机器学习-偏差与方差
目录
- 1.偏差与方差
-
- 1.1 方差
- 1.2 偏差
- 2. 偏差-方差权衡
- 3. 特征提取
-
- 3.1训练误差修正
- 3.2 交叉验证
- 4. 压缩估计(正则化)
-
- 4.1 岭回归实例
- 4.2 Lasso实例
- 5.降维
- 5.1 主成分分析(PCA)
1.偏差与方差
Bias和Variance是针对Generalization来说的。
在机器学习中,我们用训练数据集去训练一个模型,一般是定义一个误差函数,通过将这个Loss的最小化过程,来提高模型的性能。
单纯地将训练数据集的loss最小化,并不能保证在解决更一般的问题时模型仍然是最优这个训练数据集的loss与一般化的数据集的loss之间的差异就叫做generalization error。而generalization error又可以细分为Bias和Variance两个部分。
而bias和variance分别从两个方面来描述了我们学习到的模型与真实模型之间的差距。
Bias是 “用所有可能的训练数据集训练出的所有模型的输出的平均值” 与 “真实模型”的输出值之间的差异;
Variance则是“不同的训练数据集训练出的模型”的输出值之间的差异。
1.1 方差
方差代表的是用一个不同的训练数据集估计f(x)时,估计函数f(x)_hat的改变量。
光滑度越高的模型有更高的方差;如下图所示,右图中改变其中任何一个数据点将会使得f(x)_hat有相当大的改变。
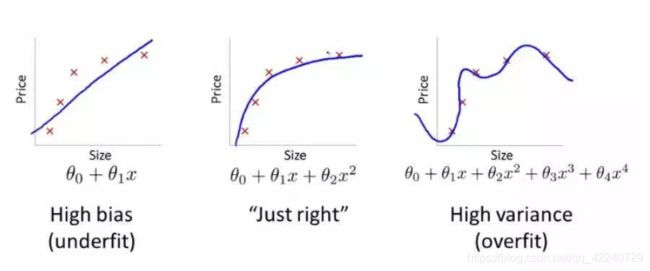
1.2 偏差
偏差代表的是为了选择一个简单的模型逼近真实函数而被带入的误差,其构成可能非常复杂。
一般来说,光滑度越高的模型所产生的偏差越小。
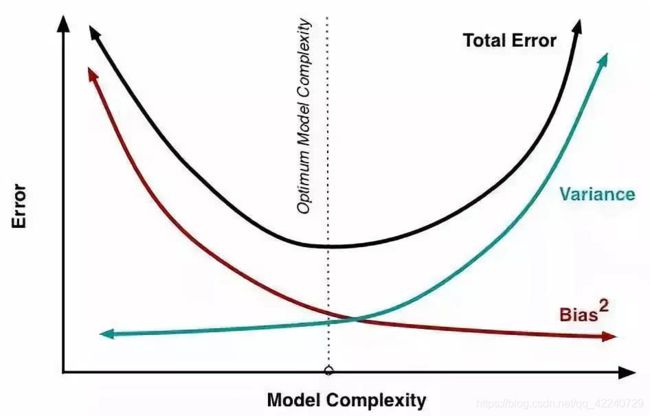
2. 偏差-方差权衡
模型光滑度越高(复杂度越高)所得模型方差增加,偏差减小,则这两个量比值的相对变化率会导致测试均方误差整体的增加或减小。总的测试均方误差会有一个先下降后上升的趋势,如果一个统计学习模型被称为测试性能好,那么要求该模型有较小的方差和较小的偏差,这就涉及到权衡的问题。
3. 特征提取
在前面能得出个结论,我们要选择一个测试误差达到最小的模型。但是实际上我们很难对实际的测试误差做精确的计算,因此我们要对测试误差进行估计,估计的方式有两种:训练误差修正与交叉验证。
3.1训练误差修正
模型越复杂,训练误差越小,测试误差先减后增。
构造一个特征较多的模型使其过拟合,此时训练误差很小而测试误差很大,那这时加入关于特征个数的惩罚。
训练误差随着特征个数的增加而减少时,惩罚项因为特征数量的增加而增大,抑制了训练误差随着特征个数的增加而无休止地减小。
C p = 1 N ( R S S + 2 d σ ^ 2 ) C_p = \frac{1}{N}(RSS + 2d\hat{\sigma}^2) Cp=N1(RSS+2dσ^2), 其中d为模型特征个数,
R S S = ∑ i = 1 N ( y i − f ^ ( x i ) ) 2 RSS = \sum\limits_{i=1}^{N}(y_i-\hat{f}(x_i))^2 RSS=i=1∑N(yi−f^(xi))2, σ ^ 2 \hat{\sigma}^2 σ^2为模型预测误差的方差的估计值,即残差的方差。
AIC赤池信息量准则: A I C = 1 d σ ^ 2 ( R S S + 2 d σ ^ 2 ) AIC = \frac{1}{d\hat{\sigma}^2}(RSS + 2d\hat{\sigma}^2) AIC=dσ^21(RSS+2dσ^2)
BIC贝叶斯信息量准则: B I C = 1 n ( R S S + l o g ( n ) d σ ^ 2 ) BIC = \frac{1}{n}(RSS + log(n)d\hat{\sigma}^2) BIC=n1(RSS+log(n)dσ^2)
3.2 交叉验证
交叉验证法可以用来估计一种指定的统计学习方法的测试误差,从而来评价这种方法的表现(模型评价),目前已成为业界评估模型性能的标准;或者为这种方法选择合适的光滑度(模型选择)。
K折交叉验证法(k-fold CV)是将观测集随机地分为k个大小基本一致的组,或者说折(fold),第一折作为验证集,然后在剩下的k-1个折上拟合模型,均方误差MSE1(响应变量Y为定性变量时则为错误率)由保留折的观测计算得出。重复这个步骤k次,每一次把不同折作为验证集,整个过程会得到k个测试误差的估计MSE1,MSE2,…, MSEk。K折CV估计由这些值求平均计算得到。
在测试误差能够被合理的估计出来以后,我们做特征选择的目标就是:从p个特征中选择m个特征,使得对应的模型的测试误差的估计最小。对应的方法有:
- 最优子集选择:
-
记不含任何特征的模型为 M 0 M_0 M0,计算这个 M 0 M_0 M0的测试误差。
-
在 M 0 M_0 M0基础上增加一个变量,计算p个模型的RSS,选择RSS最小的模型记作 M 1 M_1 M1,并计算该模型 M 1 M_1 M1的测试误差。
-
再增加变量,计算p-1个模型的RSS,并选择RSS最小的模型记作 M 2 M_2 M2,并计算该模型 M 2 M_2 M2的测试误差。
-
重复以上过程知道拟合的模型有p个特征为止,并选择p+1个模型 { M 0 , M 1 , . . . , M p } \{M_0,M_1,...,M_p \} {M0,M1,...,Mp}中测试误差最小的模型作为最优模型。
- 向前逐步选择:
最优子集选择虽然在原理上很直观,但是随着数据特征维度p的增加,子集的数量为 2 p 2^p 2p,计算效率非常低下且需要的计算内存也很高因此,我们需要把最优子集选择的运算效率提高,因此向前逐步选择算法的过程如下:
- 记不含任何特征的模型为 M 0 M_0 M0,计算这个 M 0 M_0 M0的测试误差。
- 在 M 0 M_0 M0基础上增加一个变量,计算p个模型的RSS,选择RSS最小的模型记作 M 1 M_1 M1,并计算该模型 M 1 M_1 M1的测试误差。
- 在最小的RSS模型下继续增加一个变量,选择RSS最小的模型记作 M 2 M_2 M2,并计算该模型 M 2 M_2 M2的测试误差。
- 以此类推,重复以上过程知道拟合的模型有p个特征为止,并选择p+1个模型 { M 0 , M 1 , . . . , M p } \{M_0,M_1,...,M_p \} {M0,M1,...,Mp}中测试误差最小的模型作为最优模型。
4. 压缩估计(正则化)
对回归的系数进行约束或者加罚的技巧对p个特征的模型进行拟合,显著降低模型方差,这样也会提高模型的拟合效果。
-
岭回归(L2正则化的例子)
在线性回归中,损失函数为 J ( w ) = ∑ i = 1 N ( y i − w 0 − ∑ j = 1 p w j x i j ) 2 J(w) = \sum\limits_{i=1}^{N}(y_i-w_0-\sum\limits_{j=1}^{p}w_jx_{ij})^2 J(w)=i=1∑N(yi−w0−j=1∑pwjxij)2
在线性回归的损失函数的基础上添加对系数的约束或者惩罚,即:
J ( w ) = ∑ i = 1 N ( y i − w 0 − ∑ j = 1 p w j x i j ) 2 + λ ∑ j = 1 p w j 2 , 其 中 , λ ≥ 0 w ^ = ( X T X + λ I ) − 1 X T Y J(w) = \sum\limits_{i=1}^{N}(y_i-w_0-\sum\limits_{j=1}^{p}w_jx_{ij})^2 + \lambda\sum\limits_{j=1}^{p}w_j^2,\;\;其中,\lambda \ge 0\\ \hat{w} = (X^TX + \lambda I)^{-1}X^TY J(w)=i=1∑N(yi−w0−j=1∑pwjxij)2+λj=1∑pwj2,其中,λ≥0w^=(XTX+λI)−1XTY
λ \lambda λ越大,惩罚的力度越大,系数则越趋近于0,反之,选择合适的 λ \lambda λ对模型精度来说十分重要。岭回归通过牺牲线性回归的无偏性降低方差,有可能使得模型整体的测试误差较小,提高模型的泛化能力。
- Lasso回归(L1正则化的例子):
岭回归的一个很显著的特点是:将模型的系数往零的方向压缩,但是岭回归的系数只能呢个趋于0但无法等于0,换句话说,就是无法做特征选择。
使用系数向量的L1范数替换岭回归中的L2范数:
J ( w ) = ∑ i = 1 N ( y i − w 0 − ∑ j = 1 p w j x i j ) 2 + λ ∑ j = 1 p ∣ w j ∣ , 其 中 , λ ≥ 0 J(w) = \sum\limits_{i=1}^{N}(y_i-w_0-\sum\limits_{j=1}^{p}w_jx_{ij})^2 + \lambda\sum\limits_{j=1}^{p}|w_j|,\;\;其中,\lambda \ge 0 J(w)=i=1∑N(yi−w0−j=1∑pwjxij)2+λj=1∑p∣wj∣,其中,λ≥0
当RSS曲线与坐标轴相交时恰好回归系数中的某一个为0,这样就实现了特征提取。反观岭回归的约束是一个圆域,没有尖点,因此与RSS曲线相交的地方一般不会出现在坐标轴上,因此无法让某个特征的系数为0,因此无法做到特征提取。
#定义向前逐步回归函数
def forward_select(data,target):
variate=set(data.columns) #将字段名转换成字典类型
variate.remove(target) #去掉因变量的字段名
selected=[]
current_score,best_new_score=float('inf'),float('inf') #目前的分数和最好分数初始值都为无穷大(因为AIC越小越好)
#循环筛选变量
while variate:
aic_with_variate=[]
for candidate in variate: #逐个遍历自变量
formula="{}~{}".format(target,"+".join(selected+[candidate])) #将自变量名连接起来
aic=ols(formula=formula,data=data).fit().aic #利用ols训练模型得出aic值
aic_with_variate.append((aic,candidate)) #将第每一次的aic值放进空列表
aic_with_variate.sort(reverse=True) #降序排序aic值
best_new_score,best_candidate=aic_with_variate.pop() #最好的aic值等于删除列表的最后一个值,以及最好的自变量等于列表最后一个自变量
if current_score>best_new_score: #如果目前的aic值大于最好的aic值
variate.remove(best_candidate) #移除加进来的变量名,即第二次循环时,不考虑此自变量了
selected.append(best_candidate) #将此自变量作为加进模型中的自变量
current_score=best_new_score #最新的分数等于最好的分数
print("aic is {},continuing!".format(current_score)) #输出最小的aic值
else:
print("for selection over!")
break
formula="{}~{}".format(target,"+".join(selected)) #最终的模型式子
print("final formula is {}".format(formula))
model=ols(formula=formula,data=data).fit()
return(model)
4.1 岭回归实例
from sklearn import linear_model
reg_rid = linear_model.Ridge(alpha=.5)
reg_rid.fit(X,y)
reg_rid.score(X,y)
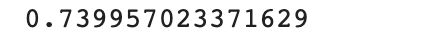
4.2 Lasso实例
from sklearn import linear_model
reg_lasso = linear_model.Lasso(alpha = 0.5)
reg_lasso.fit(X,y)
reg_lasso.score(X,y)

5.降维
将原始的特征空间投影到一个低维的空间实现变量的数量变少,如:将二维的平面投影至一维空间。机器学习领域中所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中。
降维的本质是学习一个映射函数 f : x->y,其中x是原始数据点的表达,目前最多使用向量表达形式。
y是数据点映射后的低维向量表达,通常y的维度小于x的维度(当然提高维度也是可以的)。
f可能是显式的或隐式的、线性的或非线性的。
目前大部分降维算法处理向量表达的数据,也有一些降维算法处理高阶张量表达的数据。之所以使用降维后的数据表示是因为在原始的高维空间中,包含有冗余信息以及噪音信息,在实际应用例如图像识别中造成了误差,降低了准确率;而通过降维,我们希望减少 冗余信息 所造成的误差,提高识别(或其他应用)的精度。又或者希望通过降维算法来寻找数据内部的本质结构特征。在很多算法中,降维算法成为了数据预处理的一部分,如PCA。事实上,有一些算法如果没有降维预处理,其实是很难得到很好的效果的。
5.1 主成分分析(PCA)
主成分分析的思想:通过最大投影方差 将原始空间进行重构,即由特征相关重构为无关,即落在某个方向上的点(投影)的方差最大。
把样本均值和样本协方差矩阵推广至矩阵形式:
样本均值Mean: x ˉ = 1 N ∑ i = 1 N x i = 1 N X T 1 N , 其 中 1 N = ( 1 , 1 , . . . , 1 ) N T \bar{x} = \frac{1}{N}\sum\limits_{i=1}^{N}x_i = \frac{1}{N}X^T1_N,\;\;\;其中1_N = (1,1,...,1)_{N}^T xˉ=N1i=1∑Nxi=N1XT1N,其中1N=(1,1,...,1)NT
样本协方差矩阵 S 2 = 1 N ∑ i = 1 N ( x i − x ˉ ) ( x i − x ˉ ) T = 1 N X T H X , 其 中 , H = I N − 1 N 1 N 1 N T S^2 = \frac{1}{N}\sum\limits_{i=1}^{N}(x_i-\bar{x})(x_i-\bar{x})^T = \frac{1}{N}X^THX,\;\;\,其中,H = I_N - \frac{1}{N}1_N1_N^T S2=N1i=1∑N(xi−xˉ)(xi−xˉ)T=N1XTHX,其中,H=IN−N11N1NT
最大投影方差的步骤:
(i) 中心化: x i − x ˉ x_i - \bar{x} xi−xˉ
(ii) 计算每个点 x 1 , . . . , x N x_1,...,x_N x1,...,xN至 u ⃗ 1 \vec{u}_1 u1方向上的投影: ( x i − x ˉ ) u ⃗ 1 , ∣ ∣ u ⃗ 1 ∣ ∣ = 1 (x_i-\bar{x})\vec{u}_1,\;\;\;||\vec{u}_1|| = 1 (xi−xˉ)u1,∣∣u1∣∣=1
(iii) 计算投影方差: J = 1 N ∑ i = 1 N [ ( x i − x ˉ ) T u ⃗ 1 ] 2 , ∣ ∣ u ⃗ 1 ∣ ∣ = 1 J = \frac{1}{N}\sum\limits_{i=1}^{N}[(x_i-\bar{x})^T\vec{u}_1]^2,\;\;\;||\vec{u}_1|| = 1 J=N1i=1∑N[(xi−xˉ)Tu1]2,∣∣u1∣∣=1
(iv) 最大化投影方差求 u ⃗ 1 \vec{u}_1 u1:
u ˉ 1 = a r g m a x u 1 1 N ∑ i = 1 N [ ( x i − x ˉ ) T u ⃗ 1 ] 2 s . t . u ⃗ 1 T u ⃗ 1 = 1 ( u ⃗ 1 往 后 不 带 向 量 符 号 ) \bar{u}_1 = argmax_{u_1}\;\;\frac{1}{N}\sum\limits_{i=1}^{N}[(x_i-\bar{x})^T\vec{u}_1]^2 \\ \;\;\;s.t. \vec{u}_1^T\vec{u}_1 = 1 (\vec{u}_1往后不带向量符号) uˉ1=argmaxu1N1i=1∑N[(xi−xˉ)Tu1]2s.t.u1Tu1=1(u1往后不带向量符号)
得到:
J = 1 N ∑ i = 1 N [ ( x i − x ˉ ) T u ⃗ 1 ] 2 = 1 N ∑ i = 1 N [ u 1 T ( x i − x ˉ ) ( x i − x ˉ ) T u 1 ] = u 1 T [ 1 N ∑ i = 1 N ( x i − x ˉ ) ( x i − x ˉ ) T ] u 1 = u 1 T S 2 u 1 J = \frac{1}{N}\sum\limits_{i=1}^{N}[(x_i-\bar{x})^T\vec{u}_1]^2 = \frac{1}{N}\sum\limits_{i=1}^{N}[u_1^T(x_i-\bar{x})(x_i-\bar{x})^Tu_1]\\ \; = u_1^T[\frac{1}{N}\sum\limits_{i=1}^{N}(x_i-\bar{x})(x_i - \bar{x})^T]u_1 = u_1^TS^2u_1 J=N1i=1∑N[(xi−xˉ)Tu1]2=N1i=1∑N[u1T(xi−xˉ)(xi−xˉ)Tu1]=u1T[N1i=1∑N(xi−xˉ)(xi−xˉ)T]u1=u1TS2u1
即:
u ^ 1 = a r g m a x u 1 u 1 T S 2 u 1 , s . t . u 1 T u 1 = 1 L ( u 1 , λ ) = u 1 T S 2 u 1 + λ ( 1 − u 1 T u 1 ) ∂ L ∂ u 1 = 2 S 2 u 1 − 2 λ u 1 = 0 即 : S 2 u 1 = λ u 1 \hat{u}_1 = argmax_{u_1}u_1^TS^2u_1,\;\;\;s.t.u_1^Tu_1 = 1\\ L(u_1,\lambda) = u_1^TS^2u_1 + \lambda (1-u_1^Tu_1)\\ \frac{\partial L}{\partial u_1} = 2S^2u_1-2\lambda u_1 = 0\\ 即:S^2u_1 = \lambda u_1 u^1=argmaxu1u1TS2u1,s.t.u1Tu1=1L(u1,λ)=u1TS2u1+λ(1−u1Tu1)∂u1∂L=2S2u1−2λu1=0即:S2u1=λu1
可以看到: λ \lambda λ为 S 2 S^2 S2的特征值, u 1 u_1 u1为 S 2 S^2 S2的特征向量。因此我们只需要对中心化后的协方差矩阵进行特征值分解,得到的特征向量即为投影方向。如果需要进行降维,那么只需要取p的前M个特征向量即可。