2.1 Vision-Language Pre-Training for Multimodal Aspect-Based Sentiment Analysis
Vision-Language Pre-Training for Multimodal Aspect-Based Sentiment Analysis
1、基本信息
-
作者:Yan Ling, Jianfei Yu, Rui Xia
-
会议:ACL 2022
-
单位:南京理工大学
2、主要框架
- 任务:Multimodal Aspect-Based Sentiment Analysis(MABSA)
- Multimodal Aspect Term Extraction(MATE)
- input: text-image pair
- output: aspect terms(mentioned in the text)
- Multimodal Aspect-oriented Sentiment Classification(MASC)
- input: extracted aspect term
- output: sentiment class
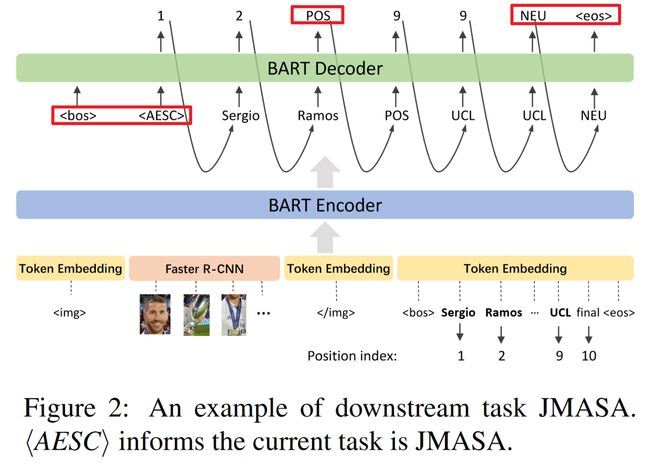
- Joint Multimodal Aspect-Sentiment Analysis(JMASA)【如下图1所示】
- input: text-image pair
- output: aspect-sentiment pairs
- Multimodal Aspect Term Extraction(MATE)

- 问题
- 现有方法要么
分别使用预训练的视觉、文本模型,忽略了模态间的对齐关系。 - 要么使用经
通用预训练任务的视觉-语言模型,不足以识别细粒度的aspect、opinion和模态间的对齐关系。
- 现有方法要么
- 方法
- A task-specific Vision-Language Pre-training framework for MABSA(VLP-MABSA)
- BART-based generative multimodal architecture
- 所有预训练任务和下游任务都可以通用的(unified)多模态encoder-decoder 架构
- 3类task-specific 预训练任务
- Language
- Masked Language Modeling(MLM)
- Textual Aspect-Opinion Extraction(AOE)
- Vision
- Masked Region Modeling(MRM)
- Visual Aspect-Opinion Generation(AOG)
- Multimodal
- Multimodal Sentiment Prediction(MSP)
- Language
- A task-specific Vision-Language Pre-training framework for MABSA(VLP-MABSA)
- 实验结果:超过SOTA
3. VLP-MABSA

模型骨干是BART,a denoising autoencoder for sequence-to-sequence models。将其扩展为同时编码文本和视觉输入,可解码不同模态的预训练任务或下游任务。
3.1. Feature Extractor
- Image Representation:用Faster R-CNN抽取的mean-pooled convolutional features作为视觉特征。
- 抽取并取置信度前36个regions,即 R = { r 1 , . . . , r 36 } R=\{r_1, ..., r_{36}\} R={r1,...,r36},并保留其semantic class distribution,记为 q ( v ) q(v) q(v)(用于MRM)。
- 每个region的视觉特征向量的维度本来是2048,即 r i ∈ R 2048 r_i \in \mathbb R^{2048} ri∈R2048,为了和文本特征一致,再用linear transformation layer投影成d维向量,即 V ∈ R d × 36 V \in \mathbb R^{d \times 36} V∈Rd×36。
- Text Representation:Embedding Matrix
- 句子分词成tokens, E = { e 1 , . . . , e T } E=\{e_1, ..., e_T \} E={e1,...,eT}记录其下标序列, T T T是文本长度。
- 从Embedding Matrix中取相应tokens的embeddings,即 W = { w 1 , . . . , w T } W=\{ w_1, ..., w_T\} W={w1,...,wT}。
3.2. BART-based Generative Framework
- Encoder:多层双向Transformer
- 在编码器的输入端,分别用 和 ,和
标识visual features,textual input的起始和结束。 
- X X X表示concatenated的多模态输入。
- 在编码器的输入端,分别用 和 ,和
- Decoder:多层单向Transformer
- 在解码端的输入端,因为所有预训练任务共享同样的解码器,为
标识不同预训练任务,分别都用两个special tokens作为解码器输入的开始。, , , 和 分别是5个预训练任务的special tokens。

- 在解码端的输入端,因为所有预训练任务共享同样的解码器,为
3.3. Pre-training Tasks
- Original dataset: MVSA-Multi
- input: image-text pairs
- output: coarse-grained sentiments

3.3.1 Textual Pre-training
-
Masked Language Modeling(MLM):对齐文本和视觉特征
-
mask的策略和BERT一样;
-
损失函数如下, X ~ \widetilde {X} X 指的是masked的拼接后的多模态输入 X X X。
L M L M = − E X ∼ D ∑ i = 1 T l o g P ( e i ∣ e < i , X ~ ) L_{MLM}=-\mathbb E_{X \sim D} \sum_{i=1}^{T} log P(e_i|e_{
-
-
Textual Aspect-Opinion Extraction(AOE):生成文本中的aspects和opinions-
数据集中不提供aspect和opinion的标注,需用其他的方法构造
监督信号。- Aspect:一个Named Entity Recognition(NER)工具中的预训练模型(2011)
- Opinion:a sentiment lexicon(SentiWordNet)(2006)
-
an index generation task:生成所有aspects和opinions的起止下标。
- target标注 Y = [ a 1 s , a 1 e , . . . , a M s , a M e , < s e p > , o 1 s , o 1 e , . . . , o N s , o N s , < e o s > ] Y=[a_1^s, a_1^e, ..., a_M^s, a_M^e,
, o_1^s, o_1^e, ..., o_N^s, o_N^s, Y=[a1s,a1e,...,aMs,aMe,<sep>,o1s,o1e,...,oNs,oNs,<eos>] ,其中 M , N M,N M,N指aspect terms 和opinion terms的数量, a s , a e a^s, a^e as,ae和 o s , o e o^s, o^e os,oe分别是每个的起止下标。、标识分割、结束。] - 例子如图所示:

- 公式流程:得到token的概率分布。
- h t d = D e c o d e r ( H e ; Y < t ) h_t^d = Decoder(H^e;Y_{
- H ‾ T e = ( W + H T e ) / 2 \overline{H}_T^e=(W+H_T^e)/2 HTe=(W+HTe)/2。一个文本一个固定的值。 H T e H_T^e HTe指 H T H_T HT对应的文本部分。
- P ( y t ) = S o f t m a x ( [ H ‾ T e ; C d ] h t d ) P(y_t)=Softmax([\overline{H}_T^e;C^d]h_t^d) P(yt)=Softmax([HTe;Cd]htd)。 C d C_d Cd指 C = [ < s e p > , < e o s > ] C=[
, C=[<sep>,<eos>]的d维embeddings。]
- h t d = D e c o d e r ( H e ; Y < t ) h_t^d = Decoder(H^e;Y_{
- 损失函数如下, O = 2 M + 2 N + 2 O=2M+2N+2 O=2M+2N+2指target标注 Y Y Y的长度。
L A O E = − E X ∼ D ∑ t = 1 O l o g P ( y t ∣ Y < t , X ) L_{AOE}=-\mathbb E_{X \sim D} \sum_{t=1}^OlogP(y_t|Y_{
- target标注 Y = [ a 1 s , a 1 e , . . . , a M s , a M e , < s e p > , o 1 s , o 1 e , . . . , o N s , o N s , < e o s > ] Y=[a_1^s, a_1^e, ..., a_M^s, a_M^e,
-
3.3.2 Visual Pre-training
用以下两个任务捕获图像中的主体和客体信息
-
Masked Region Modeling(MRM):预测masked region的semantic class distribution
-
在编码器输入端,regions以15%的概率随机被mask,相应的特征会改为零向量。
-
在解码器输入端,masked region的提示词为,其余为。
-
在解码器输出后,所有的会追加一个MLP分类器,用以预测其semantic class distribution,记为 p ( v ) p(v) p(v)。
-
损失函数:减少预测分布和target分布的KL散度。Z指masked regions的数量。
L M R M = E X ∼ D ∑ z = 1 Z D K L ( q ( v z ) ∣ ∣ p ( v z ) ) L_{MRM}= \mathbb E_{X\sim D}\sum_{z=1}^ZD_{KL}(q(v_z)||p(v_z)) LMRM=EX∼Dz=1∑ZDKL(q(vz)∣∣p(vz)) -
例子如图所示

-
-
Visual Aspect-Opinion Generation(AOG):生成图像中的aspect-opinion对-
监督信号
- Adjective-Noun Pair(ANP)(2013):如smiling man and beautiful landscape,分别能捕获细粒度的aspects 和opinions,因此将其作为图像中的aspect-opinion对。
- 用一个预训练ANP检测器DeepSentiBank(2014),预测2089个预先定义的
ANPs的类分布,概率最高的ANP作为监督信号。
-
a sequence generation task
-
G = { g 1 , . . . , g ∣ G ∣ } G=\{g_1,...,g_{|G|}\} G={g1,...,g∣G∣}指target ANP的tokens, ∣ G ∣ |G| ∣G∣指ANP tokens的数量
-
公式流程:
- h i d = D e c o d e r ( H e ; G < i ) h_i^d=Decoder(H^e;G_{
- P ( g i ) = S o f t m a x ( E T h i d ) P(g_i)=Softmax(E^Th_i^d) P(gi)=Softmax(EThid);E指词汇中所有tokens的embedding matrix。【跟之前E的定义不一样?词汇中是所有词典还是输入文本的词?】
- h i d = D e c o d e r ( H e ; G < i ) h_i^d=Decoder(H^e;G_{
-
损失函数:
L A O G = − E X ∼ D ∑ i = 1 ∣ G ∣ l o g P ( g i ∣ g < i , X ) L_{AOG}=-\mathbb E_{X\sim D}\sum_{i=1}^{|G|}logP(g_i|g_{ -
例图[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7W2DprLy-1668692099370)(C:/Users/26282/AppData/Roaming/Typora/typora-user-images/image-20221112163228101.png)]
-
-
3.3.3 Multimodal Pre-training
不像前两类预训练任务,MSP的监督信号是多模态的。识别文本和视觉的客观信息,以及他们之间的对齐关系。
-
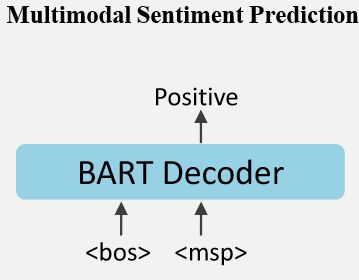
Multimodal Sentiment Prediction(MSP)-
MVSA-Multi数据集提供粗粒度的情感标签,将其作为监督信号。
-
a classification task
-
公式流程:
- h m s p d = D e c o d e r ( H e ; E m s p ) h_{msp}^d=Decoder(H^e;E_{msp}) hmspd=Decoder(He;Emsp); E m s p E_{msp} Emsp指两个special tokens相应的embeddings
- P ( s ) = S o f t m a x ( M L P ( h m s p d ) ) P(s)=Softmax(MLP(h_{msp}^d)) P(s)=Softmax(MLP(hmspd));s指相应的情感标签
-
损失函数:
L M S P = − E X ∼ D l o g P ( s ∣ X ) L_{MSP}=-\mathbb E_{X\sim D}logP(s|X) LMSP=−EX∼DlogP(s∣X) -
例图
-
-
3.3.4 Full Pre-training Loss
目标函数
L = λ 1 L M L M + λ 2 L A O E + λ 3 L M R M + λ 4 L A O G + λ 5 L M S P L=\lambda_1L_{MLM}+\lambda_2L_{AOE}+\lambda_3L_{MRM}+\lambda_4L_{AOG}+\lambda_5L_{MSP} L=λ1LMLM+λ2LAOE+λ3LMRM+λ4LAOG+λ5LMSP
3.4 Downstream Tasks
-
下游任务:MABSA的3个子任务,即Joint Multimodal Aspect-Sentiment Analysis(JMASA),Multimodal Aspect Term Extraction(MATE),和Multimodal Aspect-oriented Sentiment Classification(MASC)。
-
模型:和预训练任务一样
-
模型输出
- JMASA: Y = [ a 1 s , a 1 e , . . . , a i s , a i e , s i , . . . ] Y=[a_1^s,a_1^e,...,a_i^s,a_i^e,s_i,...] Y=[a1s,a1e,...,ais,aie,si,...], a 1 s , a i e , s i a_1^s, a_i^e,s_i a1s,aie,si分别指文本中某aspect的起止下标和情感。
- MATE: Y = [ a 1 s , a 1 e , . . . , a i s , a i e ] Y=[a_1^s,a_1^e,...,a_i^s, a_i^e] Y=[a1s,a1e,...,ais,aie]。
- MASC: Y = [ a 1 s ‾ , a 1 e ‾ , s 1 , . . . , a i s ‾ , a i e ‾ , s i , . . . ] Y=[\underline {a_1^s},\underline {a_1^e},s_1,...,\underline {a_i^s},\underline {a_i^e},s_i,...] Y=[a1s,a1e,s1,...,ais,aie,si,...],下划线表示推理时是已知的。
-
index generation tasks
- 与AOE一样的公式流程,除了special token集合 C = [ < P O S > , < N E U > , < N E G > , < E O S > ] C=[
, C=[<POS>,<NEU>,<NEG>,<EOS>]改成了感情类别。, , ] - JMASA图例
- 与AOE一样的公式流程,除了special token集合 C = [ < P O S > , < N E U > , < N E G > , < E O S > ] C=[
4. 实验
4.1 Experimental Settings
Dataset
下游数据集使用TWITTER-2015和TWITTWE-2017评估VLP-MABSA模型

4.2 对比实验
JMASA

- 从text-based methods的对比可以看出VLP-MABSA中基础模型BART的优越性
- Multimodal methods中JML采用了辅助任务来检测图像与文本的关系,超越了此前所有方法;而VLP-MABSA的F1得分比它分别高了2.5和2.0,这可以归功于3类task-specifc 预训练任务识别了aspects、opinion和模态间的对齐关系。
MATE
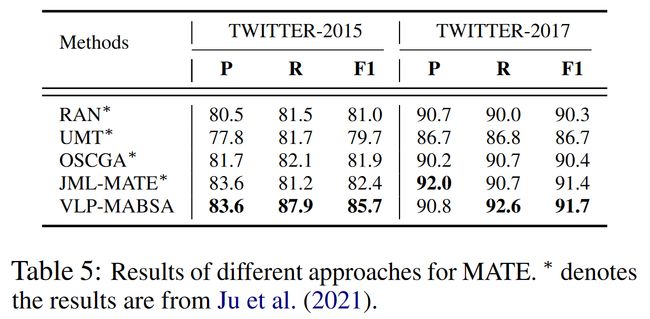
MASC

- 要注意JML只评估了正确预测的aspect的结果,而其他都是评估了所有的golden aspects。
4.3 消融实验

以weak supervision为例具体分析每个预训练任务的效果,只加入MLM、MRM提效甚微,AOE、AOG提高很明显,特别是MSP。
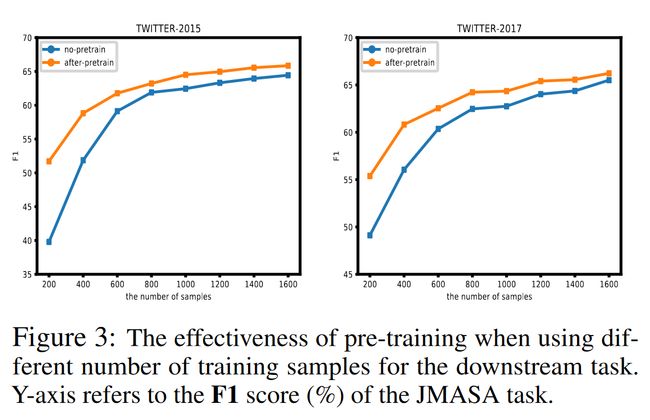
- 下游训练时的样本数量少时,预训练带来的提效比没有预训练来的高。数量多时,效果是一样的。
- 这表明预训练方法的鲁棒性和有效性,特别在数据集少的领域。
4.4 实例展示
MM是没有预训练的多模态输入的框架,VLP是预训练后的。
5.思考
- 预训练任务里加入图像与文本的关系