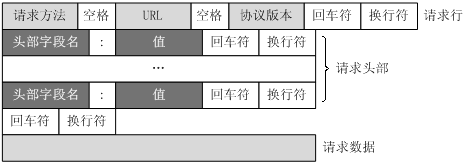
服务器响应信息
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
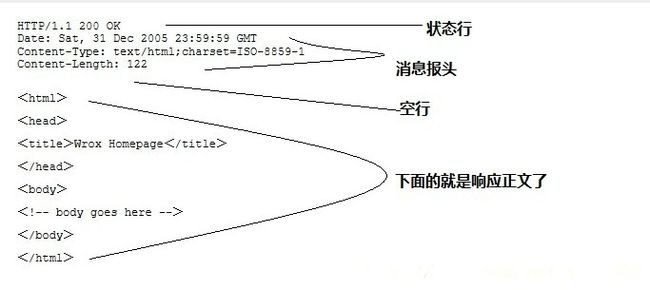
实例:
下面实例是一点典型的使用GET来传递数据的实例:
客户端请求:
GET /hello.txt HTTP/1.1
User-Agent: curl/7.16.3 libcurl/7.16.3 OpenSSL/0.9.7l zlib/1.2.3
Host: www.example.com
Accept-Language: en, mi
服务端响应:
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2009 12:28:53 GMT
Server: Apache
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
ETag: "34aa387-d-1568eb00"
Accept-Ranges: bytes
Content-Length: 51
Vary: Accept-Encoding
Content-Type: text/plain
HTTP 协议的 8 种请求类型介绍
HTTP1.0 定义了三种请求方法: GET, POST 和 HEAD 方法。
HTTP1.1 新增了六种请求方法:OPTIONS、PUT、PATCH、DELETE、TRACE 和 CONNECT 方法。
HTTP 协议中共定义了八种方法或者叫“动作”来表明对 Request-URI 指定的资源的不同操作方式,具体介绍如下:
- OPTIONS:返回服务器针对特定资源所支持的HTTP请求方法。也可以利用向Web服务器发送’*'的请求来测试服务器的功能性。
- HEAD:向服务器索要与GET请求相一致的响应,只不过响应体将不会被返回。这一方法可以在不必传输整个响应内容的情况下,就可以获取包含在响应消息头中的元信息。
- GET:向特定的资源发出请求。
- POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的创建和/或已有资源的修改。
- PUT:向指定资源位置上传其最新内容。
- DELETE:请求服务器删除 Request-URI 所标识的资源。
- TRACE:回显服务器收到的请求,主要用于测试或诊断。
- CONNECT:HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。
- PATCH: 是对 PUT 方法的补充,用来对已知资源进行局部更新 。
虽然 HTTP 的请求方式有 8 种,但是我们在实际应用中常用的也就是 get 和 post,其他请求方式也都可以通过这两种方式间接的来实现。
HTTP 响应头信息:
| 应答头 | 说明 |
|---|---|
| Allow | 服务器支持哪些请求方法(如GET、POST等)。 |
| Content-Encoding | 文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。利用gzip压缩文档能够显著地减少HTML文档的下载时间。Java的GZIPOutputStream可以很方便地进行gzip压缩,但只有Unix上的Netscape和Windows上的IE 4、IE 5才支持它。因此,Servlet应该通过查看Accept-Encoding头(即request.getHeader(“Accept-Encoding”))检查浏览器是否支持gzip,为支持gzip的浏览器返回经gzip压缩的HTML页面,为其他浏览器返回普通页面。 |
| Content-Length | 表示内容长度。只有当浏览器使用持久HTTP连接时才需要这个数据。如果你想要利用持久连接的优势,可以把输出文档写入 ByteArrayOutputStream,完成后查看其大小,然后把该值放入Content-Length头,最后通过byteArrayStream.writeTo(response.getOutputStream()发送内容。 |
| Content-Type | 表示后面的文档属于什么MIME类型。Servlet默认为text/plain,但通常需要显式地指定为text/html。由于经常要设置Content-Type,因此HttpServletResponse提供了一个专用的方法setContentType。 |
| Date | 当前的GMT时间。你可以用setDateHeader来设置这个头以避免转换时间格式的麻烦。 |
| Expires | 应该在什么时候认为文档已经过期,从而不再缓存它? |
| Last-Modified | 文档的最后改动时间。客户可以通过If-Modified-Since请求头提供一个日期,该请求将被视为一个条件GET,只有改动时间迟于指定时间的文档才会返回,否则返回一个304(Not Modified)状态。Last-Modified也可用setDateHeader方法来设置。 |
| Location | 表示客户应当到哪里去提取文档。Location通常不是直接设置的,而是通过HttpServletResponse的sendRedirect方法,该方法同时设置状态代码为302。 |
| Refresh | 表示浏览器应该在多少时间之后刷新文档,以秒计。除了刷新当前文档之外,你还可以通过setHeader(“Refresh”, “5; URL=http://host/path”)让浏览器读取指定的页面。 注意这种功能通常是通过设置HTML页面HEAD区的<META HTTP-EQUIV=“Refresh” CONTENT=“5;URL=http://host/path">实现,这是因为,自动刷新或重定向对于那些不能使用CGI或Servlet的HTML编写者十分重要。但是,对于Servlet来说,直接设置Refresh头更加方便。 注意Refresh的意义是"N秒之后刷新本页面或访问指定页面”,而不是"每隔N秒刷新本页面或访问指定页面"。因此,连续刷新要求每次都发送一个Refresh头,而发送204状态代码则可以阻止浏览器继续刷新,不管是使用Refresh头还是<META HTTP-EQUIV=“Refresh” …>。 注意Refresh头不属于HTTP 1.1正式规范的一部分,而是一个扩展,但Netscape和IE都支持它。 |
| Server | 服务器名字。Servlet一般不设置这个值,而是由Web服务器自己设置。 |
| Set-Cookie | 设置和页面关联的Cookie。Servlet不应使用response.setHeader(“Set-Cookie”, …),而是应使用HttpServletResponse提供的专用方法addCookie。参见下文有关Cookie设置的讨论。 |
| WWW-Authenticate | 客户应该在Authorization头中提供什么类型的授权信息?在包含401(Unauthorized)状态行的应答中这个头是必需的。例如,response.setHeader(“WWW-Authenticate”, “BASIC realm=\“executives\””)。 注意Servlet一般不进行这方面的处理,而是让Web服务器的专门机制来控制受密码保护页面的访问(例如.htaccess)。 |
HTTP状态码
当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码的信息头(server header)用以响应浏览器的请求。
HTTP状态码的英文为HTTP Status Code。
下面是常见的HTTP状态码:
- 200 - 请求成功
- 301 - 资源(网页等)被永久转移到其它URL
- 404 - 请求的资源(网页等)不存在
- 500 - 内部服务器错误
HTTP状态码分类
HTTP状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。HTTP状态码共分为5种类型:
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
HTTP状态码列表:
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的 |
HTTP content-type
Content-Type(内容类型),一般是指网页中存在的 Content-Type,用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件,这就是经常看到一些 PHP 网页点击的结果却是下载一个文件或一张图片的原因。
Content-Type 标头告诉客户端实际返回的内容的内容类型。
语法格式:
Content-Type: text/html; charset=utf-8
Content-Type: multipart/form-data; boundary=something
常见的媒体格式类型如下:
- text/html : HTML格式
- text/plain :纯文本格式
- text/xml : XML格式
- image/gif :gif图片格式
- image/jpeg :jpg图片格式
- image/png:png图片格式
以application开头的媒体格式类型:
- application/xhtml+xml :XHTML格式
- application/xml: XML数据格式
- application/atom+xml :Atom XML聚合格式
- application/json: JSON数据格式
- application/pdf:pdf格式
- application/msword : Word文档格式
- application/octet-stream : 二进制流数据(如常见的文件下载)
- application/x-www-form-urlencoded : 中默认的encType,form表单数据被编码为key/value格式发送到服务器(表单默认的提交数据的格式)
另外一种常见的媒体格式是上传文件之时使用的:
-
multipart/form-data : 需要在表单中进行文件上传时,就需要使用该格式
| |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| | | |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| | | |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的 |
HTTP content-type
Content-Type(内容类型),一般是指网页中存在的 Content-Type,用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件,这就是经常看到一些 PHP 网页点击的结果却是下载一个文件或一张图片的原因。
Content-Type 标头告诉客户端实际返回的内容的内容类型。
语法格式:
Content-Type: text/html; charset=utf-8
Content-Type: multipart/form-data; boundary=something
常见的媒体格式类型如下:
- text/html : HTML格式
- text/plain :纯文本格式
- text/xml : XML格式
- image/gif :gif图片格式
- image/jpeg :jpg图片格式
- image/png:png图片格式
以application开头的媒体格式类型:
- application/xhtml+xml :XHTML格式
- application/xml: XML数据格式
- application/atom+xml :Atom XML聚合格式
- application/json: JSON数据格式
- application/pdf:pdf格式
- application/msword : Word文档格式
- application/octet-stream : 二进制流数据(如常见的文件下载)
- application/x-www-form-urlencoded : 中默认的encType,form表单数据被编码为key/value格式发送到服务器(表单默认的提交数据的格式)
另外一种常见的媒体格式是上传文件之时使用的:
- multipart/form-data : 需要在表单中进行文件上传时,就需要使用该格式