初识 CV Transformer 之Vision Transformer (ViT)
初识 CV Transformer 之Vision Transformer (ViT)

请没有征服不了的高山
0 回顾




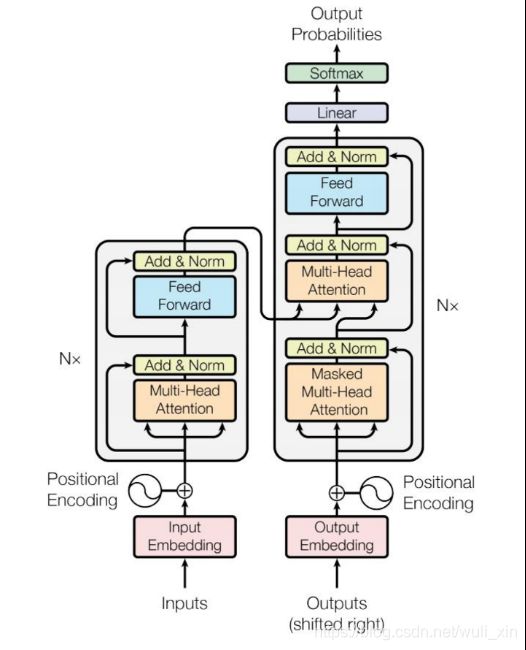
Attention Is All You Need
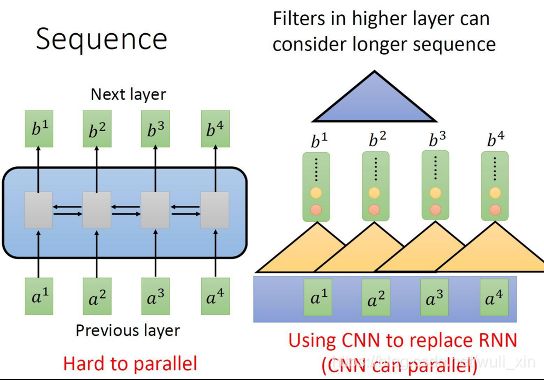
RNN、LSTM时序网络,存在一定的问题:1.记忆长度有限,像RNN记忆时序比较短,后面就提出了LSTM;2.无法并行化,即只有计算完t0时刻才能计算t1时刻,计算效率比较低。
Google提出了Transformer,在理论上不受硬件的限制,记忆长度可以无限长,并且可以并行化。
Embedding层有什么用?
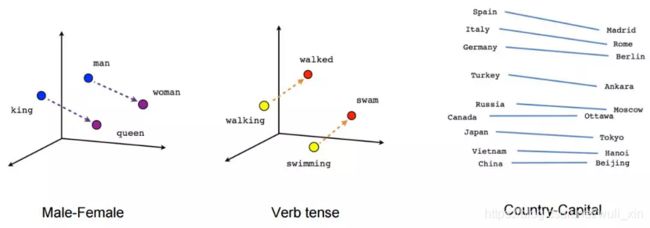
Eembedding层, Keras中文文档中对嵌入层 Embedding的介绍除了一句 “嵌入层将正整数(下标)转换为具有固定大小的向量”之外就不愿做过多的解释。那么我们为什么要使用嵌入层 Embedding呢? 主要有这两大原因:
1、使用One-hot方法编码的向量会很高维也很稀疏。假设我们在做自然语言处理(NLP)中遇到了一个包含2000个词的字典,当使用One-hot编码时,每一个词会被一个包含2000个整数的向量来表示,其中1999个数字是0,如果字典再大一点,这种方法的计算效率会大打折扣。
2、训练神经网络的过程中,每个嵌入的向量都会得到更新。通过上面的图片我们就会发现在多维空间中词与词之间有多少相似性,这使我们能可视化的了解词语之间的关系,不仅仅是词语,任何能通过嵌入层 Embedding 转换成向量的内容都可以这样做。
上面说的概念可能还有些不清楚,那我们就举个例子看看嵌入层Embedding对下面的句子怎么处理的。Embedding的概念来自于word embeddings,如果您有兴趣阅读更多内容,可以查询word2vec。

1 前言
论文题目:An Image is Worth 16x16 Words:Transformers for Image Recognition
at Scale
研究背景
Transformer提出后在NLP领域中取得了极好的效果,其全Attention的结构,不仅增强了特征提取能力,还保持了并行计算的特点,可以又快又好的完成NLP领域内几乎所有任务,极大地推动自然语言处理的发展。
虽然Transformer很强,但在其在计算机视觉领域的应用还非常有限。在此之前只有目标检测(Objectdetection)中的DETR大规模使用了Transformer,其他领域很少,而纯Transformer结构的网络则是没有。
下图是该方向论文必出现的图:
Transformer的优势
1、并行计算;
2、全局视野;
3、灵活的堆叠能力;
研究成果及意义
ViT和ResNet Baseline取得了不相上下的结果

JFT:谷歌闭源数据集,规模是ImageNet的30倍左右
ViT-H/14:ViT-Huge模型,输入序列14x14
ViT的历史意义:展示了在计算机视觉中使用纯Transformer结构的可能。
图片→Backbone(CNNs)→Transformer→结果
图片→Transformer→结果
2 论文算法模型总览
一切的开端:Self-Attention
Attention是什么?以机器翻译为例。


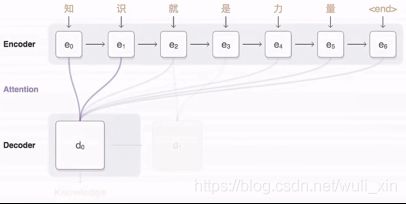
每次输出只与输入的某几个词有关,关系深,权重大,关系浅,权重小。
Attention Mechanism
Attention的本质:加权平均
Attention的计算:实际上就是相似度计算
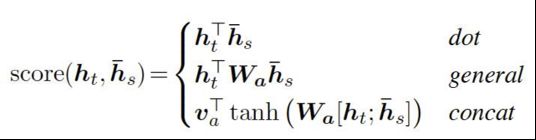
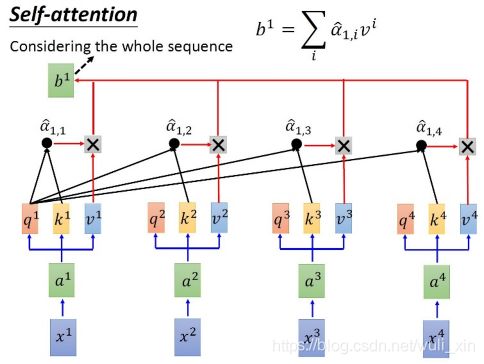
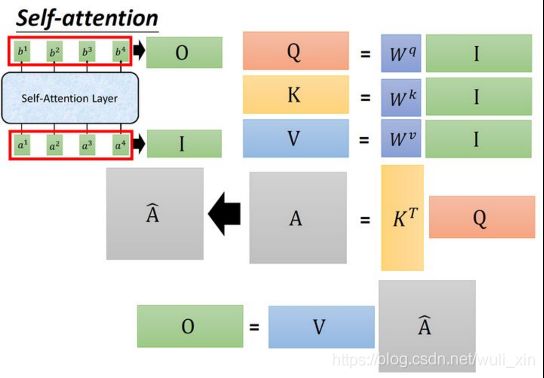
Self-Attention怎么计算?
Self Attention 计算:实际上是在进行相似度计算,计算每个q分别和每个k的相似度
公式:
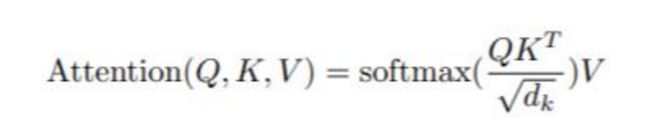
Q,K,V是什么?
Query:查询,询问;

Key:键值,关键词;

Value:价值,数值。

点积为什么可以衡量q与k的相似度?
公式:q1·k1= |q1| x |k1| x cos
q1·k2= |q1| x |k2| x cos

Attention计算


假设的input是x1-x4,是一个sequence,每一个input (vector)先乘以矩阵W得到embedding,即向量a1-a4。接着这个embedding进入self-attention层,每一个向量a1-a4分别乘上3个不同的transformation matrix Wq,Wk,Wv,以向量a1为例,分别得到3个不同的向量q1,k1,v1;接下来使用每个query q去对每个key k做attention,attention就是做点积,匹配这2个向量有多接近,然后除以q和k的维度的开平方。




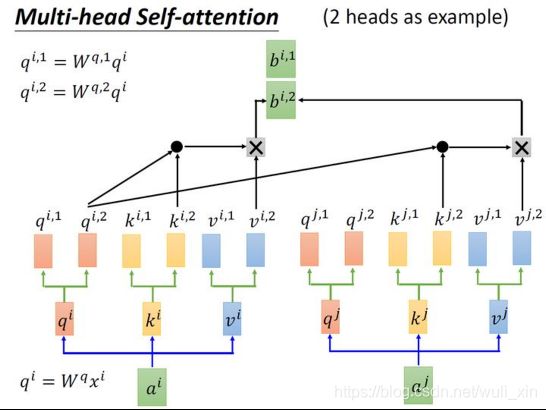
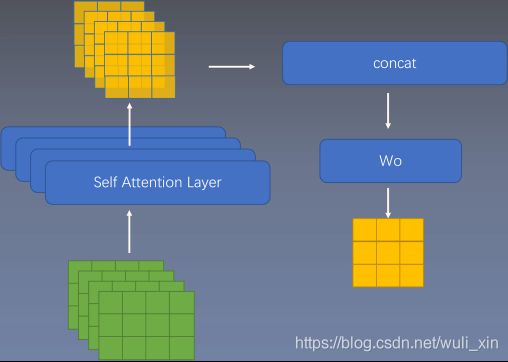
MultiHead Attention

ViT结构
受NLP中Transformer扩展成功的启发,我们尝试将一个标准的Transformer直接应用于图像,并尽可能少地进行修改。为此,我们将图像分割成补丁,并将这些补丁的线性嵌入序列作为转化器的一个输入。图像斑块的处理方式与NLP应用中的记号(单词)相同。我们以监督的方式训练图像分类的模型。


1、将图像切分转化为序列化数据:原本HxWxC维的图片被转化为N个 D维的向量(或者一个NxD维的二维矩阵);
2、Position Embedding:采用position embedding(紫色框) + patch embedding(粉色框)方式来结合position信息;
3、Learnable Embedding:Xclass(带星号的粉色框)是可学习的vector,这个token没有语义信息(即在句子中与任何的词无关,在图像中与任何的patch无关),它与图片label有关,经过encoder得到的结果使得整体表示偏向于这个指定embedding的信息;
4、Transformer Encoder:将前面得到的Z0作为transformer的初始输入,transformer encoder是由多个MSA和MLP块交替组成的,每次在MSA和MLP前都要进行LN归一化。
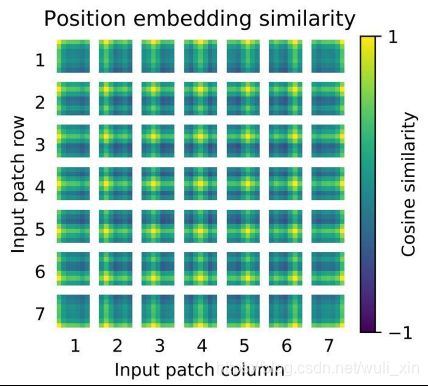
位置编码 Positional Encoding
为什么要位置编码?
图像切分重排(由二维变一维)后失去了位置/空间信息,并且Transformer的内部运算是空间信息无关的,所以需要把位置信息编码重新传进网络;
ViT使用了一个可学习的vector(Xclass)来编码,编码vector和patch vector直接相加组成输入;
为什么直接相加,而不是concat?
因为相加是concat的一种特例
相加形式:W(I+P)=WI+WP
concat形式:
当W1=W2时,两式内涵一致
BN和LN的区别
为什么采用LN?
LN其实就是在每个样本上都计算均值和方差,将输入数据转化成均值为0,方差为1的数据。而不采用BN是因为,Batch Normalization的处理对象是对一批样本,是对这批样本的同一维度特征做归一化,Layer Normalization 的处理对象是单个样本,是对这单个样本的所有维度特征做归一化,而此处输入的N+1个序列,每个序列的长度可能是不同的。

3 实验结果分析
先在大数据集上预训练,然后到小数据集上Fine Tune
迁移过去后,需要把原本的MLP Head换掉,换成对应类别数的FC层,处理不同尺寸输入的时候需要对Positional Encoding的结果进行插值

在中等规模的数据集上(例如ImageNet),transformer模型的表现不如ResNets;
而当数据集的规模扩大,transformer模型的效果接近或者超过了目前的一些SOTA结果。
BiT : 一个大ResNet进行监督+迁移学习的模型
Noisy Student:一个半监督学习的EfficientNet-L2
ViT-H/14:ViT-Huge模型,输入序列14x14


Attention距离和网络层数的关系。Attention的距离可以等价为Conv中的感受野大小,层数越深,Attention跨越的距离越远,但是在最底层,也有的head可以覆盖到很远的距离。这说明Transformer可以进行Global信息整合。
