池化技术总结
池化技术总结
主要用的池化操作有平均池化、最大池化、全局平均池化,全局自适应池化。此外还有很多,如RoI池化、金字塔池化、重叠池化、随机池化、双线性池化等。
池化的作用
-
抑制噪声,降低信息冗余。
-
提升模型的尺度不变性、旋转不变性。
-
降低模型计算量。
-
防止过拟合。
此外,最大池化作用:保留主要特征,突出前景,提取特征的纹理信息。平均池化作用:保留背景信息,突出背景。这两者具体后面会介绍,这里只介绍它们的作用。
池化回传梯度
池化回传梯度的原则是保证传递的loss(或者说梯度)总和不变。根据这条原则很容易理解最大池化和平均池化回传梯度方式的不同。
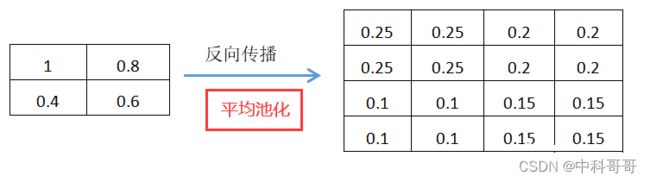
平均池化的操作是取每个块( 如2x2 )的平均值,作为下一层的一个元素值,因此在回传时,下一层的每一元素的loss(或者说梯度)要除以块的大小( 如2x2 = 4),再分配到块的每个元素上,这是因为该loss来源于块的每个元素。
注意:如果块的每个元素直接使用下一层的那个梯度,将会造成Loss之和变为原来的N倍。具体如下图。
最大池化的操作是取每个块的最大值作为下一层的一个元素值,因此下一个元素的Loss只来源于这个最大值,因此梯度更新也只更新这个最大值,其他值梯度为0。因此,最大池化需要在前向传播中记录最大值所在的位置,即max_id。这也是最大池化与平均池化的区别之一。具体如下图所示:

最大池化与平均池化的使用场景
根据最大池化的操作,取每个块中的最大值,而其他元素将不会进入下一层。众所周知,CNN卷积核可以理解为在提取特征,对于最大池化取最大值,可以理解为提取特征图中响应最强烈的部分进入下一层,而其他特征进入待定状态(之所以说待定,是因为当回传梯度更新一次参数和权重后,最大元素可能就不是在原来的位置取到了)。
一般而言,前景的亮度会高于背景,因此,正如前面提到最大池化具有提取主要特征、突出前景的作用。但在个别场合,前景暗于背景时,最大池化就不具备突出前景的作用了。
因此,当特征中只有部分信息比较有用时,使用最大池化。如网络前面的层,图像存在噪声和很多无用的背景信息,常使用最大池化。
同理,平均池化取每个块的平均值,提取特征图中所有特征的信息进入下一层。因此当特征中所有信息都比较有用时,使用平均池化。如网络最后几层,最常见的是进入分类部分的全连接层前,常常都使用平均池化。这是因为最后几层都包含了比较丰富的语义信息,使用最大池化会丢失很多重要信息。
空间金字塔池化
首先尝试一下用几句话介绍一下空间金字塔池化的背景,空间金字塔池化出自目标检测的SPPNet中,在目标检测中需要生成很多区域候选框,但这些候选框的大小都不一样,这些候选框最后都需要进入分类网络对候选框中的目标进行分类,因此需要将候选框所在区域变成一个固定大小的向量,空间金字塔池化就是解决这么一个问题。
下面是具体做法。
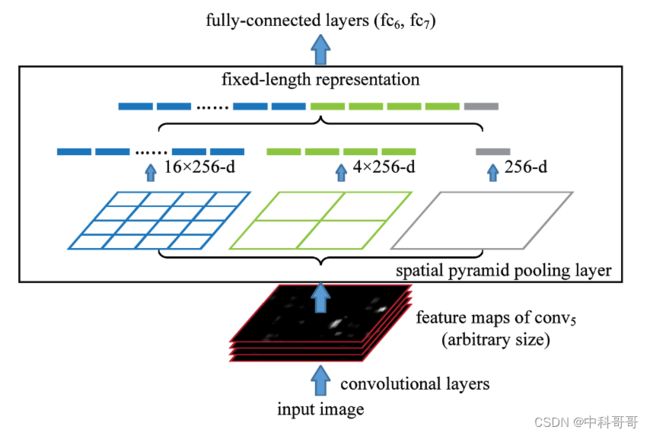
对于一个通道数为C的feature map,一取全局最大值,得到一个1xC的张量,二将feature map分割成4块,在每一块上进行最大池化,得到一个4xC的张量,三将feature map分成16块,在每块上进行最大池化,得到一个16xC的张量,将这三个张量拼接起来,得到一个大小为21xC的张量。对于任意大小的feature map经过这些操作都可以得到固定大小的张量。
RoI池化
RoI即Region of Interest,RoI池化是空间金字塔池化的一种特殊形式。
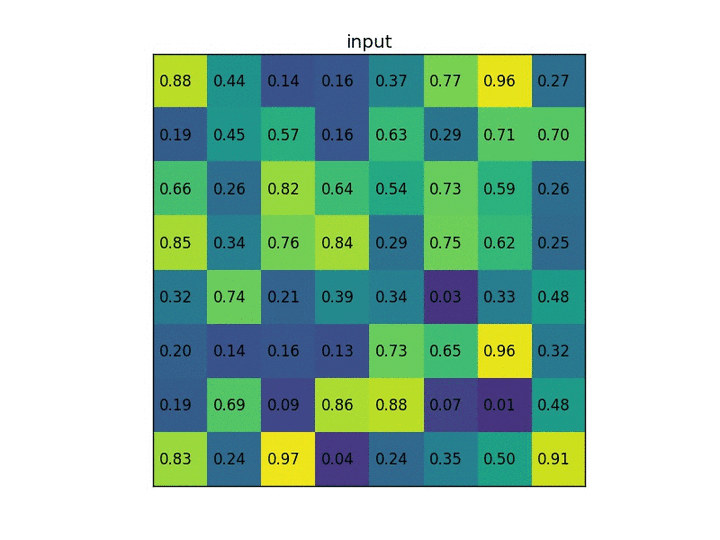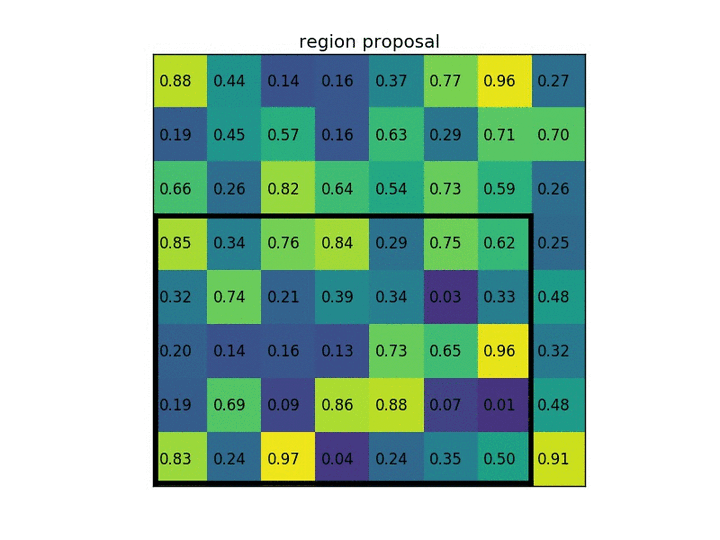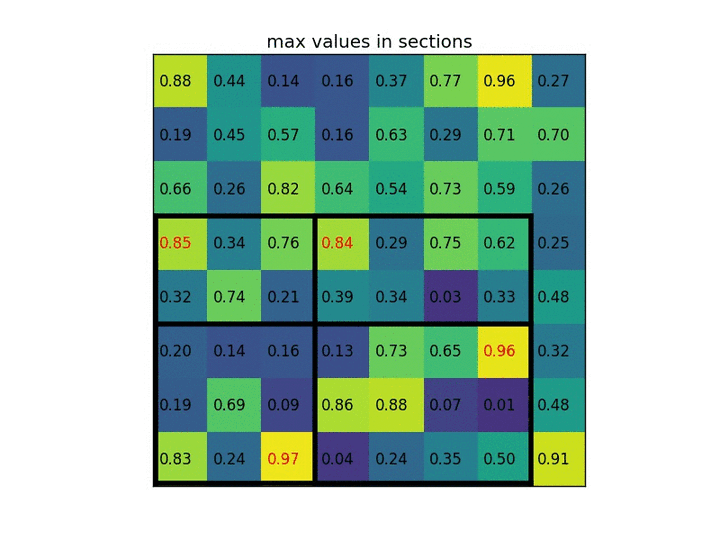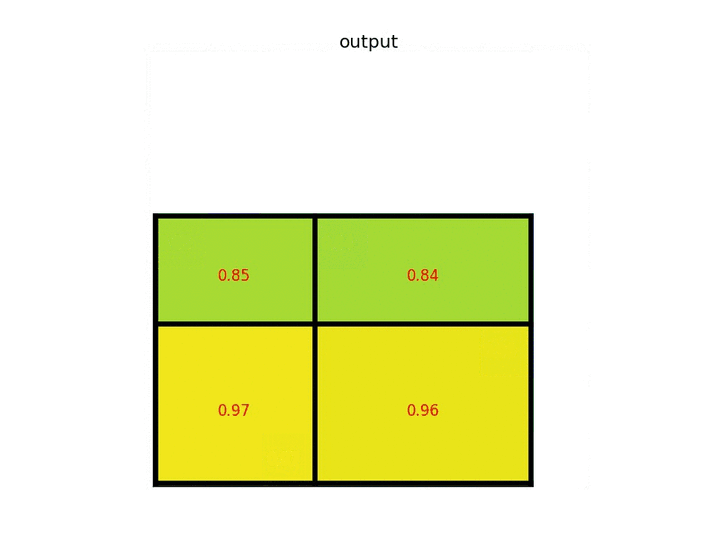
让我们考虑一个小例子,看看它是如何工作的。我们将在单个8×8特征图上执行感兴趣区域,一个感兴趣的区域和2×2的输出大小。我们的输入要素图如下所示:(以下为图像,一般处理时转化像素为映射到0~1的实数,保持精度)
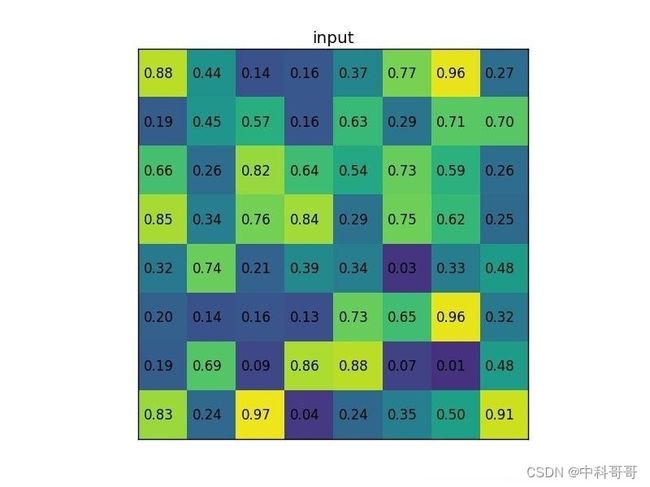
假设我们还有一个区域建议(左上角,右下角坐标)(0,3),(7,8)。在图片中它看起来像这样:

通常,每个都有多个功能图和多个提案,但我们为这个例子保持简单。
通过将其划分为(2×2)个部分(因为输出大小为2×2),我们得到:
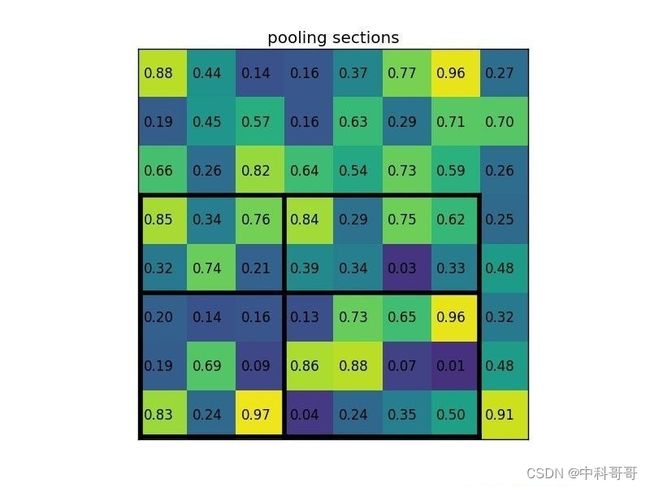
请注意,感兴趣区域的大小不必完全被池化部分的数量整除(在这种情况下)我们的RoI是7×5,我们有2×2汇集部分)。 每个部分的最大值是:
关于RoI Pooling最重要的事情是什么
- 它用于对象检测任务
- 它允许我们重新使用卷积网络中的特征映射
- 它可以显着加快训练(train)和测试时间
- 它允许以端到端的方式训练物体检测系统
其他类型的池化
重叠池化(Overlapping Pooling):一般而言,池化的窗口大小等于步长,因此池化作用区域不存在重合部分。所谓重叠池化,即池化窗口大小大于步长,池化作用区域存在重合部分,这种池化也许有一定的效果。
随机池化(Stochastic Pooling):在一个池化窗口内对feature map的数值进行归一化得到每个位置的概率值,然后按照此概率值进行随机采样选择,即元素值大的被选中的概率也大。该池化的优点是确保了特征图中非最大响应值的神经元也有可能进入下一层被提取,随机池化具有最大池化的优点,同时由于随机性它能够避免过拟合。
全局自适应池化:其原理也是对于任意大小的feature map,都可以输出指定的大小。这背后的原理不知是否与RoI池化类似,即对于输入大小为HxW的feature map,指定输出大小为7x7,我猜测其可能就是将HxW分成7x7块再进行最大池化或平均池化。但真实情况需要阅读源码方可知。若有知情读者,可在公众号中留言指出。
此外还有双线性池化等不是很常用的池化,这里不作过多介绍。