Mnist数据集介绍
Mnist数据集已经是一个被"嚼烂"了的数据集了,很多关于神经网络的教程都会对它下手。因此在开始深度学习之前,先对这个数据集介绍一下。
Mnist数据集图片格式介绍
Mnist数据集分为两部分,分别含有60000张训练图片和10000张测试图片。
每一张图片包含28*28个像素。Mnist数据集把代表一张图片的二维数据转开成一个向量,长度为28*28=784。因此在Mnist的训练数据集中mnist.train.images是一个形状为[60000, 784]的张量,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点,图片里的某个像素的强度值介于0-1之间。
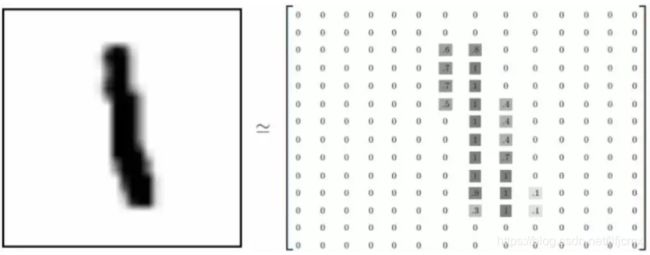
Mnist数据集标签格式介绍--------独热编码
Mnist数据集中的标签是介于0~9的数字,Mnist中的标签是用独热编码(one-hot-vectors)表示的,一个one-hot向量除了某一位数字是1以外,其余维度的数组都是0,比如标签0用独热编码表示为([1, 0, 0, 0, 0, 0, 0, 0, 0, 0]),标签3用独热编码表示为([0, 0, 0, 1, 0, 0, 0, 0, 0, 0])。所以,Mnist数据集中所有的标签mnist.train.labels是一个[60000, 10]的数字矩阵。
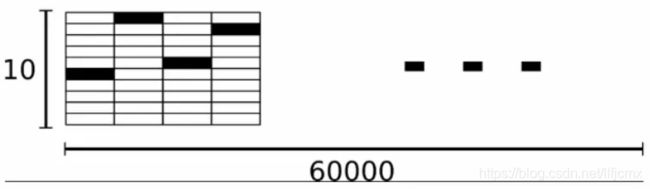
手动提取Mnist数据集图片
如果直接下载该数据集的话,下载下来的是.gz格式的数据,如下图所示:

使用tensorflow是可以直接加载该数据的,但是是按照张量的格式加载的,就是说你看不到这些图片到底是长什么样子的。下面就要介绍一下如何手动提取Mnist数据集中的图片,并把它按照常用的格式存储。
在代码中用到了两个第三方的包,分别为tensorflow、PIL。如何你是用的我之前推荐的Anaconda来管理你的Python环境的话,那么安装这两个包就非常的简单了。使用下面的命令即可安装:
conda install tensorflow-gpu
conda install Pillow
提取的代码写成了函数def的形式,可以非常简单的调用。下面是提取训练数据的代码:
#coding: utf-8
import os
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from PIL import Image
'''
函数功能:按照bmp格式提取mnist数据集中的图片
参数介绍:
mnist_dir mnist数据集存储的路径
save_dir 提取结果存储的目录
'''
def extract_mnist(mnist_dir, save_dir):
rows = 28
cols = 28
# 加载mnist数据集
# one_hot = True为默认打开"独热编码"
mnist = input_data.read_data_sets(mnist_dir, one_hot=False)
# 获取训练图片数量
shape = mnist.train.images.shape
images_train_count = shape[0]
pixels_count_per_image = shape[1]
# 获取训练标签数量=训练图片数量
# 关闭"独热编码"后,labels的类型为[7 3 4 ... 5 6 8]
labels = mnist.train.labels
labels_train_count = labels.shape[0]
if (images_train_count == labels_train_count):
print("训练集共包含%d张图片,%d个标签" % (images_train_count, labels_train_count))
print("每张图片包含%d个像素" % (pixels_count_per_image))
print("数据类型为", mnist.train.images.dtype)
# mnist图像数值的范围为[0,1], 需将其转换为[0,255]
for current_image_id in range(images_train_count):
for i in range(pixels_count_per_image):
if mnist.train.images[current_image_id][i] != 0:
mnist.train.images[current_image_id][i] = 255
if ((current_image_id + 1) % 50) == 0:
print("已转换%d张,共需转换%d张" %
(current_image_id + 1, images_train_count))
# 创建train images的保存目录, 按标签保存
for i in range(10):
dir = "%s/%s" % (save_dir, i)
print(dir)
if not os.path.exists(dir):
os.mkdir(dir)
# indices = [0, 0, 0, ..., 0]用来记录每个标签对应的图片数量
indices = [0 for x in range(0, 10)]
for i in range(images_train_count):
new_image = Image.new("L", (cols, rows))
# 遍历new_image 进行赋值
for r in range(rows):
for c in range(cols):
new_image.putpixel(
(r, c), int(mnist.train.images[i][c + r * cols]))
# 获取第i张训练图片对应的标签
label = labels[i]
image_save_path = "%s/%s/%s.bmp" % (save_dir, label,
indices[label])
indices[label] += 1
new_image.save(image_save_path)
# 打印保存进度
if ((i + 1) % 50) == 0:
print("图片保存进度: 已保存%d张,共需保存%d张" % (i + 1, images_train_count))
else:
print("图片数量与标签数量不一致!")
if __name__ == '__main__':
mnist_dir = "E:/PythonSourceCode/TensorflowLearning/Mnist_Data"
save_dir = "E:/PythonSourceCode/TensorflowLearning/Mnist_Data_TrainImages"
extract_mnist(mnist_dir, save_dir)
最终提取出来的结果如下:
文件夹0下对应的图片为:

可以看到,各种形状的’0’都有。提取出来的图片在后面学习的卷积神经网络的时候会用到,所以有兴趣的可以run一下上面的代码。
如果对我的推文有兴趣,欢迎转载分享。也可以推荐给朋友关注哦。只推干货,宁缺毋滥。
