生活不如意?不如来学习一下GAN(Generative Adversarial Nets) 论文精读
说明:论文原文Generative Adversarial Nets (nips.cc),文中图片均来自该论文。
ABS
提出了一种框架(GAN),该框架通过对抗过程来评估生成模型。
框架中有两个模型:生成模型 G G G和辨别模型 D D D, G G G用来提取数据的分布从而生成人造数据, D D D用来评估样本来自训练数据集的可能性(即样本是真实的可能性)。 G G G的目标是让 D D D尽可能犯错误(类似于博弈游戏)。在最优情况下, G G G完全吻合原始数据的特性,此时 D D D输出的概率全部是 50 50% 50。该框架不需要任何的马尔可夫链(条件概率相互依赖)。
1 Intro
基于反向传播的识别算法已经取得了巨大的成功。而深度生成模型因为种种原因并没有取得很好的进展。作者提出了一种能够跨过现有困难的框架的生成模型评估方法——对抗网络(adversarial nets)。
作者举了一个例子:将生成模型 G G G比作是一个假币制造者,而把辨别模型 D D D比做一个警察。 G G G需要尽可能制造难以辨别的假币, D D D需要尽可能的识别假币。两者之间的竞争关系使得 G G G的“造假”水平和 D D D的辨别能力都能得到提升,在最终情况会期望达到一种平衡(博弈论中叫做纳什均衡,但这里的平衡似乎并那么那是平衡:警察最终无法辨别,而Faker却获得成功)。
G G G和 D D D最简单的情况下都是是MLP(多层感知机),文中的 G G G将的输入初始是一个随机的高斯分布,通过训练让 G G G(通过调整MLP的参数)能使输出数据尽可能的接近真实数据。过程中使用了反向传播和dropout。
2 Related work
其他工作中大多数都是基于最大似然估计进行推理。
而生成随机网络(不需要马尔科夫链)可以生成想要的样本。
作者指出自己的工作与VAEs(variational autoencoders)有一定的相似之处,但是不完全相同。
NCE(Noise-contrastive estimation)也训练识别模型,但是识别模型由噪声分布和模型分布的概率密度的比率来定义(这样定义需要能够同时对两个模型进行评估和反向传播)。
predictability minimization中也有两个网络,但是不同于GAN,第一个网络中的隐藏单元会尽可能的输出与另一个网络不同的输出,而另一个网络的隐藏层会尽可能地输出与第一个网络相同的输出。
3 Adversarial nets
以标量为例,来说明两个网络需要做的事情,首先我们需要定义一些符号:
- x x x表示真实数据;
- p d a t a p_{data} pdata表示真实数据的概率密度;
- p g p_g pg表示 G G G最终学习到的概率密度;
- p z p_z pz表示 G G G初始概率密度(一般是一个高斯分布);
- G ( z ; θ g ) G(z;\theta_g) G(z;θg)表示生成网络的输出(本文使用MLP, θ g \theta_g θg是MLP的参数, D D D中参数同理);
- D ( x ; θ d ) D(x;\theta_d) D(x;θd)表示辨别网络的输出,该输出表示 x x x(这里的 x x x仅仅表示 D D D的输入)来自真实数据的概率。
正如前面介绍的,两个网络有着各自的目标:
- 辨别网络 D D D的目标:当输入是真实数据是,输出应该尽可能靠近 1 1 1;当输入是人造数据时,输出应该尽可能的靠近0。
- 生成网络 G G G的目标是:生成的数据让辨别网络的输出尽可能的靠近 1 1 1,这里我们转换成最大化: l o g ( 1 − D ( G ( z ) ) ) log(1-D(G(z))) log(1−D(G(z))),也就是让 D ( G ( z ) ) D(G(z)) D(G(z))尽可能的靠近 1 1 1。
对于 D D D和 G G G的目标可以用一个方程来表示:
m i n G m a x D V ( D , G ) = E [ l o g D ( x ) ] + E [ l o g ( 1 − D ( G ( z ) ) ) ] ( 1 ) \underset {G}{min}\ \underset {D}{max}V(D,G) = E[logD(x)]+E[log(1-D(G(z)))] \quad (1) Gmin DmaxV(D,G)=E[logD(x)]+E[log(1−D(G(z)))](1)
上述公式需要拆开来看:
- 对于 G G G,需要 m i n ( E [ l o g D ( x ) ] + E [ l o g ( 1 − D ( G ( z ) ) ) ] ) = m i n ( E [ l o g ( 1 − D ( G ( z ) ] min(E[logD(x)] + E[log(1-D(G(z)))])=min(E[log(1-D(G(z)] min(E[logD(x)]+E[log(1−D(G(z)))])=min(E[log(1−D(G(z)],这是因为对于 G G G来说能产生联系的是 z z z而不用关心 x x x;
- 对于 D D D,需要 m a x ( E [ l o g D ( x ) ] + E [ l o g ( 1 − D ( G ( z ) ) ) ] ) max(E[logD(x)] + E[log(1-D(G(z)))]) max(E[logD(x)]+E[log(1−D(G(z)))])。
实际的训练:
- 直接最优化 D D D是行不通的,这很容易导致过拟合,作者提出了一种训练方法通过对 D D D进行 k k k次优化的同时加入对 G G G进行一次优化,这样让两个网络同时进行训练,只要 G G G更新的足够慢, D D D就会收敛到最优解,整个算法过程如Algorithm 1所示。
- 在训练一开始由于 G G G生成的数据非常不好, D D D有很大的概率直接让 l o g ( 1 − D ( G ( z ) ) ) log(1-D(G(z))) log(1−D(G(z)))等于0,这样进行反向传播的时候, G G G会非常难训练(梯度一开始会非常小),所以采用了一种转换:在训练的时候让 G G G去最大化 l o g ( D ( G ( z ) ) ) log(D(G(z))) log(D(G(z)))。

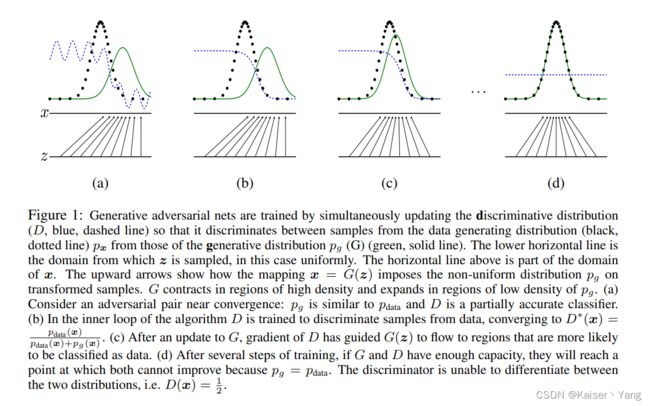 Figure 1是Algorithm 1的一个简单情况的可视化:
Figure 1是Algorithm 1的一个简单情况的可视化:
- 绿色的线代表 G G G生成的数据,黑色的点代表真实的数据,蓝色虚线代表 D D D的输出;
- 在一开始 G G G会生成一个高斯分布这个分布与真实数据差距较远,而 D D D的能力较差,预测结果存在震荡情况,如(a)所示;
- 此时对 D D D进行 k k k次的优化,理想情况下 D D D会收敛(收敛的具体值在下一小节中证明),如(b)所示;
- 此时对 G G G进行 1 1 1次优化,会使得输出更加靠近真实值,如(c)所示;
- 在最终的情况下,两者会到一种平衡状态,此时 D D D的输出始终是 1 2 \frac 1 2 21而 G G G的输出与真实值完全一样,如(d)所示。
4 Theoretical Results
4.1 Global Optimality of p g = p d a t a p_g=p_{data} pg=pdata
存在全局的最优解 p g = p d a t a p_g = p_{data} pg=pdata,下面进行详细的说明。
Proposition 1:当 G G G固定时,对于 D D D存在最优解:
D G ∗ ( x ) = p d a t a ( x ) p d a t a ( x ) + p g ( x ) ( 2 ) D^*_G(x) = \frac {p_{data}(x)} {p_{data}(x) + p_g(x)} \quad(2) DG∗(x)=pdata(x)+pg(x)pdata(x)(2)
上面的公式很好理解,下面进行证明:
最优解就是让 V ( G , D ) V(G,D) V(G,D)最大的点,而:
V ( G , D ) = ∫ x p d a t a ( x ) l o g ( D ( x ) ) d x + ∫ z p z ( z ) l o g ( 1 − D ( G ( z ) ) ) d z = ∫ x p d a t a ( x ) l o g ( D ( x ) ) + p g ( x ) l o g ( 1 − D ( x ) ) d x ( 将 z 看成 x 的函数 z ( x ) ) ( 3 ) \begin{align*} V(G,D)&= \int_x p_{data}(x)log(D(x))dx + \int_zp_z(z)log(1-D(G(z)))dz \\ &= \int_x p_{data}(x)log(D(x))+p_g(x)log(1-D(x))dx(将z看成x的函数z(x)) \quad (3) \end{align*} V(G,D)=∫xpdata(x)log(D(x))dx+∫zpz(z)log(1−D(G(z)))dz=∫xpdata(x)log(D(x))+pg(x)log(1−D(x))dx(将z看成x的函数z(x))(3)
而 p d a t a ( x ) l o g ( D ( x ) ) + p g ( x ) l o g ( 1 − D ( x ) ) p_{data}(x)log(D(x))+p_g(x)log(1-D(x)) pdata(x)log(D(x))+pg(x)log(1−D(x))的最大值在 D ( x ) = p d a t a ( x ) p d a t a ( x ) + p g ( x ) D(x)=\frac {p_{data}(x)} {p_{data}(x) + p_g(x)} D(x)=pdata(x)+pg(x)pdata(x)处取得(因为 a l o g ( y ) + b l o g ( 1 − y ) alog(y) +blog(1-y) alog(y)+blog(1−y)的最大值在 y = a a + b y=\frac a {a + b} y=a+ba处取得,其中 0 ≤ y ≤ 1 , a + b ≠ 0 , a ≥ 0 , b ≥ 0 0\le y\le 1, a+b \ne 0, a\ge 0, b \ge 0 0≤y≤1,a+b=0,a≥0,b≥0)。
将(2)带入(1)中我们可以得到:
C ( G ) = m D a x V ( G , D ) = E p d a t a [ l o g p d a t a ( x ) p d a t a ( x ) + p g ( x ) ] + E p g [ p g ( x ) p d a t a ( x ) + p g ( x ) ] ( 4 ) \begin{align*} C(G) &= \underset D max V(G, D)\\ &= E_{p_{data}}[log\frac {p_{data}(x)} {p_{data}(x) + p_g(x)}]+E_{p_g}[\frac {p_{g}(x)} {p_{data}(x) + p_g(x)}] \quad (4) \end{align*} C(G)=DmaxV(G,D)=Epdata[logpdata(x)+pg(x)pdata(x)]+Epg[pdata(x)+pg(x)pg(x)](4)
Theorem 1:当且仅当 p g = p d a t a p_g = p_{data} pg=pdata时 C ( G ) C(G) C(G)取最小值 − l o g 4 -log4 −log4,即 G G G此时达到最优。
证明需要用到一些统计的知识:K-L散度和J-S散度
C ( G ) = − l o g 4 + E ( l o g 2 ) + E p d a t a [ l o g p d a t a ( x ) p d a t a ( x ) + p g ( x ) ] + E ( l o g 2 ) + E p g [ p g ( x ) p d a t a ( x ) + p g ( x ) ] = − l o g 4 + K L D ( p d a t a ∣ ∣ p d a t a + p g 2 ) + K L D ( p g ∣ ∣ p d a t a + p g 2 ) = − l o g 4 + 2 J S D ( p d a t a ∣ ∣ p g ) \begin{align*} C(G) &= -log4 + E(log2) + E_{p_{data}}[log\frac {p_{data}(x)} {p_{data}(x) + p_g(x)}]+E(log2)+E_{p_g}[\frac {p_{g}(x)} {p_{data}(x) + p_g(x)}]\\ &=-log4 + KLD(p_{data}||\frac {p_{data}+p_g} {2}) + KLD(p_{g}||\frac {p_{data}+p_g} {2})\\ &=-log4 + 2JSD(p_{data}||p_g) \end{align*} C(G)=−log4+E(log2)+Epdata[logpdata(x)+pg(x)pdata(x)]+E(log2)+Epg[pdata(x)+pg(x)pg(x)]=−log4+KLD(pdata∣∣2pdata+pg)+KLD(pg∣∣2pdata+pg)=−log4+2JSD(pdata∣∣pg)
J-S散度是一个非负数,当且仅当 p d a t a = p g p_{data}=p_g pdata=pg时取 0 0 0所以上式的最小值位 − l o g 4 -log4 −log4(G的目标是取最小值)。
注:
K L D 的定义: K L D ( p ∣ ∣ q ) = E p ( l o g p q ) = ∫ p ( x ) ( l o g p ( x ) − l o g q ( x ) ) d x K L D 性质:( 1 )非负;( 2 )非对称性: K L D ( p ∣ ∣ q ) ≠ K L D ( q ∣ ∣ p ) J S D 的定义: J S D ( p ∣ ∣ q ) = 1 2 ( K L D ( p ∣ ∣ m ) + K L D ( q ∣ ∣ m ) ) 其中 m = p + q 2 J S D 性质:( 1 )非负;( 2 )对称性 \begin{align*} &KLD的定义:KLD(p||q)=E_p(log\frac p q)=\int p(x)(logp(x)-logq(x))dx\\ &KLD性质:(1)非负;(2)非对称性: KLD(p||q)\ne KLD(q||p)\\ &JSD的定义:JSD(p||q)=\frac 1 2(KLD(p||m)+KLD(q||m)) \quad 其中m=\frac{p+q} 2\\ &JSD性质:(1)非负;(2)对称性 \end{align*} KLD的定义:KLD(p∣∣q)=Ep(logqp)=∫p(x)(logp(x)−logq(x))dxKLD性质:(1)非负;(2)非对称性:KLD(p∣∣q)=KLD(q∣∣p)JSD的定义:JSD(p∣∣q)=21(KLD(p∣∣m)+KLD(q∣∣m))其中m=2p+qJSD性质:(1)非负;(2)对称性
4.2 Convergence of Algorithm 1
Proposition 2:在算法1的过程中只要 D D D在过程能够到达最优解,那么 p g p_g pg会收敛于 p d a t a p_{data} pdata,证明略。
即使在实际的训练中我们并没有更新 p g p_g pg而是更新MLP的参数,但是这同样可以获得不错的表现。
5 Experiments
在MNIST,TFD,CIFAR-10上做了实验。实验结果如Table 1所示(表格中的数字越大,效果越好):
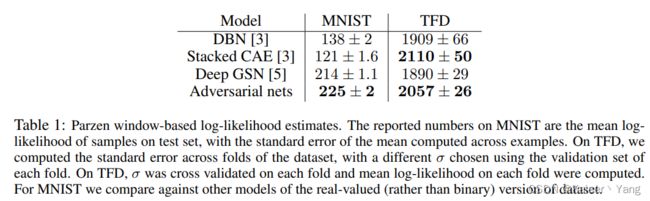

Figure 2展示了生成的图片(最右边应该是真实数据)。

Figure 3表示:两张图的的最左边和最右边的数字时真实的,中间的数字是通过线性插值生成的。
6 Advantages and disadvantages
缺点:
- 并没有直接给出 p d a t a p_{data} pdata;
- 训练过程中要求 D D D和 G G G同步更新,对于调参来说不太容易;
优点:
- 不需要马尔可夫链;
- 在训练过程不需要推理;
- G的反向传播并不依照真实数据进行而是根据D来进行;
- 能拟合退化的分布(或噪声比较强)。
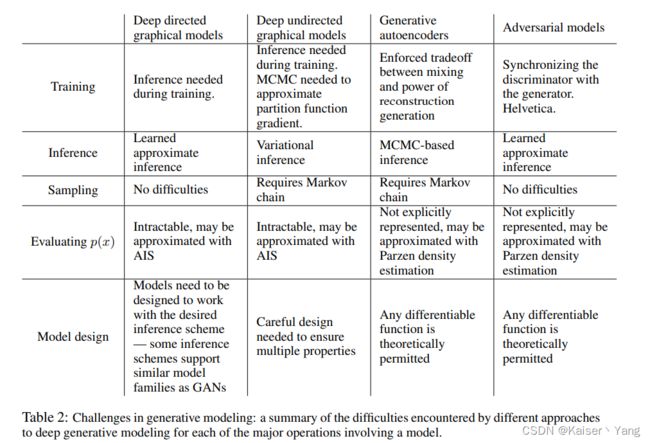
Table 2是一份详细的总结,第一行是模型名称,第一列是方面。
7 Conclusion and future work
可以增加的拓展:
- 可以通过对 G G G和 D D D增加输入来训练条件概率分布;
- 可以通过训练一个备用网络对于给定的 x x x预测 z z z来进行近似推理(approximate inference);
- 可以训练多个条件下的条件概率分布;
- 当有标记的数据有限时,辨别器所识别的特点能够提升分类的效果;
- 通过更好的方法来协调 G , D G,D G,D可以加快训练速度。