2022.11.6 第7次周报
目录
- 摘要
- 经典卷积神经网络学习
-
- LeNet-5
- AlexNet
- TensorFlow学习
-
- Fetch和Feed代码实现
- 非线性回归代码实现
- 文献阅读
-
- 主要内容
- 自然语言处理中的深度学习
- 从图像到文本
- 白盒攻击
- 黑盒攻击
- 存在问题及解决方法
- 总结
摘要
本周学习了卷积神经网络经典模型LeNet-5、AlexNet,了解了AlexNet如何在LeNet-5上取得更低的错误率;除此之外,本周还学习了TensorFlow的用法,了解了图的创建及启动、会话的定义及默认图的启动、变量的使用、Fetch 和 Feed的使用等,通过非线性回归的实现对学习的内容进行了一个大致的梳理与总结。
经典卷积神经网络学习
LeNet-5
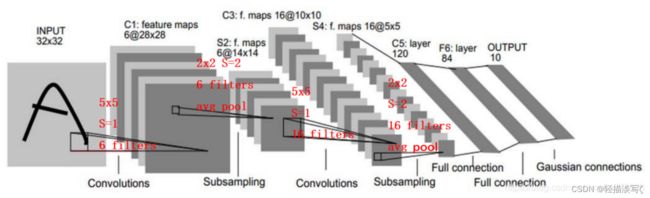
# LeNet5
import torch
from torch import nn
from torch.nn import functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5) # (H+2p-K)/S + 1
self.pool1 = nn.AvgPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.pool2 = nn.AvgPool2d(2)
self.fc1 = nn.Linear(5 * 5 * 16, 120)
self.fc2 = nn.Linear(120, 84)
def forward(self, x):
x = torch.tanh(self.conv1(x))
x = self.pool1(x)
x = torch.tanh(self.conv2(x))
x = self.pool2(x)
x = x.view(-1, 5 * 5 * 16)
x = torch.tanh(self.fc1(x))
output = F.softmax(self.fc2(x), dim=1) # (samples, features)
# 使用模型可视化工具torchinfo可以模拟输入,查看模型信息。
from torchinfo import summary
net = Model()
summary(net, input_size=(10, 1, 32, 32))
运行结果:
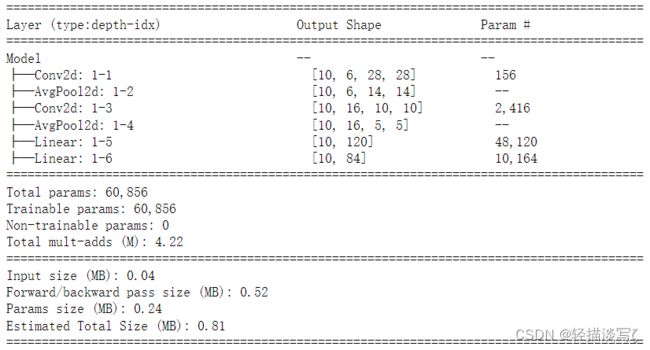
AlexNet
AlexNet出现之前,大规模视觉识别最好成绩一直由手工提取特征+支持向量机的算法获得,最低错误率为25.8%。2012年,AlexNet一下将错误率降低到了15.3%。

# AlexNet
class Model(nn.Module):
def __init__(self):
super().__init__()
# 为了处理尺寸较大的原始图片,先使用11x11的卷积核和较大的步长来快速降低特征图的尺寸
# 同时,使用比较多的通道数,来弥补降低尺寸造成的数据损失
self.conv1 = nn.Conv2d(3, 96, kernel_size=11, stride=4)
self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2) # overlap pooling
# 已经将特征图尺寸缩小到27x27,计算量可控,可以开始进行特征提取了
# 卷积核、步长恢复到业界常用的大小,进一步扩大通道来提取数据
self.conv2 = nn.Conv2d(96, 256, kernel_size=5, padding=2)
self.pool2 = nn.MaxPool2d(kernel_size=3, stride=2)
# 疯狂提取特征,连续用多个卷积层
# kernel 5, padding 2, kernel 3, padding 1 可以维持住特征图的大小
self.conv3 = nn.Conv2d(256, 384, kernel_size=3, padding=1)
self.conv4 = nn.Conv2d(384, 384, kernel_size=3, padding=1)
self.conv5 = nn.Conv2d(384, 256, kernel_size=3, padding=1)
self.pool3 = nn.MaxPool2d(kernel_size=3, stride=2)
# 进入全连接层,进行信息汇总
self.fc1 = nn.Linear(6 * 6 * 256, 4096) # 上层所有特征图上的所有像素
self.fc2 = nn.Linear(4096, 4096)
self.fc3 = nn.Linear(4096, 1000)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(x)
x = F.relu(self.conv2(x))
x = self.pool2(x)
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = F.relu(self.conv5(x))
x = self.pool3(x)
x = x.view(-1, 6 * 6 * 256) # 将数据拉平
x = F.dropout(x, p=0.5)
x = F.relu(F.dropout(self.fc1(x), p=0.5))
x = F.relu(self.fc2(x))
output = F.softmax(self.fc3(x), dim=1)
net = Model()
summary(net, input_size=(10, 3, 227, 227))
运行结果:

相比于LeNet5,AlexNet主要做出了如下改变:
- 卷积核更小、网络更深、通道数更多
- 使用了ReLU激活函数
- 使用了Dropout层来控制模型复杂度,控制过拟合
- 引入了大量传统或新兴的图像增强技术来扩大数据集,进一步缓解过拟合
- 使用GPU对网络进行训练,加速了网络的训练与推断
TensorFlow学习
Tensorflow是一个编程系统,使用图( graphs )来表示计算任务,图( graphs )中的节点称之为op( operation ) ,一个op获得0个或多个Tensor,执行计算,产生0个或多个Tensor。Tensor看作是一个n维的数组或列表。图必须在会话( Session)里被启动。
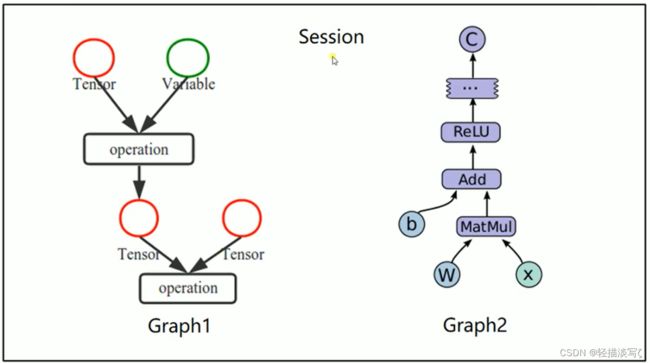
- 使用图( graphs )来表示计算任务
- 在被称之为会话(Session )的上下文( context )中执行图使用tensor表示数据
- 通过变量( Variable )维护状态
- 使用feed和fetch可以为任意的操作赋值或者从其中获取数据
Fetch和Feed代码实现

非线性回归代码实现
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 使用numpy生成200个随机点
x_data = np.linspace(-0.5,0.5,200)[:,np.newaxis] # 从-0.5~0.5之间选取200个均匀分布的点 [:,np.newaxis]增加一个维度,200行1列
noise = np.random.normal(0,0.02,x_data.shape) # 生成一些干扰随机值,类型和x_data一致
y_data = np.square(x_data) + noise
# 定义两个placeholder
tf.compat.v1.disable_eager_execution()
x = tf.compat.v1.placeholder(tf.float32,[None,1]) # [None,1]: None表示可以为任意形状,只有一列
y = tf.compat.v1.placeholder(tf.float32,[None,1])
# 构建简单神经网络解决回归问题
# 定义神经网络中间层
Weights_L1 = tf.Variable(tf.random.normal([1,10]))# 赋值随机常数,一行十列
biases_L1 = tf.Variable(tf.zeros([1,10]))# 赋值为0,一行十列
Wx_plus_b_L1 = tf.matmul(x,Weights_L1) + biases_L1
L1 = tf.nn.tanh(Wx_plus_b_L1)# 运用tanh激活函数
# 定义神经网络输出层
Weights_L2 = tf.Variable(tf.random.normal([10,1]))
biases_L2 = tf.Variable(tf.zeros([1,1]))
Wx_plus_b_L2 = tf.matmul(L1,Weights_L2) + biases_L2
prediction = tf.nn.tanh(Wx_plus_b_L2)
# 二次代价函数
loss = tf.reduce_mean(tf.square(y - prediction))
# 使用梯度下降法训练
train_step =tf.compat.v1.train.GradientDescentOptimizer(0.1).minimize(loss)
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer()) # 变量初始化
for _ in range(2000):
sess.run(train_step,feed_dict={x:x_data,y:y_data})
# 获得预测值
prediction_value = sess.run(prediction,feed_dict={x:x_data})
# 画图
plt.figure()
plt.scatter(x_data,y_data)
plt.plot(x_data,prediction_value,'r-',lw = 5) # r-:红色实线,lw:线宽为5
plt.show()
运行结果:

文献阅读
论文题目:Adversarial Attacks on Deep-learning Models in Natural Language Processing: A Survey
地址:https://dl.acm.org/doi/abs/10.1145/3374217
主要内容
本文介绍了在深度神经网络上生成文本反例方向上的第一次综合研究。回顾了最近的研究成果,并制定了分类方案来组织现有的文献。此外,我们还从不同的角度对它们进行了总结和分析。我们试图为研究人员提供一个很好的参考,以了解这一研究课题中的挑战、方法和问题,并揭示未来的方向。我们希望基于对抗性攻击的知识提出更健壮的深度神经模型。
自然语言处理中的深度学习
神经网络在自然语言处理领域越来越受欢迎,各种 DNN 模型被用于不同的自然语言处理任务。除了前馈神经网络和卷积神经网络(CNN),递归/递归神经网络(RNN)及其变体是 NLP 中最常用的神经网络,因为它们具有处理序列的天然能力。近年来, NLP 在深度学习方面取得了两个重要突破。它们是序列对序列的学习和注意机制,强化学习和生成模型也越来越受欢迎 。
从图像到文本
对抗性攻击起源于计算机视觉社区,其中 首 次 提 出 了 攻 击 用 于 对 象 识 别 的 dnn 的 对 抗 性 例 子[17,40,95,104,105,132,157]。
向量化文本输入。DNN 模型需要向量作为输入,对于图像任务,通常的方式是使用像素值来形成向量/矩阵作为 DNN 输入。但是对于文本模型,需要特殊的操作来将文本转换成向量。有三个主要的方法分支:基于字数的编码、一键编码和密集编码(或特征嵌入),后两种主要用于文本应用的 DNN 模型。
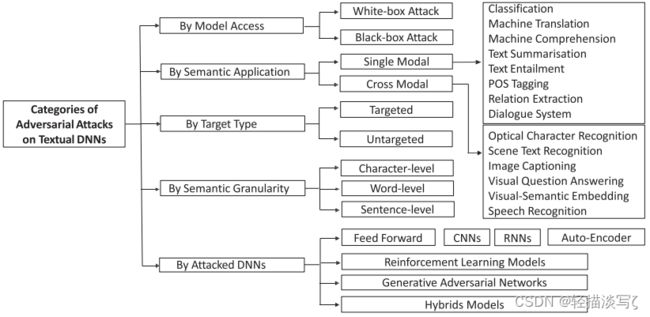
这里五个角度对攻击方法进行了分类:
- 模型访问是指当攻击被执行时对被攻击模型的了解。在接下来的部分中,我们将着重从这个角度进行讨论。
- 语义应用是指通过不同的自然语言处理应用的方法。更详细的讨论将在第节提供。
- 目标类型是指攻击的目标是实施不正确的预测或针对特定结果。
- 语义粒度考虑模型在什么粒度级别上受到攻击。
- 被攻击的 dnn 是我们在第节讨论过的受害者 dnn。
白盒攻击
在白盒攻击中,攻击需要访问模型的全部信息,包括体系结构、参数、损失函数、激活函数、输入和输出数据。对于特定的模型和输入,白盒攻击通常近似于最坏情况的攻击,包括一组扰动。这种攻击策略往往非常有效。文本 dnn 的白盒攻击分为七类:FGSM-based、JSMA-based、C&W-based、Direction-based、Attention-based、Reprogramming、Hybrid。

已审查的白盒 ANack 方法概述如上表,分类、目标和非目标方法显示了相同的效果,所以在表中指出它们的目标为“二进制”。
黑盒攻击
黑盒攻击不需要神经网络的细节,但可以访问输入和输出。这种类型的攻击通常依赖于启发式算法来生成对抗性的例子,这种方法更加实用,因为在许多现实世界的应用程序中,DNN 的细节对于攻击者来说是一个黑盒。在本文中,文本 dnn 的黑盒攻击分为五类:Concatenation Adversaries、Edit Adversaries、Paraphrase-based Adversaries、GAN-based Adversaries、Substitution。

上表综述了黑盒 ANack 方法,该方法是否是目标驱动的;受攻击的神经模型、扰动控制和 NLP 应用。
存在问题及解决方法
1、图像像素的扰动通常很难被察觉,因此不会影响人类的判断,但会欺骗深层神经网络。然而,对文本的扰动是显而易见的,无论这种扰动是翻转字符还是改变单词。无效单词和语法错误很容易被人识别,并被语法检查软件检测到,因此扰动很难攻击真实的 NLP 系统,需要提出一些方法,使得扰动不仅不可察觉,而且保持正确的语法和语义。
2、由于深层神经网络的细节不会对攻击方法产生太大影响,这一特性在黑盒攻击中更常被利用。
3、许多研究不是针对实际攻击,更多的是考察目标网络的健壮性。这些手工工作既费时又不切实际。有些评论作品能够自动生成反例,有些则不能。在白盒攻击中,利用 DNN 的损失函数可以自动识别文本中最受影响的点(例如,字符、单词)。然后通过自动修改相应的文本对这些点进行攻击。在黑盒攻击中,一些攻击,例如替代序列替代 DNNs,并在替代上应用白盒攻击策略,这可以自动实现。
4、尽管大多数常见的文本 dnn 已经从敌对攻击的角度获得了关注,到目前为止,许多 dnn 还没有受到攻击,注意机制成了大多数顺序模型中的标准组件,但是还没有研究这种机制本身的工作。
5、直观上,一次性攻击比迭代攻击快得多,但效率较低,也更容易被防御。当在实际应用程序上设计攻击方法时,攻击者需要仔细考虑攻击的效率和效果之间的权衡。
总结
本周大部分时间都花在了课程上,对卷积神经网络经典模型及Tensorflow学习进度偏慢,对Tensorflow上的很多语法还是不太懂,下周我会继续学习卷积神经网络经典模型及Tensorflow,争取加快一些学习进度。