PAUL:Patch-based Discriminative Feature Learning for Unsupervised Person Re-identification阅读总结
Patch-based Discriminative Feature Learning for Unsupervised Person Re-identification
作者:Qize Yang, Hong-Xing Yu(MAR一作) 郑伟诗团队 2019 CVPR
源码:https://github.com/QizeYang/PAUL.
1.摘要:
part/patch在有监督reid中用烂了,但无监督reid中还没用过。因此作者提出基于patch的无监督网络PAUL。主要是三个部分:PatchNet提取patch,PEDAL和IPFL作为损失监督,性能不错。
2. 介绍
2.1. Motivation
作者的motivation来于实验观察,如下图:

对上图解释如下:相似的图像中必然存在相似的matched patches,而且patches之间的相似度必然远大于图像的相似度;但不是所有的matched patches都相似,因此作者要做基于patch的而不是基于图像的无监督reid。
2.2. 主体框架:
整个模型叫做patch-based unsupervised learning(PAUL),分三个部分:
- 前期是一个PatchNet网络,对输入图像学习到的feature map提取patches并为这些patches学习鉴别性特征(每个patch鉴别性特征学习单独用一条支路)
- 在PatchNet中学习的无监督图像的鉴别性patch特征(不是指patch的学习,patch的学习是PatchNet中的基于STN的PGN网络学习的)是由patch-based discriminative feature learning loss (PEDAL)损失监督指导的,其pull相似patch但push不相似patch。
- 同时,还使用image-level patch feature learning loss (IPFL)对所有patches进行图像级指导,即克服pull相似的patch对那些难负样本的负面影响,该损失是基于triplet的,triplet分别有anchor,anchor经图像变化的代理正样本,anchor用循环ranking挖掘的困难负样本组成。
2.3. 贡献:
- 第一次在无监督reid中用patch/part策略
- PAUL的有效性
3. PAUL模型
3.1. PAUL概览
在2.2中的主体框架中已介绍了大半,这里只进行补充,如图2所示:
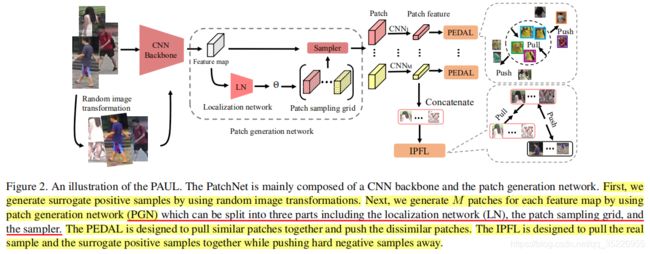
3.2. 各模块介绍
3.2.1 PatchNet
PatchNet由前端的CNN bockbone,中端的patch generation network (PGN)以及后端的多分支鉴别性特征学习网络组成。PGN是从STN改造而来,对前端CNN的feature map提取patches而非直接对原始图像提取patches(能减少计算和复杂度),其能自动捕捉M个不同的(作者用的是不同的初始化,但这显然不够,需要更好的策略保证这些patches之间少重叠和针对性—如都针对手臂,躯体而不是背景之类的,然而奇怪的是作者展示的patch学习结果却挺不错的,图6)图像patches,这些是通过localization network (LN)网络的一组仿射变换参数: 都是一个2*3的仿射变换矩阵,分别对应两个平移,两个旋转,两个尺度参数。这些参数是通过LN模块的卷进层+两个FC层学习到的,其中最后一个FC的bias参数初始化不同而带来学习不同的M个不同patches(前面说了不够),PGN经过LN后再经过patch sampling grids和the sampler两个模块就可以完整的裁减出M个patches了。然后由于M个patches分别对应M个不同的图像区域,其语义信息也不同,因此需要使用M个独立的CNN分支分别提取鉴别性patch特征,就像学习M个不同属性那样。But,这是unlabeled数据,怎么学习?作者提出了下面两种损失来进行监督。
都是一个2*3的仿射变换矩阵,分别对应两个平移,两个旋转,两个尺度参数。这些参数是通过LN模块的卷进层+两个FC层学习到的,其中最后一个FC的bias参数初始化不同而带来学习不同的M个不同patches(前面说了不够),PGN经过LN后再经过patch sampling grids和the sampler两个模块就可以完整的裁减出M个patches了。然后由于M个patches分别对应M个不同的图像区域,其语义信息也不同,因此需要使用M个独立的CNN分支分别提取鉴别性patch特征,就像学习M个不同属性那样。But,这是unlabeled数据,怎么学习?作者提出了下面两种损失来进行监督。
3.2.2 Patch-based Discriminative Feature Learning PEDAL
每个分支用一个损失函数来监督(图2patch后面的CNN部分),所有分支在形式上式一样的。

但作者指出,以上过程需要将这个batch内的每一张图像的m-th个patch的特征(以m-th patch为例说明问题,其余patch同理)和所有训练集图像的m-th个patch的特征计算相似度,根据相似度将它们pull和push,这就类似于测试过程中probe和gallery的关系,我们知道:即使是计算简单的cos相似度,这个可近似看做“度量学习”的过程也是相当耗时的;即使是优秀如KISSME和triplet的度量学习方法,也会出现probe的检索结果中rank较高的图像与probe的相似度不太高而rank较低的图像与probe的相似度很高的现象,因此这种计算相似度的过程我们其实希望只在最后的测试阶段做(2017年的PUL中就是在测试之前引入了计算相似度的过程,因此性能不算很高),而本文则脱离了这一过程,引入了和ECN类似的内存机制(这种内存机制估计是出自哪一篇文章),略有不同。作者设计了一个patch feature memory bank来存储这些patch特征,设训练集图像数量为N,存储体记为:




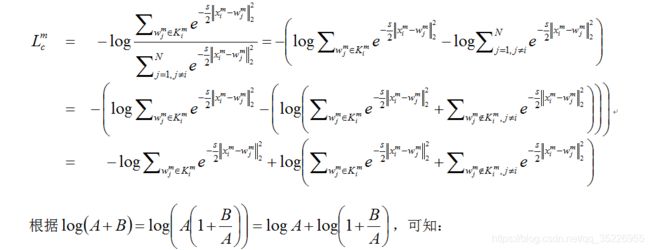
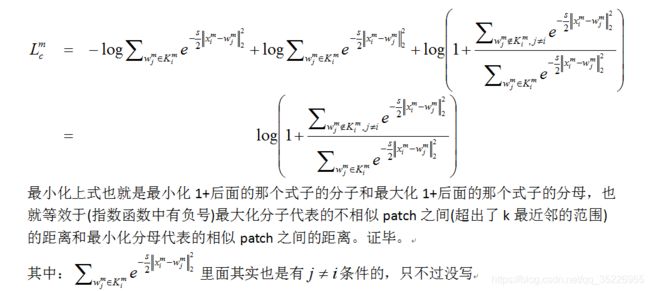
以上过程看似很普通,但却解决了几个问题: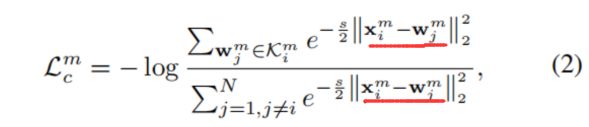
将计算相似度的过程转变为计算和存储体差异的L2范数了;而根据对式2的推导(从原始式2也不难发现)可以发现,尽管式2表面上类似于一个分类的形式,但作者没有想办法打伪标签,而是将一直以来“用分类来解决reid”的思想退还为检索问题(pull相似和push不相似),而reid正是一个检索问题,用检索的方法来做才是正道。当下的方法多数是:softmax和triplet损失联调,基于ResNet50网络的backbone去掉最后两个fc而加上一些分类的fc层,本质上没有逃离分类的圈子,而联调效果好也正是因为用分类(softmax)做reid不够,必须用基于检索的度量学习损失(triplet)才能带来性能的进一步improve。作者成功解决了这一问题。并且这种存储体结构设计和ECN一样,是一种不仅仅考虑一个batch内样本关系,而是考虑整个数据集内的样本关系的一种方法,从ECN可以看出这一策略能提点很多。
讨论:
根据图3的实验可以看出,如果直接pull视觉/外观相似的图像对而push视觉/外观不相似的图像对势必导致模型对于不同id的相似图像的鉴别力不够,如图3c所示。而如果pull视觉/外观相似的patches对而push视觉/外观不相似的patches对,如图3ab所示,可以很好的解决这一问题,虽然pull视觉/外观相似的patches也会略微导致模型对于不同id的相似图像的鉴别力不够,但id其实不是由某一个patch决定的,而是由很多patch共同决定的,因此我们还有IPFL损失来补救。即使没有,如图3a所示,我们pull了不同id的黄色T恤的上身patch,但如图3b所示,我们会因为它们下身裤子的不同而push开它们。
3.2.3. image-level patch feature learning loss (IPFL)
目的是为了进一步监督最小化类内差异并最大化类间差异,这次和监督reid一样用triplet的rank loss来监督。那triplet怎么获取?
首先要明确的是这里用的是图像级的综合信息,global,很好理解。然后anchor就是输入的图像,将该图像通过一系列图像变换如crop,scale,rotation,brightness,contrast和saturation等就得到所谓的代理正样本。而负样本则是通过循环ranking挖掘到的。
所谓循环ranking,其思想是互近邻的概念,即我在你的rank结果中,而你也在我的rank结果中,则我和你是相同id样本的概率就很大(ZhongZhun的re-ranking,2017);那反过来,我在你的rank结果中,而你不在我的rank结果中,则我和你是不同id样本的概率就很大。如下图4:

在这一块其实使用了前面说的测试之前计算相似度的问题,这一过程确实是为引入错误的(可以在测试时看rank结果的相似度就可以发现),但好在作者仅仅是为了挖一个硬负样本,就算挖错了,也很大概率是负样本而非正样本(负样本比正样本多),因此问题不大。
操作:对一张图像(query)按照测试时一样做rank,得到rank list;取top1作为新query,ranking,看query是否在新query的rank list的top-r中,不在则说明该top1是硬负样本,否则说明不是,继续;再看top2,top3,…直到找到了指定个数的硬负样本,我们这里只找一个最难的,而硬负样本的位置在query的rank list中位置越靠前,说明越hard,因此指定只挖掘一个硬负样本也就是最难的那个。
注:以上均在一个batch中进行。
找到triplet的图像后,接下来就是将这些图像通过网络得到的patch特征(s)各自concat起来就是图像特征(测试时也是取这个作为图像特征的),三个特征的三元组损失为:
3.3. 总优化目标

4. 实验
注:和MAR一样,用了MSMT打辅助预训练PatchGAN了(和MAR一个组的作品),仅这一点就提点很大
MAR传送门:MAR
4.1. 实验细节
- CNN的backbone选ImageNet上预训练的ResNet50,去掉最后的2个fc(用MSMT预训练这个过程没有完全逃出分类网络这一过程,但已标注的数据用分类网络确实强过检索(ZL,IDE)),最后一个残差块的stride改为1
- 每个分支输出的最终向量维度设置为256
- PGN用不同初始化来锁定不同区域(理论上是不够,会重叠的;但作者没有用这一点仍然学习得很好了,图6,每个patch提取基本都锁定在同一区域,且在没有高级特征指导的情况下(ZZD,PAN)仍然关注的是行人区域,其定位网络的进一步改善可能性不大)
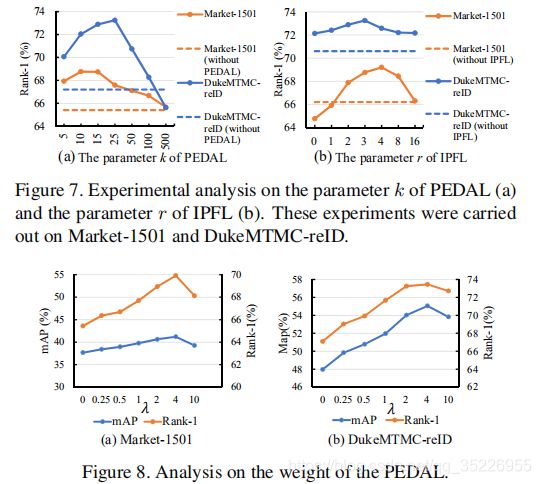
- PEDAL中的k超参取10,s超参取10/30(D/M),l更新率超参取0.1
- IPFL中r超参取3,m超参取2
- 总损失中lambda超参取2
- PatchGAN在MSMT上预训练,之后用unlabel数据训练时不再使用MSMT,并固定PGN
- 图像输入resize为384*128
- 每个batch输入40张真实图像和经过图像变化的40张代理正样本(每张图像生成一张代理正样本)
- SGD优化,lr为0.0001,每50epoch除10,60epoch结束训练
- patch特征(s)concat作为行人描述符–测试
- 获取代理正样本时的图像变化策略(每张图像变化时从下面随机选一个)
** crop:随机crop图像的70%~95%处理
** rotation:随机旋转图像10度
** contrast,brightness和saturation:随机变化原来的80%~120%
4.2. 和SOTA比较
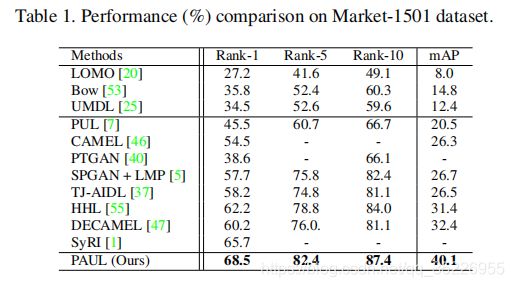

Duke上挺高的,但其实用MSMT预训练了,不算公平比较
作者说好的原因在两个方面:不同数据集之间图像存在的gap比patch存在的gap大;结构有效
4.3. 消融

第二行的结果和作者说的一致,对相似图像pull到一起会使鉴别性降低,不利
4.4 更深的分析
学习的patch的可视化:

框出来的区域对齐得很好,只进行了简单的不同初始化达到这种效果其实很厉害。
PGN:

第一栏是随机选patch,第二个是选择equal的水平stripe做patch的效果。
几个超参的影响
其他数据集上的效果

在不同数据集上预训练模型的影响
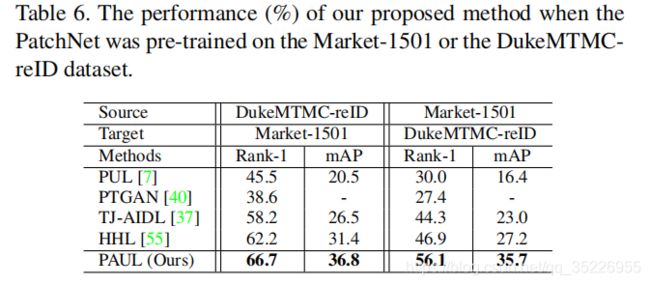
MSMT上预训练然后在Market测试的性能只有68.5%,说明模型还是很有效的,不是完全依赖于大的MSMT预训练的。在Market上预训练,Duke上测试的效果不行,只有56%,主要原因是MSMT和Duke有更多common的patch,而M和D则没有这么多common的patch