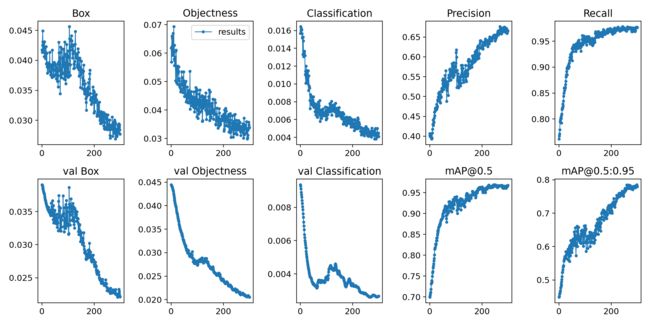
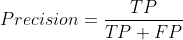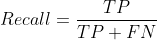- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- 2020-01-25
晴岚85
郑海燕坚持分享590天2020.1.24在生活中只存在两个问题。一个问题是:你知道想要达成的目标是什么,但却不知道如何才能达成;另一个问题是:你不知道你的目标是什么。前一个是行动的问题,后一个是结果的问题。通过制定具体的下一步行动,可以解决不知道如何开始行动的问题。而通过去想象结果,对结果做预估,可以解决找不着目标的问题。对于所有吸引我们注意力,想要完成的任务,你可以先想象一下,预期的结果究竟是什
- 10月|愿你的青春不负梦想-读书笔记-01
Tracy的小书斋
本书的作者是俞敏洪,大家都很熟悉他了吧。俞敏洪老师是我行业的领头羊吧,也是我事业上的偶像。本日摘录他书中第一章中的金句:『一个人如果什么目标都没有,就会浑浑噩噩,感觉生命中缺少能量。能给我们能量的,是对未来的期待。第一件事,我始终为了进步而努力。与其追寻全世界的骏马,不如种植丰美的草原,到时骏马自然会来。第二件事,我始终有阶段性的目标。什么东西能给我能量?答案是对未来的期待。』读到这里的时候,我便
- C语言如何定义宏函数?
小九格物
c语言
在C语言中,宏函数是通过预处理器定义的,它在编译之前替换代码中的宏调用。宏函数可以模拟函数的行为,但它们不是真正的函数,因为它们在编译时不会进行类型检查,也不会分配存储空间。宏函数的定义通常使用#define指令,后面跟着宏的名称和参数列表,以及宏展开后的代码。宏函数的定义方式:1.基本宏函数:这是最简单的宏函数形式,它直接定义一个表达式。#defineSQUARE(x)((x)*(x))2.带参
- 《投行人生》读书笔记
小蘑菇的树洞
《投行人生》----作者詹姆斯-A-朗德摩根斯坦利副主席40年的职业洞见-很短小精悍的篇幅,比较适合初入职场的新人。第一部分成功的职业生涯需要规划1.情商归为适应能力分享与协作同理心适应能力,更多的是自我意识,你有能力识别自己的情并分辨这些情绪如何影响你的思想和行为。2.对于初入职场的人的建议,细节,截止日期和数据很重要截止日期,一种有效的方法是请老板为你所有的任务进行优先级排序。和老板喝咖啡的好
- 绘本讲师训练营【24期】8/21阅读原创《独生小孩》
1784e22615e0
24016-孟娟《独生小孩》图片发自App今天我想分享一个蛮特别的绘本,讲的是一个特殊的群体,我也是属于这个群体,80后的独生小孩。这是一本中国绘本,作者郭婧,也是一个80厚。全书一百多页,均为铅笔绘制,虽然为黑白色调,但并不显得沉闷。全书没有文字,犹如“默片”,但并不影响读者对该作品的理解,反而显得神秘,梦幻,給读者留下想象的空间。作者在前蝴蝶页这样写到:“我更希望父母和孩子一起分享这本书,使他
- 【一起学Rust | 设计模式】习惯语法——使用借用类型作为参数、格式化拼接字符串、构造函数
广龙宇
一起学Rust#Rust设计模式rust设计模式开发语言
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录前言一、使用借用类型作为参数二、格式化拼接字符串三、使用构造函数总结前言Rust不是传统的面向对象编程语言,它的所有特性,使其独一无二。因此,学习特定于Rust的设计模式是必要的。本系列文章为作者学习《Rust设计模式》的学习笔记以及自己的见解。因此,本系列文章的结构也与此书的结构相同(后续可能会调成结构),基本上分为三个部分
- Python数据分析与可视化实战指南
William数据分析
pythonpython数据
在数据驱动的时代,Python因其简洁的语法、强大的库生态系统以及活跃的社区,成为了数据分析与可视化的首选语言。本文将通过一个详细的案例,带领大家学习如何使用Python进行数据分析,并通过可视化来直观呈现分析结果。一、环境准备1.1安装必要库在开始数据分析和可视化之前,我们需要安装一些常用的库。主要包括pandas、numpy、matplotlib和seaborn等。这些库分别用于数据处理、数学
- C#中使用split分割字符串
互联网打工人no1
c#
1、用字符串分隔:usingSystem.Text.RegularExpressions;stringstr="aaajsbbbjsccc";string[]sArray=Regex.Split(str,"js",RegexOptions.IgnoreCase);foreach(stringiinsArray)Response.Write(i.ToString()+"");输出结果:aaabbbc
- git常用命令笔记
咩酱-小羊
git笔记
###用习惯了idea总是不记得git的一些常见命令,需要用到的时候总是担心旁边站了人~~~记个笔记@_@,告诉自己看笔记不丢人初始化初始化一个新的Git仓库gitinit配置配置用户信息gitconfig--globaluser.name"YourName"gitconfig--globaluser.email"
[email protected]"基本操作克隆远程仓库gitclone查看
- Pyecharts数据可视化大屏:打造沉浸式数据分析体验
我的运维人生
信息可视化数据分析数据挖掘运维开发技术共享
Pyecharts数据可视化大屏:打造沉浸式数据分析体验在当今这个数据驱动的时代,如何将海量数据以直观、生动的方式展现出来,成为了数据分析师和企业决策者关注的焦点。Pyecharts,作为一款基于Python的开源数据可视化库,凭借其丰富的图表类型、灵活的配置选项以及高度的定制化能力,成为了构建数据可视化大屏的理想选择。本文将深入探讨如何利用Pyecharts打造数据可视化大屏,并通过实际代码案例
- 怎么起诉借钱不还的人?怎样起诉欠款不还的人?
影子爱学习
怎么起诉借钱不还的人?怎样起诉欠款不还的人?如果遇到难以解决的法律问题,我们可以匹配专业律师。例如:婚姻家庭(离婚纠纷)、刑事辩护、合同纠纷、债权债务、房产(继承)纠纷、交通事故、劳动争议、人身损害、公司相关法律事务(法律顾问)等咨询推荐手机/微信:15633770876【全国案件皆可】借钱不还起诉对方需要哪些资料起诉欠钱不还的,一般需要的材料包括以下这些:借据、收据、欠条、付款凭证等证据,以及向
- Python教程:一文了解使用Python处理XPath
旦莫
Python进阶python开发语言
目录1.环境准备1.1安装lxml1.2验证安装2.XPath基础2.1什么是XPath?2.2XPath语法2.3示例XML文档3.使用lxml解析XML3.1解析XML文档3.2查看解析结果4.XPath查询4.1基本路径查询4.2使用属性查询4.3查询多个节点5.XPath的高级用法5.1使用逻辑运算符5.2使用函数6.实战案例6.1从网页抓取数据6.1.1安装Requests库6.1.2代
- Google earth studio 简介
陟彼高冈yu
旅游
GoogleEarthStudio是一个基于Web的动画工具,专为创作使用GoogleEarth数据的动画和视频而设计。它利用了GoogleEarth强大的三维地图和卫星影像数据库,使用户能够轻松地创建逼真的地球动画、航拍视频和动态地图可视化。网址为https://www.google.com/earth/studio/。GoogleEarthStudio是一个基于Web的动画工具,专为创作使用G
- LLM 词汇表
落难Coder
LLMsNLP大语言模型大模型llama人工智能
Contextwindow“上下文窗口”是指语言模型在生成新文本时能够回溯和参考的文本量。这不同于语言模型训练时所使用的大量数据集,而是代表了模型的“工作记忆”。较大的上下文窗口可以让模型理解和响应更复杂和更长的提示,而较小的上下文窗口可能会限制模型处理较长提示或在长时间对话中保持连贯性的能力。Fine-tuning微调是使用额外的数据进一步训练预训练语言模型的过程。这使得模型开始表示和模仿微调数
- 将cmd中命令输出保存为txt文本文件
落难Coder
Windowscmdwindow
最近深度学习本地的训练中我们常常要在命令行中运行自己的代码,无可厚非,我们有必要保存我们的炼丹结果,但是复制命令行输出到txt是非常麻烦的,其实Windows下的命令行为我们提供了相应的操作。其基本的调用格式就是:运行指令>输出到的文件名称或者具体保存路径测试下,我打开cmd并且ping一下百度:pingwww.baidu.com>./data.txt看下相同目录下data.txt的输出:如果你再
- PHP环境搭建详细教程
好看资源平台
前端php
PHP是一个流行的服务器端脚本语言,广泛用于Web开发。为了使PHP能够在本地或服务器上运行,我们需要搭建一个合适的PHP环境。本教程将结合最新资料,介绍在不同操作系统上搭建PHP开发环境的多种方法,包括Windows、macOS和Linux系统的安装步骤,以及本地和Docker环境的配置。1.PHP环境搭建概述PHP环境的搭建主要分为以下几类:集成开发环境:例如XAMPP、WAMP、MAMP,这
- 基于社交网络算法优化的二维最大熵图像分割
智能算法研学社(Jack旭)
智能优化算法应用图像分割算法php开发语言
智能优化算法应用:基于社交网络优化的二维最大熵图像阈值分割-附代码文章目录智能优化算法应用:基于社交网络优化的二维最大熵图像阈值分割-附代码1.前言2.二维最大熵阈值分割原理3.基于社交网络优化的多阈值分割4.算法结果:5.参考文献:6.Matlab代码摘要:本文介绍基于最大熵的图像分割,并且应用社交网络算法进行阈值寻优。1.前言阅读此文章前,请阅读《图像分割:直方图区域划分及信息统计介绍》htt
- 509. 斐波那契数(每日一题)
lzyprime
lzyprime博客(github)创建时间:2021.01.04qq及邮箱:2383518170leetcode笔记题目描述斐波那契数,通常用F(n)表示,形成的序列称为斐波那契数列。该数列由0和1开始,后面的每一项数字都是前面两项数字的和。也就是:F(0)=0,F(1)=1F(n)=F(n-1)+F(n-2),其中n>1给你n,请计算F(n)。示例1:输入:2输出:1解释:F(2)=F(1)+
- 18-115 一切思考不能有效转化为行动,都TM是扯淡!
成长时间线
7月25号写了一篇关于为什么会断更如此严重的反思,然而,之后日更仅仅维持了一周,又出现了这次更严重的现象。从8月2号到昨天8月6号,5天!又是5天没有更文!虽然这次断更时间和上次一样,那为什么说这次更严重?因为上次之后就分析了问题的原因,以及应该如何解决,按理说应该会好转,然而,没过几天严重断更的现象再次出现,想想,经过反思,问题依然没有解决与改变,这让我有些担忧。到底是哪里出了问题,难道我就真的
- 拥有断舍离的心态,过精简生活--《断舍离》读书笔记
爱吃丸子的小樱桃
不知不觉间房间里的东西越来越多,虽然摆放整齐,但也时常会觉得空间逼仄,令人心生烦闷。抱着断舍离的态度,我开始阅读《断舍离》这本书,希望从书中能找到一些有效的方法,帮助我实现空间、物品上的断舍离。《断舍离》是日本作家山下英子通过自己的经历、思考和实践总结而成的,整体内涵也从刚开始的私人生活哲学的“断舍离”升华成了“人生实践哲学”,接着又成为每个人都能实行的“改变人生的断舍离”,从“哲学”逐渐升华成“
- 直返最高等级与直返APP:无需邀请码的返利新体验
古楼
随着互联网的普及和电商的兴起,直返模式逐渐成为一种流行的商业模式。在这种模式下,消费者通过购买产品或服务,获得一定的返利,并可以分享给更多的人。其中,直返最高等级和直返APP是直返模式中的重要概念和工具。本文将详细介绍直返最高等级的概念、直返APP的使用以及与邀请码的关系。【高省】APP(高佣金领导者)是一个自用省钱佣金高,分享推广赚钱多的平台,百度有几百万篇报道,运行三年,稳定可靠。高省APP,
- SQL Server_查询某一数据库中的所有表的内容
qq_42772833
SQLServer数据库sqlserver
1.查看所有表的表名要列出CrabFarmDB数据库中的所有表(名),可以使用以下SQL语句:USECrabFarmDB;--切换到目标数据库GOSELECTTABLE_NAMEFROMINFORMATION_SCHEMA.TABLESWHERETABLE_TYPE='BASETABLE';对这段SQL脚本的解释:SELECTTABLE_NAME:这个语句的作用是从查询结果中选择TABLE_NAM
- 四章-32-点要素的聚合
彩云飘过
本文基于腾讯课堂老胡的课《跟我学Openlayers--基础实例详解》做的学习笔记,使用的openlayers5.3.xapi。源码见1032.html,对应的官网示例https://openlayers.org/en/latest/examples/cluster.htmlhttps://openlayers.org/en/latest/examples/earthquake-clusters.
- Git常用命令-修改远程仓库地址
猿大师
LinuxJavagitjava
查看远程仓库地址gitremote-v返回结果originhttps://git.coding.net/*****.git(fetch)originhttps://git.coding.net/*****.git(push)修改远程仓库地址gitremoteset-urloriginhttps://git.coding.net/*****.git先删除后增加远程仓库地址gitremotermori
- 高端密码学院笔记285
柚子_b4b4
高端幸福密码学院(高级班)幸福使者:李华第(598)期《幸福》之回归内在深层生命原动力基础篇——揭秘“激励”成长的喜悦心理案例分析主讲:刘莉一,知识扩充:成功=艰苦劳动+正确方法+少说空话。贪图省力的船夫,目标永远下游。智者的梦再美,也不如愚人实干的脚印。幸福早课堂2020.10.16星期五一笔记:1,重视和珍惜的前提是知道它的价值非常重要,当你珍惜了,你就真正定下来,真正的学到身上。2,大家需要
- 【加密社】Solidity 中的事件机制及其应用
加密社
闲侃区块链智能合约区块链
加密社引言在Solidity合约开发过程中,事件(Events)是一种非常重要的机制。它们不仅能够让开发者记录智能合约的重要状态变更,还能够让外部系统(如前端应用)监听这些状态的变化。本文将详细介绍Solidity中的事件机制以及如何利用不同的手段来触发、监听和获取这些事件。事件存储的地方当我们在Solidity合约中使用emit关键字触发事件时,该事件会被记录在区块链的交易收据中。具体而言,事件
- 深入理解 MultiQueryRetriever:提升向量数据库检索效果的强大工具
nseejrukjhad
数据库python
深入理解MultiQueryRetriever:提升向量数据库检索效果的强大工具引言在人工智能和自然语言处理领域,高效准确的信息检索一直是一个关键挑战。传统的基于距离的向量数据库检索方法虽然广泛应用,但仍存在一些局限性。本文将介绍一种创新的解决方案:MultiQueryRetriever,它通过自动生成多个查询视角来增强检索效果,提高结果的相关性和多样性。MultiQueryRetriever的工
- Day17笔记-高阶函数
~在杰难逃~
Python笔记python开发语言pycharm数据分析
高阶函数【重点掌握】函数的本质:函数是一个变量,函数名是一个变量名,一个函数可以作为另一个函数的参数或返回值使用如果A函数作为B函数的参数,B函数调用完成之后,会得到一个结果,则B函数被称为高阶函数常用的高阶函数:map(),reduce(),filter(),sorted()1.map()map(func,iterable),返回值是一个iterator【容器,迭代器】func:函数iterab
- Day1笔记-Python简介&标识符和关键字&输入输出
~在杰难逃~
Pythonpython开发语言大数据数据分析数据挖掘
大家好,从今天开始呢,杰哥开展一个新的专栏,当然,数据分析部分也会不定时更新的,这个新的专栏主要是讲解一些Python的基础语法和知识,帮助0基础的小伙伴入门和学习Python,感兴趣的小伙伴可以开始认真学习啦!一、Python简介【了解】1.计算机工作原理编程语言就是用来定义计算机程序的形式语言。我们通过编程语言来编写程序代码,再通过语言处理程序执行向计算机发送指令,让计算机完成对应的工作,编程
- Algorithm
香水浓
javaAlgorithm
冒泡排序
public static void sort(Integer[] param) {
for (int i = param.length - 1; i > 0; i--) {
for (int j = 0; j < i; j++) {
int current = param[j];
int next = param[j + 1];
- mongoDB 复杂查询表达式
开窍的石头
mongodb
1:count
Pg: db.user.find().count();
统计多少条数据
2:不等于$ne
Pg: db.user.find({_id:{$ne:3}},{name:1,sex:1,_id:0});
查询id不等于3的数据。
3:大于$gt $gte(大于等于)
&n
- Jboss Java heap space异常解决方法, jboss OutOfMemoryError : PermGen space
0624chenhong
jvmjboss
转自
http://blog.csdn.net/zou274/article/details/5552630
解决办法:
window->preferences->java->installed jres->edit jre
把default vm arguments 的参数设为-Xms64m -Xmx512m
----------------
- 文件上传 下载 解析 相对路径
不懂事的小屁孩
文件上传
有点坑吧,弄这么一个简单的东西弄了一天多,身边还有大神指导着,网上各种百度着。
下面总结一下遇到的问题:
文件上传,在页面上传的时候,不要想着去操作绝对路径,浏览器会对客户端的信息进行保护,避免用户信息收到攻击。
在上传图片,或者文件时,使用form表单来操作。
前台通过form表单传输一个流到后台,而不是ajax传递参数到后台,代码如下:
<form action=&
- 怎么实现qq空间批量点赞
换个号韩国红果果
qq
纯粹为了好玩!!
逻辑很简单
1 打开浏览器console;输入以下代码。
先上添加赞的代码
var tools={};
//添加所有赞
function init(){
document.body.scrollTop=10000;
setTimeout(function(){document.body.scrollTop=0;},2000);//加
- 判断是否为中文
灵静志远
中文
方法一:
public class Zhidao {
public static void main(String args[]) {
String s = "sdf灭礌 kjl d{';\fdsjlk是";
int n=0;
for(int i=0; i<s.length(); i++) {
n = (int)s.charAt(i);
if((
- 一个电话面试后总结
a-john
面试
今天,接了一个电话面试,对于还是初学者的我来说,紧张了半天。
面试的问题分了层次,对于一类问题,由简到难。自己觉得回答不好的地方作了一下总结:
在谈到集合类的时候,举几个常用的集合类,想都没想,直接说了list,map。
然后对list和map分别举几个类型:
list方面:ArrayList,LinkedList。在谈到他们的区别时,愣住了
- MSSQL中Escape转义的使用
aijuans
MSSQL
IF OBJECT_ID('tempdb..#ABC') is not null
drop table tempdb..#ABC
create table #ABC
(
PATHNAME NVARCHAR(50)
)
insert into #ABC
SELECT N'/ABCDEFGHI'
UNION ALL SELECT N'/ABCDGAFGASASSDFA'
UNION ALL
- 一个简单的存储过程
asialee
mysql存储过程构造数据批量插入
今天要批量的生成一批测试数据,其中中间有部分数据是变化的,本来想写个程序来生成的,后来想到存储过程就可以搞定,所以随手写了一个,记录在此:
DELIMITER $$
DROP PROCEDURE IF EXISTS inse
- annot convert from HomeFragment_1 to Fragment
百合不是茶
android导包错误
创建了几个类继承Fragment, 需要将创建的类存储在ArrayList<Fragment>中; 出现不能将new 出来的对象放到队列中,原因很简单;
创建类时引入包是:import android.app.Fragment;
创建队列和对象时使用的包是:import android.support.v4.ap
- Weblogic10两种修改端口的方法
bijian1013
weblogic端口号配置管理config.xml
一.进入控制台进行修改 1.进入控制台: http://127.0.0.1:7001/console 2.展开左边树菜单 域结构->环境->服务器-->点击AdminServer(管理) &
- mysql 操作指令
征客丶
mysql
一、连接mysql
进入 mysql 的安装目录;
$ bin/mysql -p [host IP 如果是登录本地的mysql 可以不写 -p 直接 -u] -u [userName] -p
输入密码,回车,接连;
二、权限操作[如果你很了解mysql数据库后,你可以直接去修改系统表,然后用 mysql> flush privileges; 指令让权限生效]
1、赋权
mys
- 【Hive一】Hive入门
bit1129
hive
Hive安装与配置
Hive的运行需要依赖于Hadoop,因此需要首先安装Hadoop2.5.2,并且Hive的启动前需要首先启动Hadoop。
Hive安装和配置的步骤
1. 从如下地址下载Hive0.14.0
http://mirror.bit.edu.cn/apache/hive/
2.解压hive,在系统变
- ajax 三种提交请求的方法
BlueSkator
Ajaxjqery
1、ajax 提交请求
$.ajax({
type:"post",
url : "${ctx}/front/Hotel/getAllHotelByAjax.do",
dataType : "json",
success : function(result) {
try {
for(v
- mongodb开发环境下的搭建入门
braveCS
运维
linux下安装mongodb
1)官网下载mongodb-linux-x86_64-rhel62-3.0.4.gz
2)linux 解压
gzip -d mongodb-linux-x86_64-rhel62-3.0.4.gz;
mv mongodb-linux-x86_64-rhel62-3.0.4 mongodb-linux-x86_64-rhel62-
- 编程之美-最短摘要的生成
bylijinnan
java数据结构算法编程之美
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
public class ShortestAbstract {
/**
* 编程之美 最短摘要的生成
* 扫描过程始终保持一个[pBegin,pEnd]的range,初始化确保[pBegin,pEnd]的ran
- json数据解析及typeof
chengxuyuancsdn
jstypeofjson解析
// json格式
var people='{"authors": [{"firstName": "AAA","lastName": "BBB"},'
+' {"firstName": "CCC&
- 流程系统设计的层次和目标
comsci
设计模式数据结构sql框架脚本
流程系统设计的层次和目标
- RMAN List和report 命令
daizj
oraclelistreportrman
LIST 命令
使用RMAN LIST 命令显示有关资料档案库中记录的备份集、代理副本和映像副本的
信息。使用此命令可列出:
• RMAN 资料档案库中状态不是AVAILABLE 的备份和副本
• 可用的且可以用于还原操作的数据文件备份和副本
• 备份集和副本,其中包含指定数据文件列表或指定表空间的备份
• 包含指定名称或范围的所有归档日志备份的备份集和副本
• 由标记、完成时间、可
- 二叉树:红黑树
dieslrae
二叉树
红黑树是一种自平衡的二叉树,它的查找,插入,删除操作时间复杂度皆为O(logN),不会出现普通二叉搜索树在最差情况时时间复杂度会变为O(N)的问题.
红黑树必须遵循红黑规则,规则如下
1、每个节点不是红就是黑。 2、根总是黑的 &
- C语言homework3,7个小题目的代码
dcj3sjt126com
c
1、打印100以内的所有奇数。
# include <stdio.h>
int main(void)
{
int i;
for (i=1; i<=100; i++)
{
if (i%2 != 0)
printf("%d ", i);
}
return 0;
}
2、从键盘上输入10个整数,
- 自定义按钮, 图片在上, 文字在下, 居中显示
dcj3sjt126com
自定义
#import <UIKit/UIKit.h>
@interface MyButton : UIButton
-(void)setFrame:(CGRect)frame ImageName:(NSString*)imageName Target:(id)target Action:(SEL)action Title:(NSString*)title Font:(CGFloa
- MySQL查询语句练习题,测试足够用了
flyvszhb
sqlmysql
http://blog.sina.com.cn/s/blog_767d65530101861c.html
1.创建student和score表
CREATE TABLE student (
id INT(10) NOT NULL UNIQUE PRIMARY KEY ,
name VARCHAR
- 转:MyBatis Generator 详解
happyqing
mybatis
MyBatis Generator 详解
http://blog.csdn.net/isea533/article/details/42102297
MyBatis Generator详解
http://git.oschina.net/free/Mybatis_Utils/blob/master/MybatisGeneator/MybatisGeneator.
- 让程序员少走弯路的14个忠告
jingjing0907
工作计划学习
无论是谁,在刚进入某个领域之时,有再大的雄心壮志也敌不过眼前的迷茫:不知道应该怎么做,不知道应该做什么。下面是一名软件开发人员所学到的经验,希望能对大家有所帮助
1.不要害怕在工作中学习。
只要有电脑,就可以通过电子阅读器阅读报纸和大多数书籍。如果你只是做好自己的本职工作以及分配的任务,那是学不到很多东西的。如果你盲目地要求更多的工作,也是不可能提升自己的。放
- nginx和NetScaler区别
流浪鱼
nginx
NetScaler是一个完整的包含操作系统和应用交付功能的产品,Nginx并不包含操作系统,在处理连接方面,需要依赖于操作系统,所以在并发连接数方面和防DoS攻击方面,Nginx不具备优势。
2.易用性方面差别也比较大。Nginx对管理员的水平要求比较高,参数比较多,不确定性给运营带来隐患。在NetScaler常见的配置如健康检查,HA等,在Nginx上的配置的实现相对复杂。
3.策略灵活度方
- 第11章 动画效果(下)
onestopweb
动画
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- FAQ - SAP BW BO roadmap
blueoxygen
BOBW
http://www.sdn.sap.com/irj/boc/business-objects-for-sap-faq
Besides, I care that how to integrate tightly.
By the way, for BW consultants, please just focus on Query Designer which i
- 关于java堆内存溢出的几种情况
tomcat_oracle
javajvmjdkthread
【情况一】:
java.lang.OutOfMemoryError: Java heap space:这种是java堆内存不够,一个原因是真不够,另一个原因是程序中有死循环; 如果是java堆内存不够的话,可以通过调整JVM下面的配置来解决: <jvm-arg>-Xms3062m</jvm-arg> <jvm-arg>-Xmx
- Manifest.permission_group权限组
阿尔萨斯
Permission
结构
继承关系
public static final class Manifest.permission_group extends Object
java.lang.Object
android. Manifest.permission_group 常量
ACCOUNTS 直接通过统计管理器访问管理的统计
COST_MONEY可以用来让用户花钱但不需要通过与他们直接牵涉的权限
D