PyTorch加载数据集、训练网络一个完整的网络(优化)及其注意事项
【注意事项总结】
全部来源:https://blog.csdn.net/qq_43665602?type=blog感谢大佬提供灵感,大家快去关注!!!
- (一)图像尺寸有问题的,(例如通道数有3有1),先检查数据集,数据集里可能有黑白图片。再检查网络结构看是不是卷积池化这些操作导致图像尺寸发生了意想不到的变化
- (二)写测试代码,模块测试,每个完整的方法或者类写完就单独测试一下
- (三)修修改改网络后面的那部分,分类加softmax(建议加,人家自己就没加,应该不加也可以)Softmax的参数https://blog.csdn.net/qq_43665602/article/details/126576622?spm=1001.2014.3001.5502
- (四)优化函数现在常用Adam
- (五)学习率太大了,可以使用学习率衰减策略,网络开始训练希望学习率大一点,训练后期小一点。人家的已经训练的很好了,所以你做的只是微调,所以学习率可能需要小一点
- (六)网络太复杂但是数据集太简单容易过拟合
(一)、图像尺寸问题
训练神经网络时,一个epoch还没跑完,报错:
RuntimeError: stack expects each tensor to be equal size, but got [3, 224, 224] at entry 0 and [1, 224, 224] at entry 6
读入了通道数为1的图片。
解决方式:
① 检查数据集,有一个无关的黑白图片,删掉。
② 黑白图片有用的话,将黑白图片的通道数改成3通道。
在制作数据集的getitem方法里,将获取的img转成3通道。
img=img.convert("RGB")
(二)、学会写测试模块
①制作数据集
- 制作数据集的时候,要将图片和标签一一对应制作好,因为在训练的时候数据集可能会打乱。
- getitem方法是关键:获取图像和图像的label,并且torch的神经网络接收的都是tensor数据类型,需要在制作数据集的时候进行tensor数据类型的转换。返回img,label,len。将img和label都改成tensor数据类型!!!
class MyData(Dataset):
def __init__(self,root_dir,label_dir,transform=None):
'''初始化类:根据一个类创建实例。为整个class/后面的函数提供全局变量'''
'''获取图片的步骤
1、创建图片的列表:获取文件夹;获取文件夹下所有的图片root_dir
2、label:这里的label是图片上一级的名称(文件夹的名字)
'''
# self:指定了类里面的一个全局变量
#获取图片的列表和label
#a_base/dataset/train
self.root_dir=root_dir
#ants或bees,注意:文件名就是label
self.label_dir=label_dir
#将路径连接起来,就是ants或bees的路径
self.path=os.path.join(self.root_dir,self.label_dir)
#获取所有图片的地址,放在一个list里面(只是获取了所有图片的名字)
self.img_path=os.listdir(self.path)
self.transform=transform
def __getitem__(self, idx):
'''从路径获取每一张图片'''
#根据索引获取图片的名称
img_name=self.img_path[idx]
#上一步只是知道了名称。加上相对路径:加上每一张图片的路径
img_item_path=os.path.join(self.root_dir,self.label_dir,img_name) #这一步把每一个图片的路径都获取到了
#获取img:从路径打开图片
img=Image.open(img_item_path)
#img=img.convert("RGB")
#获取label
label=self.label_dir
if self.transform:
img=self.transform(img)
if label=="ants":
label=torch.tensor(1)
else:label=torch.tensor(0)
return img,label
def __len__(self):
'''返回数据集的长度:图片的数量'''
return len(self.img_path)
② 创建数据集
- 创建数据集时,调用dataset函数,在参数里写transfrom的一系列操作
'''创建数据集'''
#获取蚂蚁的训练数据集
root_dir_train= "dataset/train"
ants_label_dir_train="ants"
ants_dataset=MyData(root_dir_train,ants_label_dir_train,
transform=torchvision.transforms.Compose(
[torchvision.transforms.Resize((224,224)),
torchvision.transforms.ToTensor(),]
))
#查看第一张图片的信息
print(ants_dataset[0])
img,label=ants_dataset[0]
print("图片的信息:{},图片的label:{}".format(img,label))
print('图片的数据类型:{}'.format(type(img)))
print('label的数据类型:{}'.format(type(label)))
#查看第一张图片
#img.show()
#获取蜜蜂的训练数据集
bees_label_dir_train="bees"
bees_dataset=MyData(root_dir_train,bees_label_dir_train,
transform=torchvision.transforms.Compose(
[torchvision.transforms.Resize((224,224)),
torchvision.transforms.ToTensor(), ]
))
#获取测试集
#蚂蚁
root_dir_test="dataset/val"
ants_label_dir_test="ants"
ants_dataset_test=MyData(root_dir_test,ants_label_dir_test,
transform=torchvision.transforms.Compose(
[torchvision.transforms.Resize((224,224)),
torchvision.transforms.ToTensor(), ]
))
#蜜蜂
bees_label_dir_test="bees"
bees_dataset_test=MyData(root_dir_test,bees_label_dir_test,
transform=torchvision.transforms.Compose(
[torchvision.transforms.Resize((224,224)),
torchvision.transforms.ToTensor(), ]
))
#整个训练数据集:对象可以相加
train_dataset=ants_dataset+bees_dataset #训练集的图片
#整个测试数据集:
test_dataset=ants_dataset_test+bees_dataset_test #测试集的图片
#定义训练的设备
device=torch.device("cuda:0")
'''查看数据集的长度'''
train_data_size=len(train_dataset)
test_data_size=len(test_dataset)
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
'''利用dataloader加载数据集'''
train_dataloader=DataLoader(train_dataset,batch_size=10)
test_dataloader=DataLoader(test_dataset,batch_size=10)
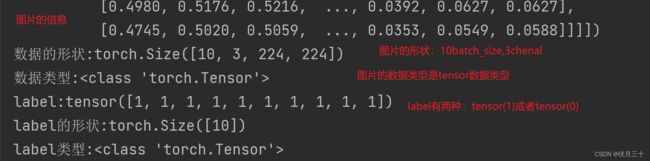
输出一下结果对不对:
可以看到img和label的数据类型均为tensor数据类型。

③ 测试数据集是否正确
- 主要看是否符合网络的输入
'''测试一下数据的形状'''
for (data,label) in train_dataloader:
print('数据:{}'.format(data))
print('数据的形状:{}'.format(data.shape))
print('数据类型:{}'.format(type(data)))
print('label:{}'.format(label))
print('label的形状:{}'.format(label.shape))
print('label类型:{}'.format(type(label)))
break
结果:为什么label的Size是10,因为此时batch_size是10。
④ 数据集没问题后准备网络
使用ResNet34预训练网络。测试的时候发现修改的网络和之前修改的网络(Resnet34)分类数都有问题!!!如何修改正确的网络看(三)修改网络。这部分只写如何测试网络。
'''3创建网络模型 resnet34 预训练的模型'''
resnet34=torchvision.models.resnet34(pretrained=True,progress=True)
resnet34.fc=nn.Sequential(
nn.Linear(resnet34.fc.in_features,resnet34.fc.out_features),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(resnet34.fc.out_features,2)
)
resnet34.add_module("Softmax",nn.Softmax(dim=None))
resnet34=resnet34.cuda()
print(resnet34)
⑤ 对网络进行测试
- 随机生成一个数据,让该数据经过网络,看结果是否符合预期,避免了直接使用数据集进行训练浪费资源。
inp_tensor=torch.randint(10,size=(1,3,244,244),dtype=torch.float32)
inp_tensor=inp_tensor.cuda()
print('输入图片的形状:{}'.format(inp_tensor))
out=resnet34(inp_tensor)
print('测试网络的输出结果:{}'.format(out))
print('测试网络输出结果的形状:{}'.format(out.shape))
⑥ 后面的步骤参见完整代码
(三)、修改网络
此处以ResNet34为例,将网络修改成分为两类的分类器。
① 查看ResNet34的网络结构
resnet34=torchvision.models.resnet34(pretrained=True,progress=True)
resnet34=resnet34.cuda()
print(resnet34)
结果:

② 对网络进行修改
- 错误案例:修改最后一个fc层再加一个fc层
'''3创建网络模型 resnet34 预训练的模型'''
resnet34=torchvision.models.resnet34(pretrained=True,progress=True)
resnet34.fc=nn.Linear(in_features=512,out_features=128)
resnet34.add_module("fc2",nn.Linear(in_features=128,out_features=2))
resnet34.add_module("softmax",nn.Softmax())
resnet34=resnet34.cuda()
print(resnet34)
结果:分类的结果还是128!!!并没有分成2。原因是必须在fc这个模块里进行修改。

- 错误案例:直接在后面加层fc层
网络模型:
resnet34=torchvision.models.resnet34(pretrained=True,progress=True)
#resnet34.fc=nn.Linear(in_features=512,out_features=2)
resnet34.add_module("fc_add",nn.Linear(in_features=1000,out_features=2))
resnet34.add_module("softmax",nn.Softmax())
resnet34=resnet34.cuda()
测试案例:
inp_tensor=torch.randint(10,size=(1,3,244,244),dtype=torch.float32)
inp_tensor=inp_tensor.cuda()
print('输入图片的形状:{}'.format(inp_tensor))
out=resnet34(inp_tensor)
print('测试网络的输出结果:{}'.format(out))
print('测试网络输出结果的形状:{}'.format(out.shape))
结果:输出的结果还是1000!!!加的out_feature=1根本没用!!!

- 正确案例:整体修改fc层
resnet34=torchvision.models.resnet34(pretrained=True,progress=True)
resnet34.fc=nn.Sequential(
nn.Linear(resnet34.fc.in_features,resnet34.fc.out_features),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(resnet34.fc.out_features,2)
)
resnet34.add_module("Softmax",nn.Softmax(dim=None))
resnet34=resnet34.cuda()
print(resnet34)
修改后的网络结构:

测试案例:
inp_tensor=torch.randint(10,size=(1,3,244,244),dtype=torch.float32)
inp_tensor=inp_tensor.cuda()
print('输入图片的形状:{}'.format(inp_tensor))
out=resnet34(inp_tensor)
print('测试网络的输出结果:{}'.format(out))
print('测试网络输出结果的形状:{}'.format(out.shape))
结果:可以看到成功的分成了两类
![]()
- 正确案例:直接将fc层的output_feature改成想要的分类数
'''3创建网络模型 resnet34 预训练的模型'''
resnet34=torchvision.models.resnet34(pretrained=True,progress=True)
#直接修改全连接层
resnet34.fc=nn.Linear(in_features=512,out_features=2)
#加入softmax层输出的就是一个概率值
#resnet34.add_module("softmax",nn.Softmax())
resnet34=resnet34.cuda()
print(resnet34)
效果一般般。。。
(三一)、之前修改网络模型遇到的一些错误
- Resnet34只给fc层后有加了一层fc,以为是10分类模型其实是1000分类模型,乌鱼子。。。注意Resnet修改要修改整个fc模块。
- VGG16添加一个线性层也是要添加到模块里面去。
要点就是要将线性层加到模块里面去!!!
vgg16_t=torchvision.models.vgg16(pretrained=True,progress=True)
vgg16_t.classifier.add_module("7",nn.Linear(1000,10))
vgg16_t=vgg16_t.to(device)
print(vgg16_t)
将模型打印出来:
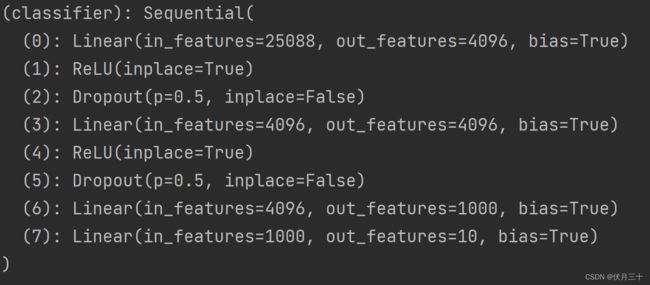
测试:分成了10类。

- 在同样的条件下,VGG16的网络效果要比ResNet34好。
VGG16的效果:

Resnet34的效果:
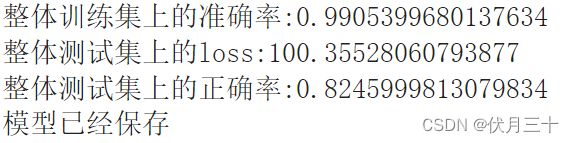
原因可能是过拟合(在训练集上的效果好,在测试集上的效果差,泛化能力差)了,或者参数选择,模型太大等等。。。
(四)、优化函数的选择问题
参见:https://blog.csdn.net/shanglianlm/article/details/85019633
(五)、学习率衰减策略
网络训练初期希望学习率大一点,后期希望学习率小一点,可以使用学习率衰减策略。
参见:https://blog.csdn.net/qq_43665602/article/details/126981783?spm=1001.2014.3001.5502
(六)、网络太复杂数据集太简单容易过拟合
- 使用dropot丢失一些神经元防止过拟合
- 使用大型模型的一小部分
完整代码:
# function:将数据加载进来后进行分类
from torch.utils.data import Dataset
from PIL import Image
import os
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
#继承Dataset类
#在Dataset里就要进行图片数据类型的转换
class MyData(Dataset):
def __init__(self,root_dir,label_dir,transform=None):
'''初始化类:根据一个类创建实例。为整个class/后面的函数提供全局变量'''
'''获取图片的步骤
1、创建图片的列表:获取文件夹;获取文件夹下所有的图片root_dir
2、label:这里的label是图片上一级的名称(文件夹的名字)
'''
# self:指定了类里面的一个全局变量
#获取图片的列表和label
#a_base/dataset/train
self.root_dir=root_dir
#ants或bees,注意:文件名就是label
self.label_dir=label_dir
#将路径连接起来,就是ants或bees的路径
self.path=os.path.join(self.root_dir,self.label_dir)
#获取所有图片的地址,放在一个list里面(只是获取了所有图片的名字)
self.img_path=os.listdir(self.path)
self.transform=transform
def __getitem__(self, idx):
'''从路径获取每一张图片'''
#根据索引获取图片的名称
img_name=self.img_path[idx]
#上一步只是知道了名称。加上相对路径:加上每一张图片的路径
img_item_path=os.path.join(self.root_dir,self.label_dir,img_name) #这一步把每一个图片的路径都获取到了
#获取img:从路径打开图片
img=Image.open(img_item_path)
#img=img.convert("RGB")
#获取label
label=self.label_dir
if self.transform:
img=self.transform(img)
if label=="ants":
label=torch.tensor(1)
else:label=torch.tensor(0)
return img,label
def __len__(self):
'''返回数据集的长度:图片的数量'''
return len(self.img_path)
'''创建数据集'''
#获取蚂蚁的训练数据集
root_dir_train= "dataset/train"
ants_label_dir_train="ants"
ants_dataset=MyData(root_dir_train,ants_label_dir_train,
transform=torchvision.transforms.Compose(
[torchvision.transforms.Resize((224,224)),
torchvision.transforms.ToTensor(),]
))
#查看第一张图片的信息
print(ants_dataset[0])
img,label=ants_dataset[0]
print("图片的信息:{},图片的label:{}".format(img,label))
print('图片的数据类型:{}'.format(type(img)))
print('label的数据类型:{}'.format(type(label)))
#查看第一张图片
#img.show()
#获取蜜蜂的训练数据集
bees_label_dir_train="bees"
bees_dataset=MyData(root_dir_train,bees_label_dir_train,
transform=torchvision.transforms.Compose(
[torchvision.transforms.Resize((224,224)),
torchvision.transforms.ToTensor(), ]
))
#获取测试集
#蚂蚁
root_dir_test="dataset/val"
ants_label_dir_test="ants"
ants_dataset_test=MyData(root_dir_test,ants_label_dir_test,
transform=torchvision.transforms.Compose(
[torchvision.transforms.Resize((224,224)),
torchvision.transforms.ToTensor(), ]
))
#蜜蜂
bees_label_dir_test="bees"
bees_dataset_test=MyData(root_dir_test,bees_label_dir_test,
transform=torchvision.transforms.Compose(
[torchvision.transforms.Resize((224,224)),
torchvision.transforms.ToTensor(), ]
))
#整个训练数据集:对象可以相加
train_dataset=ants_dataset+bees_dataset #训练集的图片
#整个测试数据集:
test_dataset=ants_dataset_test+bees_dataset_test #测试集的图片
#定义训练的设备
device=torch.device("cuda:0")
'''查看数据集的长度'''
train_data_size=len(train_dataset)
test_data_size=len(test_dataset)
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
'''利用dataloader加载数据集'''
train_dataloader=DataLoader(train_dataset,batch_size=10,shuffle=True)
test_dataloader=DataLoader(test_dataset,batch_size=10,shuffle=True)
# for batch,(img,label) in enumerate(train_dataloader):
# channels=img.shape[1]
# if channels==1:
# print(batch)
# img=torch.permute(img[0],dims=(1,2,0))
# plt.imshow(img,cmap='gray')
# plt.show()
'''3创建网络模型 resnet34 预训练的模型'''
resnet34=torchvision.models.resnet34(pretrained=True,progress=True)
resnet34.fc=nn.Sequential(
nn.Linear(resnet34.fc.in_features,resnet34.fc.out_features),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(resnet34.fc.out_features,2)
)
resnet34.add_module("Softmax",nn.Softmax(dim=None))
resnet34=resnet34.cuda()
print(resnet34)
'''4创建损失函数'''
loss_fn = nn.CrossEntropyLoss()
loss_fn=loss_fn.cuda()
'''5优化器'''
learning_rate = 1e-4 # 学习率
optimizer = torch.optim.Adam(resnet34.parameters(), learning_rate, )
'''6设置训练啊网络的一些参数'''
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 记录训练的轮数 第七轮开始往后精度不在上升
for i in range(epoch):
print("-----------------第{}轮训练开始:------------------".format(i))
'''训练步骤开始'''
resnet34.train()
total_train_accuracy=0 #训练集的正确个数
for data in train_dataloader:
imgs, targets = data # 取数据
imgs=imgs.cuda()
targets=targets.cuda()
outputs = resnet34(imgs) # 送入神经网络模型
loss = loss_fn(outputs, targets) # 计算误差
'''训练一次:优化器优化模型'''
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 对参数进行优化
total_train_step = total_train_step + 1
print("在训练集上的训练次数:{},loss:{}".format(total_train_step, loss.item())) # 例如.item()可以把一个tensor数据类型转换成真实的数字
train_accuracy = (outputs.argmax(1) == targets).sum() # outputs.argmax(1)==targets 预测结果和标签值相同的求和
total_train_accuracy = total_train_accuracy + train_accuracy
#整体训练集的准确率
print("整体训练集上的准确率:{}".format(total_train_accuracy/train_data_size))
'''训练完一轮后,在测试数据集上进行测试,看是否需要终止训练'''
'''测试步骤'''
resnet34.eval()
total_test_loss = 0
total_accuracy = 0 # 整体正确的个数
with torch.no_grad(): # 没有梯度
for data in test_dataloader:
imgs, targets = data
imgs=imgs.cuda()
targets=targets.cuda()
outputs = resnet34(imgs)
loss = loss_fn(outputs, targets) # loss是一部分loss
total_test_loss = loss.item() + total_test_loss # 整体loss
# 指标
accuracy = (outputs.argmax(1) == targets).sum() # outputs.argmax(1)==targets 预测结果和标签值相同的求和
total_accuracy = total_accuracy + accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
total_test_step = total_test_step + 1
'''保存模型'''
#torch.save(resnet34, "resnet34_t_{}.pth".format(i)) # 将每一轮训练的结果都保存一下
#print("模型已经保存")
在小蜜蜂分类上的效果哈行~

待定的问题
CIFAR10模型上效果较差,使用学习率衰减策略试一下
前期的图像处理问题
冻结一部分参数,修改网络的一部分参数