51JOB爬虫+数据可视化 python
1.登录模块:
用了Xpath和selenium,最后被缺口滑块验证码反爬了一波,缺口验证码那个地方成功率奇低。
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from PIL import Image
import time
from time import sleep
global web,wait
web=webdriver.Firefox()#打开浏览器
wait = WebDriverWait(web, 20)
def denglu():
web.get("https://login.51job.com/login.php?loginway=0&isjump=0&lang=c&from_domain=i&url=http%3A%2F%2Fsearch.51job.com%2Flist%2F360000%2C000000%2C0000%2C00%2C9%2C99%2C%252B%2C2%2C1.html%3Flang%3Dc%26postchannel%3D0000%26workyear%3D99%26cotype%3D99%26degreefrom%3D99%26jobterm%3D99%26companysize%3D99%26ord_field%3D0%26dibiaoid%3D0%26line%3D%26welfare%3D") #在浏览器地址栏,输入网站
#web.maximize_window()# 全屏最大化窗口
web.find_element_by_xpath('//*[@id="loginname"]').send_keys('18658607893')
web.find_element_by_xpath('//*[@id="password"]').send_keys('cjhcjh123')
web.find_element_by_xpath('//*[@id="isread_em"]').click()
web.find_element_by_xpath('/html/body/div[4]/div/div/span').click()
sleep(3)
web.find_element_by_id('login_btn_withPwd').click()
# 对某元素截图
def save_pic(obj, name):
try:
pic_url = web.save_screenshot('.\\51job.png')
print("%s:截图成功!" % pic_url)
# 获取元素位置信息
left = obj.location['x'] * 1.25 # 自己通过原图与实际图片对比得出的系数
top = obj.location['y'] * 1.25
right = left + obj.size['width'] * 1.25
bottom = top + obj.size['height'] * 1.25
print('图:' + name)
print('Left %s' % left)
print('Top %s' % top)
print('Right %s' % right)
print('Bottom %s' % bottom)
print('')
im = Image.open('.\\51job.png')
im = im.crop((left, top, right, bottom)) # 元素裁剪
file_name = '51job_' + name + '.png'
im.save(file_name) # 元素截图
except BaseException as msg:
print("%s:截图失败!" % msg)
# 设置元素可见
def show_element(element):
web.execute_script("arguments[0].style=arguments[1]", element, "display: block;")
# 设置元素不可见
def hide_element(element):
web.execute_script("arguments[0].style=arguments[1]", element, "display: none;")
def cut():
c_background = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'canvas.geetest_canvas_bg.geetest_absolute')))
c_slice = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'canvas.geetest_canvas_slice.geetest_absolute')))
c_full_bg = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'canvas.geetest_canvas_fullbg.geetest_fade.geetest_absolute')))
hide_element(c_slice)
save_pic(c_background, 'back') # 隐藏滑块
show_element(c_slice)
save_pic(c_slice, 'slice') # 所有的
show_element(c_full_bg)
save_pic(c_full_bg, 'full') # 隐藏所有的
# 判断像素是否相同
def is_pixel_equal(bg_image, fullbg_image, x, y):
"""
:param bg_image: (Image)缺口图片
:param fullbg_image: (Image)完整图片
:param x: (Int)位置x
:param y: (Int)位置y
:return: (Boolean)像素是否相同
"""
# 获取缺口图片的像素点(按照RGB格式)
bg_pixel = bg_image.load()[x, y]
# 获取完整图片的像素点(按照RGB格式)
fullbg_pixel = fullbg_image.load()[x, y]
# 设置一个判定值,像素值之差超过判定值则认为该像素不相同
threshold = 120
# 判断像素的各个颜色之差,abs()用于取绝对值
if (abs(bg_pixel[0] - fullbg_pixel[0] < threshold) and abs(bg_pixel[1] - fullbg_pixel[1] < threshold) and abs(bg_pixel[2] - fullbg_pixel[2] < threshold)):
# 如果差值在判断值之内,返回是相同像素
return True
else:
# 如果差值在判断值之外,返回不是相同像素
return False
# 计算滑块移动距离
def get_distance(bg_image, fullbg_image):
'''
:param bg_image: (Image)缺口图片
:param fullbg_image: (Image)完整图片
:return: (Int)缺口离滑块的距离
'''
# 滑块的初始位置
distance = 0
# 遍历像素点横坐标
for i in range(distance, fullbg_image.size[0]):
# 遍历像素点纵坐标
for j in range(fullbg_image.size[1]):
# 如果不是相同像素
if not is_pixel_equal(fullbg_image, bg_image, i, j):
# 返回此时横轴坐标就是滑块需要移动的距离
return i
#破解滑块验证
def slide():
distance=get_distance(Image.open('.\\51job_back.png'),Image.open('.\\51job_full.png'))/1.25 #要将原图与实际图对比的系数除掉
try:
slider=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'div.geetest_slider_button'))) #找到滑块
if slider:
print("====有滑块验证=====")
action_chains = webdriver.ActionChains(web)
# 点击,准备拖拽
action_chains.click_and_hold(slider)
action_chains.pause(0.2)
action_chains.move_by_offset(distance,0)
action_chains.pause(0.6)
action_chains.move_by_offset(36,0) #添加修正过程
action_chains.pause(0.6)
action_chains.release()
action_chains.perform() # 释放滑块
time.sleep(5)
else:
print("===没有滑块验证===")
except Exception as e:
print("==="+str(e))
denglu()
cut()
slide()
2.搜索+爬取模块 没结合第一个登录模块 因为登录成功率实在低了点(涉及了一小部分的数据清洗,关于工资那部分的)
import re
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from PIL import Image
import time
import json
from time import sleep
import requests
global web,wait
web=webdriver.Firefox()#打开浏览器
wait = WebDriverWait(web, 20)
web.get("https://search.51job.com/list/360000,000000,0000,00,9,99,%2B,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=") #在浏览器地址栏,输入网站
web.maximize_window()# 全屏最大化窗口
print('请输入你要搜索的职位')
s = input()
def sousuo():
sleep(3)
#web.find_element_by_xpath('/html/body/div[1]/div[4]/div/p/a[2]').click()
web.find_element_by_xpath('/html/body/div[2]/div[2]/div[1]/div[1]/div[2]/div[2]').click()
web.find_element_by_xpath('/html/body/div[2]/div[2]/div[1]/div[2]/div/div[2]/div[1]/div[2]/div/table/tbody[1]/tr/td[2]/em').click()
web.find_element_by_xpath('/html/body/div[2]/div[2]/div[1]/div[2]/div/div[2]/div[1]/div[2]/div/table/tbody[2]/tr/td[2]/em').click()
web.find_element_by_xpath('/html/body/div[2]/div[2]/div[1]/div[2]/div/div[2]/div[1]/div[2]/div/table/tbody[4]/tr/td[4]/em').click()
web.find_element_by_xpath('/html/body/div[2]/div[2]/div[1]/div[2]/div/div[2]/div[1]/div[3]/table/tbody/tr/td/em').click()
web.find_element_by_xpath('/html/body/div[2]/div[2]/div[1]/div[2]/div/div[3]/span').click()
sleep(2)
web.find_element_by_xpath('//*[@id="keywordInput"]').send_keys(s)
sleep(0.5)
web.find_element_by_xpath('//*[@id="search_btn"]').click()
def pachu():
f=open('C:\\Users\\55151\\Desktop\\python课设\\51jobpachong.csv','a+')
f.write('{},{},{},{},{},{},{}\n'.format('职位','公司','工资','工作地点','学历','更新时间','详情'))
#f = open('C:\\Users\\55151\\Desktop\\python课设\\51jobpachong.csv', 'a+')
headers={'Cookie': '_uab_collina=165432020619222940563756; acw_tc=ac11000116543202028027511e010fbf52b6b519923541b8e77a0e3850f097; guid=b6ba05a019649425e1e1883cbfeb8b3f; search=jobarea%7E%60360000%2C020000%2C080200%2C170200%7C%21ord_field%7E%600%7C%21recentSearch0%7E%60360000%2C020000%2C080200%2C170200%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FApython%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch1%7E%60360000%2C020000%2C080200%2C170200%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FA%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch2%7E%60360000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FA%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21; nsearch=jobarea%3D%26%7C%26ord_field%3D%26%7C%26recentSearch0%3D%26%7C%26recentSearch1%3D%26%7C%26recentSearch2%3D%26%7C%26recentSearch3%3D%26%7C%26recentSearch4%3D%26%7C%26collapse_expansion%3D; ssxmod_itna=YqIx2DBDyii=iteGHD8Qbq0IKpQD0DbAGQG=CcD0vxpeGzDAxn40iDto=ThloZA7u5Pf8lO+hxZWEDedpsWpOAfOe6+r4GLDmKDylYxheDx1q0rD74irDDxD3DbRdDSDWKD9D0bMgy2VKDbxi36xDbDiWkvxGCDeKD0PqHDQKDucKPslrkYRPw9ro1eGAxKnKD9OoDsc0fC4oLU/2GfCKDX1dDvhv1ZgPpDB4C/pyGbQDPfmlFsxDOy4017zqDWcIxsel5DjTk1gaKWB=DBoUe/j+x5G0q8b0gqlGKOlGZeBqxNQaq6Nm4O2PH7DDDfPGhdmDxD=; ssxmod_itna2=YqIx2DBDyii=iteGHD8Qbq0IKpQD0DbAGQG=7DnFfbyqDs=KeDL7ZiybDqnRDq=zKmrqc5eXtAGIxq9Qigc5kcKYMpaCd3br2dze3rkMD3YxcGOwfeYeu80KsbNBrKmli7vKhNc8pxW0Qiie8pkWeW+Yhwie8GHKiAiO0WmaSwT8lbTxExTOlRbt8gd7+qmXm7zpU3fhU33ptpioI36KQaflj34G/cm8SpNz/d2SScWYVpIp3e=E6oXGRezdgh2gIwUhRT8xF=uiMMIcn0bk/7pKQA=nQAXlFgDYlxvtgTp0QWihafmZq1YxToBHL+sk3=WSH3earfsVbOiuDb21kRF93bc04pRhhd8c7Y+S1V8whT+OYWB+NUhFrk75lrqLT/0FBozDWmjbYCMdw81BObfq7n7OTw7M3FKdzqaY2dmBOKPT88qEquxxO1uQrZQTPcOnjE8kObCHDm7pODDkadSdOYFALk=GEtldY7aCDjBqLk4HhQOz41DI54U+F6+SfxEDDwZGKnDc9E5s6xiAAA=elo3lxCm9M=K=uO/0EEnherhZWIicoTkwZBK6ph1iwy9OSZOOww8kqbue=G2eavQeo=ZkIih99vX++nn+MFXmBmE0C8TxDjKDeuz/rxuhTwYubgCphTAi3GBz0BqEbmC/zkNHCbZ=r/bo/jTlV7D4D===','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:100.0) Gecko/20100101 Firefox/100.0'}
for page in range(1,497):
print('正在爬取第{}页\n'.format(page))
url='https://search.51job.com/list/360000%252c020000%252c080200%252c170200,000000,0000,00,9,99,python,2,{}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare='.format(page)
ree=requests.get(url=url,headers=headers).text
#print(ree)
r=re.findall('window.__SEARCH_RESULT__ = (.*?)',ree,re.S)
#print(r)
sss=' '.join(r)
# #print(sss)
infodict=json.loads(sss)
print(infodict)
engine_jds=infodict['engine_jds']
for i in engine_jds:
job_name=i['job_name']
company_name=i['company_name']
providesalary_text=i['providesalary_text']
for k in i['attribute_text']:
if k=='大专' or k=='本科' or k =='硕士' :
attribute_text=k
n = 0
if ("万/月" in providesalary_text):
Num = (re.findall(r"\d+\.?\d*", providesalary_text)) # 将工资字符串中数字提取出
n = int((float(Num[0]) + float(Num[1])) * 10000 / 2) # 将工资区间平均化
elif ("千/月" in providesalary_text):
Num = (re.findall(r"\d+\.?\d*", providesalary_text))
n = int((float(Num[0]) + float(Num[1])) * 1000 / 2)
elif ('元/天'in providesalary_text ):
n=0
if n==0:
providesalary_text='面议'
else:
providesalary_text= str(n)+'元'
workarea_text=i['workarea_text'][0:2]
updatedate=i['updatedate']
job_href=i['job_href']
f.write('{},{},{},{},{},{},{}\n'.format(job_name,company_name,providesalary_text,workarea_text,attribute_text,updatedate,job_href))
sleep(0.1)
print('done!\n')
f.close()
sousuo()
pachu()
3.可视化模块:
import csv
import wordcloud as wc
import jieba
from PIL import Image
import numpy as np
from matplotlib import pyplot as plt
from pyecharts.charts import Map
from pyecharts.charts import Bar
from pyecharts import options
from pyecharts.commons.utils import JsCode
import csv
import pandas as pd
from pyecharts.charts import Pie
from pyecharts import options as opts
data_x = []
data_y = []
province_date = []
data_number_y = []
ss=''
with open("C:\\Users\\55151\\Desktop\\python课设\\51jobpachong.csv") as fp:
read = csv.reader(fp) # 读取文件内容
for i in read:
ss+=i[0]
#print(i[2]+'\n')
if i[2]=='工资' or i[2]=='面议':
pass
else:
#print(i[2][:len(i[2])-1])
province = []
data_x.append(i[3])
data_y.append((i[2][:len(i[2])-1]))
data_number_y.append(i[3])
province.append(i[3])
province.append(i[2][:len(i[2])-1])
province_date.append(province)
res = jieba.lcut(ss) # 中文分词
text = " ".join(res) # 用空格连接所有的词
mask = np.array(Image.open("C:\\Users\\55151\\Desktop\\词云.jpg")) # 指定词云图效果
word_cloud = wc.WordCloud(font_path="msyh.ttc", mask=mask) # 创建词云对象
word_cloud.generate(text) # 生成词语
plt.imshow(word_cloud) # 显示词云图
word_cloud.to_file("wordcloud.png") # 保存成图片
plt.show() # 显示图片
data_x = data_x[0: 30]
print(data_x)
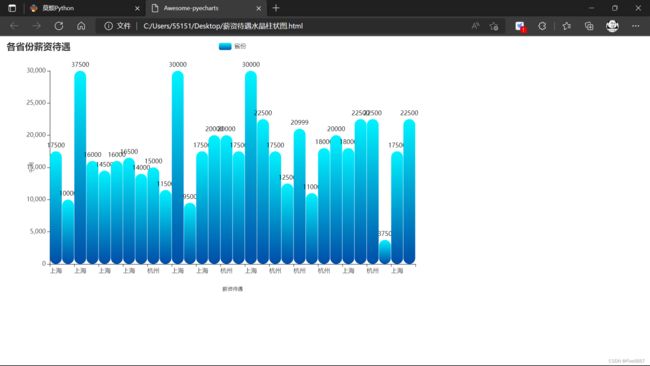
date_many_map = (#薪资待遇水晶柱状图
Bar()
.add_xaxis(data_x)
.add_yaxis("省份", data_y, category_gap="3%")
.set_series_opts(
itemstyle_opts={
"normal": {
"color": JsCode(
"""new echarts.graphic.LinearGradient(0, 0, 0, 1, [{
offset: 0,
color: 'rgba(0, 244, 255, 1)'
}, {
offset: 1,
color: 'rgba(0, 77, 167, 1)'
}], false)"""
),
"barBorderRadius": [50, 50, 50, 50],
"shadowColor": "rgb(0, 160, 221)",
}
}
)
.set_global_opts(title_opts=options.TitleOpts(title="各省份薪资待遇"),
xaxis_opts=options.AxisOpts(
name='薪资待遇',
name_location='middle',
name_gap=45, # 标签与轴线之间的距离,默认为20,最好不要设置20
name_textstyle_opts=options.TextStyleOpts(
font_family='Times New Roman',
font_size=10 # 标签字体大小
)),
yaxis_opts=options.AxisOpts(
name='千/月',
name_location='middle',
name_gap=30,
split_number = 5,
max_=30000,
#length=100,
name_textstyle_opts=options.TextStyleOpts(
font_family='Times New Roman',
font_size=10
# font_weight='bolder',
)),
# toolbox_opts=opts.ToolboxOpts() # 工具选项
)
.render("C:\\Users\\55151\\Desktop\\薪资待遇水晶柱状图.html")
)
print("薪资待遇水晶柱状图创建能完成!!!")
data = pd.read_csv('C:\\Users\\55151\\Desktop\\python课设\\51jobpachong.csv', error_bad_lines=False, encoding='gbk')
counts = data['学历'].value_counts()
l1 = counts.index.tolist()
l2 = counts.values.tolist()
# 数据格式整理
data_pair = [list(z) for z in zip(l1, l2)]
(
# 设置图标背景颜色
Pie(init_opts=opts.InitOpts(bg_color="rgba(206, 206, 206, 0.3)"))
.add(
# 系列名称,即该饼图的名称
series_name="学历分析",
# 系列数据项
data_pair=data_pair,
# 饼图的半径,设置成默认百分比,相对于容器高宽中较小的一项
radius="55%",
# 饼图的圆心,第一项是相对于容器的宽度,第二项是相对于容器的高度
center=["50%", "50%"],
# 标签配置项
label_opts=opts.LabelOpts(is_show=False, position="center"),
)
# 全局设置
.set_global_opts(
# 设置标题
title_opts=opts.TitleOpts(
# 名字
title="学历占比分析",
# 组件距离容器左侧的位置
pos_left="center",
# 组件距离容器上方的像素值
pos_top="20",
# 设置标题颜色
title_textstyle_opts=opts.TextStyleOpts(color="#000"),
),
# 图例配置项,参数 是否显示图里组件
legend_opts=opts.LegendOpts(
is_show=True,
# 竖向显示
orient="vertical",
# 距离左边5%
pos_left="5%",
# 距离上边60%
pos_top="60%",
),
)
# 系列设置
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a}
{b}: {c} ({d}%)"
),
# 设置标签颜色
label_opts=opts.LabelOpts(color="#000"),
)
.render('C:\\Users\\55151\\Desktop\\xueli.html')
)