R-CNN详解
本篇文章为R-CNN的总结, R-CNN论文精读详见我的博客:
论文精读:R-CNN:Rich feature hierarchies for accurate object detection and semantic segmentation..._梦回沈园外的博客-CSDN博客1.论文核心我们提出了一种简单且可扩展的检测算法,相对于之前对VOC2012的最佳结果,它将平均平均精度(mAP)提高了30%以上——实现了53.3%的mAP。我们的方法结合了两个关键的见解:(1)可以应用高容量卷积神经网络(CNN)自底而上的地区建议为了定位和分段对象和(2)标记训练数据稀缺,监督预训练辅助任务,其次是特定领域的微调,产生显著的性能提升。由于我们将区域建议与CNN结合起来,我们称我们的方法为R-CNN:具有CNN特征的区域。2.主要内容2.1 Abstract https://blog.csdn.net/qq_52053775/article/details/124906672
1.概述
相较于传统的目标检测算法,转换为region的特征获取问题和proposals的分类问题。
2.算法流程
R-CNN的算法流程,如图4所示。在一幅图像上进行目标检测时,R-CNN首先使用selective search建议框提取方法,在图像中选取大约2000个建议框。接着,将每个建议框调整为同一尺寸(227×227)并送入AlexNet 中提取特征,得到特征图。然后,对每个类别,使用该类别的SVM分类器对得到的所有特征向量进行打分,得到这幅图像中的所有建议框对应于每个类别的得分。随后,同样在每个类别上独立地对建议框使用贪心的非极大值抑制的方法进行筛选,过滤1oU^大于一个特定阔值的分类打分较低的建议框,并使用边界框回归的方法对建议框的位置与大小进行微调。使之对目标的包围更加精确,如图所示。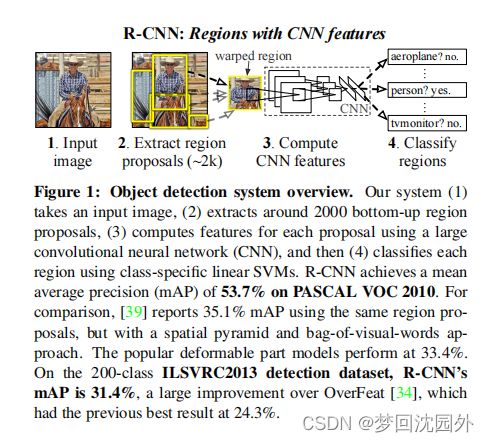

2 训练过程
1. 预训练与CNN参数调优
R-CNN中使用的AlexNet是在ILSVRC 2012分类数据集上进行预训练的。在预训练过程中,AlexNet的输入为227×227的ILSVRC训练集图像,输出的最后4096维特征到ILSVRC分类数据集上1000类的映射。这样的预训练使得分类任务中获得了较强的特征提取能力。
为了使CNN想指任务和领城,预训练完成后,还需要在Pascal VOC据集上进行参数的调优。在调优阶段,Alexnet的输人不再是定整的图像,而是调整到227×227的建议框(使用selective search或其他外部方法在训练集图像提取)。CNN的输出也由原本包含1000个神经元的分类层替换成一个随机初后化的包含N+1个神经元的分类层,其中N代表类别个数,1代表背景。对于Pascal VOC数据集,N=20。
在训练数据中,正样本为与某一标定的真值边界框的IoU大于等于0.5的建议框,而负样本为与标定的真值边界框的IoU小于0.5的建议框。在进行CNN调优训练时,一个mini-batch 中有128个样本(32个为正样本,96个为负样本)。
2. SVM训练
在R-CNN中,CNN用于提取特征,在对目标进行分类时使用的是SVM分类器。因为SVM是二分类器,所以,对于每个类别,都要训练一个SVM分类器。SVM分类器的输入是经过CN提取的4096维的特征向量,输出是属于该类别的得分 在训练时,正样本为标定的真值边思框经过CNN提取的特征向量,而负样本为与所有标定的真值边界框的loU都小于0.3的建议框经过CNN提取的特征向量。因为负样本的数量非常多,所以应采用难负样本挖掘(standard -hard negativemining)的方法选取有代表性的负样本。
R-CNN中的难负例挖掘就是采用了这种自举法(bootstrap)的方法:
- 先用初始的正负样本训练分类器(此时为了平衡数据,使用的负样本也只是所有负样本的子集)
- 用训练好的分类器对样本进行分类,把其中错误分类的那些样本(hard negative)放入负样本子集,
- 再继续训练分类器,
- 如此反复,直到达到停止条件(比如分类器性能不再提升).
此处选择负样本时IoU的國值(0.3)与微调时loU的阙值(0.5)并不相同。因为CNN在样本数量较少时容易发生过拟合,所以需要大量的训练数据,故在微调时不对1oU进行严格的限制。而SVM更适用于小样本训练,故对样本IOU的原制严格,同时能提高定位的准确度。
另外,R-CNN使用SVM进行分类,而不使用CNN最后一层的sofmax函数进行分类原因是微调 CNN和训练 SVM时采用的正负样本的阈值不同。调优训练的正样本定义宽松,并不强调位置的精确性,SVM正样本只有标定的真值边界。框。调优训练的负样本是随机抽样的,而SVM的负样本是通过难负样本挖掘的方法筛选出来的。在将SVM作为分类器时,mAP为54.2%。在将softmax函数作为分类器时,mAP为50.9%。
(3) 边界框回归
作者使用一个简单的边界框回归阶段来提高定位性能。在使用特定类的检测SVM对每个选择性搜索建议进行评分后,我们预测一个新的边界框回归器使用特定类的边界框进行检测。这在精神上类似于在deformable part models模型[17]中使用的边界框回归。这两种方法的主要区别在于,这里我们从CNN计算的特征回归,而不是从推断的DPM部分位置计算的几何特征回归。
训练算法的输入是一组N个训练对{(Pi,Gi)}i=1,...,N,其中Pi=(Pix,Piy,Piw,Pih)指定了建议Pi的边界框中心的像素坐标以及以像素为单位的宽度和高度。因此,我们去掉上标i,除非需要它。每个地面真实边界框G都以相同的方式指定:G=(Gx、Gy、Gw、Gh)。我们的目标是学习一个转换,它将一个提议的框P映射到一个地面真实框G。
我们用四个函数dx(P)、dy(P)、dw(P)和dh(P)来参数化这个变换(边框的高层特征)。前两个指定P边界框中心的尺度不变平移,而第二两个指定P边界框的宽度和高度的对数空间平移。在学习了这些函数后,我们可以通过应用变换将输入建议P转换为预测的地面真值框![]()
(候选框高层特征与底层图像候选框的转换关系)

每个函数d![]() (P)(
(P)( 是x,y,h,w)中的一个,被建模的建议框P的第五层poor层特征的线性函数,用
是x,y,h,w)中的一个,被建模的建议框P的第五层poor层特征的线性函数,用![]() 表示。(隐式地假设了
表示。(隐式地假设了![]() 对图像数据的依赖性。)这样就有
对图像数据的依赖性。)这样就有![]() ,
,![]() 是一个可学习的模型参数的向量。学习
是一个可学习的模型参数的向量。学习![]() 通过优化正则化最小二乘目标(岭回归):
通过优化正则化最小二乘目标(岭回归):

回归的目标是![]() 对于训练对(P,G),被定义为:
对于训练对(P,G),被定义为:
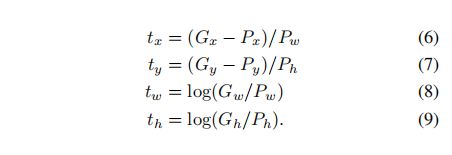
作为一个标准的正则化最小二乘问题,它可以有效地求解。
在实现边界框回归时,作者发现了两个微妙的问题。首先,正则化很重要:我们基于验证集设置了λ=1000。第二个问题是,在选择使用哪个训练对(P,G)时必须小心。直观地说,如果P远离所有的地面真盒,那么将P转换为地面真盒G的任务就没有意义了。使用像P这样的例子会导致一个无望的学习问题。因此,我们只有当建议P靠近至少一个地面真值盒时,才能从它中学习。当且仅当重叠大于一个阈值(我们使用验证集将其设置为0.6)时,我们通过将P分配给地面真值框G(在它具有最大的地面真值重叠的情况下)来实现“接近性”。所有未分配的提案都将被丢弃。我们对每个对象类这样做一次,是为了学习一组特定于类的边界框回归变量。
在测试时,只对每个提案进行评分,并预测其新的检测窗口一次。原则上,我们可以迭代这个过程(即,对新预测的边界框进行重新评分,然后从中预测一个新的边界框,等等)。然而,作者发现迭代并不能改善结果。