论文阅读:Augmenting Document Representations for Dense Retrieval with Interpolation and Perturbation
利用插值和扰动增强密集检索的文档表示
ACL2022
摘要
密集检索模型以在密集表示空间上检索与输入查询最相关的文档为目标,因其显著的成功而受到广泛关注。此外,密集模型需要大量标记的训练数据才能获得显著的性能,而获取由人类注释的查询文档对通常很困难。为了解决这个问题,我们提出了一个简单但有效的文档增强密集检索(DAR)框架,该框架通过插值和扰动来增强文档的表示。我们用两个基准数据集验证了DAR在检索任务中的性能,表明所提出的DAR在密集检索标记和未标记文档方面显著优于相关基线。
引言
检索系统的目标是检索与输入查询最相关的文档,并且由于它们作为各种应用程序的核心元素,特别是开放域问答(QA)的核心元素而备受关注(V oorhees,1999)。开放域QA是一项从大量文档中回答问题的任务,通常需要两个组件,一个检索器和一个阅读器(Chen等人,2017;Karpukhin等人,2020)。具体来说,检索器对与问题相关的文档进行排序,阅读器使用检索到的文档回答问题。
传统的稀疏检索方法,如BM25(Robertson et al.,1994)和TF-IDF依赖于基于词汇的匹配,因此存在词汇不匹配问题:由于与查询的词汇差异,检索相关文档失败。为了解决这一问题,最近的研究集中于密集检索模型,以生成查询和文档的可学习密集表示(Karpukhin等人,2020)。
尽管最近取得了成功,但由于几个原因,密集检索方案仍然存在一些挑战。首先,密集检索模型需要大量标记训练数据才能获得良好的性能。然而,如下图所示,标记的查询文档对的比例非常小,因为几乎不可能依靠人类对大型文档语料库进行注释。其次,为了使检索模型适应不断出现新文档的现实世界,显然应该考虑处理训练期间看不到的未标记文档,但仍然具有挑战性。
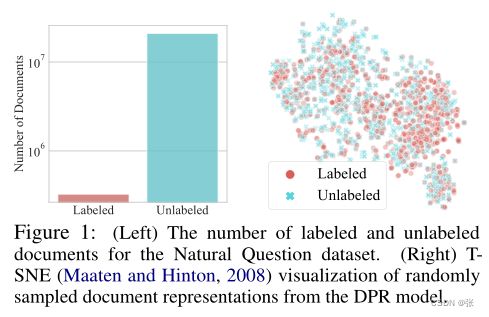
为了自动扩展查询文档对,最近的工作从生成模型生成查询(Liang等人,2020;Ma等人,2021)或合并来自其他数据集的查询(Qu等人,2021),然后生成额外的增强查询和文档对。然而,这些查询增强方案具有严重而明显的缺点。首先,为数据集中的每个文档增加查询是不可行的(参见上图中未标记文档的数量),因为生成和配对查询非常昂贵。其次,即使在获得新的配对之后,我们也需要额外的训练步骤来将生成的配对反映在检索模型上。第三,这种查询扩展方法不会给文档添加变化,只会给查询添加变化,因此处理大量未标记的文档可能不是最佳方法。
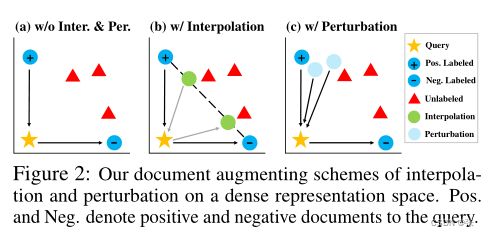
由于增加附加查询的成本很高,因此问题是否可以只操作给定的查询-文档配对来处理大量未标记的文档。为了回答这个问题,我们首先可视化了标记和未标记文档的嵌入。图1显示了标记和未标记文档之间没有明显的分布变化。因此,仅操作标记文档以处理附近的未标记文档以及标记文档可能是有效的。利用这一观察结果,我们提出了一种用于密集检索器的新的文档增强方法,该方法不仅插值了与标记查询相关的两个不同的文档表示(图2(b)),而且还随机干扰了带有丢失掩码的标记文档的表示(图2(c))。我们的方案的一个显著优点是,因为它只处理文档的表示,所以我们的模型不需要查询文档对的显式注释步骤,这使得它非常高效。我们将我们的总体方法称为文档增强密集检索(DAR)。
我们在标准开放域QA数据集上实验验证了我们的方法,即自然问题(NQ)(Kwiatkowski等人,2019)和TriviaQA(Joshi等人,2017)(TQA),对照检索模型的各种评估指标。实验结果表明,我们的方法显著提高了未标记和标记文档的检索性能。此外,对所提出模型的详细分析表明,插值和随机扰动对整体性能有积极影响。
我们在这项工作中的贡献有三点:
•我们建议为密集检索模型增加文档,以解决查询文档对标签不足的问题。
•我们提出了两种用于密集检索器的新文档增强方案:文档表示的插值和扰动。
•我们表明,我们的方法在开放域QA任务中对标记和未标记的文档都实现了出色的检索性能。
Related Work
Dense Retriever 密集检索模型(Lee等人,2019;Karpukhin等人,2020)已获得广泛关注,它为查询和文档生成密集表示。然而,密集检索面临着来自有限训练数据的关键挑战。最近的工作通过生成额外的查询文档对来将这些对扩展到原始的密集检索模型(Liang等人,2020;Ma等人,2021;Qu等人,2021)或通过正则化模型(Rosset等人,2019)来解决这一问题。然而,与我们在训练阶段自动增加数据的方法不同,这些方法在训练检索器之前需要大量的计算资源来进行显式查询文档配对的额外生成步骤。
Data Augmentation 由于数据增强对深度神经网络的性能至关重要,它被广泛应用于各种领域(Shorten和Khoshgoftaar,2019;Hedderich等人,2021),其中插值和扰动是主要方法。Mixup插值两个项目,例如图像像素,以增加训练数据(Zhang等人,2018;V erma等人,2019),这也适用于非线性规划(Chen等人,2020;Yin等人,2021)。然而,以前的工作都没有显示混合在检索任务中的有效性。除了插值,Wei和Zou(2019)和Ma(2019年)提出了对词的扰动,Lee等人(2021b)提出了词嵌入的扰动。Jeong等人(2021)和Gao等人(2021)扰动了文本嵌入,以生成不同的句子,并在无监督学习中增强了正句子对。相比之下,我们在有标签文档的监督环境中处理密集检索、干扰文档表示和丢失(Srivastava等人,2014)。
Method
我们从密集检索的定义开始。
Dense Retrieval 给定一对查询q和文档d,密集检索的目标是根据密集表示q和d正确计算它们之间的相似性得分,如下所示:
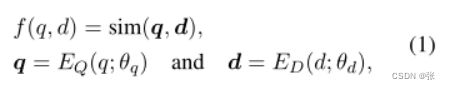
其中f是度量查询文档对之间相似性的评分函数,sim是相似性度量,如余弦相似性,EQ和ED分别是查询和文档的密集编码器,参数θ=(θq,θd)。
密集检索方案通常使用负采样策略来区分相关的查询文档对和无关的查询文档,这为查询和文档生成了有效的表示空间。我们将相关的查询文档对指定为(q,d+)∈ τ+,一个不相关的对为(q,d−) ∈ τ −, 其中τ+∩ τ − = ∅.
目标函数如下: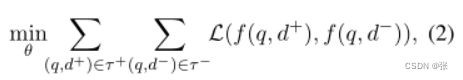
其中损失函数L是肯定文档的负对数似然。我们的目标是通过使用文档的插值或扰动来操作文档,从而增加一组查询文档对,我们将在接下来的段落中对此进行解释。
带混合的插值
如图2的插值所示,我们旨在增强位于两个标记文档之间的文档表示,以获得更多的查询文档对,这可能有助于处理两个标记文档中的未标记文档。为了实现这一目标,我们建议插入正负文档(d+,d−) 对于给定的查询q,采用混合(Zhang等人,2018)。
请注意,由于编码器ED的输入文档是离散的,我们使用文档的输出嵌入来插值它们,如下所示:
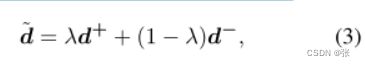
其中~d是给定查询q的正负文档的混合表示,λ∈ [0, 1]. 然后,我们优化模型,将插值文档和查询之间的相似度sim(q,~d)估计为具有二进制交叉熵损失的软标签λ。将交叉熵损失的输出加到等式2中的原始损失上。我们方案的一个显著优点是等式2中的负对数似然损失使正对的相似性得分最大,同时使负对的得分最小;因此,在任意查询文档对之间没有中间相似性。然而,我们可以通过插入正负文档来获得具有软标签的查询文档对,而不是严格的正负类。
带脱落的随机扰动
除了我们在两个标记文档的插值空间中处理未标记文档的内插方案之外,我们还旨在干扰标记文档以处理其附近的未标记文档,如图2(c)所示。为了做到这一点,我们随机屏蔽由文档编码器ED获得的带标签文档的表示,其中我们从伯努利分布中采样屏蔽。换句话说,如果我们从分布中采样n个不同的掩码,我们会得到n个不同查询文档对?(q,d+i)?i=n i=1来自一个正对(q,d+)。
通过这样做,我们通过替换等式2中的单个正对(q,d+)来增加n倍的正查询文档对。此外,由于文档扰动与插值正交,我们进一步在扰动的正文档d+i和负文档d之间进行插值− 对于等式3中的给定查询,从扰动中增加软查询文档对。
效率
数据扩充方法通常容易效率低下,因为它们需要大量的资源来生成数据并将生成的数据转发到大型语言模型中。然而,由于我们的插值和扰动方法只处理已经从编码器ED获取文档的表示,我们不必重新生成文档文本,也不必将生成的文档转发到模型中,这大大节省了时间和内存(见表3)。我们在附录B.1中对效率进行了详细分析和讨论。
总结:
本文提出的方法比较特殊,采用的是插值和扰动来增强文档的表示,主要是为了解决密集模型需要大量标记的训练数据才能获得显著的性能,因为类似于DPR模型,它检索出的未标记文档基本上都是围绕已标记文档。同时,DAR只处理文档的表示,所以我们的模型不需要查询文档对的显式注释步骤,这使得它非常高效。
当然本文也有一些缺点,例如该工作继承的是DPR抽取式阅读器找答案的过程,而如果检索到的所有的passage中都不存在答案的区间,那这个训练过程就是无意义的,且这些passage都将是噪声。另外,作者是基于句子进行抽取的,而有些答案可能存在跨句子的情况,或者答案存在多个句子里,同时也并未采用候选段落Ranker。