【目标检测算法】YOLOv2学习笔记
趁着放寒假,把目标检测算法总结了(*^__^*)
这篇文章有很多细节,参考的文章已经说得很详细了,有些太详细的部分如果只是为了看论文不操作代码的话(比如我)就可以忽略了,直接看yolov3更好。
所以下面的部分都是我认为(对于本弱鸡我)要掌握的。。。
Darknet-19和VGG一样都是用来做特征提取的,一个新的网络结构(未知URL)。

3、Convolutional With Anchor Boxes
引入了anchor使得每个cell可以预测多个尺度的不同物体
这里的anchor和SSD中的prior box的含义是一样的,都是初始框,根据你设定的大小和宽高比和其他一些参数就能生成这些有规律的框,anhor翻译过来就是锚,可以说是比较形象了,相当于基准。而一般说的bounding box是指预测框。
yolo v2设置的5种anchor是通过维度聚类得到的。5种anchor的宽高,分别如下:
# 宽高
[0.57273, 0.677385],
[1.87446, 2.06253],
[3.33843, 5.47434],
[7.88282, 3.52778],
[9.77052, 9.16828].
注意,这个宽高是在grid cell的尺度(即feature map)下的,不是在原图尺度上,在原图尺度上的话还要乘以步长32。
5、Direct Location prediction
因为引入了anchor的概念,所以计算bbox的位置计算又和v1不一样了(绝望.jpg)。
(回忆:v1里是预测出来bbox的![]() ,这里x_hat,y_hat是cell左上角坐标的偏移量,就找到了bbox。)
,这里x_hat,y_hat是cell左上角坐标的偏移量,就找到了bbox。)
开始啦!!!求bbox坐标沿用了YOLO算法中直接预测相对于grid cell的坐标位置的方式 —— 沿用YOLOv1的方法,就是预测bbox中心点相对于对应cell左上角位置的相对偏移值,为了将bbox中心点约束在当前cell中,使用sigmoid函数处理偏移值,这样预测的偏移值在(0,1)范围内(每个cell的尺度看做1)。
The network predicts 5 bounding boxes at each cell in the output feature map. The network predicts 5 coordinates for each bounding box,
, and
. 这里
根据anchor预测的4个offsets![]() ,可以按如下公式计算出bbox实际位置和大小:
,可以按如下公式计算出bbox实际位置和大小:
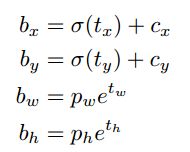
其中,
 为cell的左上角坐标,在计算时每个cell的尺度为1,所以当前cell的左上角坐标为(1,1)。由于sigmoid函数的处理,bbox的中心位置会约束在当前cell内部,防止偏移过多。
为cell的左上角坐标,在计算时每个cell的尺度为1,所以当前cell的左上角坐标为(1,1)。由于sigmoid函数的处理,bbox的中心位置会约束在当前cell内部,防止偏移过多。
而![]() 和
和![]() 是先验框(是anchor吗?嗯)的宽度与长度,前面说过它们的值也是相对于特征图大小的,在特征图中每个cell的长和宽均为1。这里记特征图的大小为(W,H)(在文中是13*13),这样我们可以将bbox相对于整张图片的位置和大小计算出来(4个值均在0和1之间):
是先验框(是anchor吗?嗯)的宽度与长度,前面说过它们的值也是相对于特征图大小的,在特征图中每个cell的长和宽均为1。这里记特征图的大小为(W,H)(在文中是13*13),这样我们可以将bbox相对于整张图片的位置和大小计算出来(4个值均在0和1之间):
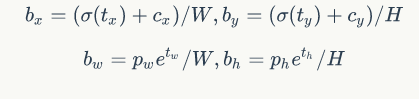
如果再将上面的4个值分别乘以(为啥公式里写的是➗除呢?)图片的宽度和长度(像素点值)就可以得到边界框的最终位置和大小了。(bbox的坐标解码结束!)
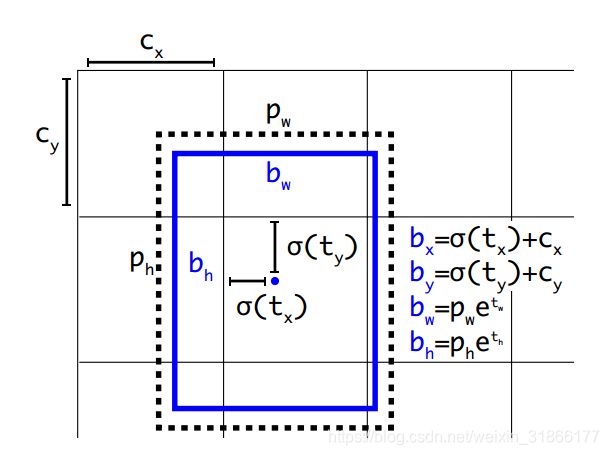
(黑色的是先验框,就是那个被挑中的、IoU最为匹配的anchor;蓝色blue的是边界框即bbox。)
训练
1. 给anchor分配label
首先,对于一个物体的bbox,我们得到它的中心,看这个中心落在grid中的哪一个cell,那么这个cell就负责预测这个物体。但是,需要注意的是,每个cell中实际上有5个anchor,并不是每个anchor的会预测这个物体,我们只会选择一个长宽和这个bbox最匹配的anchor来负责预测这个物体。那么什么叫长宽最为匹配?这个实际上就是将anchor移动到图像的右上角,bbox也移动到图像的左上角,然后去计算它们的iou,iou最大的其中一个anchor负责预测这个物体,如下图所示。

2. 损失函数(论文里都没介绍!我找了好久~~)和多尺度输入图片训练,直接看reference1吧,上面的anchor打label也是来源于此。
和YOLOv1一样,对于训练图片中的ground truth,若其中心点落在某个cell内,那么该cell内的5个先验框所对应的边界框负责预测它,具体是哪个边界框预测它,需要在训练中确定,即由那个与ground truth的IOU最大的边界框预测它,而剩余的4个边界框不与该ground truth匹配。YOLOv2同样需要假定每个cell至多含有一个grounth truth,而在实际上基本不会出现多于1个的情况。与ground truth匹配的先验框(就是被挑中的那个anchor)计算坐标误差、置信度误差(此时object为1)以及分类误差,而其它的边界框只计算置信度误差(此时object为0)。
YOLO中一个ground truth只会与一个先验框匹配(IOU值最好的),对于那些IOU值超过一定阈值的先验框,其预测结果就忽略了。这和SSD与RPN网络的处理方式有很大不同,因为它们可以将一个ground truth分配给多个先验框。
损失函数有5个部分:
第一项:负责预测物体的anchor的xywh损失。如果anchor负责预测物体,那么需要计算坐标的L2损失。
第二项:不负责预测物体的anchor的xywh损失。如果anchor不负责预测物体,那么需要在迭代的初期(比如iteration<12800)去计算坐标的L2损失。问题的关键是,anchor都不负责预测物体,那么它的预测目标是什么呢?答:预测目标是anchor的xywh。为什么要这么做?我的理解是,这么做可以让所有anchor的预测都接近anchor自身的xywh,这样当它有物体落入这个anchor的时候,anchor的预测不至于和目标差别太大,相应的损失也会比较小,训练起来会更加容易。
第三项:负责预测物体的anchor的confidence损失。负责预测物体的anchor需要计算confidence损失,confidence的目标就是预测的bbox和真实bbox的iou。
第四项:不负责预测物体的anchor的confidece损失。对那些不负责预测gt的anchor,需要计算每个anchor和所有gt box的IOU。如果算出来的最大IOU<0.6,相应的 ,并且confidence的label就是0。但是,如果这个值大于0.6,相应的 ,也就是说,这个时候是不算这个anchor的confidence损失的。为什么要这么做呢?我的理解是,当anchor不负责预测物体的时候,如果它预测出来的结果和真实值差别很大的话,那代表它是没有物体的,那么这个时候就希望它的预测的confidence接近0。但是如果预测的结果和真实值比较接近的话,则不计算损失。
第五项:负责预测物体的anchor的类别损失。每个类别的输出概率0-1之间,计算的是L2损失。也就是说分类问题也把它当做了回归问题。另外需要注意的是,类别预测中是不需要预测背景的,因为confidence实际上就已经代表是否存在物体,类别就没必要去预测背景。
?:图片中的阿拉斯加object,它落在了一个cell里,那么这个cell就是只用来预测阿拉斯加的,这个cell有5个anchor,在训练的时候我们只挑选IoU与gt最为匹配的anchor当做负责预测物体的bbox,就xywhc计算loss,然后就是网络的预测值和gt不断进行优化,训练好网络权重。
问题:那么这个cell就是只用来预测阿拉斯加的,这个“只”还对吗?
测试
image进入网络,Darknet-19特征提取之后为13*13*125的矩阵,产生13*13*5个anchor,做NMS留下confidence最高的(同v1)。
对于“YOLOv2使用了anchor boxes之后,每个位置(一个cell)的5个anchor都单独预测一套分类概率值”这句话的理解(所以一个cell里可以产生狗的bbox,也可以产生猪的bbox了?v1中一个cell里只能产生同类的bbox)。


一些问题
Q:multi scale的训练输入的话那网络结构不用实时改变么? 在做分类预训练时那个平均池化层要如何应对224×224和448×448这两种不同分辨率?
A:multi scale训练网络结构是可以不改变的,因为大部分网络最后都会将提到的特征做flatten,然后和全连接层相连,所以差别无非是将7*7 flatten成49和将9*9 flatten成81而已。以ResNet为例,最后的池化层采用的是global pooling,也就是不管输入是多大都处理成1*1大小,所以当输入是224*224时,池化层的输入就是7*7,输出是1*1;当输入是448*448时,池化层的输入就是14*14,输出还是1*1。(前面的global pooling会保证flatten前的特征数量相同,网络的最后有个全局pooling操作,这个和很多分类网络类似,因此不管输入图像分辨率多少,最后经过全局pooling后尺寸都是1*1。)
Q:网络抛弃了全连接,采用全卷积FCN的架构,因此可以输入任意大小的图片。
(这句话我自己目前还不太明白,也可以理解为全连接换成全卷积的好处是什么?在我看来一直都可以输入任意大小的图片啊,只要送进CNN之前resize到要的尺寸不就可以了吗?求指点)
A:因为faster rcnn有ROI pooling,所以变成size一样的送入全连接,这里又没有。
所以加入全卷积,就可以输入任意size大小的图片。
Q:训练部分,那么这个cell就是只用来预测阿拉斯加的,这个“只”还对吗?
和YOLOv1一样,对于训练图片中的ground truth,若其中心点落在某个cell内,那么该cell内的5个先验框所对应的边界框负责预测它,具体哪一个选IoU最大的那个框。
第一项loss是计算background的置信度误差,但是哪些预测框来预测背景呢,需要先计算各个预测框和所有ground truth的IOU值,并且取最大值Max_IOU,如果该值小于一定的阈值(YOLOv2使用的是0.6),那么这个预测框就标记为background,需要计算noobj的置信度误差。第二项是计算先验框与预测框的坐标误差,但是只在前12800个iterations间计算,我觉得这项应该是在训练前期使预测框快速学习到先验框的形状。第三大项计算与某个ground truth匹配的预测框各部分loss值,包括坐标误差、置信度误差以及分类误差。先说一下匹配原则,对于某个ground truth,首先要确定其中心点要落在哪个cell上,然后计算这个cell的5个先验框与ground truth的IOU值(YOLOv2中bias_match=1),计算IOU值时不考虑坐标,只考虑形状,所以先将先验框与ground truth的中心点都偏移到同一位置(原点),然后计算出对应的IOU值,IOU值最大的那个先验框与ground truth匹配,对应的预测框用来预测这个ground truth。在计算obj置信度时,在YOLOv1中target=1,而YOLOv2增加了一个控制参数rescore,当其为1时,target取预测框与ground truth的真实IOU值。对于那些没有与ground truth匹配的先验框(与预测框对应),除去那些Max_IOU低于阈值的,其它的就全部忽略,不计算任何误差。
A:我自己答的,?。狗的中心点落入这个cell中,选择IOU最大的anchor进行训练,恰好!猫的中心点也落入这个cell中,选择IoU最大的anchor进行训练。问题又来了。。。如果这两个anchor是同一个呢?
Q:测试部分,所以一个cell里可以产生狗的bbox,也可以产生猪的bbox了?(v1中一个cell里只能产生同类的bbox)这与之前所说中心落入哪个cell,哪个cell就负责预测该类别是否冲突呢?
A:因此yolo v2借鉴了faster RCNN中anchor的思想,这样实际上使得grid的每个cell可以预测多个尺度的不同物体。

9021年了,中心落入哪个cell,哪个cell就负责预测该类别这句话是描述yolov1的,那个这里的anchor和faster rcnn中就一模一样了,一个像素点对应回原图产生了多少个anchor。anchor找与它iou最大的gt,这个gt是什么类,那么这个anchor在训练的时候就和这个类(dog or cat?)不断拟合了。这些anchor可以任意学,可以任意预测不同物体,就按照faster rcnn中的anchor理解即可。
参考:
1. 重温yolo v2
2. YOLO v2算法详解
3. 目标检测|YOLOv2原理与实现(附YOLOv3)
YOLOv2目标检测详解 (这里有计算举例,bbox的计算更清楚)
一文详解YOLO 2与YOLO 9000目标检测系统 | 分享总结 (这里有视频讲解)
5分钟学会AI(里面列出了具体的数据),一个讲v2的文章但用的v1的名字。
?不知道什么时候才能写好v3的总结帖,/(ㄒoㄒ)/~~