《李宏毅2022机器学习》HW1 记录
文章目录
- 任务描述
- 一、特征选择(Feature selection)
- 二、调整网络结构和优化器
-
- 1. 增加神经元和隐藏层
- 2. L2正则化及调参
任务描述


现已成功跑完sample 样例代码,结果如下:
并生成了预测的csv文件,但是放在kaggle上得分是1.8几,现需要调节模型及代码以得到更好的结果。
一、特征选择(Feature selection)
通过观察数据知道影响是否为阳性的有38+15个特征,前38位为id及one-hot表示地点的feature。

通过相关系数找出与tested_postive相关的特征,tested_postive也就是要预测的属性。
代码为:
df = pd.read_csv('./covid.train_new.csv')
df.head()
# df.describe()
result=df.corr(method='spearman')['tested_positive'].sort_values(ascending=False)
# 将相关系数大于0.8的特征提取出来
result = result.loc[abs(result)>0.8]
print(result)
结果如下:
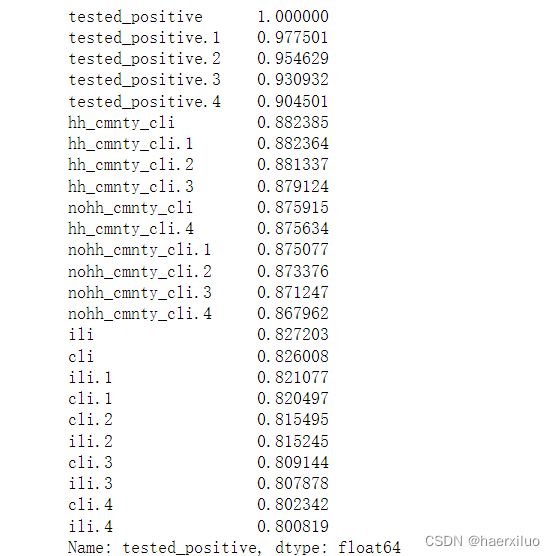
将tested_positive,hh_cmnty_cli,nohh_cmnty_cli,ili,cli 五个标签组选出。在上课视频中也提到过,后面四个标签正好是新冠检测指标。并且加上前面one-hot表示的地区特征,记得要去掉第一列id。
# 更改select_all 和 else中的feature,这里的特征选择考虑回归预测的实际情况
def select_feat(train_data, valid_data, test_data, select_all=True):
'''Selects useful features to perform regression'''
y_train, y_valid = train_data[:,-1], valid_data[:,-1]
raw_x_train, raw_x_valid, raw_x_test = train_data[:,:-1], valid_data[:,:-1], test_data
if select_all:
feat_idx = list(range(raw_x_train.shape[1]))
print(raw_x_train.shape[1])
else:
# feat_idx = [0,1,2,3,4] # TODO: Select suitable feature columns.
feat_idx = list(range(1,38))+[38,39,40,41,53,54,55,56,57, 69,70,71,72,73, 85,86,87,88,89, 101,102,103,104,105]
return raw_x_train[:,feat_idx], raw_x_valid[:,feat_idx], raw_x_test[:,feat_idx], y_train, y_valid
注意还需要在config中将select_all改为False
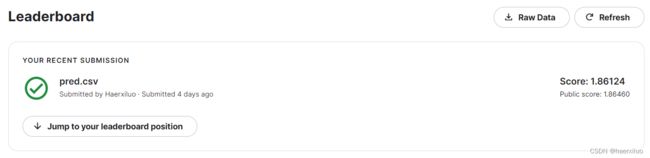
再次提交后:

分数大幅提高达到了strong baseline,但还是未达到boss baseline。
二、调整网络结构和优化器
1. 增加神经元和隐藏层
class My_Model(nn.Module):
def __init__(self, input_dim):
super(My_Model, self).__init__()
# TODO: modify model's structure, be aware of dimensions. 修改网络结构
self.layers = nn.Sequential(
nn.Linear(input_dim, 64),
nn.ReLU(),
nn.Linear(64, 8),
nn.ReLU(),
nn.Linear(8, 4),
nn.ReLU(),
nn.Linear(4, 1)
)
def forward(self, x):
x = self.layers(x)
x = x.squeeze(1) # (B, 1) -> (B)
return x
device = 'cuda' if torch.cuda.is_available() else 'cpu'
config = {
'seed': 5201314, # Your seed number, you can pick your lucky number. :)
'select_all': False, # Whether to use all features.
'valid_ratio': 0.2, # validation_size = train_size * valid_ratio
'n_epochs': 3000, # Number of epochs.
'batch_size': 128, #初始是256
'learning_rate': 1e-5, # 初始是1e-5
'early_stop': 400, #f model has not improved for this many consecutive epochs, stop training.
'save_path': './models/model.ckpt' # Your model will be saved here.
}
得出结果分数更好了一点:

2. L2正则化及调参
Pytorch中做L2正则化只需在optimizer中设置weight_decay
代码如下:
def trainer(train_loader, valid_loader, model, config, device):
criterion = nn.MSELoss(reduction='mean') # Define your loss function, do not modify this.
# Define your optimization algorithm.
# TODO: Please check https://pytorch.org/docs/stable/optim.html to get more available algorithms.
# TODO: L2 regularization (optimizer(weight decay...) or implement by your self).
# optimizer = torch.optim.SGD(model.parameters(), lr=config['learning_rate'], momentum=0.90) #初始设置
# 带动量的随机梯度下降 SGDM 并设置L2正则化
optimizer = torch.optim.SGD(model.parameters(), lr=config['learning_rate'], momentum=0.95,weight_decay=0.001)
# optimizer = torch.optim.AdamW(model.parameters(), lr=config['learning_rate'], weight_decay=0.08)
# optimizer = torch.optim.Adam(model.parameters(),lr=config['learning_rate'])
writer = SummaryWriter() # Writer of tensoboard.
if not os.path.isdir('./models'):
os.mkdir('./models') # Create directory of saving models.
n_epochs, best_loss, step, early_stop_count = config['n_epochs'], math.inf, 0, 0
for epoch in range(n_epochs):
model.train() # Set your model to train mode.
loss_record = []
# tqdm is a package to visualize your training progress.
train_pbar = tqdm(train_loader, position=0, leave=True)
for x, y in train_pbar:
optimizer.zero_grad() # Set gradient to zero.
x, y = x.to(device), y.to(device) # Move your data to device.
pred = model(x)
loss = criterion(pred, y)
loss.backward() # Compute gradient(backpropagation).
optimizer.step() # Update parameters.
step += 1
loss_record.append(loss.detach().item())
# Display current epoch number and loss on tqdm progress bar.
train_pbar.set_description(f'Epoch [{epoch+1}/{n_epochs}]')
train_pbar.set_postfix({'loss': loss.detach().item()})
mean_train_loss = sum(loss_record)/len(loss_record)
writer.add_scalar('Loss/train', mean_train_loss, step)
model.eval() # Set your model to evaluation mode.
loss_record = []
for x, y in valid_loader:
x, y = x.to(device), y.to(device)
with torch.no_grad():
pred = model(x)
loss = criterion(pred, y)
loss_record.append(loss.item())
mean_valid_loss = sum(loss_record)/len(loss_record)
print(f'Epoch [{epoch+1}/{n_epochs}]: Train loss: {mean_train_loss:.4f}, Valid loss: {mean_valid_loss:.4f}')
writer.add_scalar('Loss/valid', mean_valid_loss, step)
if mean_valid_loss < best_loss:
best_loss = mean_valid_loss
torch.save(model.state_dict(), config['save_path']) # Save your best model
print('Saving model with loss {:.3f}...'.format(best_loss))
early_stop_count = 0
else:
early_stop_count += 1
if early_stop_count >= config['early_stop']:
print('\nModel is not improving, so we halt the training session.')
return
最终结果为:

仍然没有达到boss baseline。。。后续再继续优化