Pytorch 自学笔记(自用)
第二章 构造神经网络*
一、torch.Tensor/torch.function是什么?
- Tensor是核心类,要进行反向传播,直接调用.backward()。自动计算所有的梯度,累加进属性.grad中
- 终止Tensor在计算图中的追踪回溯,执行.detach()
- 也可采用代码块的方式 with torch.no_grad():,适用于对模进行预测的时候,不需要计算梯度
二、使用步骤
代码如下(示例):
x1=torch.ones(3,3)
print(x1)
x=torch.ones(2,2,requires_grad=True)
print(x)
y=x+2
print(y)
z=y*y*3
out=z.mean()
print(z,out)

方法.requires_grad_():该方法可以原地改变Tensor的属性。requires_grad的值,如果没有主动设定默认为False
a=torch.randn(2,2)
a=((a*3)/(a-1))
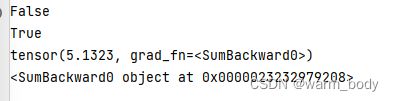
print(a.requires_grad)
a.requires_grad_(True)
print(a.requires_grad)
b=(a*a).sum()
print(b)
print(b.grad_fn)
2.读入数据
代码如下(示例):
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
使用Pytorch构建一个神经网络
提示:torch.nn,依赖于sutograd来定义模型,并对其自动求导
构建流程
- 定义一个拥有科学系参数的神经网络
- 遍历训练数据集
- 处理输入数据使其流经神经网络
- 计算损失值
- 网络参数的梯度进行反向传播
- 以一定的规则更新网络的权重
import torch
import torch.nn as nn
import torch.nn.functional as F
#定义一个简单的网络类
class Net (nn.Module):
def __init__(self):
super(Net,self).__init__()
#定义第一层卷积神经网络,输入通道维度=1,输出通道维度=6,卷积核大小3*3
self.conv1=nn.Conv2d(1,6,3)
#定义第二层卷积神经网络,输入通道维度=6,输出通道维度=16,卷积核大小3*3
self.conv2=nn.Conv2d(6,16,3)
#定义三层全连接网络
self.fc1=nn.Linear(16*6*6,120)
self.fc2=nn.Linear(120,84)
self.fc3=nn.Linear(84,10)
def forward(self,x):
#在(2,2)的池化窗口进行最大池化操作
x=F.max_pool2d(F.relu(self.conv1(x)),(2,2))
x=F.max_pool2d(F.relu(self.conv2(x)),2)
x=x.view(-1,self.num_flat_features(x))#扁平化或者直接.Flattern()
x=F.relu(self.fc1(x))
x=F.relu(self.fc2(x))
x=self.fc3(x)
return x
def num_flat_festures(self,x):
#计算size,除了第0个维度上的batch——size
size =x.size()[1:]
num_features=1
for s in size:
num_features *=s
return num_features
net =Net()
print(net)

模型中的所有训练参数,可以通过net.parameters()来获得
net =Net()
# print(net)
params=list(net.parameters())
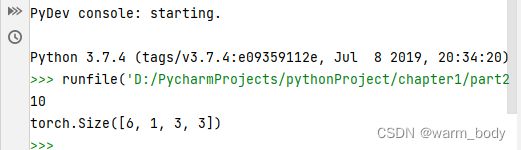
print(len(params))
print(params[0].size())
input =torch.randn(1,1,32,32)
out = net(input)
net.zero_grad()#梯度归零
out.backward(torch.randn(1,10))#反向传播
损失函数
pair:(output,target),计算出一个数值来评估output和target之间的差距大小
nn.MSELoss就是计算均方差损失来评估输入和目标值之间的差距
input =torch.randn(1,1,32,32)
output = net(input)
target=torch.randn(10)
target =target.view(1,-1)#-1是为了匹配input维度
crierion=nn.MSELoss()
loss=crierion(output,target)
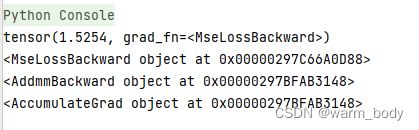
print(loss)
print(loss.grad_fn)
print(loss.grad_fn.next_functions[0][0])#反向传播
print(loss.grad_fn.next_functions[0][0].next_functions[0][0])
更新网络参数
最简单的算法就是SGD(随机梯度下降)
具体表达式为:weight=weight-learning_rate*gradient
#传统的SGD代码 weight=weight-learning_rate*gradien
learning_rate=0.01
for f in net.parameters():
f.data.sub_(f.grad * learning_rate)#就地减法
#官方pytorch推荐代码
#首先导入优化器的包,optim中包含很多优化算法 SGD,ADAM等
import torch.optim as optim
#通过optimal创建优化器对象
optimizer=optim.SGD(net.parameters(),lr=0.01)
#将优化器梯度清零
optimizer.zero_grad() ####必写代码
output=net(input)
loss=crierion(output,target)
#对损失值进行反向传播操作
loss.backward()####必写代码
#参数更新
optimizer.step()####必写代码