Tensorflow Slim分类教程(1):以Flower数据集为例
本文是根据Tensorflow slim github上的教程,结合自己的实战经历所整理的。该篇主要是小白入门,所以这里实战使用的数据集是官方提供的数据集Flowers,
后续还会再写一篇如何使用slim在自己的数据集上进行分类。更新:在对自己数据集分类时,参考了一个博主的教程,写的很详细,我就不写了: )。链接:https://blog.csdn.net/rookie_wei/article/details/80796009
Tensorflow Slim github:https://github.com/tensorflow/models/tree/master/research/slim
本文实践的环境是:Ubuntu18.04+Python3.6+Tensorflow1.9+CUDA9.0+cudnn7.0+GTX 1080Ti
插一句:我在win10和ubuntu下多次配置了tensorflow-gpu的环境,ubuntu下的配置还没遇到什么问题,win10下配置的时候遇到了比较多的问题,欢迎交流!
0 简介
TF-slim是TensorFlow(tensorflow.contrib.slim)的一个新的轻量级高级API,可以很方便地搭建、训练分类模型。
slim的github目录中包含了几种广泛使用的卷积神经网络(CNN)图像分类模型的代码,如Inception, Resnet, Inception_resnet, VGG16, VGG19, MobileNet等等。
Github中包含的脚本可以让我们从头开始训练模型或从预训练的网络权重中对其进行微调。
还包含了用于下载标准图像数据集(Minist, Flowers, Cifar10, Imagenet)的代码,将它们转换为TensorFlow的TFRecord格式,并有读取TFRecord数据格式的例子。
如果想了解Slim开发相关或者需要根据自己的需求修改模型的同学,另请参阅TF-Slim主页面https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/slim。
1 Slim安装
TF-Slim以tf.contrib.slim的形式提供。如果Tensorflow安装成功,可以直接测试slim是否正常。执行以下命令,运行时没有任何错误,说明该步通过。
$ python3 -c "import tensorflow.contrib.slim as slim; eval = slim.evaluation.evaluate_once"运行结果如下:

2 安装TF-slim image models library
要使用TF-Slim进行图像分类,还必须安装TF-Slim图像模型库,该库不是核心TF库的一部分。 为此,需要从github上检出tensorflow / models,如下所示:
$ cd $HOME/workspace
$ git clone https://github.com/tensorflow/models/运行结束后会把TF-Slim图像模型库放在$HOME/workspace/models/research/slim中。(官方说:它还将创建一个名为models/ inception的目录,其中包含较旧版本的slim,您可以放心地忽略它。我因为渣网速,所以直接从网站上下下来放到workspace目录下了,没有用git命令,没有发现inception目录)。models文件夹下的东西有这么些:

这里我的$HOME/workspace就是~/zyt/tensorflow。你可以放在自己的路径下。
其主要文件夹和文件用途如下表所示:
| 文件夹或文件名 |
用途 |
| datasets |
定义一些数据集,默认预定义好了4个数据集,分别为MNIST,CIFAR-10,Flowers,ImageNet。如果需要训练自己的数据,则必须在该文件夹下定义,模仿其他数据集的定义即可 |
| nets |
定义一些常用网络结构,如AlexNet、VGG16、VGG19、ResNet、Inception等 |
| scripts |
一些训练示例脚本,只能在支持shell的系统下使用 |
| preprocessing |
在模型读取图片之前,先进行图像的预处理和数据增强,这个文件夹下针对不同的网络,分别定义了其预处理方法 |
| download_and_convert_data.py |
下载并转换数据集格式的入口代码 |
| train_image_classifier.py |
训练模型的入口代码 |
| eval_image_classifier.py |
验证模型性能的入口代码 |
接下来验证一下刚刚下载的TF-Slim模型库是否有效,执行以下命令没有错误,说明有效。
$ cd $HOME/workspace/models/research/slim
$ python3 -c "from nets import cifarnet; mynet = cifarnet.cifarnet"运行结果如下:

3 准备数据集
接下来就是准备数据集了。这里我拿来练手的是Flower数据集。
对于每个数据集,我们需要下载原始数据并将其转换为TensorFlow的TFRecord格式。 下面演示如何为Flowers数据集执行此操作。
$ cd models/research/slim
$ DATA_DIR=/tmp/data/flowers
$ python download_and_convert_data.py \
--dataset_name=flowers \
--dataset_dir="${DATA_DIR}"这个脚本里包含了数据集的下载和格式转换,不用另外去下载了。
运行结束之后会在你的DATA_DIR下生成以下文件,可以看到分成了训练集和验证集,训练集用来训练模型,验证集用来评估我们训练好的模型:
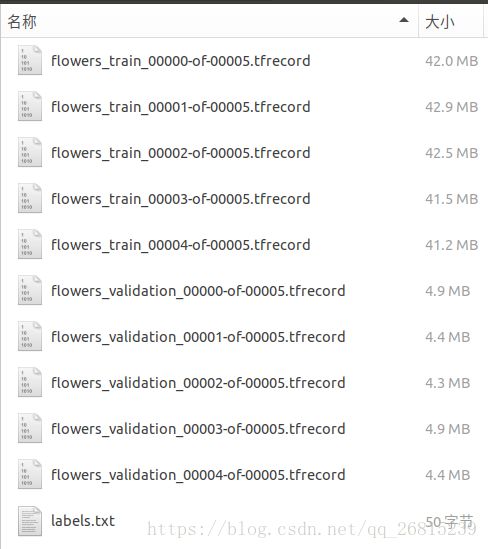
注意:download_and_convert_data.py只支持对cifar10,flowers,minist三个数据集的下载和格式转换,如果要使用自己的数据集制作TFRecord,请看后续文章。
4 创建一个TF-Slim Dataset Descriptor
这里我们可以用官方给的例子创建Dataset Descriptor,并验证我们制作的TFRecord是否正确。代码如下:
import tensorflow as tf
from datasets import flowers
import pylab
slim = tf.contrib.slim
DATA_DIR= "/home/asus/zyt/tensorflow/flowers/TFRecord"
# Selects the 'validation' dataset.
dataset = flowers.get_split('validation', DATA_DIR)
# Creates a TF-Slim DataProvider which reads the dataset in the background
# during both training and testing.
provider = slim.dataset_data_provider.DatasetDataProvider(dataset)
[image, label] = provider.get(['image', 'label'])
#在session下读取数据,并用pylab显示图片
with tf.Session() as sess:
#初始化变量
sess.run(tf.global_variables_initializer())
#启动队列
tf.train.start_queue_runners()
image_batch,label_batch = sess.run([image, label])
#显示图片
pylab.imshow(image_batch)
pylab.show()运行成功可以看到类似下面的结果:
这里我遇到了一个问题:ModuleNotFoundError: No module named 'tkinter'
问题解决参考:https://blog.csdn.net/wyt734933289/article/details/53007792
5 Slim提供的预训练模型介绍
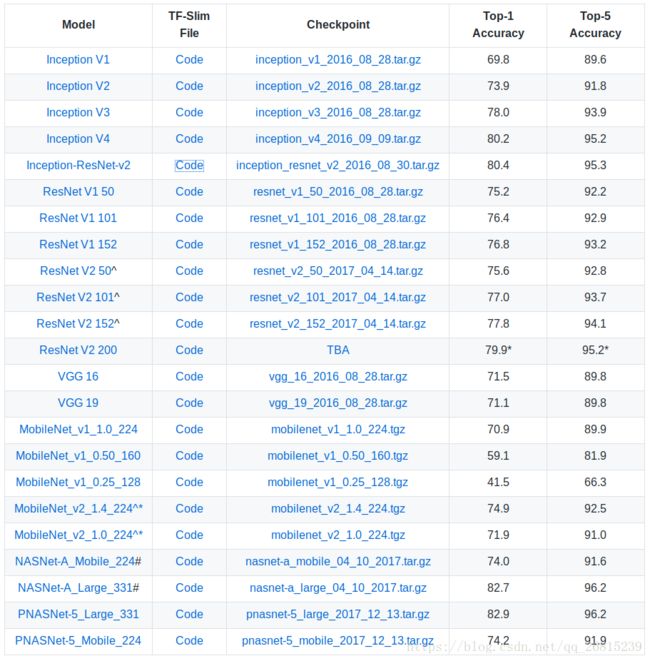
当神经网络具有许多参数时,使它们成为功能强大的近似函数,效果最佳。 但是,这意味着必须对非常大的数据集进行训练。 因为从头开始的训练模型可能需要数天甚至数周,所以Slim提供各种预训练模型,如下所示。 这些网络已经在ILSVRC-2012-CLS分类数据集上进行了训练。
大家可以去上面给出的github链接中下载预训练模型,更多细节也可以在readme中看到。
这里Top-1指对一个图片,如果概率最大的是正确答案,才认为正确。
Top-5指对一个图片,如果概率前五中包含正确答案,即认为正确。
6 从头开始训练模型
从头开始训练模型,也就是不使用预训练模型。下面的示例演示如何使用ImageNet数据集上训练inception_resnet_v2网络。
DATASET_DIR=/home/asus/zyt/tensorflow/flowers/TFRecord
TRAIN_DIR=/home/asus/zyt/tensorflow/train_logs
python3 train_image_classifier.py \
--train_dir=${TRAIN_DIR} \
--dataset_name=flowers \
--dataset_split_name=train \
--dataset_dir=${DATASET_DIR} \
--model_name=inception_resnet_v2 \
--max_number_of_steps=500 \
--batch_size=32 \
--learning_rate=0.0001 \
--learning_rate_decay_type=fixed \
--save_interval_secs=60 \
--save_summaries_secs=60 \
--log_every_n_steps=10 \
--optimizer=rmsprop \
--weight_decay=0.00004DATASET_DIR就是存放TFRecord的路径,TRAIN_DIR用来存放训练好的模型。max_number_of_steps就是迭代次数。
运行完之后会在TRAIN_DIR路径下生成下面这些东东:
TensorBorad可视化训练过程
在训练期间可以对损失和其他指标进行可视化,通过运行以下命令来使用TensorBoard。
$ tensorboard --logdir=${TRAIN_DIR}TensorBoard运行后,将Web浏览器导航到http:// localhost:6006进行查看。
7 在已有的checkpoint上fine-tune自己的模型
我们通常希望从预训练模型开始并对其进行微调,而不是从头开始训练。
在微调模型时,我们需要注意恢复checkpoint的权重。 特别是,当我们自己的数据集的标签和数量与预训练模型不同时,我们将无法恢复最终的logits(分类器)层。 因此,我们将使用--checkpoint_exclude_scopes标志,阻止加载某些变量。
当我们自己的数据集的标签和数量与预训练模型不同时,新模型将具有与预训练模型尺寸不同的“logits”层。 例如,如果在Flowers上微调ImageNet训练的模型,预训练的logits图层具有尺寸[2048 x 1001],但我们的新logits层将具有尺寸[2048 x 5]。
下面我们举一个微调inception_resnet_v2 on flowers的例子,inception_resnet_v2在ImageNet上训练有1000个类标签,但是花朵数据集只有5个类。 由于数据集非常小,我们只训练更新最后的logits层。
python3 train_image_classifier.py \
--train_dir=/home/asus/zyt/tensorflow/train_logs \
--dataset_name=flowers \
--dataset_split_name=train \
--dataset_dir=/home/asus/zyt/tensorflow/flowers/TFRecord \
--model_name=inception_resnet_v2 \
--checkpoint_path=/home/asus/zyt/tensorflow/checkpoints/inception_resnet_v2.ckpt \
--checkpoint_exclude_scopes=InceptionResnetV2/Logits,InceptionResnetV2/AuxLogits \
--trainable_scopes=InceptionResnetV2/Logits,InceptionResnetV2/AuxLogits \
--max_number_of_steps=1000 \
--batch_size=32 \
--learning_rate=0.01 \
--learning_rate_decay_type=fixed \
--save_interval_secs=60 \
--save_summaries_secs=60 \
--log_every_n_steps=10 \
--optimizer=rmsprop \
--weight_decay=0.00004TRAIN_DIR用来存放训练后的模型;DATASET_DIR是存放TFRecord的路径;checkpoint_path就是存放我们下载的预训练模型的路径。
注意: 模型训练后,将在$ {TRAIN_DIR}中创建一个新的checkpoint。如果停止并重新启动微调训练,则应从$ {TRAIN_DIR}下的checkpoint恢复权重,而不是$ {checkpoint_path} 了。
因此,标志--checkpoint_path和--checkpoint_exclude_scopes仅在第1个步骤(模型初始化)使用。 通常,为了微调某些层,所以标志--trainable_scopes允许指定应该训练哪些层,其余的将保持冻结。
训练好之后,TRAIN_DIR下会出现这些东东:
8 评估模型性能
最后就是评估我们训练好的模型的性能啦。
8.1 从头开始训练的模型评估(第6节中训练出的模型)
下面是评估的命令行语句例子:
python3 eval_image_classifier.py \
--checkpoint_path=/home/asus/zyt/tensorflow/train_logs/flower_inception_resnet_v2 \
--eval_dir=/home/asus/zyt/tensorflow/train_logs/flower_inception_resnet_v2 \
--dataset_name=flowers \
--dataset_split_name=validation \
--dataset_dir=/home/asus/zyt/tensorflow/flowers/TFRecord \
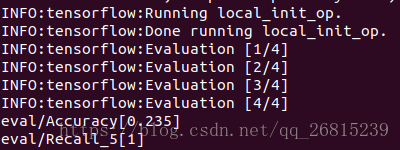
--model_name=inception_resnet_v2这里我只迭代了500次,所以评估结果很差,准确率只有23.5%。
8.2 fine-tune的模型(第7节中训练出的模型)
python3 eval_image_classifier.py \
--checkpoint_path=/home/asus/zyt/tensorflow/train_logs \
--eval_dir=/home/asus/zyt/tensorflow/train_logs \
--dataset_name=flowers \
--dataset_split_name=validation \
--dataset_dir=/home/asus/zyt/tensorflow/flowers/TFRecord \
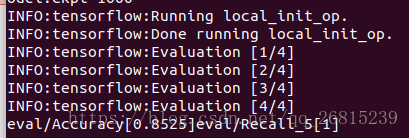
--model_name=inception_resnet_v2结果如下,可以看到使用预训练模型进行fine-tune,只迭代1000次,结果也达到了85.25%。可以迭代更多次试试准确率会不会有提升。
以上就是我在Flower数据集上的尝试,后续我还会在自己的数据集上进行分类。