【SDN】软件定义硬件
本文目录
- 前言
- 软件和硬件的定义
- “软件定义硬件”的定义
- CPU,软件和硬件解耦
- CPU的软硬件定义
- 软件定义硬件
- 软件定义网络SDN
-
- 1)运行于CPU的软件虚拟交换机
- 2)数据面可编程的网络交换机DSA
- 软件定义接口:Virtio
- 软件定义也存在一些挑战
-
- 1)基于CPU的摩尔定律失效
- 2)DSA只解决了部分问题
前言
摘录自SDNLAB文章,原文链接附在文末。
软件和硬件的定义
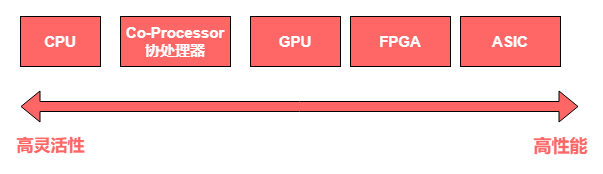
处理器平台分类:按照单位计算(指令)的复杂度。处理器平台大致分为CPU、协处理器、GPU、FPGA和ASIC。
指令是软件和硬件的媒介,指令的复杂度决定了系统的软硬件解耦程度。
解耦程度:依赖降低程度
从左往右,单位计算越来越复杂,灵活性越来越低。
- 软件运行:任务在CPU运行
- 硬件加速运行:任务在协处理器、GPU、FPGA或ASIC运行
“软件定义硬件”的定义
- 软件定义是当下比较热门的话题,比如软件定义网络、软件定义数据中心、软件定义汽车等等。范围比较大,不仅涉及到底层的软硬件技术,也涉及到系统的运行管理等,甚至包括一些商业问题。
什么是软件定义网络?
- 软件定义网络(Software Defined Network, SDN )是Emulex网络一种新型网络创新架构,是网络虚拟化的一种实现方式,其核心技术OpenFlow通过将网络设备控制面与数据面分离开来,从而实现了网络流量的灵活控制。
“软件定义硬件”定义为:
- 系统的主要业务逻辑是在软件中实现;
- 系统中没有硬件引擎,或者硬件引擎是软件可编程的;硬件引擎按照软件编程的逻辑执行操作。
- 相关的硬件依赖于软件提供的接口构建。
CPU,软件和硬件解耦

CPU最灵活,原因是运行于CPU的指令都是最基本粒度的加减乘除外加一些访存及控制类指令,就像积木块一样,我们可以随意组合出我们想要的各种形态的功能。
CPU最大价值不是可以自动的执行非常复杂的计算机程序,而是提供并规范了标准化的指令集,使得软件和硬件从此解耦:
- 硬件工程师不需要关心场景,只关注于通过各种“无所不用其极”的方式,快速的提升CPU的性能。
- 软件工程师,则完全不用考虑硬件的细节,只关注于程序本身。然后有了高级编程语言/编译器、操作系统以及各种系统框架/库的支持,构建起一个庞大的软件生态超级帝国。
X86是桌面和服务器领域最流行的处理器架构。ARM在手机等移动端占据绝对的统治地位。开源RISC-v符合未来技术和商业发展的趋势,其在MCU领域已经占据重要地位,并且在向桌面和服务器领域发起冲锋。
什么是MCU?
- 微控制单元(Microcontroller Unit;MCU) ,又称单片微型计算机(Single Chip Microcomputer )或者单片机,是把中央处理器(Central Process
Unit;CPU)的频率与规格做适当缩减,并将内存(memory)、计数器(Timer)、USB、A/D转换、UART、PLC、DMA等周边接口,甚至LCD驱动电路都整合在单一芯片上,形成芯片级的计算机,为不同的应用场合做不同组合控制。诸如手机、PC外围、遥控器,至汽车电子、工业上的步进马达、机器手臂的控制等,都可见到MCU的身影。- 简单地说就是将多个I/O接口集成在一片芯片
软件的庞大生态,是构建在特定的CPU架构之上的。但是,我们一般来说,CPU作为指令足够细粒度,计算足够通用的计算平台,其是软件和硬件解耦的:
- 一方面,特定架构下,每种CPU架构“基本”保证了向前兼容,这样可以认为,在特定架构,软件硬件完全解耦各自发展。
- 另一方面,(理想状态下,)OS、编译器等越来越成熟之后,能够保证,同样的高级语言程序,在不同的CPU架构平台,其运行行为是一致吧。这样就可以脱离具体的CPU架构凭条,构建完全无差别的软件生态。
从长期发展的角度,RISC-v应该会是未来更好的选择:
- 开放性。RISC-v最大的特点是其指令集开源,这样任何厂家就可以根据自己情况设计自己的RISC-v CPU,然后大家共建一套开放的生态,共生共荣。
- 标准化。标准化是最关键的价值。所有的架构(x86/ARM/RISC-v)都可以认为是标准的,但因为RISC-v的开放性,其标准化未来的价值就会非常大。上面说过,“理想”情况下,我们可以把程序无缝的从一个平台迁移到其他平台,但实际上,许多商业的软件,我们并不能拿到源码。而且,许多时候,一些细节问题,都可能导致平台迁移失败。这种迁移对用户来说是非常大的挑战和风险。当标准的RISC-v足够流行之后,基于RISC-v构建的整个生态会迸发强大的生命力。
- 其他。如RISC-v没有历史包袱,指令集更高效;更灵活的扩展能力(确保不碎片化)。
CPU的软硬件定义
CPU和软件程序的交互接口是指令集,是最细粒度的加减乘除等指令,像积木块一样,随意组合出任意想要的各种程序。
CPU到底是软件定义还是硬件定义,从不同的角度有不同的看法:
- 软件和硬件并行发展。CPU,通过ISA,“完美”实现了软件和硬件的标准化解耦。因此,可以认为,在这个时候,不存在硬件定义软件或软件定义硬件,软件和硬件各自并行不悖的快速发展。
- 硬件定义软件。基于CPU构建的庞大软件生态,这可以算作是“硬件定义软件”:先有CPU硬件,再有编译器,再有OS、应用等。
- 软件定义系统。 但是,站在软件的角度,所有的系统实现均可以通过编程实现,根本不需要考虑运行的CPU平台的“差一些”,因此又可以看做基于CPU运行的系统是“软件定义”的。
软件定义硬件
系统又开始从硬件逐步到软件

系统从起始发展,到逐步稳定,系统的运行平台逐步从CPU演进到ASIC。那么,ASIC是不是所有系统最终的运行平台?
答案是否定的。原因主要如下:
- 软件更新换代很快。新的热点技术层出不穷,已有的技术领域的更新迭代速度仍在快速增加。硬件的迭代周期过长,无法跟上软件迭代的节奏。
- 定制的ASIC设计,把所有功能都在硬件实现。在复杂的云计算、自动驾驶等场景,芯片公司对用户的场景理解可能不够深入,会导致设计偏差。另一方面,也会限制用户自身的主观能动性,让用户有想法也很难在ASIC平台去实现自己想要的功能。
- ASIC因为功能固定,为了适配更多场景,确保芯片的大量出货,势必需要实现功能超集。例如,某ASIC芯片支持10个功能,但实际用户场景,都是只需要2-3种功能。这样,ASIC实现实际上也是低效的。并且,这些功能因为紧耦合的缘故,系统复杂度反而更高。
这样,在许多场景,我们根据实际的场景需求,除ASIC,也开始选择DSA、FPGA、GPU甚至CPU等处理引擎。
软件定义网络SDN
最典型的一个案例就是SDN(Software Defined Network)的发展。经过几十年的发展,网络芯片已经演进到了完全ASIC的实现,这意味着基于ASIC芯片的网络设备其功能是确定的,用户只能根据厂家实现的确定功能来使用网络设备。
然而,随着云计算、4G/5G移动通信等的发展,新的网络协议和网络功能层出不穷,纯ASIC实现的网络系统遇到了挑战。
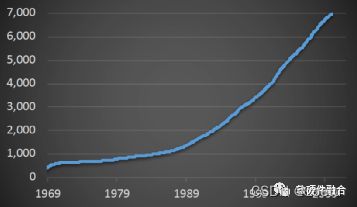
如上图所示,IETF(Internet Engineering Task Force,互联网工程任务组)的RFC(Request for Comments,请求意见稿,即网络协议)数量一直在爆炸式的增长,应用于各种新型网络场景的新协议层出不穷。但是,传统的网络处理芯片都是封闭的、特定的设计,用于特定协议处理。想要增加新的协议非常困难,并且对新协议的支持受到不同供应商的约束。定制的网络处理芯片,对新协议的支持不足以及缺乏有效的灵活性,这使得要想在网络系统增加新的功能非常困难,限制了客户的网络创新能力。
客户希望能够快速便捷的对网络进行配置和管理;客户希望能够快速的进行网络协议创新。这样,ASIC的功能固定越来越成为网络创新的约束。于是,SDN开始了两个方面的创新:
- 第一步,网络控制面和数据面分离,控制面可编程。把网络控制面从数据面分离处理,形成了控制面可编程的Openflow协议。
- 第二步,进一步的,网络数据面也可以编程,用户可以定义自己的协议。形成了数据面可编程的P4语言和P4交换机相继出现。
1)运行于CPU的软件虚拟交换机

OVS(Open Virtual Switch)是Apache 2许可下的开源的软件交换机。OVS的目标是实现一个生产环境的交换机平台,支持标准管理界面,并为程序扩展和控制开放转发功能。OVS非常适合在VM环境中用作虚拟交换机,除了向虚拟网络层公开标准控制和可见性接口之外,它还旨在支持跨多个物理服务器的分发。OVS支持多种基于Linux的虚拟化平台,包括Xen、KVM等。
最新的OVS版本支持以下功能:
- 具有主干和接入端口的标准的802.1Q VLAN模型;
- NIC绑定在上行交换机上,可以支持LACP也可以不支持;
- 通过NetFlow,sFlow®和镜像来增强可视性;
- QoS(服务质量)配置以及策略;
- Geneve, GRE, VxLAN, STT和LISP隧道;
- 802.1ag连接故障管理;
- OpenFlow 1.0以及众多扩展;
- 支持C和Python的事务配置数据库;
- 基于Linux内核的高性能转发模块。
如图,OVS答题可以分为三层: - 管理层,即:ovs-dpctl、ovs-vsctl、ovs-ofctl、ovsdb-tool。
- 业务逻辑层,即:vswitchd、ovsdb。
- 数据处理层,即:datapath。
2)数据面可编程的网络交换机DSA
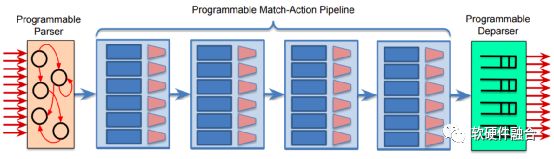
上图为PISA(Protocol Independent Switch Architecture,协议无关的交换架构)架构交换机的流水线,PISA是一种支持P4数据面可编程包处理的流水线引擎架构,通过可编程的解析器、多阶段的可编程的匹配动作以及可编程的逆解析器组成的流水线,来实现数据面的编程。这样可以通过编写P4程序,下载到处理器流水线,可以非常方便的支持新协议的处理。
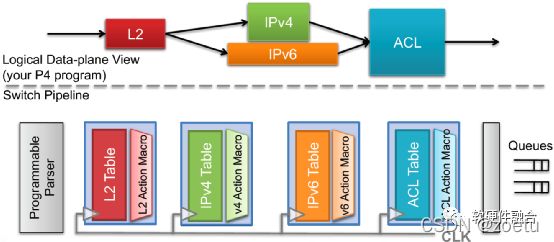
当实现了完全可编程的流水线之后,在P4工具链的支持下,就可以通过P4编程的方式来实现自定义的流水线,来达到对自定义协议的支持。
如图所示,P4定义的Parser程序会被映射到可编程的解析器,数据、包头定义、表以及控制流会被映射到多个匹配动作阶段。图 6.25中把L2处理、IPv4处理、IPv6处理以及访问控制处理分别映射到不同的匹配动作处理单元进行串行或并行的处理,来实现完整的支持各种协议的网络包处理。
软件定义接口:Virtio
Virtio旨在提供一套高效的、良好维护的通用的Linux驱动,实现虚拟机应用和不同Hypervisor实现的模拟设备之间标准化的接口。Virtio作为类虚拟化的I/O设备接口,广泛应用于云计算虚拟化场景,某种程度上,Virtio已经成为事实上的I/O设备的接口标准。
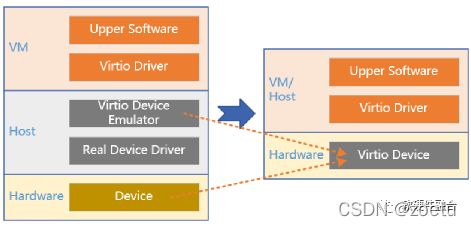
因为软件定义了标准化的Virtio接口,因此,如上图所示,在SmartNIC和DPU中,offload虚拟化和Workload的最关键部分就是要把Virtio硬件化。
如上图所示,站在虚拟化角度,把Virtio卸载,可以看做是从软件到硬件。但是,如果从硬件接口的角度,从一个完全硬件定义的接口(例如NV自定义的SR-IOV接口)过渡到软件定义的接口(Virtio接口),则可以算是从硬件到软件。
可跨平台的软件定义:Intel oneAPI

英特尔oneAPI是一个开放、可访问且基于标准的编程系统,支持开发人员跨多种硬件架构参与和创新,包括 CPU、GPU、FPGA、AI 加速器等。这些处理引擎具有非常不同的属性,因此用于各种不同的处理——oneAPI试图通过将它们统一在同一个模型下来简化这些操作。
即使在今天,开发人员面临的一个持续问题是我们日益数字化的世界提供的编程环境的数量。不同的编程环境使代码重用等节省时间的策略失效,并成为软件开发人员的真正障碍。作为其软件优先战略的一部分,英特尔在 2019 年的超级计算活动中推出了oneAPI。该模型标志着英特尔的雄心是拥有统一的编程框架作为限制专有编程平台的解决方案。oneAPI 使开发人员能够在不厌倦使用不同语言、工具、库和不同硬件的情况下工作。
Intel oneAPI可以实现:设计一套应用,根据需要,非常方便的把程序映射到CPU、GPU、FPGA或者AI-DSA/其他DSA等不同的处理器平台。
扩展:软件定义“一切”
软件定义是一个非常宏大并且非常热点的话题,除了软件定义网络之外,还有很多软件定义的热点领域:
- 软件定义存储,是一种能将存储软件与硬件分隔开的存储架构。不同于传统的网络附加存储(NAS)或存储区域网络(SAN)系统,SDS一般都在行业标准系统上执行,从而消除了软件对于专有硬件的依赖性。
- 软件定义数据中心,把数据中心基础设施通过抽象化、资源池化以及自动化来实现基础设施即服务(IAAS)。软件定义的基础设施可让IT管理员使用软件定义的模板和API轻松配置和管理物理基础设施,以定义基础设施配置和生命周期运维,并实现自动化。
- 软件定义无线电,是一种无线电广播通信技术,它基于软件定义的无线通信协议而非通过硬连线实现。频带、空中接口协议和功能可通过软件下载和更新来升级,而不用完全更换硬件。
- 软件定义汽车,通过软件实现新的车载体验和功能,并通过无线 (OTA) 提供更新和服务。从而使得汽车从高度机电一体化的机械终端,逐步转变为一个智能化、可拓展、可持续迭代升级的移动电子终端。
软件定义存储和软件定义无线电还主要是技术的范畴,而软件定义数据中心和软件定义汽车,则是把软件定义的思路和理念更加深化和拓展,应用于更广阔的领域。
软件定义也存在一些挑战
1)基于CPU的摩尔定律失效

软件定义XX,最本质的做法还是把整个系统重新从硬件实现变成偏软件的实现。随着这势必对CPU的性能提出了更高的要求。
然而,如上图所示,随着CPU的性能提升逐渐停滞,已经无法满足数字经济时代对算力持续提升的要求。
因此,还是要再轮回,“硬件”加速。
2)DSA只解决了部分问题
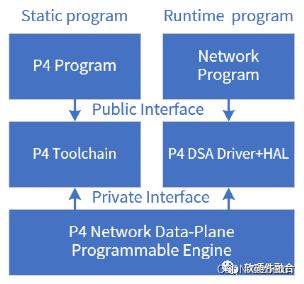
支持P4的网络数据面可编程引擎,属于DSA的范畴,专门用于网络包处理的加速,性能跟ASIC相当,但其具有非常好的软件可编程能力。
标准的P4程序,有P4前端编译器把P4程序编译成一个中间态的程序(类似Java编译器)。然后特定硬件实现的后端编译器负责把中间态的程序映射到具体的硬件实现(有点像Java虚拟机,但P4是静态)。
P4 DSA引擎预先配置好P4程序之后,P4-DSA就成了执行特定协议处理的网络包处理引擎。然后需要和已有的网络程序进行适配,实现网络任务的数据面offload。
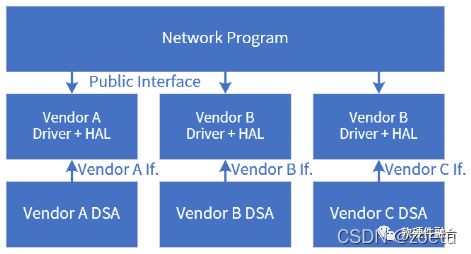
P4的整个系统栈跟之前CPU、GPU、ASIC最大的不同在于先定义了标准的P4,然后各厂家根据标准的P4去实现各自不同的P4处理引擎。
原文链接:https://www.sdnlab.com/25417.html