对GNN(图神经网络)的初步了解
一、为什么需要图神经网络?
随着机器学习、深度学习的发展,语音、图像、自然语言处理逐渐取得了很大的突破,然而语音、图像、文本都是很简单的序列或者网格数据,是很结构化的数据,深度学习很善于处理该种类型的数据(图1)。

然而现实世界中并不是所有的事物都可以表示成一个序列或者一个网格,例如社交网络、知识图谱、复杂的文件系统等(图2),也就是说很多事物都是非结构化的

相比于简单的文本和图像,这种网络类型的非结构化的数据非常复杂,处理它的难点包括:
- 图的大小是任意的,图的拓扑结构复杂,没有像图像一样的空间局部性
- 图没有固定的节点顺序,或者说没有一个参考节点
- 图经常是动态图,而且包含多模态的特征
那么对于这类数据我们该如何建模呢?能否将深度学习进行扩展使得能够建模该类数据呢?这些问题促使了图神经网络的出现与发展。
二. 图神经网络是什么样子的?
1.状态更新与输出
最早的图神经网络起源于Franco博士的论文, 它的理论基础是不动点理论。给定一张图G,每个结点都有其自己的特征(feature), 本文中用Xv表示结点v的特征;连接两个结点的边也有自己的特征,本文中用X(v,u)表示结点v与结点u之间边的特征;GNN的学习目标是获得每个结点的图感知的隐藏状态hv(state embedding),这就意味着:对于每个节点,它的隐藏状态包含了来自邻居节点的信息。那么,如何让每个结点都感知到图上其他的结点呢?GNN通过迭代式更新所有结点的隐藏状态来实现,在t+1时刻,结点v的隐藏状态按照如下方式更新:
![]()
上面这个公式中的 就是隐藏状态的状态更新函数,在论文中也被称为局部转移函数(local transaction function)。公式中的
就是隐藏状态的状态更新函数,在论文中也被称为局部转移函数(local transaction function)。公式中的![]() 指的是与结点
指的是与结点 相邻的边的特征,
相邻的边的特征,![]() 指的是结点的邻居结点的特征,
指的是结点的邻居结点的特征,![]() 则指邻居结点在
则指邻居结点在 时刻的隐藏状态。注意是对所有结点都成立的,是一个全局共享的函数。那么怎么把它跟深度学习结合在一起呢?聪明的读者应该想到了,那就是利用神经网络(Neural Network)来拟合这个复杂函数。值得一提的是,虽然看起来的输入是不定长参数,但在内部我们可以先将不定长的参数通过一定操作变成一个固定的参数,比如说用所有隐藏状态的加和来代表所有隐藏状态。我们举个例子来说明一下:
时刻的隐藏状态。注意是对所有结点都成立的,是一个全局共享的函数。那么怎么把它跟深度学习结合在一起呢?聪明的读者应该想到了,那就是利用神经网络(Neural Network)来拟合这个复杂函数。值得一提的是,虽然看起来的输入是不定长参数,但在内部我们可以先将不定长的参数通过一定操作变成一个固定的参数,比如说用所有隐藏状态的加和来代表所有隐藏状态。我们举个例子来说明一下:

假设结点5为中心结点,其隐藏状态的更新函数如图所示。这个更新公式表达的思想自然又贴切:不断地利用当前时刻邻居结点的隐藏状态作为部分输入来生成下一时刻中心结点的隐藏状态,直到每个结点的隐藏状态变化幅度很小,整个图的信息流动趋于平稳。至此,每个结点都“知晓”了其邻居的信息。状态更新公式仅描述了如何获取每个结点的隐藏状态,除它以外,我们还需要另外一个函数 来描述如何适应下游任务。举个例子,给定一个社交网络,一个可能的下游任务是判断各个结点是否为水军账号。
来描述如何适应下游任务。举个例子,给定一个社交网络,一个可能的下游任务是判断各个结点是否为水军账号。
![]()
在原论文中,又被称为局部输出函数(local output function),与类似,也可以由一个神经网络来表达,它也是一个全局共享的函数。那么,整个流程可以用下面这张图表达:
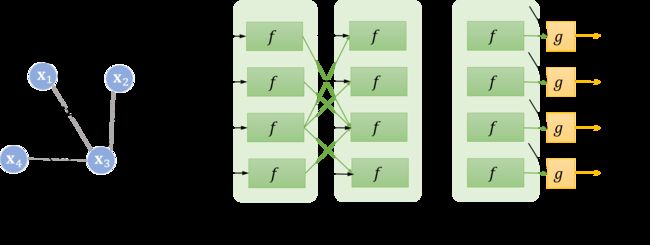
仔细观察两个时刻之间的连线,它与图的连线密切相关。比如说在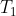 时刻,结点 1 的状态接受来自结点 3 的上一时刻的隐藏状态,因为结点 1 与结点 3相邻。直到
时刻,结点 1 的状态接受来自结点 3 的上一时刻的隐藏状态,因为结点 1 与结点 3相邻。直到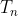 时刻,各个结点隐藏状态收敛,每个结点后面接一个即可得到该结点的输出
时刻,各个结点隐藏状态收敛,每个结点后面接一个即可得到该结点的输出 。
。
对于不同的图来说,收敛的时刻可能不同,因为收敛是通过两个时刻![]() 范数的差值是否小于某个阈值
范数的差值是否小于某个阈值 来判定的,比如:
来判定的,比如:
![]()
2.实例:化合物分类
下面让我们举个实例来说明图神经网络是如何应用在实际场景中的,这个例子来源于论文[2]。假设我们现在有这样一个任务,给定一个环烃化合物的分子结构(包括原子类型,原子键等),模型学习的目标是判断其是否有害。这是一个典型的二分类问题,一个训练样本如下图所示:

由于化合物的分类实际上需要对整个图进行分类,在论文中,作者将化合物的根结点的表示作为整个图的表示,如图上红色的结点所示。Atom feature 中包括了每个原子的类型(Oxygen, 氧原子)、原子自身的属性(Atom Properties)、化合物的一些特征(Global Properties)等。把每个原子看作图中的结点,原子键视作边,一个分子(Molecule)就可以看作一张图。在不断迭代得到根结点氧原子收敛的隐藏状态后,在上面接一个前馈神经网络作为输出层(即gg函数),就可以对整个化合物进行二分类了。
3.不动点理论
在本节的开头我们就提到了,GNN的理论基础是不动点(the fixed point)理论,这里的不动点理论专指巴拿赫不动点定理(Banach's Fixed Point Theorem)。首先我们用 表示若干个 堆叠得到的一个函数,也称为全局更新函数,那么图上所有结点的状态更新公式可以写成:
表示若干个 堆叠得到的一个函数,也称为全局更新函数,那么图上所有结点的状态更新公式可以写成:
![]()
不动点定理指的就是,不论![]() 是什么,只要是个压缩映射(contraction map),
是什么,只要是个压缩映射(contraction map),![]() 经过不断迭代都会收敛到某一个固定的点,我们称之为不动点。那压缩映射又是什么呢,一张图可以解释得明明白白:
经过不断迭代都会收敛到某一个固定的点,我们称之为不动点。那压缩映射又是什么呢,一张图可以解释得明明白白:
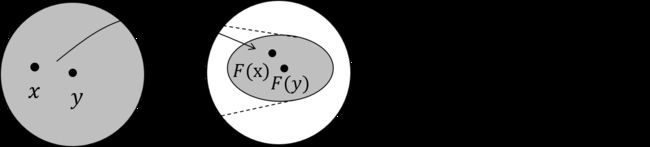
上图的实线箭头就是指映射 , 任意两个点 在经过这个映射后,分别变成了
在经过这个映射后,分别变成了 ![]() 。压缩映射就是指,
。压缩映射就是指,![]() 。也就是说,经过变换后的新空间一定比原先的空间要小,原先的空间被压缩了。想象这种压缩的过程不断进行,最终就会把原空间中的所有点映射到一个点上。
。也就是说,经过变换后的新空间一定比原先的空间要小,原先的空间被压缩了。想象这种压缩的过程不断进行,最终就会把原空间中的所有点映射到一个点上。
那么肯定会有读者心存疑问,既然是由神经网络实现的,我们该如何实现它才能保证它是一个压缩映射呢?我们下面来谈谈的具体实现。
4.具体实现
在具体实现中, 其实通过一个简单的前馈神经网络(Feed-forward Neural Network)即可实现。比如说,一种实现方法可以是把每个邻居结点的特征、隐藏状态、每条相连边的特征以及结点本身的特征简单拼接在一起,在经过前馈神经网络后做一次简单的加和。

那我们如何保证是个压缩映射呢,其实是通过限制 对 的偏导数矩阵的大小,这是通过一个对雅可比矩阵(Jacobian Matrix)的惩罚项(Penalty)来实现的。在代数中,有一个定理是:为压缩映射的等价条件是的梯度/导数要小于1。这个等价定理可以从压缩映射的形式化定义导出,我们这里使用
的偏导数矩阵的大小,这是通过一个对雅可比矩阵(Jacobian Matrix)的惩罚项(Penalty)来实现的。在代数中,有一个定理是:为压缩映射的等价条件是的梯度/导数要小于1。这个等价定理可以从压缩映射的形式化定义导出,我们这里使用![]() 表示
表示  在空间中的范数(norm)。范数是一个标量,它是向量的长度或者模,
在空间中的范数(norm)。范数是一个标量,它是向量的长度或者模,![]() 是 在有限空间中坐标的连续函数。这里把简化成1维的,坐标之间的差值可以看作向量在空间中的距离,根据压缩映射的定义,可以导出:
是 在有限空间中坐标的连续函数。这里把简化成1维的,坐标之间的差值可以看作向量在空间中的距离,根据压缩映射的定义,可以导出:

推广一下,即得到雅可比矩阵的罚项需要满足其范数小于等于 等价于压缩映射的条件。根据拉格朗日乘子法,将有约束问题变成带罚项的无约束优化问题,训练的目标可表示成如下形式:
等价于压缩映射的条件。根据拉格朗日乘子法,将有约束问题变成带罚项的无约束优化问题,训练的目标可表示成如下形式:
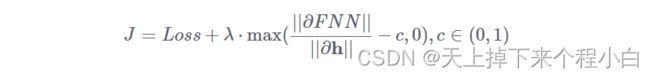
其中 是超参数,与其相乘的项即为雅可比矩阵的罚项。
是超参数,与其相乘的项即为雅可比矩阵的罚项。
5.模型学习
上面我们花一定的篇幅搞懂了如何让接近压缩映射,下面我们来具体叙述一下图神经网络中的损失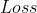 是如何定义,以及模型是如何学习的。
是如何定义,以及模型是如何学习的。
仍然以社交网络举例,虽然每个结点都会有隐藏状态以及输出,但并不是每个结点都会有监督信号(Supervision)。比如说,社交网络中只有部分用户被明确标记了是否为水军账号,这就构成了一个典型的结点二分类问题。
那么很自然地,模型的损失即通过这些有监督信号的结点得到。假设监督结点一共有 个,模型损失可以形式化为:
个,模型损失可以形式化为:
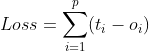
那么,模型如何学习呢?根据前向传播计算损失的过程,不难推出反向传播计算梯度的过程。在前向传播中,模型:
- 调用若干次,比如次,直到
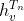 收敛。
收敛。 - 此时每个结点的隐藏状态接近不动点的解。
- 对于有监督信号的结点,将其隐藏状态通过得到输出,进而算出模型的损失。
根据上面的过程,在反向传播时,我们可以直接求出和 对最终的隐藏状态![]() 的梯度。然而,因为模型递归调用了 若干次,为计算和 对最初的隐藏状态
的梯度。然而,因为模型递归调用了 若干次,为计算和 对最初的隐藏状态 ![]() 的梯度,我们需要同样递归式/迭代式地计算 次梯度。最终得到的梯度即为和对
的梯度,我们需要同样递归式/迭代式地计算 次梯度。最终得到的梯度即为和对![]() 的梯度,然后该梯度用于更新模型的参数。这个算法就是 Almeida-Pineda 算法。
的梯度,然后该梯度用于更新模型的参数。这个算法就是 Almeida-Pineda 算法。