端到端视频编码:DVC
本文来自CVPR 2019论文《DVC: An End-to-end Deep Video Compression Framework》
官方开源代码地址:https://github.com/GuoLusjtu/DVC
DVC是一个端到端的视频编码模型,之前也有过一些基于DNN的视频编码方法,但是通常是使用DNN模型替换视频编码的某个模块,整体的训练流程不是端到端的。
DVC将传统的基于块的编码框架的所有模块都使用神经网络替换,图1(a)是传统的视频编码框架,图1(b)是DVC框架。

图1
符号定义
![]() 表示视频序列,
表示视频序列, ![]() 是第t帧,
是第t帧,![]() 是对应的预测帧,
是对应的预测帧,![]() 是重建/解码帧。
是重建/解码帧。 ![]() 表示残差,
表示残差,![]() 是残差的重建/解码值。
是残差的重建/解码值。 ![]() 是运动向量,
是运动向量, ![]() 是对应的重建值。由于编码过程中还会进行变换量化,
是对应的重建值。由于编码过程中还会进行变换量化,![]() 变换的结果为
变换的结果为 ![]() ,
, ![]() 变换结果是
变换结果是![]() 。
。
DVC架构
运动估计和压缩
使用CNN进行光流估计,得到的结果作为运动信息![]() 。其中运动信息还会经过MV编解码网络进行压缩。如图1(b)中Optical Flow Net、MV Encoder Net、MV Decoder Net。
。其中运动信息还会经过MV编解码网络进行压缩。如图1(b)中Optical Flow Net、MV Encoder Net、MV Decoder Net。
运动补偿
运动补偿网络motion compensation network主要根据前面获得的光流计算预测帧 ![]() 。
。
变换、量化和反变换
和传统的DCT、DST变换不同,这里使用残差编解码网络进行非线性变换。残差 ![]() 非线性变换的为
非线性变换的为 ![]() ,
, ![]() 量化为
量化为 ![]() 。
。![]() 通过残差解码网络可以得到重建的残差值
通过残差解码网络可以得到重建的残差值 ![]() 。
。
熵编码
量化的运动信息 ![]() 和残差
和残差![]() 要编码为比特流,为了估计比特数,使用Bit rate estimation net获取
要编码为比特流,为了估计比特数,使用Bit rate estimation net获取 ![]() 和
和 ![]() 的分布。
的分布。
帧重建
帧重建过程和传统编码框架一样。
MV编解码网络
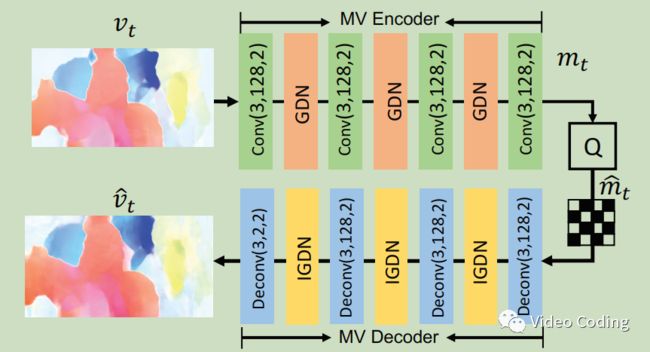
图2 MV编解码网络
图2是MV的编解码网络,Conv(3,128,2)表示卷积操作,卷积核为3x3,输出128通道,步长2。GDN/IGDN是非线性变换函数。
如果输入光流 ![]() 的尺寸是MxNx2,MV编码网络的输出
的尺寸是MxNx2,MV编码网络的输出 ![]() 的尺寸则为M/16 x N/16 x 128,
的尺寸则为M/16 x N/16 x 128, ![]() 量化为
量化为 ![]() 。MV解码网络将
。MV解码网络将 ![]() 解码为
解码为![]() 。此外,
。此外, ![]() 还要用于熵编码过程。
还要用于熵编码过程。
运动补偿网络
给定前一帧的重建帧 ![]() 和
和![]() ,运动补偿网络可以生成当前帧的重建帧
,运动补偿网络可以生成当前帧的重建帧![]() ,如图3。
,如图3。

图3 运动补偿网络
这里的运动补偿是像素级的,所以可以提供更精准的时域信息,避免了传统的基于块的运动补偿的块效应等,所以不需要环路滤波。网络详细情况请参考论文。
残差编解码网络
残差信息通过图1中的残差编解码网络进行编码,这个网络是高度非线性的,和传统的DCT等相比可以更充分的挖掘非线性变换的能力。
训练策略
损失函数
![]()
训练的目标是减小失真的同时降低码率。其他d(.)计算失真的函数,用MSE计算失真,H(.)表示估计码率。如图1所示,重建帧、原始帧和估计的码率都会输入损失函数。
量化
残差和运动向量都需要量化后才能进行熵编码,但是量化本身是不可微的,所以论文在训练阶段通过加一个均匀噪声来代替量化。
![]()
其中alpha是均匀噪声。
在推理阶段直接使用取整操作,
![]()
码率估计
为了平衡码率和失真,需要在编码过程中估计残差和运动向量的码率,估计码率需要求得数据的熵,即要获取数据的分布,论文通过一个CNN实现。
缓存历史帧
由于在运动估计和运动补偿中需要用到参考帧,参考帧是网络输出的前一帧的重建帧,即第t帧需要第t-1帧的重建帧,第t-1帧需要第t-2帧的重建帧,以此类推需要在GPU中保存所有帧,当t非常大时这是不可能的。论文提出在线更新策略,每个迭代更新一帧。
实验设置
数据集:
论文使用Vimeo-90K数据集进行训练,它包含89800个视频序列。使用UVG数据集和HEVC标准序列进行验证。
评价指标:
使用PSNR和MS-SSIM评价失真,使用bpp衡量码率。
实现细节:
使用4个lambda(256、512、1024、2048)分别训练了4个模型,每个模型使用Adam优化器训练,初始学习率设为0.0001,beta1设为0.9,β2设为0.999。当loss稳定后学习率除以10,mini-batch设为4。训练图像分辨率是256x256。使用tensorflow框架训练,在两张Titan X GPU上耗时7天完成训练。
实验结果
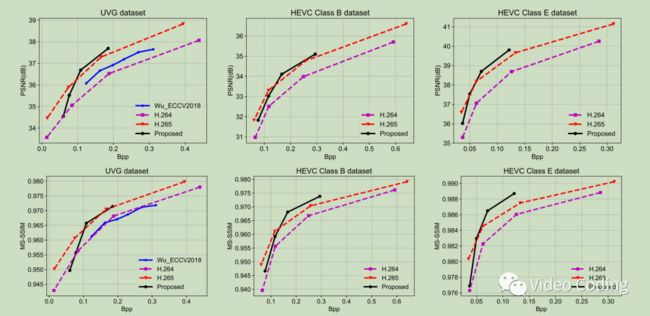
图4 部分实验结果
图4是部分实验结果,可以看见在大部分数据集上论文方法比H264在PSNR和MS-SSIM上都更优。和H265相比,中MS-SSIM指标上性能相近。论文使用MSE计算失真,如果MS-SSIM则质量会进一步提高。
总结
论文使用DNN模型将传统视频编码框架的每个部分都进行了替换实现了端到端的编码,从而可以整体进行训练。关于各个模型的具体信息可以参考论文和开源实现https://github.com/GuoLusjtu/DVC
感兴趣的请关注微信公众号Video Coding
