《深度学习感知器实现》
《深度学习感知器实现》
- 常用函数介绍
- 感知器的定义
- 感知器的训练
- 代码实现
常用函数介绍
python中的lambda函数:具体用法请参考链接:链接: Python中的lambda函数
python中的map函数:具体用法请参考链接: python中的map函数
python中的reduce函数:具体用法请参考链接:链接: 【Python基础】reduce函数详解
感知器的定义
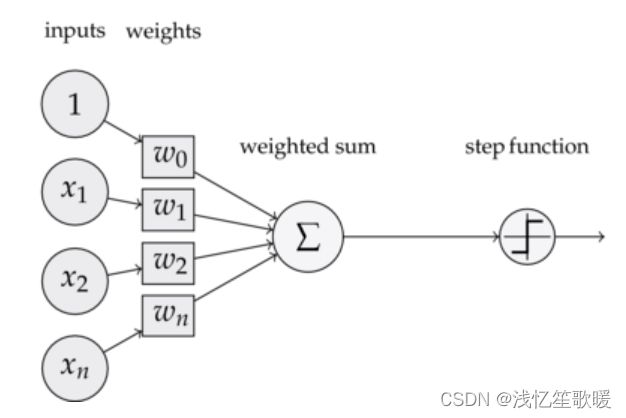
上图是一个感知器,由以下几个部分组成:
(1) 输入:一个感知器可以接收多个输入: ( x 1 , x 2 , ⋯ , x n ∣ x i ∈ R ) (x_1,x_2,\cdots,x_n|x_i\in\mathbb{R}) (x1,x2,⋯,xn∣xi∈R) ,
每个输入上都有一个权重: w i ∈ R w_i\in \mathbb{R} wi∈R, 此外还有一个偏置项: b ∈ R b\in\mathbb{R} b∈R. 就是上图中的 w 0 w_0 w0。
(2) 激活函数:阶跃函数 f f f来作为激活函数:
f ( z ) = { 1 z > 0 0 otherwise f(z) = \left\{\begin{array}{ll} 1 & z>0 \\ 0 & \text { otherwise } \end{array}\right. f(z)={10z>0 otherwise
(3)输出:感知器的输出由下面公式计算:
y = f ( w ∗ x + b ) y=f(w*x+b) y=f(w∗x+b)
感知器的训练
感知器的训练主要用来获得权重项和偏置项,将权重项和偏置项初始化为0,然后利用下面的感知器规则迭代的修改 w i w_i wi和 b b b, 直至训练完成。
w i ← w i + △ w i b ← b + △ b w_i \leftarrow w_i+\vartriangle w_i \\ b \leftarrow b +\vartriangle b wi←wi+△wib←b+△b
其中: △ w i = η ( t − y ) x i \vartriangle w_i=\eta(t-y)x_i △wi=η(t−y)xi, △ b = η ( t − y ) \vartriangle b=\eta(t-y) △b=η(t−y), w i w_i wi是与输入 x i x_i xi相对应的权重值, b b b是偏置项。可以把 b b b看作是值永远为1的输入 x b x_b xb所对应的权重值。 t t t是训练样本的实际值,也叫做label, y y y是感知器的输出值, η \eta η是学习率,是个常数,其作用是控制每一步调整权的幅度。
代码实现
- 导入包 reduce 和time
from functools import reduce
import time
- 定义Perception()类,初始化感知器,传入两个参数,分别是 input_num: 设置输入参数的个数 和activator: 激活函数, 实现__str__()函数,打印权重值和偏置,实现train(self, input_vecs, labels, iteration, rate) 和predict(self, input_vec)函数。
train()函数里面传入input_vecs表示输入的一组样本向量,labels 实际标签,iteration训练轮次,rate 学习率。predict()函数里面传入input_vec 一个样本向量,进行预测。
class Perception():
def __init__(self, input_num, activator):
'''
初始化感知器
:param input_num: 设置输入参数的个数
:param activator: 激活函数,激活函数的类型为 double->double
'''
self.activator = activator
# 权重向量初始化为0
self.weights = [0.0 for _ in range(input_num)]
# 偏置项初始化为0
self.bias = 0.0
def __str__(self):
'''
:return:打印学习到的权重、偏置项
'''
return 'weights\t:%s\n bias\t:%f\n' % (self.weights, self.bias)
def predict(self, input_vec):
'''
:return: 输入向量,输出感知器的计算结果
'''
# 把input_vec[x1,x2,x3,...]和weights[w1,w2,w3,...]打包在一起
# 变成[(x1,w1),(x2,w2),(x3,w3),...]
# 然后利用map函数计算[x1*w1,x2*w2,x3*w3]
# 最后利用reduce求和
return self.activator(
reduce(lambda a, b: a + b, list(map(lambda x, w: x * w, input_vec, self.weights)), 0.0) + self.bias)
def train(self, input_vecs, labels, iteration, rate):
'''
:param input_vecs: 输入训练数据: 输入一组向量
:param labels: 与每个向量对应的label
:param iteration: 训练轮数
:param rate: 学习率
'''
for i in range(iteration):
self._one_iteration(input_vecs, labels, rate)
def _one_iteration(self, input_vecs, labels, rate):
'''
一次迭代,把所有的训练数据过一遍
:param input_vecs: 输入一组向量
:param labels: 与每个向量对应的label
:param rate: 学习率
'''
# 把输入和输出打包在一起,成为样本的列表[(input_vec,label),...]
# 而每个训练样本是(input_vec,label)
samples = zip(input_vecs, labels)
for (input_vec, label) in samples:
# 计算感知器在当前权重下的输出
output = self.predict(input_vec)
# 更新权重
self._update_weights(input_vec, output, label, rate)
def _update_weights(self, input_vec, output, label, rate):
'''
按照感知器规则更新权重
:param input_vec: 输入一组向量
:param output: 输出结果
:param label: 标签
:param rate: 学习率
'''
# 把input_vec[x1,x2,x3,...]和weights[w1,w2,w3,...]打包在一起
# 变成[(x1,w1),(x2,w2),(x3,w3),...]
# 然后利用感知器规则更新权重
delta = label - output
self.weights = list(map(lambda x, w: w + rate * delta * x, input_vec, self.weights))
# 更新bias
self.bias += rate * delta
- 定义激活函数(阶跃函数):
def f(x):
'''
定义激活函数f
:return: 0/1
'''
return 1 if x > 0 else 0
- 获取数据集
def get_training_dataset():
'''
基于and真值表构建训练数据
:return:
'''
# 构建训练数据
# 输入向量列表
input_vecs = [[1, 1],
[0, 0],
[1, 0],
[0, 1]]
# 期望的输出列表,注意要与输入一一对应
# [1,1]->1, [0,0]->0, [1,0]->0, [0,1]->0
labels = [1, 0, 0, 0]
return input_vecs, labels
def get_training_dataset1():
'''
基于or真值表构建训练数据
:return:
'''
# 构建训练数据
# 输入向量列表
input_vecs=[[1,1],
[0,0],
[1,0],
[0,1]]
# 期望的输出列表,注意要和输入一一对应
# [1,1]->1, [0,0]->0, [1,0]->1, [0,1]->0
labels=[1,0,1,1]
return input_vecs, labels
- 训练感知器
def train_and_perceptron():
'''
使用and真值表训练感知器
:return:
'''
# 创建感知器,输入参数个数为2(因为and是二元函数),激活函数为f
p = Perception(2, f)
# 训练,迭代10轮,学习速率为0.1
input_vecs, labels = get_training_dataset()
# print('input_vecs:{}'.format(input_vecs))
# print('labels:{}'.format(labels))
p.train(input_vecs, labels, 10, 0.1)
# 返回训练好的感知器
return p
def train_or_perceptron():
'''
使用or真值表训练感知器
:return:
'''
# 创建感知器,输入参数个数为2(因为or是二元函数),激活函数为f
p = Perception(2, f)
# 训练,迭代10轮,学习速率为0.1
input_vecs, labels = get_training_dataset1()
# print('input_vecs:{}'.format(input_vecs))
# print('labels:{}'.format(labels))
p.train(input_vecs, labels, 10, 0.1)
# 返回训练好的感知器
return p
- 主函数进行测试
if __name__ == '__main__':
t1=time.perf_counter()
# 训练and感知器
and_perception = train_and_perceptron()
# 打印训练获得的权重
print(and_perception)
# 测试
print('1 and 1 = %d' % and_perception.predict([1, 1]))
print('0 and 0 = %d' % and_perception.predict([0, 0]))
print('1 and 0 = %d' % and_perception.predict([1, 0]))
print('0 and 1 = %d' % and_perception.predict([0, 1]))
t2=time.perf_counter()
print('训练and感知器耗时{}'.format(t2-t1))
# 训练or感知器
t3=time.perf_counter()
or_perception = train_or_perceptron()
# 打印训练获得的权重
print(or_perception)
# 测试
print('1 or 1 = %d' % or_perception.predict([1, 1]))
print('0 or 0 = %d' % or_perception.predict([0, 0]))
print('1 or 0 = %d' % or_perception.predict([1, 0]))
print('0 or 1 = %d' % or_perception.predict([0, 1]))
t4= time.perf_counter()
print('训练and感知器耗时{}'.format(t4- t3))