【TensorRT】onnx转成TensorRT开发踩坑记录(Win10+cuda11.1+TensorRT7.2.2.3)(持续更新)
onnx转成TensorRT开发注意点
本博客基于以下关于将onnx转成TensorRT的开源项目,在开发过程中记录出错或者一些需要注意的点。
onnx_tensorrt_project
环境配置:
Win10
Nvidia472.88显卡驱动
cuda11.1
TensorRT7.2.2.3
注意点:
1.TensorRT将onnx模型转成engine模型时
(即执行mBuilder->buildEngineWithConfig(*mNetwork, *mConfig))
跟当前的显卡计算能力有关。
如果在一个低计算能力的显卡的机器上生成的engine模型直接放到另一台高计算能力的显卡的机器上时会报错,必须是相同计算能力显卡上生成的engine文件才可以直接使用。
所以建议在哪个机器上调用engine模型时就在哪个机器上对图像进行推理,重点在于显卡不能更换。
而显卡的计算能力可以参照英伟达的这张显卡计算能力表
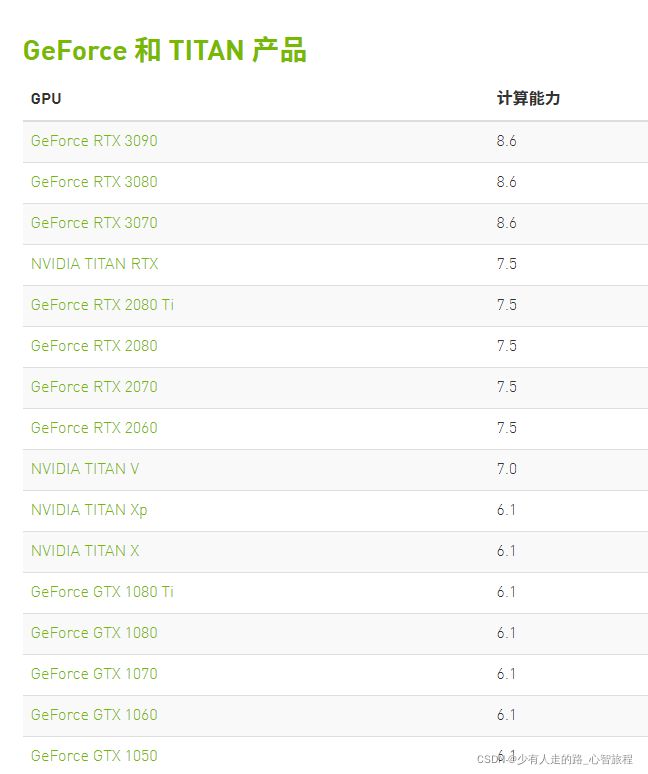
参考资料:
Your GPU Compute Capability
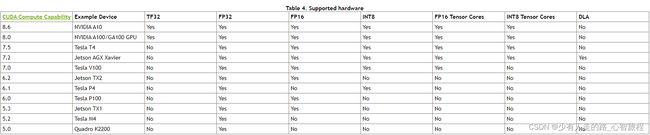
2.TensorRT在计算能力为6.1的显卡上不支持FP16模式的加速,可以参照以下表格
而计算能力为6.1的有以下型号的显卡,比如10系列的GeForce GTX
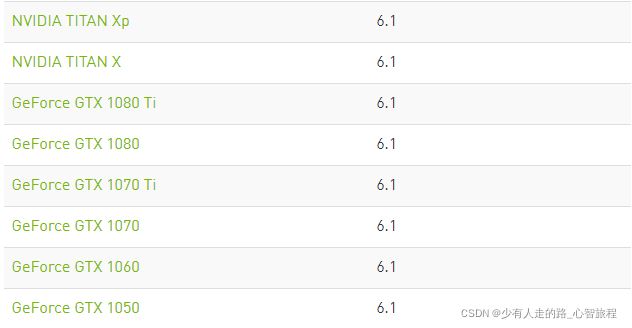
实际测试下来,能跑得通,但是速度与显存和FP32的一样。
参考资料:
NVIDIA TENSORRT DOCUMENTATION
3.基于C++开发时最后测速度时,记得要把Debug模式切换成Release模式,否则速度不如理想的快。

4.注意如果想要遍历所有图片来测试速度时,发现隔几张图片后速度就会突然变得很慢,然后又恢复正常,接着变慢,那么可以看下是否是内存溢出问题。
如果是内存溢出的话,看下是否使用了类似cv::imwrite()的函数,使得不断将数据写入硬盘中。如果有的话取消掉,问题应该就会解决。
5.注意解析onnx模型的时候,如果正常的通道排序应该是(batch_size,channel,height,width)
但是C++下的opencv调用resize时通道排序是(width,height),顺序有点不同。
转onnx的python代码:
var=torch.ones((batch_size,3,resize_height,resize_width))
var=var.type(torch.cuda.FloatTensor)
model.eval()
model = model.to(device)
torch.onnx.export(model, var, output_onnx_path,opset_version=11,verbose=True)
解析onnx的C++代码:
std::shared_ptr<Trt> onnx_net;
m_InputW = onnx_net->mBindingDims[0].d[3];
m_InputH = onnx_net->mBindingDims[0].d[2];
6.yolov4的pth生成的onnx,如果是在FP16模式下转成engine的时间会非常长,测试下来时间需要49分钟,需要耐心等待。
目前本人已经尝试过的解决方案(都没成功):
a.本人将yolov4的各个模块拆解下来做实验看是哪个模块导致这么长时间的,发现mish激活函数就会占用很长时间(如果将Mish换成Relu的话,转engine的时间会缩短20分钟),本人又替换了等价Mish函数的写法,时间仍然很长。
b.本人也在NVIDIA官网上提交过自己issue,目前还没得到解决方案:
【TensorRT】buildEngineWithConfig too slow in FP16
c.用TensorRT8.2版本来转成engine文件,时间略微缩短点,需要42分钟。
欢迎大佬提出一些可行的解决方案可以能更快速地将yolov4的onnx模型转成engine模型,感激不尽
yolov4的模型用的是以下开源项目地址:
https://github.com/bubbliiiing/yolov4-pytorch
模型的百度网盘链接:
链接: https://pan.baidu.com/s/1WlDNPtGO1pwQbqwKx1gRZA
提取码: p4sc
7.TensorRT在INT8模式下需要输入一些图片来做校准表,而这需要输入指定的校准类型,batch_size,宽,高和图像路径,其中的图像路径就是包含了需要输入图像的路径。
而这个图像路径不能包含中文,否则会报错。
nvinfer1::IInt8Calibrator* calibrator = GetInt8Calibrator(calibratorType, mBatchSize, input_w, input_h, img_dir, calib_table_name, "calibrator", false);
8.TensorRT在多显卡下的使用:
其实需要做的工作不多,在建立builder和反序列化模型(deserialize)时前面加上cudasetDevice(Device)就行。
以及将数据从内存拷贝到显存时也要加cudaSetDevice(Device)
参考资料:
多线程下创建多个tensorrt实例
但是本人发现一个目前网上没有提到但是会报错的点:
就是如果在多显卡下开启多个线程的话,在将第一个onnx模型序列化成engine模型后,如果不析构这个类直接继续将第二个onnx模型序列化成engine模型的话,会有报错出现。
Serialization Error in nvinfer1::rt::CoreReadArchive::verifyHeader: 0 (Magic tag does not match)
所以一定要注意序列化模型的代码的最后自己手动析构掉,然后再去重新实例化这个类,调用这个生成好的engine模型进行推理。
9.目前实验发现如果内存占用较大的情况下,TensorRT推理的速度会慢几毫秒。
所以如果想尽可能提升推理速度的话,把其他软件都关闭,节省内存。
10.关于cudastream的一个问题
如果在初始化类的时候,对cudastream没有赋一个nullptr的初值的话,使用C++来执行cudaStreamCreate(&mCudaStream)不会有问题;
但是如果是C++生成dll,再让C#调用此dll来执行的话,有的时候cudaStreamCreate(&mCudaStream)会报错而闪退。
推测可能的原因是C++和C#分配未赋初值变量的机制不同的关系。
所以最好的做法是在初始化类的时候对cudastream赋一个nullptr,然后在调用析构函数的时候判断mCudaStream是否未nullptr。
如果只是将onnx转为engine模型的话,cudastream理论上一直是nullptr,那就不执行cudaStreamCreate(&mCudaStream);如果进行过推理的话,那cudastream就不再是nullptr,那就执行cudaStreamCreate(&mCudaStream)。
cudaStream_t mCudaStream = nullptr;
if (mCudaStream != nullptr)
{
cudaStreamDestroy(mCudaStream);
mCudaStream = nullptr;
}
11.推理速度不稳定
目前本人将碰到过的情况汇总到另一篇博客上去(因为篇幅实在太长的关系)
【C++】【TensorRT】检测时间不稳定原因汇总(持续更新)
后续会不断补充。