Transformer论文解读四(SegFormer)
最近Transformer在CV领域很火,Transformer是2017年Google发表的Attention Is All You Need中主要是针对自然语言处理领域提出的,后被拓展到各个领域。本系列文章介绍Transformer及其在各种领域引申出的应用。
本文介绍的SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers将Transformer应用于语义分割。
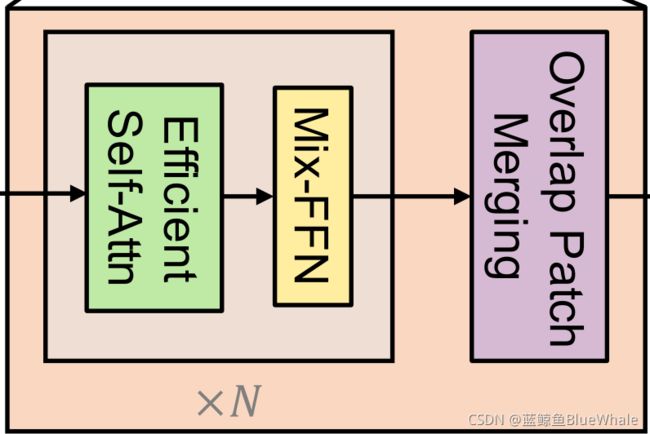
SegFormer是一个将transformer与轻量级多层感知器(MLP)解码器统一起来的语义分割框架。SegFormer的优势在于:
- SegFormer设计了一个新颖的分级结构transformer编码器,输出多尺度特征。它不需要位置编码,从而避免了位置编码的插值(当测试分辨率与训练分辨率不同时,会导致性能下降)。
- SegFormer避免了复杂的解码器。提出的MLP解码器从不同的层聚合信息,从而结合局部关注和全局关注来呈现强大的表示。作者展示了这种简单和轻量级的设计是有效分割transformer的关键。
论文给出的SegFormer的框架如下:
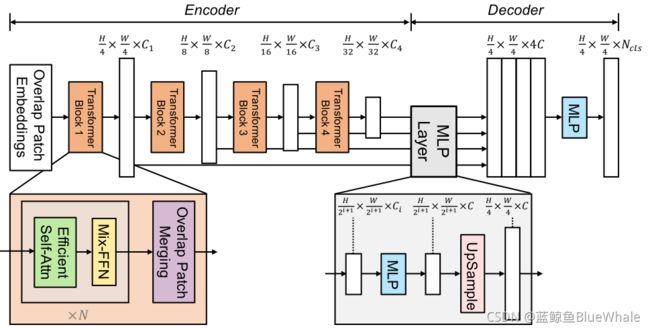
如上图所示,SegFormer由两个主要模块组成:
- 一个分层的Transformer编码器,用于生成高分辨率的粗特征和低分辨率的细特征
- 一个轻量级的All-MLP解码器,融合这些多级特征,产生最终的语义分割掩码。
对于给定图像,首先将其划分为多个较小的patch,然后输入到分级Transformer编码器,以获得原始图像分辨率的 ( 1 / 4 , 1 / 8 , 1 / 16 , 1 / 32 ) (1/4,1/8,1/16,1/32) (1/4,1/8,1/16,1/32)的多级特征。然后,将这些多级特征传递给All-MLP解码器,以预测 H 4 × W 4 × N c l s \frac{H}{4}× \frac{W}{4}× N_{cls} 4H×4W×Ncls分辨率处的分割掩码,其中 N c l s N_{cls} Ncls表示类别的数量。
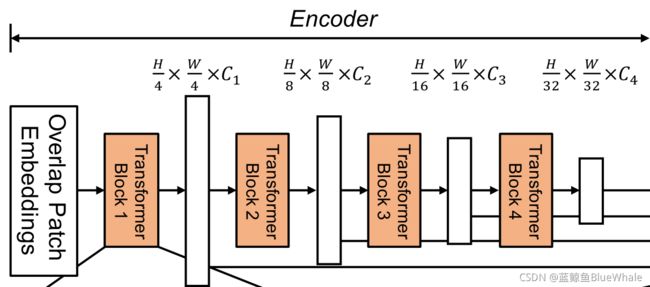
1. Hierarchical Transformer Encoder
1.1. 分层特性表示
与只能生成单分辨率特征图的ViT不同,该模块的目标是对给定输入图像生成类似cnn的多级特征。这些特征提供了高分辨率的粗特征和低分辨率的细粒度特征,通常可以提高语义分割的性能。更准确地说,给定一个分辨率为为 H × W × 3 H×W×3 H×W×3的输入图像,我们进行patch合并,得到一个分辨率为 H 2 i + 1 × W 2 i + 1 × C i \frac{H}{2^{i+1}}× \frac{W}{2^{i+1}}× C_i 2i+1H×2i+1W×Ci的层次特征图 F i F_i Fi,其中 i ∈ 1 , 2 , 3 , 4 i\in{1,2,3,4} i∈1,2,3,4, C i + 1 C_{i+1} Ci+1大于 C i C_i Ci。
1.2. 重叠合并
对于一个映像patch,ViT中使用的patch合并过程将一个 N × N × 3 N×N×3 N×N×3patch统一为一个 1 × 1 × C 1×1×C 1×1×C向量。这可以很容易地扩展到将一个 2 × 2 × C i 2×2×C_i 2×2×Ci特征路径统一到一个 1 × 1 × C i + 1 1×1×C_{i+1} 1×1×Ci+1向量中,以获得分层特征映射。
使用此方法,可以将层次结构特性从 H 4 × W 4 × C 1 \frac{H}{4}× \frac{W}{4}× C_1 4H×4W×C1缩小到 H 8 × W 8 × C 2 \frac{H}{8}× \frac{W}{8}× C_2 8H×8W×C2,然后迭代层次结构中的任何其他特性映射。这个过程最初的设计是为了结合不重叠的图像或特征块。因此,它不能保持这些斑块周围的局部连续性。相反,我们使用重叠补丁合并过程。为此,我们定义 K K K为patch大小,表示相邻两个patch之间的步幅, P P P为填充大小。
1.3. 自注意机制
编码器的主要计算瓶颈是自注意层。在原来的多头自注意过程中,每个头 Q , K , V Q, K, V Q,K,V都有相同的维数 N × C N×C N×C,其中 N = H × W N=H×W N=H×W为序列的长度,估计自注意为:
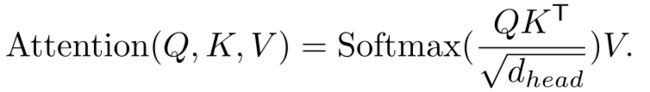
这个过程的计算复杂度是 O ( N 2 ) O(N^2) O(N2),这对于大分辨率的图像来说是巨大的。相反,作者使用一个减少比率来减少以下序列的长度:
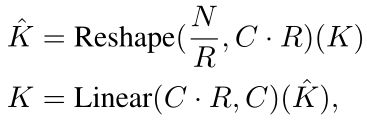
其中第一步将 K K K的形状由 N × C N×C N×C转变为 N R × ( C ⋅ R ) \frac{N}{R}×(C\cdot R) RN×(C⋅R),第二行又将 K K K的形状由 N R × ( C ⋅ R ) \frac{N}{R}×(C\cdot R) RN×(C⋅R)转变为 N R × C \frac{N}{R}×C RN×C。因此,计算复杂度就由 O ( N 2 ) O(N^2) O(N2)降至 O ( N 2 R ) O(\frac{N^2}{R}) O(RN2)。在作者给出的参数中,阶段1到阶段4的 R R R分别为 [ 64 , 16 , 4 , 1 ] [64,16,4,1] [64,16,4,1]。
1.4. 混合前馈网络
ViT使用位置编码(PE)来引入位置信息。但是PE的分辨率是固定的。因此,当测试分辨率与训练分辨率不同时,位置代码需要插值,这通常会导致精度下降。作者认为位置编码对于语义分割实际上是不必要的。因此SegFormer引入Mix-FFN,它考虑了零填充对泄漏位置信息的影响,直接在前馈网络(FFN)中使用3×3 Conv。Mix-FFN公式为:
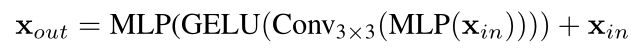
其中 x i n x_{in} xin是self-attention模块的特性。Mix-FFN将3×3卷积和MLP混合到每个FFN中。特别地,我们使用深度卷积来减少参数的数量和提高效率。
2. Lightweight All-MLP Decoder
2.1. ALL-MLP解码结构
SegFormer集成了一个轻量级解码器,只包含MLP层。实现这种简单解码器的关键是,SegFormer的分级Transformer编码器比传统CNN编码器具有更大的有效接受域(ERF)。
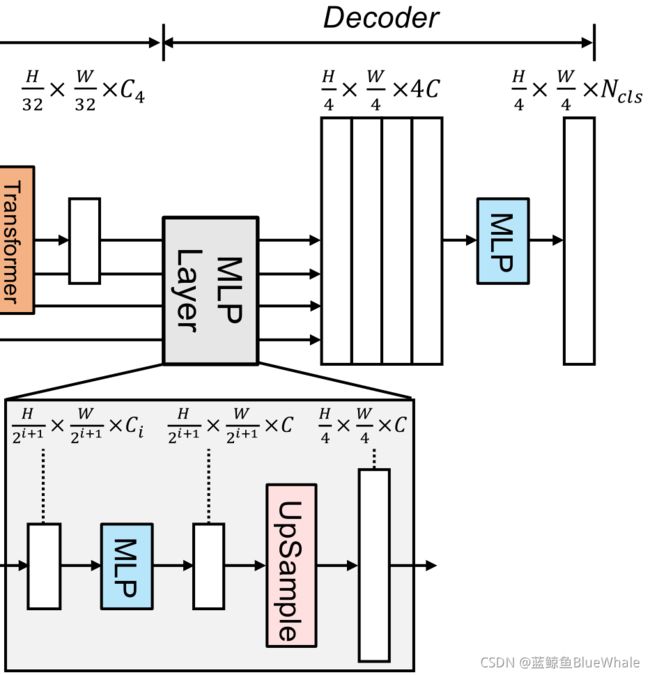
SegFormer所提出的全mlp译码器由四个主要步骤组成。
- 来自MiT编码器的多级特性通过MLP层来统一通道维度。
- 特征被上采样到1/4并连接在一起。
- 采用MLP层融合级联特征 F F F。
- 另一个MLP层采用融合的 H 4 × W 4 × N c l s \frac{H}{4}× \frac{W}{4}× N_{cls} 4H×4W×Ncls分辨率特征来预测分割掩码 M M M,其中 N c l s N_{cls} Ncls表示类别的数量。
解码器可以表述为: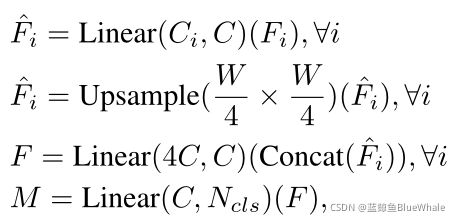
2.2. 有效接受视野(ERF)
对于语义分割,保持较大的接受域以包含上下文信息一直是一个中心问题。SegFormer使用有效接受域(ERF)作为一个工具包来可视化和解释为什么All-MLP译码器设计在TransFormer上如此有效。在下图中可视化了DeepLabv3+和SegFormer的四个编码器阶段和解码器头的ERF:
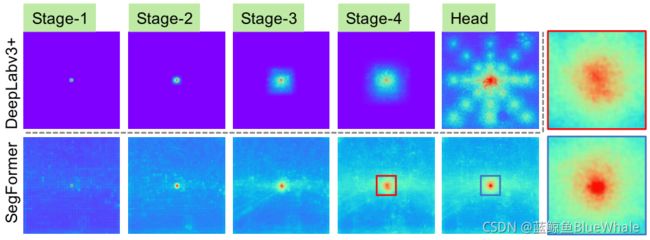
从上图中可以观察到:
- DeepLabv3+的ERF即使在最深层的Stage4也相对较小。
- SegFormer编码器自然产生局部注意,类似于较低阶段的卷积,同时能够输出高度非局部注意,有效捕获Stage4的上下文。
- 如放大Patch所示,MLP头部的ERF(蓝框)与Stage4(红框)不同,其非局部注意力和局部注意力显著增强。
CNN的接受域有限,需要借助语境模块扩大接受域,但不可避免地使网络变复杂。All-MLP译码器设计得益于transformer中的非局部注意力,并在不复杂的情况下导致更大的接受域。然而,同样的译码器设计在CNN主干上并不能很好地工作,因为整体的接受域是在Stage4的有限域的上限。
更重要的是,All-MLP译码器设计本质上利用了Transformer诱导的特性,同时产生高度局部和非局部关注。通过统一它们,All-MLP译码器通过添加一些参数来呈现互补和强大的表示。这是推动我们设计的另一个关键原因。