Windows系统下调试文本检测模型CTPN时遇到的问题
PS:本文主要用于自我整理总结,方便后续参考,如果恰好帮助到你,也是件值得高兴的事
Windows系统下调试文本检测模型CTPN时遇到的问题
- 环境及配置:
- 问题汇总:
-
- 预训练模型问题
- bbox与nms文件问题
- TensorFlow版本问题
- 执行:
环境及配置:
tensorflow版本为2.0.0
开源链接:https://github.com/eragonruan/text-detection-ctpn
问题汇总:
预训练模型问题
下载VGG16预训练模型时,在给出的slim模型库中下载不下来
![]()
后来搜到了下载地址,直接输入后可以下载:
http://download.tensorflow.org/models/vgg_16_2016_08_28.tar.gz
下载后放到data文件夹中
bbox与nms文件问题
报错:ModuleNotFoundError: No module named 'utils.bbox.bbox'或ModuleNotFoundError: No module named 'utils.bbox.nms'
然后我们看GitHub中说的是nms和bbox模块 是用cython编写的,因此您必须先构建库。
但是作者给出的在Linux系统下的执行方式,我们需要在Windows系统下解决,查到的方法是在我们的环境中和相应文件夹utils\bbox下执行命令:python setup.py build

然后在同目录下可以得到build文件夹,将build\lib.win-amd64-3.6文件夹中的两个文件复制到utils\bbox文件夹下(即和setup.py同一目录),好让我们执行命令能找到这两个文件。

TensorFlow版本问题
这个问题还是挺多的,因为这个模型开发的比较早,是在TensorFlow1.x版本下执行的,现在已经更新到TensorFlow2.x了,有些模块已经被替换掉了,下面我根据我遇到的问题提出一些解决方法,我没遇到那就只能靠你自己百度或谷歌了(摊手)。
①AttributeError: module 'tensorflow' has no attribute 'app'
这个就是TensorFlow版本的问题,解决方法是将我们的
import tensorflow as tf变成import tensorflow.compat.v1 as tf换成1.x的版本就可以了
![]()
②ModuleNotFoundError: No module named 'tensorflow.contrib'
这个是我们在调用from tensorflow.contrib import slim时会报错的,因为2.x版本中已经没有tensorflow.contrib这个模块了,他之前功能太多了,不方便后期维护,就给拆解成各个模块中了。
所以在2.x版本下用的话就需要先安装tf_slim模块,安装命令为pip install --upgrade tf_slim,然后修改代码中的调用命令为import tf_slim as slim
![]()
③
也是contrib模块的问题,原代码为:
lstm_fw_cell = tf.contrib.rnn.LSTMCell(hidden_unit_num, state_is_tuple=True)
我们也知道tf.contrib已经拆分没有了,所以应该改成:
lstm_fw_cell = tf.nn.rnn_cell.LSTMCell(hidden_unit_num, state_is_tuple=True)
④tf.contrib.layers.variance_scaling_initializer
还是contrib模块的问题,原代码为:
init_weights = tf.contrib.layers.variance_scaling_initializer(factor=0.01, mode='FAN_AVG', uniform=False)
我们参考TensorFlow的说明文档可以看到:

说明已经用 TF Slim替换tf.contrib.layers,即相关函数应该都封装在tf_slim模块中了,所以我们需要将相应代码改成:
init_weights = slim.variance_scaling_initializer(factor=0.01, mode='FAN_AVG', uniform=False) # tf.contrib.layers.variance_scaling_initializer
⑤ValueError: Buffer dtype mismatch, expected 'int_t' but got 'long long'
这个我不懂是不是版本问题,反正都先放在这里吧。
提醒我问题是出在File "nms.pyx", line 25, in nms.nms中,那我就用Pycharm打开utils\bbox\nms.pyx文件进行修改,对应为:
cdef np.ndarray[np.int_t, ndim=1] order = scores.argsort()[::-1]
这个有两种改变方法,我用第二种方法可以解决问题,第一种不行,但是我也给列出来,这玩意一个电脑一个解决方法。
方案一:
来自https://github.com/eragonruan/text-detection-ctpn/issues/380
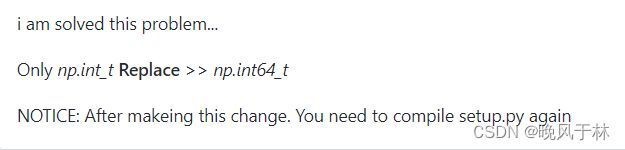
说是用np.int64_t替换np.int_t,下面还有人说np.int64_t不行就换成np.int32_t
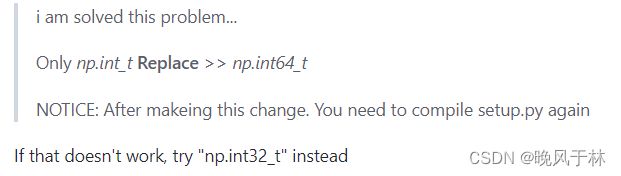
但是我两种都试了下,都不行,不过他这个解决问题时给我提个醒,修改完nms.pyx文件后需要重新setup一下才能应用,即上面步骤生成bbox.cp36-win_amd64.pyd和nms.cp36-win_amd64.pyd那里。
方案二:
来自https://github.com/eragonruan/text-detection-ctpn/issues/297
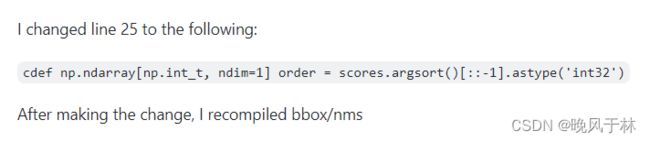
即将代码改成:
cdef np.ndarray[np.int_t, ndim=1] order = scores.argsort()[::-1].astype('int32')
文件中有两处,我都进行了修改,还有一个应该在78行。
然后重新build下即可。
执行:
最后我运行main\demo.py
就可以顺利检测图片了。
