h5文件简介
H5文件是层次数据格式第5代的版本(Hierarchical Data Format,HDF5),它是用于存储科学数据的一种文件格式和库文件。由美国超级计算中心与应用中心研发的文件格式,用以存储和组织大规模数据.
H5将文件结构简化成两个主要的对象类型:
1 数据集dataset,就是同一类型数据的多维数组
2 组group,是一种容器结构,可以包含数据集和其他组,若一个文件中存放了不同种类的数据集,这些数据集的管理就用到了group
直观的理解,可以参考我们的文件系统,不同的文件存放在不同的目录下:
目录就是hdf5文件中的group,描述了数据集DataSet的分类信息,通过group有效的将多种dataset进行管理和划分
文件就是hdf5文件中的dataset,表示具体的数据
下图就是数据集和组的关系:

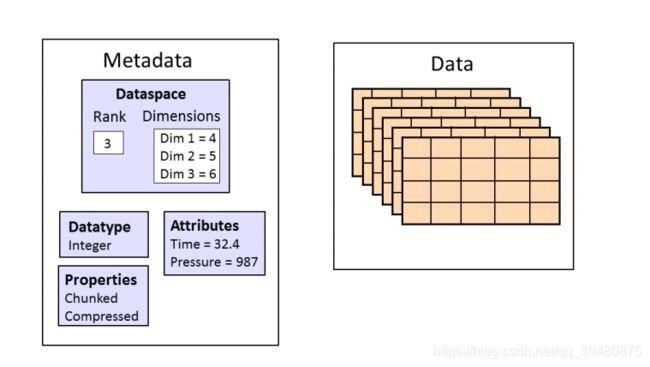
h5文件是一种真正的层次结构,文件系统式的数据类型.另外在数据集中还有元数据,即metadata
对于每一个dataset而言,除了数据本身之外,这个数据集还有很多的属性信息.在hdf5中,同时支持存储数据集对应的属性信息,所有的属性信息的集合叫做metaData,下图是h5文件的数据集的构成
h5py文件是存放两类对象的容器,数据集(dataset)和组(group),dataset类似数组类的数据集合,和numpy的数组差不多。group是像文件夹一样的容器,它好比python中的字典,有键(key)和值(value)。group中可以存放dataset或者其他的group。”键”就是组成员的名称,”值”就是组成员对象本身(组或者数据集),下面来看下如何创建组和数据集。
1.创建一个h5py文件
class File(name, mode=None, driver=None, libver=None, userblock_size=None, **kwds)
打开或创建一个 HDF5 文件,name 为文件名字符串,mode 为打开文件的模式,driver 可以指定一种驱动方式,如需进行并行 HDF5 操作,可设置为 ‘mpio’,libver 可以指定使用的兼容版本,默认为 ‘earliest’,也可以指定为 ‘latest’,userblock_size 以字节为单位指定一个在文件开头称作 user block 的数据块,一般不需要设置。返回所打开文件的句柄。
有效的 mode 参数有:
mode 说明
r 只读,文件必须存在
r+ 读写,文件必须存在
w 创建新文件写,已经存在的文件会被覆盖掉
w- / x 创建新文件写,文件如果已经存在则出错
a 打开已经存在的文件进行读写,如果不存在则创建一个新文件读写,此为默认的 mode
import h5py
#要是读取文件的话,就把w换成r
f=h5py.File("myh5py.hdf5","w")
在当前目录下会生成一个myh5py.hdf5文件
2.创建dataset数据集
create_dataset(self, name, shape=None, dtype=None, data=None, **kwds)
创建一个新的 dataset。以类似文件路径的形式指明所创建 dataset 的名字 name,shape 以一个 tuple 或 list 的形式指明创建 dataset 的 shape,用 “()” 指明标量数据的 shape,dtype 指明所创建 dataset 的数据类型,可以为 numpy dtype 或者一个表明数据类型的字符串,data 指明存储到所创建的 dataset 中的数据。如果 data 为 None,则会创建一个空的 dataset,此时 shape 和 dtype 必须设置;如果 data 不为 None,则 shape 和 dtype 可以不设置而使用 data 的 shape 和 dtype,但是如果设置的话,必须与 data 的 shape 和 dtype 兼容。
三种方式
import h5py
import numpy as np
f=h5py.File("myh5py.hdf5","w")
#分别创建dset1,dset2,dset3这三个数据集
#有现成的numpy数组,可以在创建数据集的时候就赋值,不必指定数据的类型和形状了,只需要把数组名传给参数data。
a=np.arange(20)
d1=f.create_dataset("dset1",data=a)
#dset2是数据集的name,(3,4)代表数据集的shape,i代表的是数据集的元素类型
d2=f.create_dataset("dset2",(3,4),'i')
d2[...]=np.arange(12).reshape((3,4)) #赋值
#直接按照下面的方式创建数据集并赋值
f["dset3"]=np.arange(15)
for key in f.keys():
print(f[key].name)
print(f[key].value)
输出:
/dset1
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
/dset2
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
/dset3
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
3. 创建group组
create_group(self, name, track_order=False)
创建一个新的 group。以类似目录路径的形式指明所创建 group 的名字 name,如果 track_order 为 True,则会跟踪在当前 group 下的 group 和 dataset 创建的先后顺序。该方法可以在打开的文件句柄(相当于 “/” group)或者一个存在的 group 对象上调用,此时 name 的相对路径就是相对于此 group 的。
import h5py
import numpy as np
f=h5py.File("myh5py.hdf5","w")
#创建一个名字为bar的组
g1=f.create_group("bar")
#在bar这个组里面分别创建name为dset1,dset2的数据集并赋值。
g1["dset1"]=np.arange(10)
g1["dset2"]=np.arange(12).reshape((3,4))
for key in g1.keys():
print(g1[key].name)
print(g1[key].value)
输出:
/bar/dset1
[0 1 2 3 4 5 6 7 8 9]
/bar/dset2
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
注意观察数据集dset1和dset2的名字有点和前面的不一样,如果是直接创建的数据集,不在任何组里面,那么它的名字就是**/+名字**,现在这两个数据集都在bar这个group(组)里面,名字就变成了**/bar+/名字**,有点文件夹的感觉。
import h5py
import numpy as np
f=h5py.File("myh5py.hdf5","w")
#创建组bar1,组bar2,数据集dset
g1=f.create_group("bar1")
g2=f.create_group("bar2")
d=f.create_dataset("dset",data=np.arange(10))
#在bar1组里面创建一个组car1和一个数据集dset1。
c1=g1.create_group("car1")
d1=g1.create_dataset("dset1",data=np.arange(10))
#在bar2组里面创建一个组car2和一个数据集dset2
c2=g2.create_group("car2")
d2=g2.create_dataset("dset2",data=np.arange(10))
#根目录下的组和数据集
print(".............")
for key in f.keys():
print(f[key].name)
#bar1这个组下面的组和数据集
print(".............")
for key in g1.keys():
print(g1[key].name)
#bar2这个组下面的组和数据集
print(".............")
for key in g2.keys():
print(g2[key].name)
#顺便看下car1组和car2组下面都有什么,估计你都猜到了为空。
print(".............")
print(c1.keys())
print(c2.keys())
输出:
.............
/bar1
/bar2
/dset
.............
/bar1/car1
/bar1/dset1
.............
/bar2/car2
/bar2/dset2
.............
[]
[]
————————————————
参考:https://www.cnblogs.com/abella/p/11125466.html
https://blog.csdn.net/csdn15698845876/article/details/73278120
https://www.jianshu.com/p/de9f33cdfba0