yolov3学习笔记
yolov3学习笔记
- yolov3实现思路
- Resnet
- darknet53
- yolov3主干网络
-
- 前向传播
- 先验框参数调整
-
- 特征层参数解码
yolov3实现思路

大体来说,是将输入图片传入给主干网络darknet53,进行图片的下采样,压缩图片的长和宽,加深图片的通道数。
每一层下采样结果都可以看作对图片的特征提取

batch_size:批量输入的图片个数
416,416:输入图片的长*宽
3:输入图片通道数
Resnet
darknet53
接下来,结合代码,给大家讲解一下主干网络对图片处理的流程
流程图中,图片进入主干网络darknet53

先进入一个3X3卷积核,变为32通道

也就是darknet类中的第一部分代码:
super(DarkNet, self).__init__()
self.inplanes = 32
# 416,416,3 -> 416,416,32
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(self.inplanes)
self.relu1 = nn.LeakyReLU(0.1)
DarkNet([1, 2, 8, 8, 4])传入的列表中的数字,代表残差块循环执行的次数
每一个残差块的实现:
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes[0], kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes[0])
self.relu1 = nn.LeakyReLU(0.1)
self.conv2 = nn.Conv2d(planes[0], planes[1], kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes[1])
self.relu2 = nn.LeakyReLU(0.1)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu2(out)
out += residual
return out
实质上就是进行了两次卷积,再进行残差处理
进行接下来的流程前,我们先看一下残差块网络的制作函数:
def _make_layer(self, planes, blocks):
layers = []
# 下采样,步长为2,卷积核大小为3
layers.append(("ds_conv", nn.Conv2d(self.inplanes, planes[1], kernel_size=3, stride=2, padding=1, bias=False)))
layers.append(("ds_bn", nn.BatchNorm2d(planes[1]))) # 标准化
layers.append(("ds_relu", nn.LeakyReLU(0.1))) # 通过激活函数
# 加入残差结构
self.inplanes = planes[1] # 通过kernnel后更新通道数
for i in range(0, blocks):
layers.append(("residual_{}".format(i), BasicBlock(self.inplanes, planes)))
return nn.Sequential(OrderedDict(layers))
for循环就是根据流程图,各个残差块需要进行循环的次数
接下来,我们就可以很容易读懂主干部分的代码了
# 416,416,32 -> 208,208,64
self.layer1 = self._make_layer([32, 64], layers[0])
# 208,208,64 -> 104,104,128
self.layer2 = self._make_layer([64, 128], layers[1])
# 104,104,128 -> 52,52,256
self.layer3 = self._make_layer([128, 256], layers[2])
# 52,52,256 -> 26,26,512
self.layer4 = self._make_layer([256, 512], layers[3])
# 26,26,512 -> 13,13,1024
self.layer5 = self._make_layer([512, 1024], layers[4])
yolov3主干网络
基于darknet53,我们可以进行yolov3主干网络的构建
以下代码路径为:YOLOv3/yolo3-pytorch-master/nets/yolo.py
根据流程图,我们先构建darknet53网络
class YoloBody(nn.Module):
def __init__(self, anchors_mask, num_classes, pretrained = False):
super(YoloBody, self).__init__()
#---------------------------------------------------#
# 生成darknet53的主干模型
# 获得三个有效特征层,他们的shape分别是:
# 52,52,256
# 26,26,512
# 13,13,1024
#---------------------------------------------------#
self.backbone = darknet53()
if pretrained:
self.backbone.load_state_dict(torch.load("model_data/darknet53_backbone_weights.pth"))
#---------------------------------------------------#
# out_filters : [64, 128, 256, 512, 1024]
#---------------------------------------------------#
out_filters = self.backbone.layers_out_filters
make_last_layers方法用来构建darknet53网络最后一层的网络,进行结果的预测
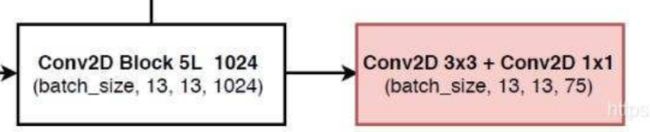
#------------------------------------------------------------------------#
# make_last_layers里面一共有七个卷积,前五个用于提取特征。
# 后两个用于获得yolo网络的预测结果
#------------------------------------------------------------------------#
def make_last_layers(filters_list, in_filters, out_filter):
m = nn.Sequential(
conv2d(in_filters, filters_list[0], 1), # 进行通道数的调整
conv2d(filters_list[0], filters_list[1], 3), # 进行特征提取
conv2d(filters_list[1], filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
conv2d(filters_list[1], filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
nn.Conv2d(filters_list[1], out_filter, kernel_size=1, stride=1, padding=0, bias=True)
)
return m
进行最后一层的输出:
self.last_layer0 = make_last_layers([512, 1024], out_filters[-1], len(anchors_mask[0]) * (num_classes + 5))
接下来,我们通过得到的最后一层网络结构,进行上采样,进行流程图的这一步操作:
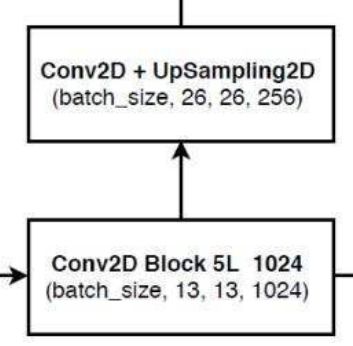
self.last_layer1_conv=conv2d(512, 256, 1) # 运用1*1卷积调整通道数
self.last_layer1_upsample = nn.Upsample(scale_factor=2, mode='nearest') # 进行上采样

我们接下来再用得到的特征层与darknet53中相同大小尺寸的特征进行堆叠,该部分功能我们放在forword前向传播中实现
# 26,26,256 + 26,26,512 -> 26,26,768
x1_in = torch.cat([x1_in, x1], 1)
再将拼接好的数据进行5次卷积,也就是进行make_last_layers操作
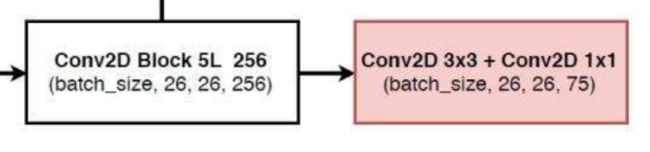
self.last_layer1= make_last_layers([256, 512], out_filters[-2] + 256,len(anchors_mask[1]) * (num_classes + 5))
了解以上步骤,剩下的流程就很容易读懂了
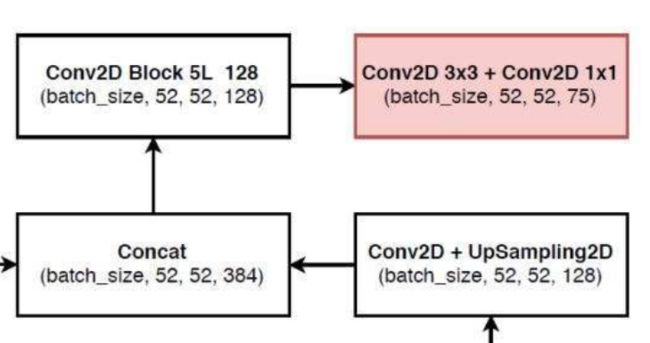
self.last_layer2_conv = conv2d(256, 128, 1)
self.last_layer2_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.last_layer2 = make_last_layers([128, 256], out_filters[-3] + 128, len(anchors_mask[2]) * (num_classes + 5))
前向传播
接下来,我们来分析前向传播进行了哪些工作
我们通过流程图可以看出,darknet中有3层我们需要单独抽离出来进行堆叠操作:

def forward(self, x):
#---------------------------------------------------#
# 获得三个有效特征层,他们的shape分别是:
# 52,52,256;26,26,512;13,13,1024
#---------------------------------------------------#
x2, x1, x0 = self.backbone(x)
branch操作就相当于每一个分支的forword,第一层的branch过程:
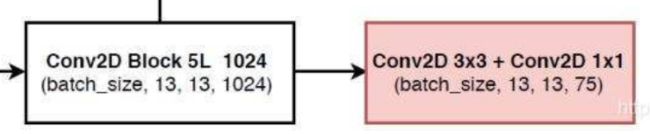
#---------------------------------------------------#
# 第一个特征层
# out0 = (batch_size,255,13,13)
#---------------------------------------------------#
# 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512
out0_branch = self.last_layer0[:5](x0) # 进行特征提取
out0 = self.last_layer0[5:](out0_branch)
# 13,13,512 -> 13,13,256 -> 26,26,256
x1_in = self.last_layer1_conv(out0_branch)
x1_in = self.last_layer1_upsample(x1_in)
# 26,26,256 + 26,26,512 -> 26,26,768
x1_in = torch.cat([x1_in, x1], 1)
进行堆叠操作:
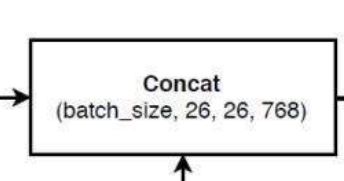
# 26,26,256 + 26,26,512 -> 26,26,768
x1_in = torch.cat([x1_in, x1], 1)
同样地,第二层:
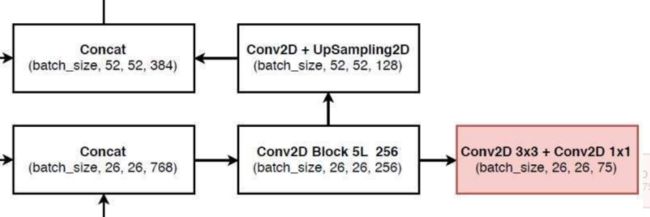
#---------------------------------------------------#
# 第二个特征层
# out1 = (batch_size,255,26,26)
#---------------------------------------------------#
# 26,26,768 -> 26,26,256 -> 26,26,512 -> 26,26,256 -> 26,26,512 -> 26,26,256
out1_branch = self.last_layer1[:5](x1_in)
out1 = self.last_layer1[5:](out1_branch)
# 26,26,256 -> 26,26,128 -> 52,52,128
x2_in = self.last_layer2_conv(out1_branch)
x2_in = self.last_layer2_upsample(x2_in)
# 52,52,128 + 52,52,256 -> 52,52,384
x2_in = torch.cat([x2_in, x2], 1)
进行第三层:

#---------------------------------------------------#
# 第三个特征层
# out2 = (batch_size,255,52,52)
#---------------------------------------------------#
# 52,52,384 -> 52,52,128 -> 52,52,256 -> 52,52,128 -> 52,52,256 -> 52,52,128
out2 = self.last_layer2(x2_in)
return out0, out1, out2
先验框参数调整
在进行完一轮结果的预测后,我们需要对先验框的参数进行调整
首先,我们要完成特征层参数的解码
特征层参数解码
在YOLOv3/yolo3-pytorch-master/utils/utils_bbox.py 路径下中的DecodeBox方法就是完成对特征层的参数解码操作
先获取图片的基本信息
batch_size = input.size(0)
input_height = input.size(2)
input_width = input.size(3)
计算图像相对于原图像缩小的倍数(特征层上一个像素点对应原图像的几个像素点)
#-----------------------------------------------#
# 输入为416x416时
# stride_h = stride_w = 32、16、8(每一个像素点对应原图上的几个像素点)
#-----------------------------------------------#
stride_h = self.input_shape[0] / input_height
stride_w = self.input_shape[1] / input_width
获得特征层中先验框的大小
#-------------------------------------------------#
# 此时获得的scaled_anchors大小是相对于特征层的
#-------------------------------------------------#
scaled_anchors = [(anchor_width / stride_w, anchor_height / stride_h) for anchor_width, anchor_height in self.anchors[self.anchors_mask[i]]]
由于特征层中的尺寸存放是(bs, 3*(5*num_classes), 13, 13),我们要将先验眶中的参数单独提取出来,变成bs, 3, 13, 13, (5num_classes),以下是调整先验框位置的实现:
prediction = input.view(batch_size, len(self.anchors_mask[i]),
self.bbox_attrs, input_height, input_width).permute(0, 1, 3, 4, 2).contiguous()