NLP项目实战—京东健康智能分诊文本分类项目
文章目录
-
-
- 引言
- 一、项目的描述与目标
- 二、项目框架
- 三、文本预处理与特征工程
-
- 1. 文本预处理
- 2. 特征工程
-
- 2.1 基于词向量的特征工程
- 2.2 基于人工定义的特征
- 四、三个任务
-
- 1.project1
- 2.project2
- 3. project3
-
项目环境配置如下:
- jieba 0.42.1
- lightgbm 3.2.1
- scikit-learn 0.24.2
- scikit-multilearn 0.2.0
- gensim 3.8.3
引言
“看病慢看病难”早已成为当今社会的常见现象,因此随着技术的发展,Al+医疗是目前最有潜力的应用场景之一,其中一个很大的痛点是很多人不清楚应该去哪个科室看病。互联网医生服务可以构建医生与患者之间的桥梁,京东通过智能分诊项目,可以根据用户提供的文字型的病情描述精准识别,并自动帮助用户判断需要去哪个分诊科室,有效减少在线问诊被反复多次转接的情况发生,提高科室分配的准确度,实现降本增效。
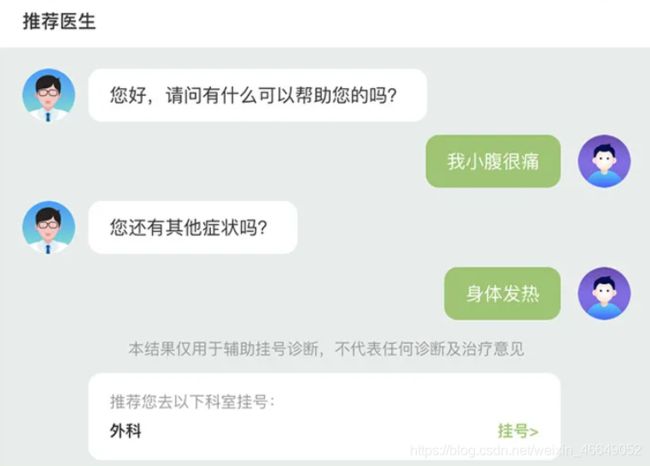
这是一个经典的文本多分类项目。通过这个项目,可以扎实地掌握文本领域的相关技术如文本预处理、特征工程、词向量、分类模型、评价指标、模型部署等,并且通过完成一个完整的项目走完所有的必要流程。从技术的角度会涉及到tf-idf,word2vec,BERT向量,N-gram,FastText,TextCNN,SkipGram,CBOW,随机森林,XGBoost,Adagrad,Adam等技术和Flask,Docker,Jenkins等部署工具的使用。
一、项目的描述与目标
文本分类作为自然语言处理领域最经典的技术之一,有着非常广泛的应用,如情感分析、情绪识别、主题分类等。文本分类任务通常分为两大类,单标签分类任务和多标签分类任务。单标签分类任务指的是对于一个输入文本,我们需要输出其中的一个类别。举个例子,我们把每一篇新闻分类成一个主题(如体育或者娱乐)。相反,多标签分类任务指的是对于一个输入文本,输出的类别有多个,如对应一篇新闻可以同时输出多个类别:体育、娱乐和音乐。其中,单标签任务又可以分为二元(binary)分类和多类别分类,二元分类指的是只有两种不同的类别。
在本项目中,我们主要来解决文本单标签的任务。数据源来自于京东健康,任务是基于患者的病情描述,自动给一个门诊科室的分类。
通过本项目的练习,你能通晓机器学习建模的各个流程:
- 文本的清洗和预处理:这是所有 NLP 项目的前提,或多或少都会用到相关的技术。
- 文本特征提取:任何建模环节都需要特征提取的过程,你将会学到如何使用 tfidf、常用的词向量 、FastText 等技术来设计文本特征。
- 模型搭建:在这里你将会学到如何使用各类经典的机器学习分类模型来搭建算法,其中也会涉及到各种调参等技术。除此之外,处理样本不均衡也是一个非常现实且具有挑战的问题。
- 模型的部署:工作的最后一般都会涉及到模型的部署,在这里你将会学到如何使用 Flask 等工具来部署模型。
同时,通过本项目,你可以
- 熟练掌握分词, 过滤停止词等技术
- 熟练掌握训练、使用 tfidf、word2vec、fasttext 模型
- 熟练掌握训练 Xgboost、lightgbm 模型, 以及常用评价指标, 并熟练掌握 GridSearch 调参方法
- 熟练掌握使用 Flask 部署模型
- 了解如何处理不均衡分类问题
- 了解如何获取词性、命名实体识别结果
- 了解如何使用 Resnet、Bert、Xlnet 等预训练模型获取 embedding
- 了解深度学习模型代码架构
在本项目中,我们使用的是京东健康的分诊数据。互联网医生服务可以构建医生与患者之间的桥梁,京东通过智能分诊项目,可以根据用户提供的文字型的病情描述精准识别,并自动帮助用户判断需要去哪个分诊科室,有效减少在线问诊被反复多次转接的情况发生,提高科室分配的准确度,实现降本增效。
本项目我们主要使用 28000 多条样本数据来训练文本分类模型,1580条样本数据为验证集,1580条样本数据为测试集。
二、项目框架
一般的AI 项目流程可分为数据预处理、文本特征工程、建模和调参、评估以及部署构成。京东健康智能分诊项目的框架为:
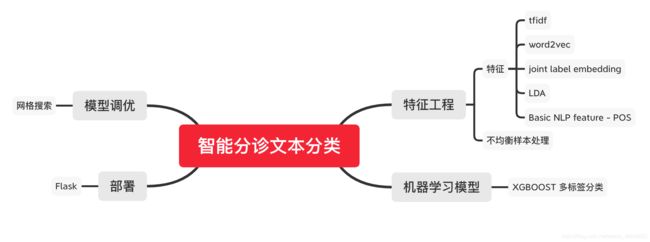
- 特征工程:对于文本的特征,在本项目中需要使用 tf-idf ,经典的预训练词向量(FastText, BERT)以及人工抽取的一些特征如 单词的词性、实体类别等。
• 模型:在训练过程中,你将有机会尝试使用各类经典的机器学习模型以及深度学习模型。
• 调参:对于模型的调参环节,我们选择使用网格搜索和贝叶斯优化搜索算法。后者相比前者可以缩小搜索空间,但同时也会增加每次的搜索代价。
• 分析:评估模型的好坏通常都需要一个标准如准确率或者F1-Score。
三、文本预处理与特征工程
1. 文本预处理
- 对文本进行清洗和预处理,
2. 特征工程
对于特征工程,我们做了如下两方面提取的操作:
2.1 基于词向量的特征工程
基于词向量的特征工程主要包括以下几个方面:
- 基于 Word2vec 或者 FastText 的词嵌入求出某个词向量的最大值和平均值,并把它们作为样本新的特征。
- 在样本表示中融合 Bert,XLNet 等预训练模型的 embedding。
- 由于之前抽取的特征并没有考虑词与词之间交互对模型的影响,对于分类模型来说,贡献最大的不一定是整个句子,可能是句子中的一部分,如短语、词组等等。在此基础上我们使用大小不同的滑动窗口(k=[2, 3, 4]),然后进行平均或取最大操作。
- 在样本表示融合样本在自动编码器(AutoEncoder)模型产生的Latent features。
- 在样本表示融合样本在 LDA 模型产生的 Topic features。
- 将 Word2Vec、Fasttext 词向量求和或取最大值
- 由于没有考虑类别的信息,因此我们从训练好的模型中获取到所有类别的 embedding,与输入的 word embedding 矩阵相乘,对其结果进行softmax 运算,对 attention score 与输入的 word embedding 相乘的结果求平均或者取最大。
特征工程示意图如下:
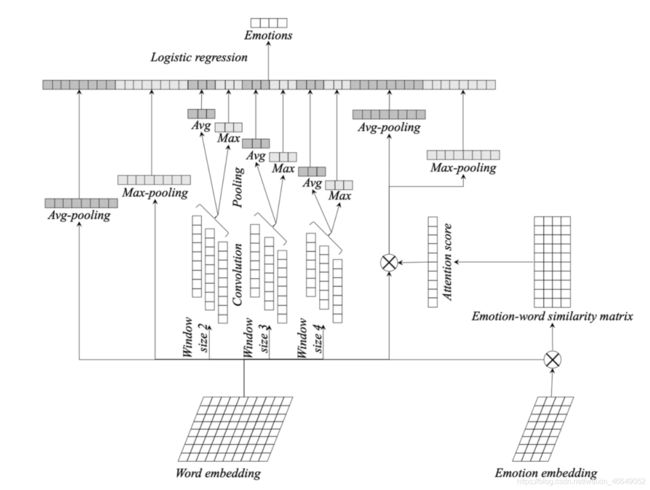
示例:
如 input 为: " 以前经常吃多了胃部会不舒服", 分词后结果假设为:” 以前 经常 吃 多 了 胃部 会 不 舒服”, 共计 9 个词。匹配我们已经训练好的embedding, 得到 9 * 300 维的向量。因为 input 的句子长短是不一样的, 所以为了保证输入到模型的维度是相同的, 有两种方法:
- 将长度的维度消去;
- 将所以文本的的长度补至一样长。
第二种方法, 会增加不必要的计算量, 所以在此我们选择使用第一种方法。使用 avg, max 的方法聚合, 得到 300 维的向量。接下来我们使用类似 n-gram 的方法来获取词组, 短语级别的信息。如我们只考虑前面一个词, 得到结果为: ” 以前经常经常吃吃多多了了胃部胃部会会不不舒服”, 8 * 300 或 8 * 2 * 300 维的向量。同样的方法我们将表示长度的维度消去 (由于我们分别考虑前面 2 个词、3 个词、4 个词,所以维度也是相同的, 可以不用消去,而是将 2 * 300 转成 1 * 600 的向量, 与其他特征拼接)。由于我们的模型没有利用到 label 信息, label 词大多出现在我们的数据集中, 我们考虑使用输入与 label 的相似程度来加权聚合我们的词向量。首先,输入 embedding(假设 9 * 300) 与标签 embedding (假设 300 * 1) 进行矩阵乘法, 得到 (9 * 1) 的矩阵。然后使用 avg、max、softmax 等聚合方法消去标签的维度, 其结果与输入 embedding 进行点乘, 并对得到加权后的结果聚合。将所有特征拼接至一起, 输入至 Xgboost/lightgbm 模型训练
2.2 基于人工定义的特征
基于人工定义的特征包括以下几个方面:
- 考虑样本中词的词性,比如句子中各种词性 (名词,动词)的个数,从而使得构造的样本表示具有多样性,从而提高模型的分类精度。
- 通过命名实体识别的技术来识别样本中是否存在地名,是否包含人名等,可以将这些特征加入到样本特征中。
在本案例中加入了词的个数,大写个数统计,大写占比,感叹号的个数,问号个数,标点符号个数,*&$%字符的个数,唯一词的个数,唯一词 与总词数的比例,获取名词, 形容词, 动词的个数,名词占词的个数的比率,形容词占词的个数的比率,动词占词的个数的比率,首字母大写其他小写的个数,平均词的个数等特征
四、三个任务
1.project1
-
对文本进行清洗和预处理,熟悉项目数据
预处理的主要目标:减少编码的稀疏性
去停用词:减少编码的稀疏性,尽量避免学到无意义的信息
大小写转换
编码统一
标点符号处理:在BERT预训练模型中,认为标点符号是有意义的
分词 jieba的使用:中文常用 -
对数据进行特征工程,学会特征工程的融合
训练词向量,Gensim的使用
人工定义特征

-
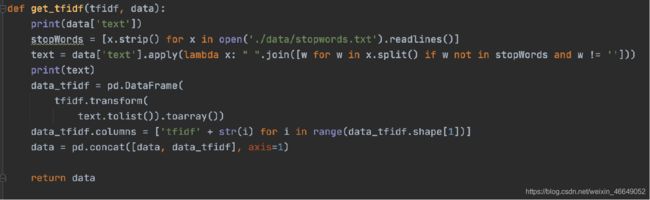
TFIDF

-
word2vec

-
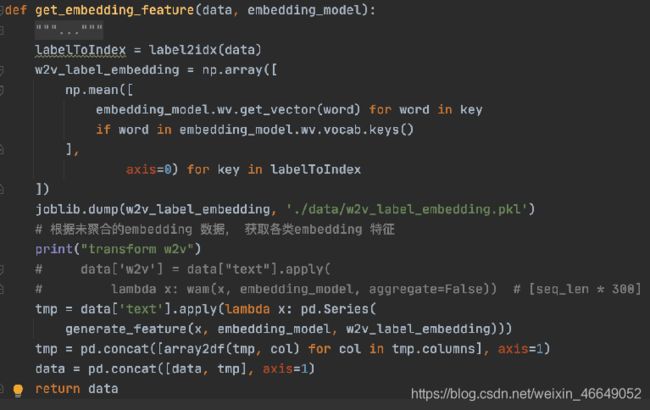
获取标签空间的词嵌入
-
LDA主题特征

def get_lda_features(data, LDAmodel): """ 获取lda特征 :param data: 数据 :param LDAmodel:lda模型 :return: """ # isinstance()函数来判断一个对象是否是一个已知的类型 if isinstance(data.iloc[0]['text'], str): # 以空格为分隔符进行分割 data['text'] = data['text'].apply(lambda x: x.split()) # 将文档转换为单词袋(BoW)格式= (token_id, token_count)元组的列表 data['bow'] = data['text'].apply( lambda x: LDAmodel.id2word.doc2bow(x)) # 得到每个主题在文档中所占的比例 data['lda'] = list( map(lambda doc: get_lda_features_helper(LDAmodel, doc), data['bow'])) cols = [x for x in data.columns if x not in ['lda', 'bow']] # 返回拼接后的lda特征 return pd.concat([data[cols], array2df(data, 'lda')], axis=1) -
POS

-
基础统计特征
def get_basic_feature_helper(text): ''' 得到基本的特征: 词的个数,大写个数统计,大写占比,感叹号的个数 @param {type} df, dataframe @return: df, dataframe ''' # 如果test是字符串,则进行分割 if isinstance(text, str): text = text.split() # 分词 queryCut = [i if i not in ch2en.keys() else ch2en[i] for i in text] # 词的个数 num_words = len(queryCut) # 大写的个数 capitals = sum(1 for c in queryCut if c.isupper()) # 大写的占比 caps_vs_length = capitals / num_words # 感叹号的个数 num_exclamation_marks = queryCut.count('!') # 问号个数 num_question_marks = queryCut.count('?') # 标点符号个数 # string.punctuation:标点符号 num_punctuation = sum(queryCut.count(w) for w in string.punctuation) # *&$%字符的个数 num_symbols = sum(queryCut.count(w) for w in '*&$%') # 唯一词的个数 num_unique_words = len(set(w for w in queryCut)) # 唯一词 与总词数的比例 words_vs_unique = num_unique_words / num_words # 获取名词, 形容词, 动词的个数, 使用tag_part_of_speech函数 nouns, adjectives, verbs = tag_part_of_speech("".join(text)) # 名词占词的个数的比率 nouns_vs_length = nouns / num_words # 形容词占词的个数的比率 adjectives_vs_length = adjectives / num_words # 动词占词的个数的比率 verbs_vs_length = verbs / num_words # 首字母大写其他小写的个数 count_words_title = len([w for w in queryCut if w.istitle()]) # 平均词的个数 mean_word_len = np.mean([len(w) for w in queryCut]) return { 'num_words': num_words, 'capitals': capitals, 'caps_vs_length': caps_vs_length, 'num_exclamation_marks': num_exclamation_marks, 'num_question_marks': num_question_marks, 'num_punctuation': num_punctuation, 'num_symbols': num_symbols, 'num_unique_words': num_unique_words, 'words_vs_unique': words_vs_unique, 'nouns': nouns, 'adjectives': adjectives, 'verbs': verbs, 'nouns_vs_length': nouns_vs_length, 'adjectives_vs_length': adjectives_vs_length, 'verbs_vs_length': verbs_vs_length, 'count_words_title': count_words_title, 'mean_word_len': mean_word_len } def get_basic_feature(data): """ 得到基础特征 :param data: 数据 :return: 返回基础特征 """ tmp = data['text'].apply( lambda x: pd.Series(get_basic_feature_helper(x))) return pd.concat([data, tmp], axis=1)
-
-
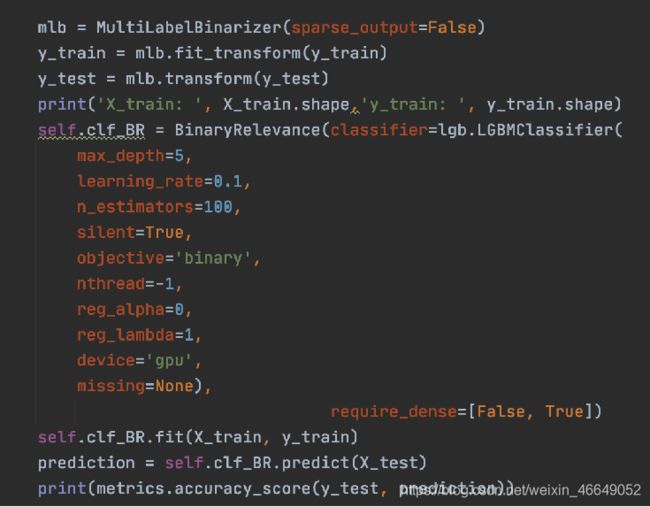
建立机器学习模型,利用xgboost/lightgbm进行多标签分类,建立baseline结果
采用多标签是因为下游任务的需要
-
熟练掌握使用 Flask 部署模型,跑通流程。


数据代码链接:JD智能分诊文本分类项目
2.project2
-
对任务一结果进行优化, 处理不均衡分类问题。
模型优化:-
Gridsearch
GridSearchCV的名字其实可以拆分为两部分,GridSearch和CV,即网格搜索和交叉验证。这两个名字都非常好理解。网格搜索,搜索的是参数,即在指定的参数范围内,按步长依次调整参数,利用调整的参数训练学习器,从所有的参数中找到在验证集上精度最高的参数,这其实是一个训练和比较的过程。原始数据集划分成训练集和测试集以后,其中测试集除了用作调整参数,也用来测量模型的好坏;这样做导致最终的评分结果比实际效果要好。(因为测试集在调参过程中,送到了模型里,而我们的目的是将训练模型应用在unseen data上)


-
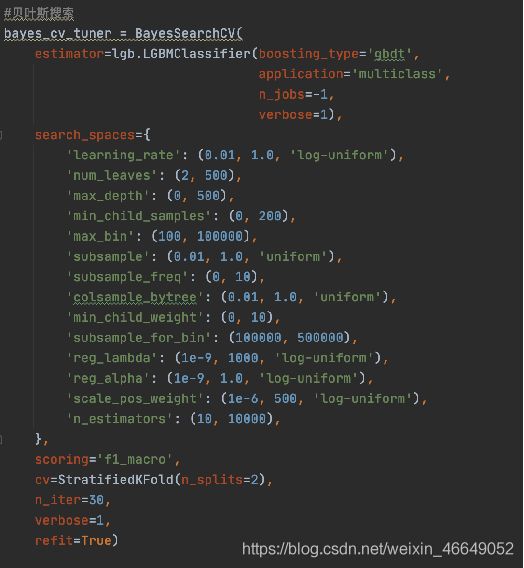
Bayselam optimization
他的适用场景一般有两个特点:
1)需要优化的function计算起来非常费时费力,比如上面提到的神经网络的超参问题,每一次训练神经网络都是燃烧好多GPU的;
2)你要优化的function没有导数信息。
有一些特殊的问题结构也会影响BO的效果。需要调的参数太多,BO处理的参数维度一般默认是在20维以内;参数里面有太多discrete parameter
数据不平衡处理:imblearn 方便又好用的不平衡数据处理库
-
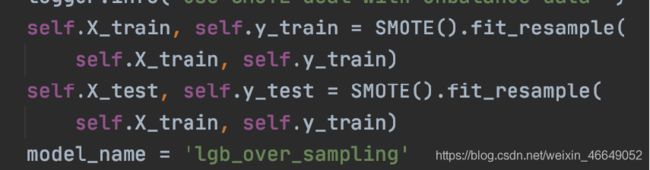
SMOTE(上采样)
SMOTE和ADASYN通过插值产生新的样本
-
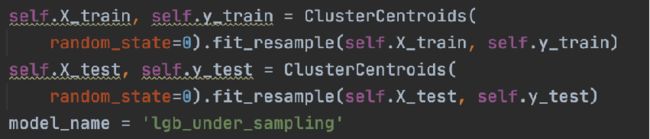
ClusterCentroids(下采样)
ClusterCentroids 利用K-means来减少样本的数量。因此,每个类的合成都将以K-means方法的中心点来代替原始样本。
-
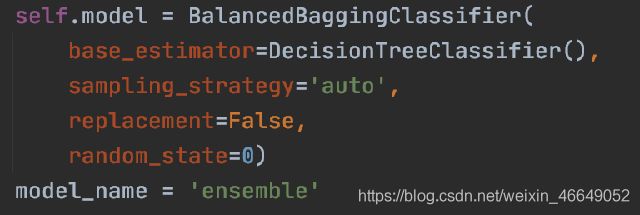
BalancedBaggingClassifier(ensemble)
在集成分类器中,bagging方法是在不同的随机选择数据子集上建立多个估计器。在scikit-learn中,这个分类器被称为BaggingClassifier。但是,这个分类器不允许平衡每个数据子集。因此,当对不平衡数据集进行训练时,该分类器将有利于样本数目多的类别。BalancedBaggingClassifier允许在训练集成的每个估计器之前重新采样每个数据子集。
-
-
熟练掌握使用 Flask 部署模型
-
将流程串通
3. project3
- 加入深度模型,了解如何使用 Resnet、Bert、Xlnet 等预训练模型获取 embedding
- 了解深度学习模型代码架构
- 对比使用深度模型的效果
如果对您有帮助,麻烦点赞关注,这真的对我很重要!!!如果需要互关,请评论或者私信!
